MapTR: Structured Modeling and Learning for Online Vectorized HD Map Construction
摘要
高清(HD)地图为驾驶场景提供了丰富且精确的环境信息,是自动驾驶系统规划模块中基础且不可或缺的核心组成部分。本文提出 MapTR,一种用于高效在线矢量化 HD 地图构建的结构化端到端 Transformer 模型。我们提出了一种统一的置换等价的建模方法,即将地图元素建模为一个点集,并包含一组等价的置换方式,从而准确描述地图元素的形状并稳定学习过程。我们设计了一种分层查询嵌入方案,以灵活编码结构化的地图信息,并执行分层二分匹配以进行地图元素学习。
1 INTRODUCTION
高清(HD)地图是专为自动驾驶设计的高精度地图,由地图要素(如人行横道、车道分隔线、道路边界等)的实例级矢量化表示构成。高清地图包含丰富的道路拓扑和交通规则语义信息,这对于自动驾驶汽车的导航至关重要。
传统上,高清地图是通过基于同步定位与建图(SLAM)的方法离线构建的(Zhang & Singh, 2014; Shan & Englot, 2018; Shan et al., 2020),这导致了复杂的处理流程和高昂的维护成本。近年来,在线高清地图构建引起了越来越多的关注,它利用车载传感器在运行时围绕自车构建地图,从而摆脱了离线人工劳动。早期工作(Chen et al., 2022a; Liu et al., 2021a; Can et al., 2021)利用线形先验,基于前视图像感知开放形状的车道。但它们局限于单视图感知,无法处理其他具有任意形状的地图要素。随着鸟瞰图(BEV)表示学习的发展,近期工作(Chen et al., 2022b; Zhou & Kr¨ahenb¨uhl, 2022; Hu et al., 2021; Li et al., 2022c)通过执行BEV语义分割来预测栅格化地图。然而,栅格化地图缺乏矢量化实例级信息(如车道结构),而这对于下游任务(例如运动预测和规划)非常重要。为了构建矢量化高清地图,HDMapNet(Li et al., 2022a)对像素级分割结果进行分组,这需要复杂且耗时的后处理。VectorMapNet(Liu et al., 2022a)将每个地图要素表示为点序列。它采用级联的由粗到精框架,并利用自回归解码器依次预测点,导致推理时间较长。
当前的在线矢量化高清地图构建方法受限于效率,无法适用于实时场景。最近,DETR(Carion et al., 2020)采用了一种简单高效的编码器-解码器Transformer架构,实现了端到端的对象检测。自然而然地产生了一个问题:我们能否设计一种类似DETR的范式来进行高效的端到端矢量化高清地图构建?我们通过提出的Map TRansformer(MapTR)证明了答案是肯定的。
与对象检测中对象可以很容易地几何抽象为边界框不同,矢量化地图要素具有更动态的形状。为了准确描述地图要素,我们提出了一种新型的统一建模方法。我们将每个地图要素建模为一个具有等效置换组构成的点集。点集决定了地图要素的位置,而置换群包含了与相同几何形状对应的点集所有可能的组织序列,从而避免了形状的歧义。
基于这种置换等价的建模,我们设计了一个结构化框架,以车载摄像头图像为输入,输出矢量化高清地图。我们将在线矢量化高清地图构建简化为一个并行回归问题。我们提出了分层查询嵌入,以灵活编码实例级和点级信息。所有实例及其所有点都通过统一的Transformer结构同时预测。训练流程被表述为分层集合预测任务,其中我们执行分层二分匹配,依次分配实例和点。我们还提出了point2point损失和边缘方向损失,在点和边缘两个层面上监督几何形状。
