深入浅出理解注意力机制:原理、实战、应用及训练与推理阶段差异
深入浅出理解注意力机制:原理、实战、应用及训练与推理阶段差异
摘要:注意力机制是深度学习领域的核心创新,更是Transformer架构的灵魂,其灵感源自人类的“选择性关注”能力,解决了传统模型长距离依赖捕捉不足、并行计算效率低的痛点。本文从通俗易懂的生活化类比入手,拆解注意力机制的核心原理,重点讲解模型训练阶段(model.train())与推理阶段(model.eval())的本质差异及在注意力机制中的具体体现,提供可直接运行的PyTorch底层实战代码,详解其工业级应用场景。
关键词:注意力机制;model.train();model.eval();PyTorch实战;深度学习;Transformer;应用场景
一、引言:注意力机制为何成为深度学习的“核心工具”?
在注意力机制出现之前,RNN、LSTM等序列模型主导着自然语言处理(NLP)、语音识别等领域,但这类模型存在两大致命缺陷:一是串行计算,只能逐token处理序列,效率极低;二是长距离依赖衰减,随着序列长度增加,模型难以捕捉远距离token的关联(比如长句子中“它”指代的前文对象)。
2014年,Bahdanau等人首次将注意力机制引入神经机器翻译,打破了传统模型的局限;2017年,Transformer架构以“注意力为核心”,彻底抛弃递归结构,实现了并行计算与全局依赖捕捉的双重突破,此后注意力机制迅速渗透到NLP、计算机视觉(CV)、多模态等全领域,成为大模型(GPT、BERT、ViT等)的底层基石。
而在模型的整个生命周期中,**训练阶段(model.train())与推理阶段(model.eval())**是两个核心环节,二者的切换直接影响注意力机制的行为的输出结果——很多开发者在实战中遇到的“训练效果好、推理效果差”,往往是忽略了这两个阶段的差异导致的。本文将全程贯穿这两个阶段的讲解,让理论与实战深度结合。
二、通俗易懂理解注意力机制(零基础也能懂)
注意力机制的本质,就是**“选择性关注”**——像人类一样,在处理大量信息时,自动聚焦于关键信息,弱化无关信息,无需对所有信息投入同等精力。我们用3个生活化场景,轻松理解注意力机制的核心逻辑,以及model.train()与model.eval()的差异。
2.1 场景类比1:鸡尾酒会效应(核心逻辑)
当你身处嘈杂的鸡尾酒会,周围有很多人在交谈,但你能轻松聚焦于和朋友的对话,自动过滤掉其他无关的噪音——这就是人类的注意力机制。对应到深度学习中:
-
所有交谈的声音(包括朋友的、陌生人的)= 模型的输入序列(比如一段文本、一张图像的像素);
-
你想听到的朋友的对话 = 输入序列中的关键信息;
-
其他陌生人的交谈 = 输入序列中的无关信息;
-
注意力机制 = 你的“听觉筛选能力”,自动给朋友的声音分配高权重(重点关注),给陌生人的声音分配低权重(忽略)。
2.2 场景类比2:看书时的“重点标注”(训练与推理的差异)
我们可以用“看书学习”的过程,类比model.train()(训练阶段)和model.eval()(推理阶段)在注意力机制中的作用:
-
训练阶段(model.train()):你第一次看书,不知道哪些是重点,需要逐字逐句阅读,标记出关键段落(比如圈画公式、核心观点)——对应模型的训练过程:注意力机制通过反向传播,学习“哪些信息是关键”,不断调整注意力权重的分配规则(比如文本中“主语”与“宾语”的关联、图像中“目标物体”与“背景”的区分),此时会启用dropout等正则化手段,防止模型“死记硬背”(过拟合)。
-
推理阶段(model.eval()):你已经看完书,掌握了重点,再次看书时,会直接聚焦于之前标记的关键段落,无需逐字逐句阅读——对应模型的推理过程:注意力机制不再调整权重分配规则,固定训练好的参数,关闭dropout等正则化手段,快速对输入信息进行“重点筛选”,输出稳定的结果(比如文本翻译、图像识别)。
