热点 Key 不是靠猜的:京东 HotKey 探测机制拆解
热点 Key 不是靠猜的:京东 HotKey 探测机制拆解
摘要: Redis 热 key 真正麻烦的地方,不是缓存本身,而是热点往往来得很突然,等慢日志、连接池、CPU 报警时已经晚了。本文结合京东云开发者社区的 JdHotkey 设计实践和京东零售开源仓库,拆解 HotKey 探测的 client、worker、dashboard、etcd 四层结构,讲清 Java 后端如何在缓存被打穿前发现热点 Key,并把它转成本地缓存、限流、降级或熔断动作。
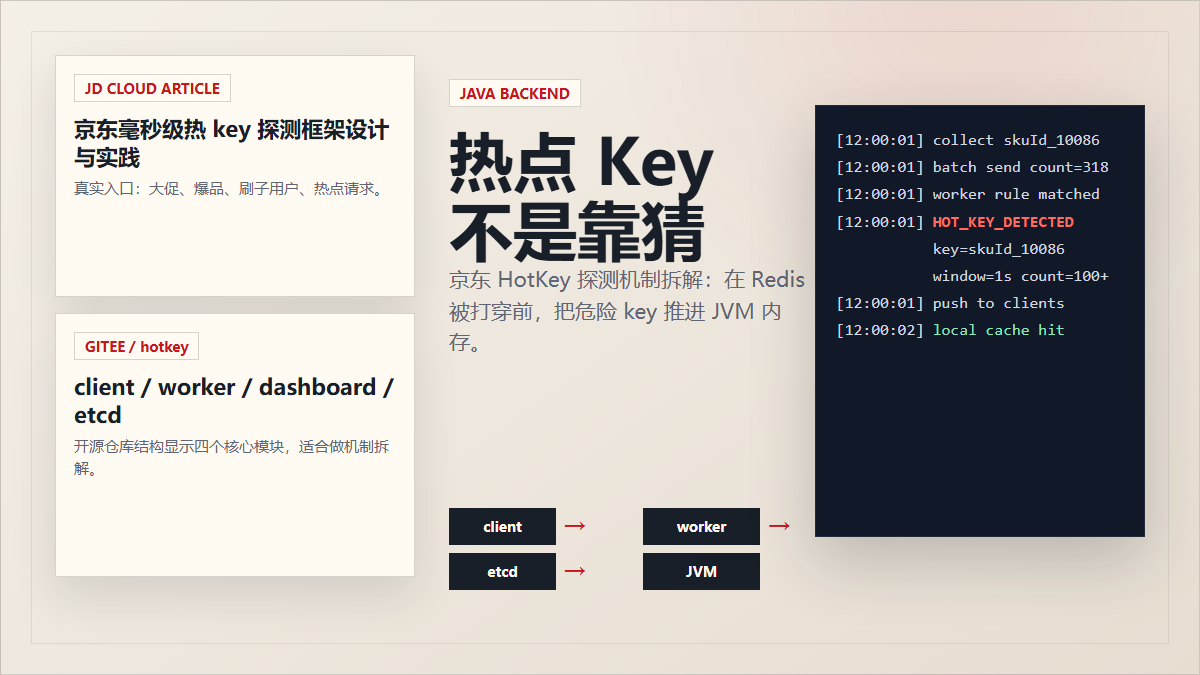
1. 缓存被打穿之前,谁先发现热点?
昨天我们聊过热点互动洪峰:Bitmap 兜状态、Kafka 削峰、SDS 做计数快照、Caffeine + Redis + MySQL 做三级缓存、单飞锁合并 miss、限流退避防重建风暴。
但那篇文章默认了一个前提:
系统已经知道哪个 key 是热点。
真实线上系统里,这一步更难。热点可能来自秒杀商品、活动页、直播间、爬虫用户、恶意 IP,也可能来自某个接口突然被集中访问。
你事后看 Redis 慢日志、连接池、CPU、DB 回源量,当然能知道出事了;问题是,那已经晚了。
所以今天只讲一个问题:
热点 Key 到底是怎么被系统实时发现的?