凭借所有提出的设计,我们展示了MapTR,这是一种具有统一建模和架构的高效端到端在线矢量化高清地图构建方法。MapTR在nuScenes数据集(Caesar et al., 2020)上的矢量化地图构建方法中取得了最佳的性能和效率。特别是,MapTR-nano在RTX 3090上以实时推理速度(25.1 FPS)运行,比现有的最先进基于相机的方法快8倍,同时mAP提高了5.0。即使与现有的最先进多模态方法相比,MapTR-nano也实现了高0.7的mAP和8倍的推理速度,而MapTR-tiny则实现了高13.5的mAP和3倍的推理速度。正如可视化所示(图1),MapTR在复杂且多样的驾驶场景中保持了稳定且鲁棒的地图构建质量。
我们的贡献总结如下:
- 我们提出了一种用于地图要素的统一置换等价建模方法,即将地图要素建模为具有等效置换组的点集,这准确描述了地图要素的形状并稳定了学习过程。
- 基于这种新颖的建模,我们提出了MapTR,这是一种用于高效在线矢量化高清地图构建的结构化端到端框架。我们设计了分层查询嵌入方案,以灵活编码实例级和点级信息,执行分层二分匹配以进行地图要素学习,并利用提出的point2point损失和边缘方向损失在点和边缘层面上监督几何形状。
- MapTR是第一种在复杂且多样的驾驶场景中具有稳定且鲁棒性能的实时且最先进(SOTA)的矢量化高清地图构建方法。
2 相关工作
高清地图构建。近年来,随着2D到BEV方法的发展(Ma et al., 2022),高清地图构建被表述为基于车载相机捕获的环视图像数据的分割问题。Chen et al. (2022b); Zhou & Kr¨ahenb¨uhl (2022); Hu et al. (2021); Li et al. (2022c); Philion & Fidler (2020); Liu et al. (2022b) 通过执行BEV语义分割生成栅格化地图。为了构建矢量化高清地图,HDMapNet(Li et al., 2022a)通过启发式且耗时的后处理对像素级语义分割结果进行分组以生成实例。VectorMapNet(Liu et al., 2022a)作为第一个端到端框架,采用两阶段由粗到精的框架并利用自回归解码器依次预测点,导致推理时间长以及置换歧义。与VectorMapNet不同,MapTR引入了新颖且统一的地图要素建模方法,解决了歧义并稳定了学习过程。此外,MapTR构建了一个结构化且并行的单阶段框架,具有更高的效率。
车道检测。车道检测可以被视为高清地图构建的一个子任务,专注于检测道路场景中的车道要素。由于大多数车道检测数据集仅提供单视图标注并专注于开放形状要素,相关方法局限于单视图。LaneATT(Tabelini et al., 2021)利用基于锚点的深度车道检测模型,在准确性和效率之间取得了良好的平衡。LSTR(Liu et al., 2021a)采用Transformer架构直接输出车道形状模型的参数。GANet(Wang et al., 2022)将车道检测表述为关键点估计和关联问题,并采用自底向上的设计。Feng et al. (2022) 提出了基于参数化贝塞尔曲线的车道检测方法。Garnett et al. (2019) 没有仅在2D图像坐标系中检测车道,而是提出了3D-LaneNet,它在BEV中执行3D车道检测。STSU(Can et al., 2021)将车道表示为BEV坐标系中的有向图,并采用基于曲线的贝塞尔方法从单目相机图像预测车道。Persformer(Chen et al., 2022a)提供了更好的BEV特征表示,并优化了锚点设计以同时统一2D和3D车道检测。MapTR不仅仅局限于有限单视图中检测车道,而是通过统一的建模和学习框架感知360°水平视场角内的各种地图要素。