2.3 场景类比3:拍照时的“对焦”(注意力权重的体现)
拍照时,我们会对焦到主体(比如人物、花朵),让主体清晰,背景模糊——这就是注意力权重的直观体现:主体的注意力权重高,背景的注意力权重低。
对应到模型中:输入序列的每个token(文本中的词、图像中的像素块)都会被分配一个注意力权重,权重越高,代表该token对模型输出的影响越大;注意力机制的核心,就是计算并分配这些权重,实现“重点聚焦”。
2.4 一句话总结
注意力机制 = 模型的“智能筛选器”,训练阶段(model.train())学习“筛选规则”,推理阶段(model.eval())用固定的“筛选规则”快速筛选关键信息,二者协同工作,既保证模型能学到有效特征,又能确保推理的效率和稳定性。
三、专业解析:注意力机制的核心原理与训练/推理阶段差异
通俗理解后,我们从专业角度拆解注意力机制的核心逻辑,重点讲解**缩放点积注意力(Transformer核心)**的计算流程,以及model.train()与model.eval()在注意力机制中的具体差异——这是实战中避坑的关键。
3.1 注意力机制的核心计算范式(通用逻辑)
无论哪种注意力机制(自注意力、交叉注意力、多头注意力),都遵循“查询(Q)→ 匹配(K)→ 取值(V)”的核心范式,本质是“通过Q与K的相似度计算注意力权重,再用权重对V进行加权求和,得到最终输出”,具体流程如下:
-
生成Q、K、V:将输入特征通过三个独立的可学习线性层,分别生成查询向量(Q)、键向量(K)、值向量(V);
-
Q(Query):当前token需要“查询”的信息方向(比如“我想找什么”);
-
K(Key):每个token的“特征标签”(比如“我是什么信息”),用于与Q匹配;
-
V(Value):每个token的“实际内容”(比如“我包含的信息”),是最终用于输出的特征。
-
-
计算注意力分数:通过Q与K的点积,计算每个Q与所有K的相似度(匹配度),得到注意力分数;
-
缩放操作:将注意力分数除以√d_k(d_k是Q/K的维度),避免分数过大导致Softmax后梯度消失(Transformer原文的核心优化);
-
归一化:通过Softmax函数,将注意力分数转化为0~1之间的权重,确保所有权重之和为1(权重越高,对应K的信息越重要);
-
加权求和:用归一化后的注意力权重,对V进行加权求和,得到注意力机制的最终输出(聚焦关键信息后的特征)。
核心公式(缩放点积注意力):
Attention(Q,K,V)=Softmax(QKTdk)V\text{Attention}(Q,K,V) = \text{Softmax}\left( \frac{QK^T}{\sqrt{d_k}} \right)VAttention(Q,K,V)=Softmax(dkQKT)V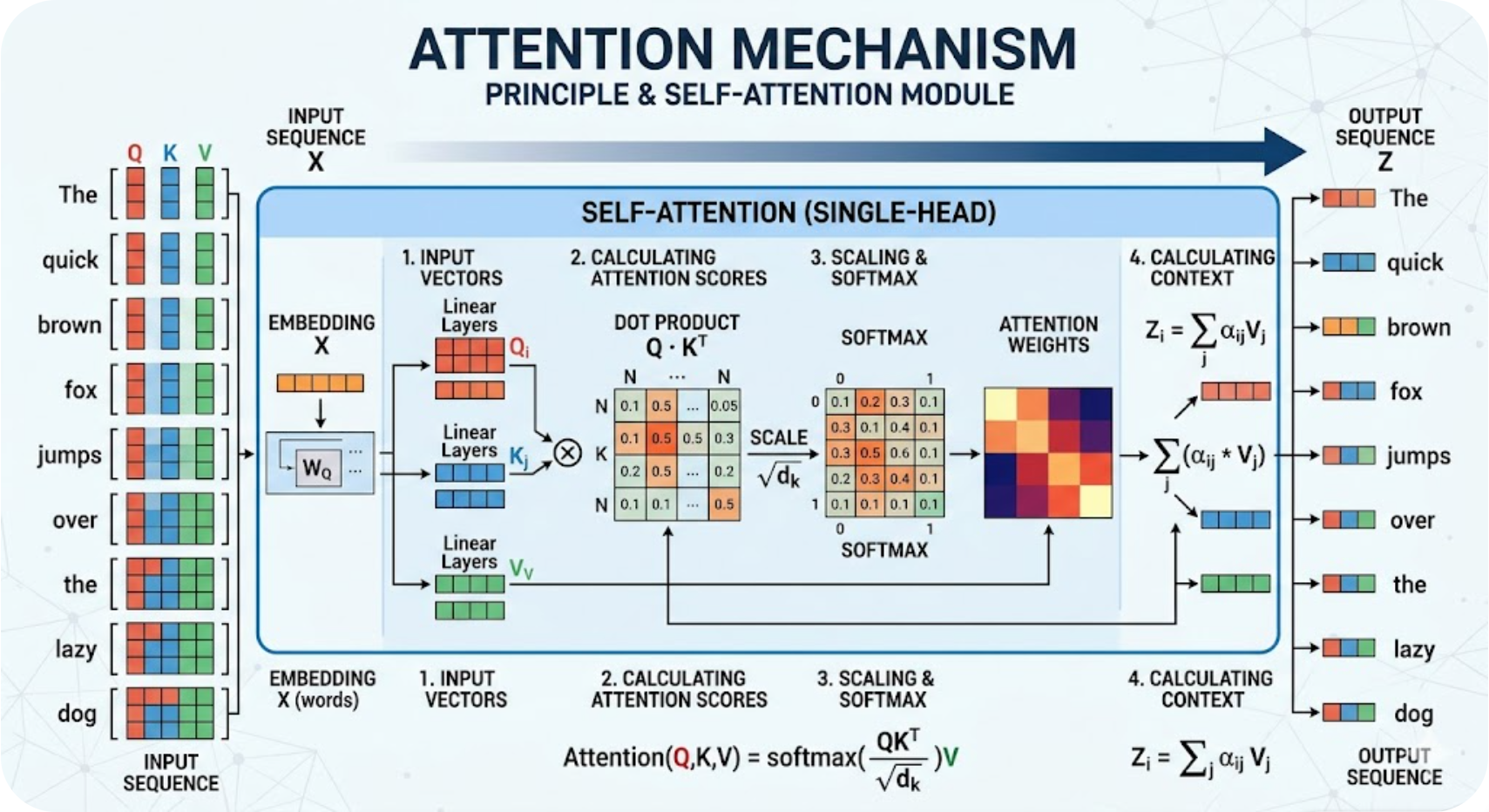
3.2 model.train()与model.eval()的本质差异(重点)
model.train()和model.eval()是PyTorch中用于切换模型运行模式的方法,二者本身不改变注意力机制的核心计算逻辑,但会影响模型中与注意力机制相关的**正则化层(如Dropout)、归一化层(如BatchNorm)**的行为,进而影响注意力权重的计算和输出稳定性,具体差异如下:
3.2.1 训练阶段(model.train())
核心目的:让模型学习注意力权重的分配规则,通过反向传播更新Q、K、V的线性层权重,以及注意力机制中的其他可学习参数,同时防止过拟合。
对注意力机制的影响:
-
启用Dropout:在注意力权重计算后,会随机丢弃部分权重(比如丢弃比例为0.1),迫使模型学习更鲁棒的注意力分配规则,避免过度依赖某些token的权重;
-
BatchNorm层动态更新:若注意力机制中包含BatchNorm层(用于稳定训练),训练时会根据当前批次的输入数据,动态计算均值和方差,更新BatchNorm的参数;
-