京东开源过一个热 key 探测框架 JdHotkey。京东云开发者社区的文章里说,它用于处理突发热点数据、热点用户、热点接口等场景,核心目标是在较短时间内识别热 key,并把它推送到服务端 JVM 内存里。Gitee 上的 jd-platform-opensource/hotkey 仓库也把它定位为“毫秒级探测热点数据,毫秒级推送至服务器集群内存”的框架。
它最值得学的不是“又加一层缓存”,而是把热点治理拆成了两步:
第一步:实时发现哪个 key 热了。
第二步:热 key 进 JVM,本地缓存、限流、降级或熔断。
2. 普通缓存为什么发现不了热点?
常见 cache-aside:
请求进来
-> 查 Redis
-> 命中:返回
-> 未命中:查数据库
-> 回写 Redis
Redis 官方 cache-aside 文档也把它作为读多写少场景的常见解法:应用先查 Redis,miss 后回源主库,再把结果写回缓存。
问题是:普通 cache-aside 是被动的。
它只回答“这个请求是否命中缓存”,回答不了“这个 key 是否正在变成热点”。
比如:
/sku/query 整体 5 万 QPS
其中 skuId=10086 这一个 key 占 3 万 QPS
接口整体 QPS 看起来正常,Redis 集群平均负载也可能看起来还行。但这个 key 如果落在某个 Redis 分片上,那一个分片会先被打满。
热点 Key 的麻烦在于:
- 平均 QPS 会掩盖单 key 峰值。
- Redis 命中率高,不代表没有单分片热点。
- 慢日志、CPU、连接池报警通常太晚。
- 人工配置本地缓存跟不上突发流量。
所以热点治理的第一步不是缓存,而是探测。
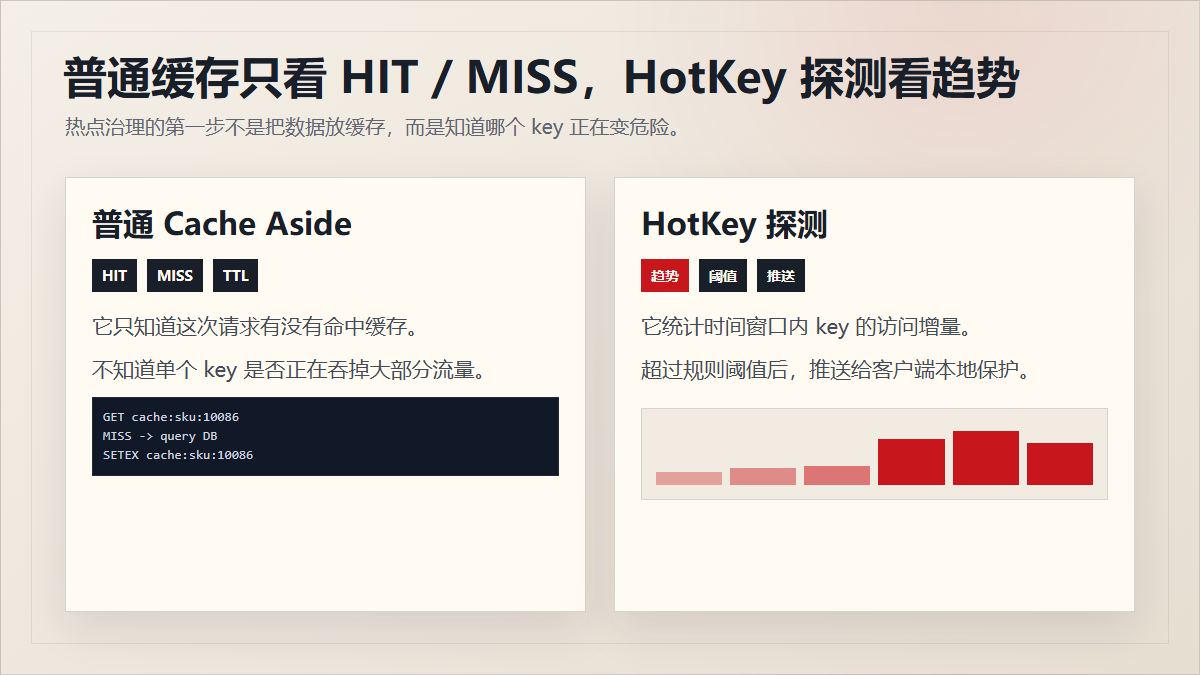
3. 京东 HotKey 的一句话理解
一句话:
客户端采集访问 key,worker 聚合判断热度,dashboard 配规则,etcd 同步规则和热 key,客户端拿到热 key 后放进 JVM 内存,再由业务决定缓存、限流、降级或熔断。
它不是 Redis 插件,也不是改造 Redis 客户端。京东云文章里明确提到,JdHotkey 不依赖 Redis,本质是一个独立的热 key 探测系统。
它关心的是“key 字符串”:
| 类型 | key 示例 |
|---|---|
| 热商品 | skuId_10086 |
| 热店铺 | shopId_888 |
| 热接口 | /sku/query |
| 刷子用户 | userId_123 |
| 恶意 IP | ip_1.2.3.4 |
| 用户访问某商品 | userId_123:/sku/query:skuId_10086 |
所以它不只服务缓存,还能服务限流、风控、降级和热点统计。
4. 四个组件:client、worker、dashboard、etcd
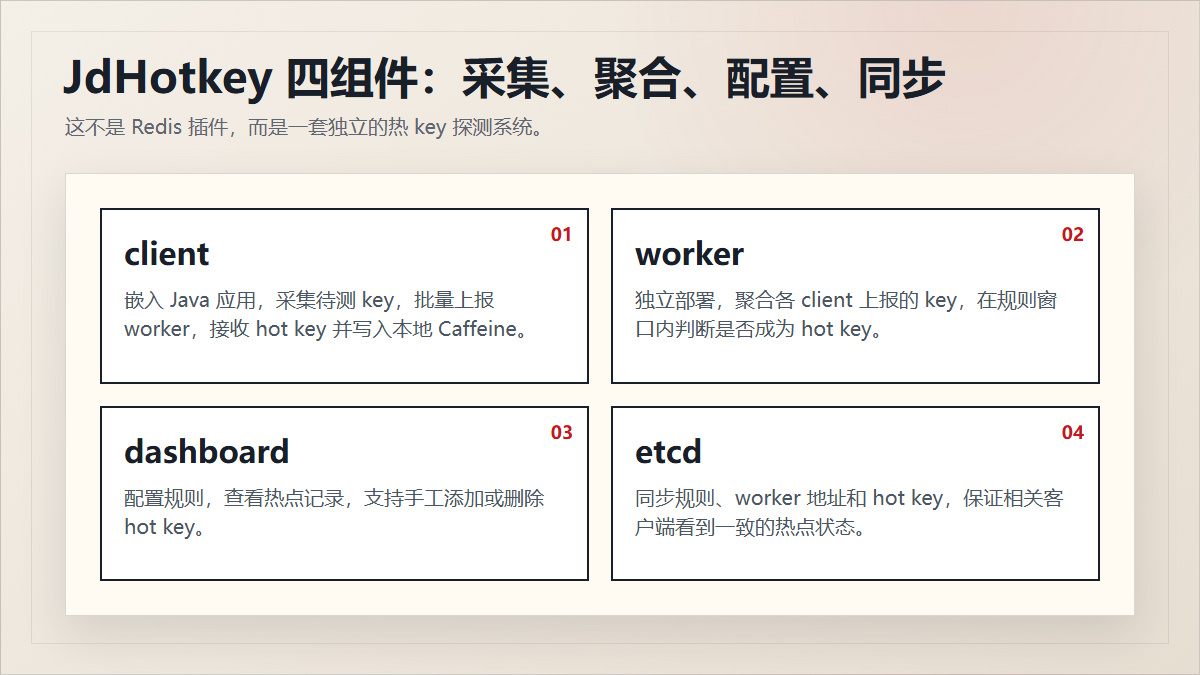
4.1 client:嵌进 Java 应用的探测入口
client 是业务应用里引入的 jar。
它负责:
- 按规则收集待探测 key。
- 定时批量上报给 worker。
- 监听规则、worker 地址、热 key 变化。
- 把探测出来的热 key 放入本地 Caffeine 缓存。
- 对外提供“这个 key 是不是热 key”的判断能力。
业务代码应该把它当成热点信号源:
if (JdHotKeyStore.isHotKey(key)) {
// 本地缓存、限流、降级、默认值等业务逻辑
}
注意:HotKey 框架只负责告诉你 key 是否热,不负责 value。比如 Redis 的 sku:10086 被判定为热 key 后,value 仍然需要业务自己加载,再放进本地缓存。
4.2 worker:真正做热度聚合和判断
worker 是独立部署的 Java 程序。
它负责:
- 从 etcd 读取规则。
- 接收 client 批量上报的 key。
- 在时间窗口内聚合 key 出现次数。
- 达到规则阈值后判定为 hot key。
- 把 hot key 推送给对应 APP 的客户端。
worker 解决的是单机看不到全局热度的问题。
集群 100 台机器
某个 sku 总访问 5000 次/秒
平均到每台机器只有 50 次/秒
单机看起来不热,整体其实已经很热。worker 聚合后,才能在集群维度判断。
4.3 dashboard:规则和人工干预入口
dashboard 是控制台。
它负责:
- 配置规则。
- 查看热 key。
- 手工添加或删除热 key。
规则示例:
skuId_ 开头:1 秒超过 100 次算热
userId_ 开头:2 秒超过 20 次算热
api_ 开头:1 秒超过 1000 次算热
商品、用户、接口、IP 的阈值不能混在一起。dashboard 的价值就是把业务规则从代码里拿出来。
4.4 etcd:配置中心和一致性通道
etcd 主要负责:
- 存规则配置。
- 存 worker 地址。
- 存探测出来的 hot key。
- 让 client、worker、dashboard 监听变化。
这里需要的是配置同步、监听、注册发现和一致性通知。etcd 更适合做这种协调型工作。
它保证:
一个 key 被判定为热
-> 所有相关 client 都能收到
一个 key 被人工删除
-> 所有相关 client 都能删除本地缓存
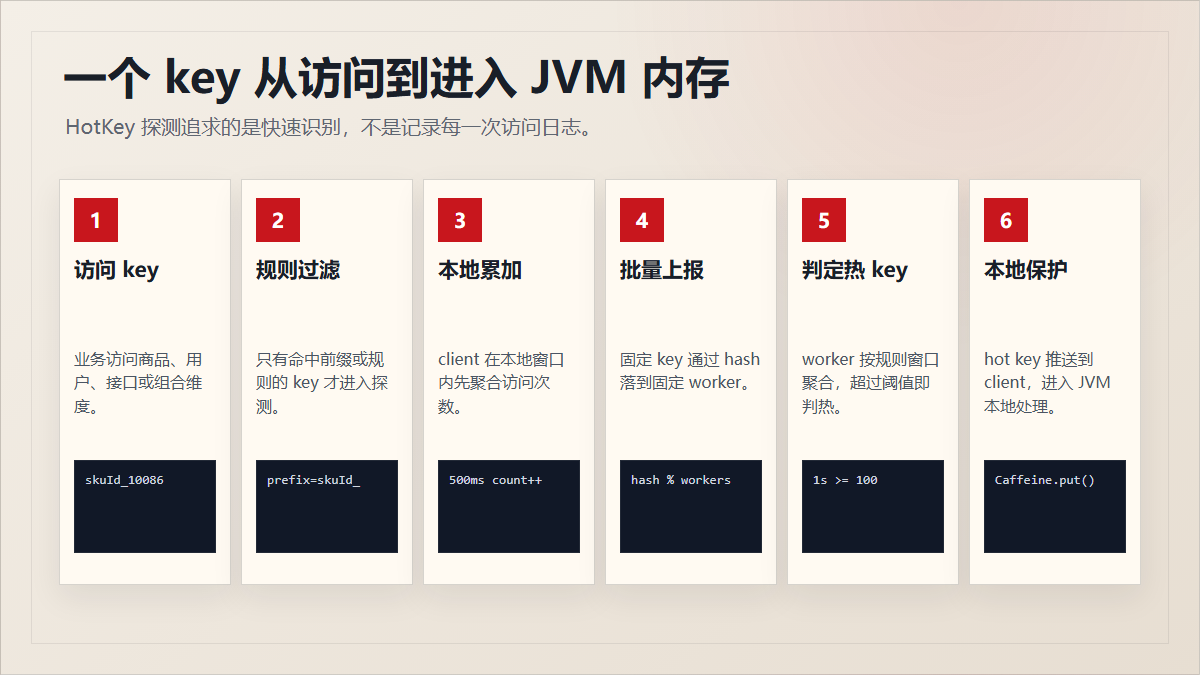
5. 探测链路:一个 key 怎么进 JVM 内存?
完整链路:
业务请求访问 key
-> client 判断这个 key 是否命中规则
-> client 在本地窗口内累加
-> 每 500ms 批量发送待测 key 到 worker
-> worker 按规则聚合计数
-> 达到阈值,判定为 hot key
-> worker 推送 hot key 给 client
-> client 放入本地 Caffeine
-> 业务后续访问走本地缓存、限流或降级
几个关键点:
5.1 只有命中规则的 key 才上报
不是所有字符串都应该上报。
HotKey 探测不是日志系统,不负责记录所有访问。它只负责尽快识别可能有风险的 key。
5.2 client 先本地累加,再批量发送
京东文章里提到,client 默认每 500ms 批量发送一次待测 key;这段时间内,client 先在本地收集并累加。
这比每次访问都发给 worker 更合理:
- 网络请求少。
- 先做局部聚合。
- worker 收到的是增量统计,不是每一次访问。
5.3 固定 key 发到固定 worker
同一个 key 不能分散到多个 worker,否则每个 worker 只看到局部计数。
所以可以用:
hash(key) % workerCount
固定 key 发送到固定 worker,聚合才准确。
5.4 热了之后不再反复上报