基于轮廓的实例分割。与MapTR相关的另一类工作是基于轮廓的2D实例分割(Zhu et al., 2022; Xie et al., 2020; Xu et al., 2019; Liu et al., 2021c)。这些方法将2D实例分割重新表述为对象轮廓预测任务,并估计轮廓顶点的图像坐标。CurveGCN(Ling et al., 2019)利用图卷积网络预测多边形边界。Lazarow et al. (2022); Liang et al. (2020); Li et al. (2021); Peng et al. (2020) 依赖中间表示并采用两阶段范式,即第一阶段执行分割/检测以生成顶点,第二阶段将顶点转换为多边形。这些工作将2D实例掩膜的轮廓建模为多边形。它们的建模方法无法处理线形地图要素,也不适用于地图构建。相比之下,MapTR专为高清地图构建而定制,并以统一的方式建模各种地图要素。此外,MapTR不依赖中间表示,并具有高效紧凑的处理流程。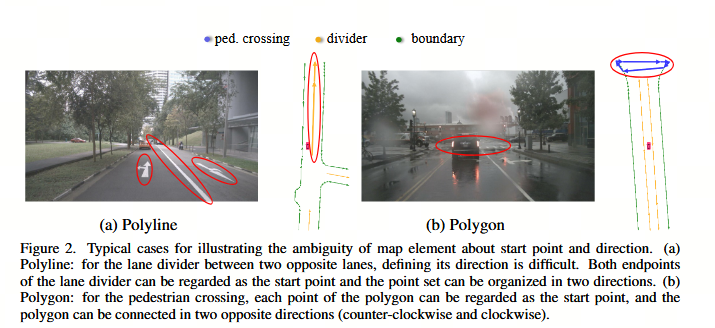
图 2. 用于阐明地图元素在起点和方向上的歧义性的典型示例。(a) 折线:对于两条对向车道之间的车道分隔线,定义其方向较为困难。车道分隔线的两个端点均可被视为起点,该点集可以以两种方向进行组织。(b) 多边形:对于人行横道,多边形的每个点均可被视为起点,且该多边形可以以两种相反的方向(逆时针和顺时针)进行连接。
3 方法论
3.1 置换等价建模
MapTR 旨在以统一的方式对高精地图(HD map)进行建模和学习。高精地图是一组矢量化静态地图元素的集合,包括人行横道、车道分隔线、道路边界等。为了进行结构化建模,MapTR 从几何上将地图元素抽象为封闭形状(如人行横道)和开放形状(如车道分隔线)。通过沿形状边界顺序采样点,封闭形状元素被离散化为多边形,而开放形状元素被离散化为折线。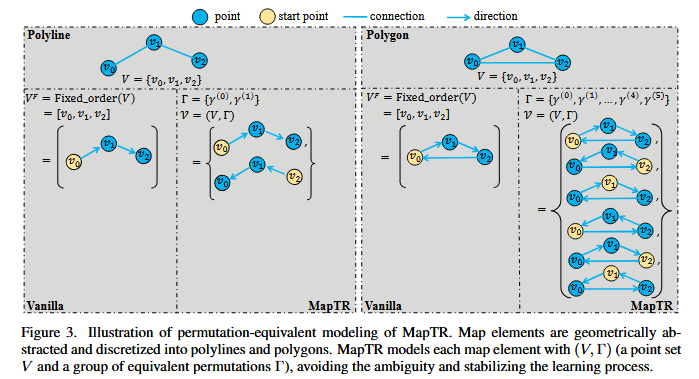
初步来看,多边形和折线都可以表示为有序点集 VF=[v0,v1,…,vNv−1]V_F = [v_0, v_1, \dots, v_{N_v-1}]VF=[v0,v1,…,vNv−1](见图 3 (Vanilla))。NvN_vNv 表示点的数量。然而,点集的排列顺序并未明确定义,也不是唯一的。多边形和折线存在许多等价的排列方式。例如,如图 2 (a) 所示,对于两条相反车道之间的车道分隔线(折线),定义其方向是很困难的。车道分隔线的两个端点都可以被视为起点,且点集可以按两个方向组织。在图 2 (b) 中,对于人行横道(多边形),点集可以按两个相反的方向组织(逆时针和顺时针)。循环改变点集的排列顺序不会影响多边形的几何形状。将固定的排列顺序强加为监督信号是不合理的。这种强加的固定排列与其他等价排列相矛盾,从而阻碍了学习过程。