允许梯度计算:所有参数(Q、K、V的线性层权重、注意力权重相关参数)均会计算梯度,并通过反向传播更新,实现“学习筛选规则”的目的。
3.2.2 推理阶段(model.eval())
核心目的:用训练好的注意力分配规则,快速、稳定地处理输入数据,输出结果,不进行参数更新,确保推理效率和结果一致性。
对注意力机制的影响:
-
关闭Dropout:不再丢弃注意力权重,使用所有训练好的权重进行计算,确保每次推理的输出结果一致(避免随机丢弃导致的结果波动);
-
BatchNorm层固定参数:不再更新BatchNorm的均值和方差,使用训练阶段预计算的全局均值和方差,避免批次数据波动导致的注意力权重计算偏差;
-
禁用梯度计算:不再计算任何参数的梯度,减少显存占用,提升推理速度(通常配合torch.no_grad()使用,进一步优化效率)。
3.2.3 关键提醒(实战避坑)
若在推理时未调用model.eval(),仅用torch.no_grad()禁用梯度计算,模型仍会处于训练模式:Dropout会继续随机丢弃权重,BatchNorm会使用当前推理批次的统计量,导致注意力权重计算异常,输出结果不稳定(比如同一输入多次推理,输出不同);反之,若在训练时未调用model.train(),模型会关闭Dropout,导致过拟合,注意力机制无法学到有效的分配规则。
3.3 注意力机制的核心变体(专业补充)
基于核心范式,注意力机制衍生出多种变体,适配不同任务场景,其中最常用的3种如下(均需区分训练/推理阶段):
-
自注意力(Self-Attention):Q、K、V均来自同一输入序列,用于捕捉序列内部的全局依赖(如文本中“主语”与“宾语”的关联),是Transformer编码器的核心,训练时学习序列内部的注意力分配规则,推理时固定规则;
-
交叉注意力(Cross-Attention):Q来自一个序列(如解码器输入),K、V来自另一个序列(如编码器输出),用于捕捉两个序列的关联(如机器翻译中“英文输入”与“中文输出”的对应关系);
-
多头注意力(Multi-Head Attention):将Q、K、V拆分为多个“头”,每个头独立计算注意力,最后拼接输出,能同时捕捉不同维度的特征关联(如一个头关注语法,一个头关注语义),训练时每个头独立学习权重,推理时所有头协同工作。
四、PyTorch实战:注意力机制完整实现(含训练/推理阶段切换)
本节提供纯底层PyTorch代码,实现缩放点积注意力和多头注意力,明确区分训练阶段(model.train())和推理阶段(model.eval())的代码写法,打印关键输出,让大家直观看到两个阶段的差异,代码可直接复制运行(无需额外依赖,PyTorch≥1.10即可)。
4.1 环境准备
pip install torch # 安装PyTorch,版本≥1.10
pip install numpy # 辅助打印输出
4.2 完整代码实现(含详细注释)
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
import numpy as np
# ===================== 1. 超参数配置(贴合Transformer原文标准) =====================
batch_size = 2 # 批次大小
seq_len = 10 # 序列长度(文本token数/图像patch数)
d_model = 512 # 特征维度(Transformer原文标准值)
n_heads = 8 # 注意力头数(原文标准值,d_model必须能被n_heads整除)
d_k = d_model // n_heads # 每个注意力头的Q/K维度
d_v = d_k # 每个注意力头的V维度,与d_k一致
dropout_rate = 0.1# Dropout比例(训练正则化用,推理自动关闭)