一个 key 已经被识别为热 key,后续重点就不是继续证明它热,而是让客户端在本地处理它。继续上报只会浪费探测资源。
6. HotKey 探测出来后,Java 侧怎么处理?
JdHotkey 只回答:
这个 key 是否热?
后续动作由业务自己决定。
6.1 本地 Caffeine 缓存
Redis 热 key 最常见的处理方式,是把 value 放进 JVM 本地缓存。
String key = "sku:" + skuId;
if (JdHotKeyStore.isHotKey(key)) {
Product product = localCache.getIfPresent(key);
if (product != null) {
return product;
}
product = redis.get(key);
JdHotKeyStore.smartSet(key, product);
return product;
}
return redis.get(key);
Caffeine 的配置文档支持 maximumSize、expireAfterWrite、refreshAfterWrite 等参数。所以本地缓存必须有容量、过期和刷新策略,不能当无界 Map。
6.2 限流或拒绝访问
如果 key 代表刷子用户或恶意 IP:
userId_123
ip_1.2.3.4
热了之后不一定缓存,而是限流、拒绝、返回默认响应。
6.3 接口降级
如果 key 代表某个接口:
api_/sku/query
热了之后可以短时间返回简化结果、默认值,或者关闭部分非核心计算。
6.4 单飞锁合并首次回源
HotKey 负责发现,single-flight 负责合并第一次加载。
CompletableFuture<Value> future = inflight.computeIfAbsent(key, k ->
CompletableFuture.supplyAsync(() -> loadValue(k), executor)
.whenComplete((v, ex) -> inflight.remove(k))
);
return future.join();
否则热 key 第一次进本地缓存前,多个线程仍可能一起回源。
7. 它和普通二级缓存有什么区别?