为了弥补这一差距,MapTR 使用 V=(V^,Γ)V = (\hat{V}, \Gamma)V=(V^,Γ) 对每个地图元素进行建模。V^={v^j}j=0Nv−1\hat{V} = \{\hat{v}_j\}_{j=0}^{N_v-1}V^={v^j}j=0Nv−1 表示地图元素的点集(NvN_vNv 是点的数量)。Γ={γk}\Gamma = \{\gamma_k\}Γ={γk} 表示点集 V^\hat{V}V^ 的一组等价排列,覆盖了所有可能的组织序列。
具体而言,对于折线元素(见图 3 (左)),Γ\GammaΓ 包含 2 种等价排列:
Γpolyline={γ0,γ1}{γ0(j)=j mod Nv,γ1(j)=(Nv−1)−j mod Nv.(1) \Gamma_{\text{polyline}} = \{\gamma_0, \gamma_1\} \begin{cases} \gamma_0(j) = j \bmod N_v, \\ \gamma_1(j) = (N_v - 1) - j \bmod N_v. \end{cases} \quad (1) Γpolyline={γ0,γ1}{γ0(j)=jmodNv,γ1(j)=(Nv−1)−jmodNv.(1)
对于多边形元素(见图 3 (右)),Γ\GammaΓ 包含 2×Nv2 \times N_v2×Nv 种等价排列:
Γpolygon={γ0,…,γ2Nv−1}{γ0(j)=j mod Nv,γ1(j)=(Nv−1)−j mod Nv,γ2(j)=(j+1) mod Nv,γ3(j)=(Nv−1)−(j+1) mod Nv,…γ2Nv−2(j)=(j+Nv−1) mod Nv,γ2Nv−1(j)=(Nv−1)−(j+Nv−1) mod Nv.(2) \Gamma_{\text{polygon}} = \{\gamma_0, \dots, \gamma_{2N_v-1}\} \begin{cases} \gamma_0(j) = j \bmod N_v, \\ \gamma_1(j) = (N_v - 1) - j \bmod N_v, \\ \gamma_2(j) = (j + 1) \bmod N_v, \\ \gamma_3(j) = (N_v - 1) - (j + 1) \bmod N_v, \\ \dots \\ \gamma_{2N_v-2}(j) = (j + N_v - 1) \bmod N_v, \\ \gamma_{2N_v-1}(j) = (N_v - 1) - (j + N_v - 1) \bmod N_v. \end{cases} \quad (2) Γpolygon={γ0,…,γ2Nv−1}⎩
⎨
⎧γ0(j)=jmodNv,γ1(j)=(Nv−1)−jmodNv,γ2(j)=(j+1)modNv,γ3(j)=(Nv−1)−(j+1)modNv,…γ2Nv−2(j)=(j+Nv−1)modNv,γ2Nv−1(j)=(Nv−1)−(j+Nv−1)modNv.(2)
通过引入等价排列的概念,MapTR 以统一的方式对地图元素进行建模,并解决了歧义问题。MapTR 进一步引入了分层二分匹配(见第 3.2 节和第 3.3 节)以进行地图元素学习,并设计了一种结构化编码器-解码器 Transformer 架构,以高效地预测地图元素(见第 3.4 节)。
3.2 分层匹配