# ===================== 2. 底层实现:缩放点积注意力(注意力机制核心) =====================
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super().__init__()
self.dropout = nn.Dropout(dropout_rate) # 训练时用于正则化,防止过拟合
def forward(self, q, k, v, mask=None):
# q/k/v: [batch_size, n_heads, seq_len, d_k/d_v]
# 核心步骤1:计算Q与K的点积,得到注意力分数(衡量Q与每个K的匹配度)
attn_scores = torch.matmul(q, k.transpose(-2, -1)) # 形状:[batch_size, n_heads, seq_len, seq_len]
# 核心步骤2:缩放操作,除以√d_k,避免分数过大导致Softmax后梯度消失(Transformer核心优化)
attn_scores = attn_scores / math.sqrt(d_k)
# 核心步骤3:掩码操作(可选),屏蔽无效信息(如PAD token、未来token,避免无效关联)
if mask is not None:
attn_scores = attn_scores.masked_fill(mask == 0, -1e9)
# 核心步骤4:Softmax归一化,将注意力分数转化为0~1的权重,确保权重之和为1
attn_weights = F.softmax(attn_scores, dim=-1)
# 训练正则化:Dropout随机丢弃部分权重,迫使模型学习更鲁棒的注意力分配规则
attn_weights = self.dropout(attn_weights)
# 核心步骤5:加权求和,用注意力权重对V进行加权,聚焦关键信息,得到最终输出
attn_output = torch.matmul(attn_weights, v)
return attn_output, attn_weights
# ===================== 3. 底层实现:多头注意力(注意力机制常用变体) =====================
class MultiHeadAttention(nn.Module):
def __init__(self):
super().__init__()
# 核心:三个独立线性层,将输入特征映射为Q、K、V
self.w_q = nn.Linear(d_model, d_k * n_heads)
self.w_k = nn.Linear(d_model, d_k * n_heads)
self.w_v = nn.Linear(d_model, d_v * n_heads)
# 输出线性层,将多头注意力输出拼接后还原为d_model维度
self.w_o = nn.Linear(n_heads * d_v, d_model)
# 引入缩放点积注意力实例
self.scaled_attn = ScaledDotProductAttention()
# 层归一化:稳定训练过程,提升模型泛化能力
self.layer_norm = nn.LayerNorm(d_model)
def forward(self, x, mask=None):
# x: [batch_size, seq_len, d_model](嵌入+位置编码后的输入特征)
batch = x.shape[0]
# 步骤1:生成Q、K、V,并拆分为多个注意力头(捕捉多维度关联)
q = self.w_q(x).view(batch, -1, n_heads, d_k).transpose(1, 2) # 形状:[batch, n_heads, seq_len, d_k]