很多人会问:这不就是 JVM 本地缓存吗?
不是。
二级缓存只是结果,HotKey 探测才是前置机制。
| 对比点 | 普通二级缓存 | HotKey 探测 |
|---|---|---|
| 是否知道 key 热不热 | 不知道,通常无脑缓存 | 实时统计后判断 |
| 是否集群一致 | 常常不一致 | 通过 etcd 推送保持一致 |
| 是否能处理刷子用户 | 不适合 | 可以把用户 ID 当 key |
| 是否能处理热接口 | 不适合 | 可以把接口路径当 key |
| 是否需要业务规则 | 较少 | 规则是核心 |
| 主要价值 | 减少部分 Redis/DB 访问 | 在热点刚出现时快速保护系统 |
8. 面试怎么讲京东 HotKey?
如果面试官问:
Redis 热 key 怎么处理?
不要只说“加本地缓存”。
可以这样讲:
我会把热 key 问题拆成两步。
第一步是发现:不能靠人工猜,也不能只看接口平均 QPS。
可以参考京东 HotKey 的思路,在业务 client 侧采集待测 key,按规则批量上报 worker,由 worker 在时间窗口内聚合判断,达到阈值后通过 etcd 推送给所有客户端。
第二步是处理:客户端拿到 hot key 后,可以把 value 放进 Caffeine 本地缓存,也可以对用户、IP、接口做限流、降级或熔断。对于首次加载,还要配合单飞锁,避免多个线程同时回源。
这段回答比“Redis 热 key 放本地缓存”更完整,因为它讲清楚了发现、聚合、规则、通知和处理动作。
9. Java 后端落地清单
如果你不是直接引入 JdHotkey,而是自己做简化版,也要保留这些关键点:
- 先定义 key 维度:商品、用户、接口、IP、组合维度。
- 规则必须可配置:不同前缀、不同业务使用不同阈值。
- client 不全量上报:先按规则过滤,再本地聚合,再批量发送。
- 同一个 key 固定打到同一个 worker:否则聚合不准。
- worker 做窗口统计:目标是快速判断,不是精确日志。
- 热 key 要推送到全部相关 client:否则集群行为不一致。
- 本地缓存要有容量和过期:Caffeine 不能当无界 Map。
- 热 key 只是一种信号:后续动作可以是缓存、限流、降级、熔断、默认值。
- 首次加载要防并发回源:HotKey + 单飞锁一起用。
- 监控探测系统本身:worker QPS、队列长度、推送延迟、hot key 数量都要看。

总结
热点 Key 不是靠猜的。
真正可上线的高并发缓存系统,不能只在 Redis 被打穿之后再补救,而要在热点刚出现时就发现它。
京东 HotKey 的机制可以概括成:
client 采集 key
worker 聚合判断
dashboard 配规则
etcd 同步推送
client 本地保护
这套机制背后的工程判断很清楚:
缓存治理不是从“缓存什么”开始,而是从“如何发现危险的 key”开始。
参考资料
- 京东云开发者社区:京东毫秒级热 key 探测框架设计与实践,已完美支撑 618 大促:https://developer.jdcloud.com/article/2855
- Gitee:京东零售 hotkey 开源仓库:https://gitee.com/jd-platform-opensource/hotkey
- Redis 官方文档:Cache-aside:https://redis.io/docs/latest/develop/use-cases/cache-aside/
- Caffeine Wiki:Specification:https://github.com/ben-manes/caffeine/wiki/Specification

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)