MapTR 遵循 DETR (Carion et al., 2020; Fang et al., 2021) 的端到端范式,在一次前向传播中并行推断出固定大小的 NNN 个地图元素集。NNN 设置为大于场景中典型地图元素数量。让我们用 Y^={y^i}i=0N−1\hat{Y} = \{\hat{y}_i\}_{i=0}^{N-1}Y^={y^i}i=0N−1 表示 NNN 个预测地图元素的集合。真实值(GT)地图元素集合通过填充 ∅\emptyset∅(无物体)形成大小为 NNN 的集合,记为 Y={yi}i=0N−1Y = \{y_i\}_{i=0}^{N-1}Y={yi}i=0N−1。yi=(ci,Vi,Γi)y_i = (c_i, V_i, \Gamma_i)yi=(ci,Vi,Γi),其中 ci,Vic_i, V_ici,Vi 和 Γi\Gamma_iΓi 分别是真实值地图元素 yiy_iyi 的目标类别标签、点集和排列组。y^i=(p^i,V^i)\hat{y}_i = (\hat{p}_i, \hat{V}_i)y^i=(p^i,V^i),其中 p^i\hat{p}_ip^i 和 V^i\hat{V}_iV^i 分别是预测的分类得分和预测点集。为了实现结构化的地图元素建模和学习,MapTR 引入了分层二分匹配,即按顺序执行实例级匹配和点级匹配。
实例级匹配。首先,我们需要在预测地图元素 {y^i}\{\hat{y}_i\}{y^i} 和真实值地图元素 {yi}\{y_i\}{yi} 之间找到最优的实例级标签分配 π^\hat{\pi}π^。π^\hat{\pi}π^ 是 NNN 个元素的一个排列(π^∈ΠN\hat{\pi} \in \Pi_Nπ^∈ΠN),具有最低的实例级匹配代价:
π^=argminπ∈ΠN∑i=0N−1Lmatchins(y^π(i),yi).(3) \hat{\pi} = \arg \min_{\pi \in \Pi_N} \sum_{i=0}^{N-1} L^{\text{ins}}_{\text{match}}(\hat{y}_{\pi(i)}, y_i). \quad (3) π^=argπ∈ΠNmini=0∑N−1Lmatchins(y^π(i),yi).(3)
Lmatchins(y^π(i),yi)L^{\text{ins}}_{\text{match}}(\hat{y}_{\pi(i)}, y_i)Lmatchins(y^π(i),yi) 是预测 y^π(i)\hat{y}_{\pi(i)}y^π(i) 和真实值 yiy_iyi 之间的成对匹配代价,考虑了地图元素的类别标签和点集的位置:
Lmatchins(y^π(i),yi)=LFocal(p^π(i),ci)+Lposition(V^π(i),Vi).(4) L^{\text{ins}}_{\text{match}}(\hat{y}_{\pi(i)}, y_i) = L_{\text{Focal}}(\hat{p}_{\pi(i)}, c_i) + L_{\text{position}}(\hat{V}_{\pi(i)}, V_i). \quad (4) Lmatchins(y^π(i),yi)=LFocal(p^π(i),ci)+Lposition(V^π(i),Vi).(4)