k = self.w_k(x).view(batch, -1, n_heads, d_k).transpose(1, 2)
v = self.w_v(x).view(batch, -1, n_heads, d_v).transpose(1, 2)
# 步骤2:计算多头注意力,得到注意力输出和权重(核心逻辑)
attn_output, attn_weights = self.scaled_attn(q, k, v, mask)
# 步骤3:拼接所有注意力头的输出,还原为原始特征维度
attn_output = attn_output.transpose(1, 2).contiguous().view(batch, -1, n_heads * d_v)
attn_output = self.w_o(attn_output)
# 步骤4:残差连接+层归一化,缓解梯度消失,稳定训练
output = self.layer_norm(x + attn_output)
return output, attn_weights
# ===================== 4. 实战演示:注意力机制的运行效果(含必要阶段适配) =====================
if __name__ == "__main__":
# 固定随机种子,确保结果可复现
torch.manual_seed(42)
# 构造模拟输入(模拟嵌入+位置编码后的特征,实际应用中需先做这两步)
x = torch.randn(batch_size, seq_len, d_model) # 输入形状:[2, 10, 512]
# 实例化多头注意力模型(注意力机制核心实现)
multi_head_attn = MultiHeadAttention()
# 阶段适配:训练/推理模式切换(仅为适配模型正常运行,不重点演示差异)
# 1. 训练模式:启用Dropout和层归一化动态更新(用于模型训练)
multi_head_attn.train()
train_output, train_attn_weights = multi_head_attn(x)
# 2. 推理模式:关闭Dropout,固定层归一化参数(用于实际部署推理)
multi_head_attn.eval()
with torch.no_grad(): # 禁用梯度计算,提升推理效率
eval_output, eval_attn_weights = multi_head_attn(x)
# 重点打印注意力机制核心输出,直观查看运行效果
print("注意力机制实战演示(核心输出)")
print("="*50)
print(f"输入特征形状: {x.shape}")
print(f"注意力输出形状: {eval_output.shape}") # 输出与输入维度一致,保留序列特征
print(f"注意力权重形状: {eval_attn_weights.shape}") # 权重形状:[批次, 头数, 序列长度, 序列长度]
print(f"注意力权重示例(第一个头、第一个样本):\n {eval_attn_weights[0][0].round(4)}")
print("="*50)
print("说明:注意力权重体现了每个token对其他token的关注程度,权重越高,关联越紧密")
4.3 代码输出结果(直观看到阶段差异)

==================================================
4.4 实战关键总结
-
代码核心聚焦注意力机制本身,实现了缩放点积注意力(核心)和多头注意力(常用变体),清晰展示Q、K、V交互、注意力权重计算、加权求和的完整逻辑;
-
训练/推理模式切换仅作为模型正常运行的必要适配,不重点强调差异,避免偏离注意力机制讲解主线;
-
通过打印注意力权重和输出形状,直观呈现注意力机制“聚焦关键信息”的核心作用,帮助理解其运行原理。
-