LFocal(p^π(i),ci)L_{\text{Focal}}(\hat{p}_{\pi(i)}, c_i)LFocal(p^π(i),ci) 是类别匹配代价项,定义为预测分类得分 p^π(i)\hat{p}_{\pi(i)}p^π(i) 和目标类别标签 cic_ici 之间的 Focal Loss (Lin et al., 2017)。Lposition(V^π(i),Vi)L_{\text{position}}(\hat{V}_{\pi(i)}, V_i)Lposition(V^π(i),Vi) 是位置匹配代价项,反映了预测点集 V^π(i)\hat{V}_{\pi(i)}V^π(i) 与真实值点集 ViV_iVi 之间的位置相关性(更多细节见附录 B)。匈牙利算法用于找到最优的实例级分配 π^\hat{\pi}π^,遵循 DETR 的方法。
点级匹配。在实例级匹配之后,每个预测地图元素 y^π^(i)\hat{y}_{\hat{\pi}(i)}y^π^(i) 被分配一个真实值地图元素 yiy_iyi。然后,对于每个被分配正标签(ci≠∅c_i \neq \emptysetci=∅)的预测实例,我们执行点级匹配,以在预测点集 V^π^(i)\hat{V}_{\hat{\pi}(i)}V^π^(i) 和真实值点集 ViV_iVi 之间找到最优的点对点分配 γ^∈Γ\hat{\gamma} \in \Gammaγ^∈Γ。γ^\hat{\gamma}γ^ 是从预定义的排列组 Γ\GammaΓ 中选择的,具有最低的点级匹配代价:
γ^=argminγ∈Γ∑j=0Nv−1DManhattan(v^j,vγ(j)).(5) \hat{\gamma} = \arg \min_{\gamma \in \Gamma} \sum_{j=0}^{N_v-1} D_{\text{Manhattan}}(\hat{v}_j, v_{\gamma(j)}). \quad (5) γ^=argγ∈Γminj=0∑Nv−1DManhattan(v^j,vγ(j)).(5)
DManhattan(v^j,vγ(j))D_{\text{Manhattan}}(\hat{v}_j, v_{\gamma(j)})DManhattan(v^j,vγ(j)) 是预测点集 V^\hat{V}V^ 的第 jjj 个点与真实值点集 VVV 的第 γ(j)\gamma(j)γ(j) 个点之间的曼哈顿距离。
3.3 训练损失
MapTR 基于最优的实例级和点级分配(π^\hat{\pi}π^ 和 {γ^i}\{\hat{\gamma}_i\}{γ^i})进行训练。损失函数由三部分组成:分类损失、点对点损失和边方向损失:
L=λLcls+αLp2p+βLdir,(6) L = \lambda L_{\text{cls}} + \alpha L_{\text{p2p}} + \beta L_{\text{dir}}, \quad (6) L=λLcls+αLp2p+βLdir,(6)
其中 λ,α\lambda, \alphaλ,α 和 β\betaβ 是用于平衡不同损失项的权重。
分类损失。利用实例级最优匹配结果 π^\hat{\pi}π^,每个预测地图元素都被分配了一个类别标签。分类损失是一个 Focal Loss 项,公式如下:
Lcls=∑i=0N−1LFocal(p^π^(i),ci).(7) L_{\text{cls}} = \sum_{i=0}^{N-1} L_{\text{Focal}}(\hat{p}_{\hat{\pi}(i)}, c_i). \quad (7) Lcls=i=0∑N−1LFocal(p^π^(i),ci).(7)