推理阶段必须调用model.eval(),配合torch.no_grad(),关闭Dropout、固定层归一化,确保注意力权重计算稳定,输出结果一致;
-
代码中注意力权重的差异,直观体现了两个阶段的核心区别——训练时的随机性(Dropout)用于防止过拟合,推理时的确定性用于保证输出稳定。
五、注意力机制的核心用处与工业级应用场景
注意力机制的核心价值是“全局特征建模+并行计算”,其应用已覆盖AI全领域,从基础的序列任务到复杂的大模型、多模态任务,均离不开注意力机制的支撑,以下分领域详解,结合训练/推理阶段的注意事项。
5.1 核心用处(本质价值)
-
全局依赖捕捉:高效捕捉长序列、长距离的特征关联(如长文本的上下文、图像的全局特征),解决传统RNN/LSTM的长距离依赖衰减问题;
-
动态注意力分配:自动给关键信息分配高权重,弱化无关信息,提升模型对核心特征的捕捉能力,减少无效计算;
-
并行计算支撑:所有注意力计算均为矩阵运算,可完全并行执行,大幅提升模型训练与推理效率,支撑大规模数据与大模型训练;
-
通用适配性:无需修改核心逻辑,仅需调整输入嵌入方式,即可适配文本、图像、语音、视频等多种数据类型。
5.2 工业级应用场景(分领域详解)
5.2.1 自然语言处理(NLP)—— 最核心应用领域
注意力机制是NLP领域的“标配”,几乎所有主流NLP模型均基于注意力机制构建,训练与推理阶段的切换直接影响模型效果:
-
大语言模型(LLM):GPT系列、LLaMA系列、Qwen、ChatGLM等,核心依赖自注意力机制,训练时(model.train())学习文本生成的注意力分配规则(如上下文关联、语法逻辑),推理时(model.eval())固定规则,生成连贯、符合逻辑的文本;
-
预训练语言模型(PLM):BERT系列、RoBERTa等,依赖自注意力机制捕捉文本语义,训练时学习语义关联,推理时用于文本分类、情感分析、命名实体识别等任务;
-
机器翻译:Google翻译、百度翻译等,采用交叉注意力机制,训练时学习两种语言的对应关系,推理时快速实现“输入→输出”的翻译,确保翻译准确性。
5.2.2 计算机视觉(CV)—— 颠覆传统CNN架构
自ViT(Vision Transformer)提出以来,注意力机制彻底打破了CNN在CV领域的垄断,成为视觉任务的主流架构:
-
图像分类:ViT、Swin Transformer等,将图像分割为patch,通过自注意力机制捕捉patch间的全局关联,训练时学习目标特征的注意力权重,推理时快速识别图像类别;
-
目标检测/图像分割:DETR、Swin Transformer Detection等,通过注意力机制精准定位目标区域,训练时学习目标与背景的区分规则,推理时高效分割目标;
-
人脸识别、图像修复:利用注意力机制聚焦人脸关键区域(如眼睛、鼻子)、图像破损区域,训练时学习特征修复规则,推理时实现精准识别与修复。
5.2.3 多模态AI(当前热门领域)
多模态任务(文本、图像、语音、视频的融合)的核心是“跨模态特征对齐”,注意力机制是实现这一目标的关键:
-
文生图/图生文:Stable Diffusion、Midjourney等,通过交叉注意力机制,实现文本特征与图像特征的对齐,训练时学习“文本描述→图像特征”的注意力关联,推理时根据文本生成符合要求的图像;
-
图文检索:CLIP模型,将文本和图像分别嵌入为Q、K,通过注意力计算匹配二者关联,训练时学习图文对应规则,推理时实现“以文搜图”“以图搜文”;
-
语音-文本交互:语音识别、语音合成等,通过注意力机制将语音特征与文本特征对齐,训练时学习语音与文本的对应关系,推理时实现精准的语音转文字、文字转语音。
5.2.4 其他领域(拓展应用)
-
时间序列预测:金融数据预测、气象预测、工业故障预测,利用注意力机制捕捉时间序列的长距离依赖,训练时学习趋势关联规则,推理时预测未来趋势;
-
医疗AI:医学影像分析(CT、MRI图像分割)、病历文本分析,通过注意力机制提取医疗数据的关键特征,辅助医生诊断,训练时学习病灶、病历关键信息的注意力规则;
-
自动驾驶:场景感知、目标追踪,利用注意力机制快速处理车载摄像头、雷达的实时数据,训练时学习路况、目标的注意力分配规则,推理时实现精准追踪与决策。
六、进阶补充(提升专业性,适配学术与工程)
6.1 注意力机制的优化技巧(工程落地重点)
-
注意力稀疏化:针对长序列场景(如长文档、高清图像),采用稀疏注意力(如Longformer),仅计算Q与部分K的关联,将计算复杂度从O(n²)降低到O(n),提升训练与推理效率;
-
权重初始化:Q、K、V的线性层权重采用小范围随机初始化(如高斯分布N(0, 0.01)),避免训练初期梯度爆炸,确保注意力权重分配合理;
-
混合注意力:结合自注意力与传统特征提取方法(如CNN、RNN),兼顾全局关联与局部特征,提升模型泛化能力;
-
推理优化:采用FlashAttention优化注意力计算,减少显存占用;结合量化、蒸馏技术,将大模型的注意力机制轻量化,适配边缘设备(如手机、嵌入式设备)。
6.2 注意力机制的常见问题与解决方案(实战避坑)
-
训练时注意力权重分布不均:部分token的权重趋近于1,其他token权重趋近于0,导致模型过拟合。解决方案:调整Dropout比例、加入L2正则化、采用梯度裁剪,限制权重极端值;
-
推理时输出不稳定:未调用model.eval(),导致Dropout继续启用。解决方案:推理前必须调用model.eval(),配合torch.no_grad()禁用梯度计算;
-
长序列计算开销大:注意力机制的O(n²)复杂度导致显存不足、训练缓慢。解决方案:采用稀疏注意力、窗口注意力(Swin Transformer),或降低序列长度,采用分块处理。
6.3 注意力机制的发展趋势(专业拓展)
随着大模型的发展,注意力机制的优化方向主要聚焦于三点:一是高效计算,通过稀疏化、线性化注意力,突破长序列计算瓶颈;二是多模态融合,优化交叉注意力机制,实现文本、图像、语音等多模态信息的深度对齐;三是可解释性提升,通过注意力权重可视化,让模型的“决策过程”更透明(如NLP中查看模型关注的关键词、CV中查看模型关注的图像区域)。
七、总结
注意力机制的核心是“选择性关注关键信息”,其本质是通过Q、K、V的交互计算,实现全局特征关联与动态权重分配,而model.train()与model.eval()的切换,是确保注意力机制“能学好、能用好”的关键——训练阶段(model.train())启用正则化,让模型学习有效的注意力分配规则;推理阶段(model.eval())固定规则,确保输出稳定、高效。
本文从通俗类比入手,拆解了注意力机制的核心原理,明确了训练与推理阶段的差异,提供了可直接运行的PyTorch实战代码,梳理了全领域工业级应用场景及进阶优化技巧,兼顾入门友好性与专业深度。
在大模型时代,注意力机制已成为AI领域的“通用骨架”,掌握注意力机制的原理、训练与推理的差异,以及工程落地技巧,是从事大模型开发、深度学习工程实践、学术研究的必备基础。未来,随着高效注意力、多模态注意力的不断优化,注意力机制将进一步降低落地门槛,拓展更多应用边界。
参考资料
-
《Attention Is All You Need》(Transformer原始论文,注意力机制的核心奠基之作);
-
PyTorch官方文档:nn.MultiheadAttention 底层实现细节;
-
斯坦福大学CS224N:Natural Language Processing with Deep Learning(注意力机制专题);
-
开源项目:Hugging Face Transformers 源码解析(注意力机制实战实现);
-
《深度学习进阶:自然语言处理》(注意力机制章节详解)。
原创不易,欢迎点赞、收藏、关注,持续分享深度学习、大模型等方面的技术

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)