点对点损失。点对点损失对每个预测点的位置进行监督。对于索引为 iii 的每个真实值实例,根据点级最优匹配结果 γ^i\hat{\gamma}_iγ^i,每个预测点 v^π^(i),j\hat{v}_{\hat{\pi}(i),j}v^π^(i),j 被分配一个真实值点 vi,γ^i(j)v_{i,\hat{\gamma}_i(j)}vi,γ^i(j)。点对点损失定义为每个分配点对之间计算的曼哈顿距离:
Lp2p=∑i=0N−11{ci≠∅}∑j=0Nv−1DManhattan(v^π^(i),j,vi,γ^i(j)).(8) L_{\text{p2p}} = \sum_{i=0}^{N-1} \mathbb{1}_{\{c_i \neq \emptyset\}} \sum_{j=0}^{N_v-1} D_{\text{Manhattan}}(\hat{v}_{\hat{\pi}(i),j}, v_{i,\hat{\gamma}_i(j)}). \quad (8) Lp2p=i=0∑N−11{ci=∅}j=0∑Nv−1DManhattan(v^π^(i),j,vi,γ^i(j)).(8)
边方向损失。点对点损失仅监督折线和多边形的节点点,而未考虑边(相邻点之间的连接线)。为了准确地表示地图元素,边的方向非常重要。因此,我们进一步设计了边方向损失,以在高阶边水平上监督几何形状。具体而言,我们考虑配对预测边 e^π^(i),j\hat{e}_{\hat{\pi}(i),j}e^π^(i),j 和真实值边 ei,γ^i(j)e_{i,\hat{\gamma}_i(j)}ei,γ^i(j) 的余弦相似度:
Ldir=−∑i=0N−11{ci≠∅}∑j=0Nv−1cosine_similarity(e^π^(i),j,ei,γ^i(j)), L_{\text{dir}} = - \sum_{i=0}^{N-1} \mathbb{1}_{\{c_i \neq \emptyset\}} \sum_{j=0}^{N_v-1} \text{cosine\_similarity}(\hat{e}_{\hat{\pi}(i),j}, e_{i,\hat{\gamma}_i(j)}), Ldir=−i=0∑N−11{ci=∅}j=0∑Nv−1cosine_similarity(e^π^(i),j,ei,γ^i(j)),
e^π^(i),j=v^π^(i),j−v^π^(i),(j+1) mod Nv, \hat{e}_{\hat{\pi}(i),j} = \hat{v}_{\hat{\pi}(i),j} - \hat{v}_{\hat{\pi}(i),(j+1)\bmod N_v}, e^π^(i),j=v^π^(i),j−v^π^(i),(j+1)modNv,
ei,γ^i(j)=vi,γ^i(j)−vi,γ^i((j+1) mod Nv).(9) e_{i,\hat{\gamma}_i(j)} = v_{i,\hat{\gamma}_i(j)} - v_{i,\hat{\gamma}_i((j+1)\bmod N_v)}. \quad (9) ei,γ^i(j)=vi,γ^i(j)−vi,γ^i((j+1)modNv).(9)
3.4 架构
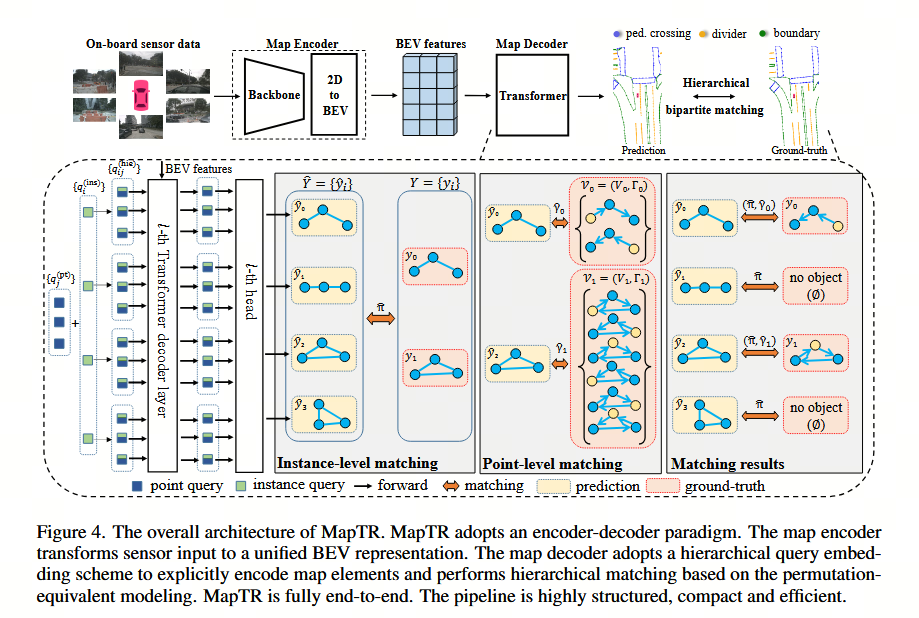
图 4. MapTR 的整体架构。MapTR 采用编码器-解码器范式。地图编码器将传感器输入转换为统一的鸟瞰图(BEV)表示。地图解码器采用分层查询嵌入方案来显式编码地图元素,并基于置换等价建模执行分层匹配。MapTR 是完全端到端的。该流程具有高度结构化、紧凑和高效的特点。
MapTR 设计了一种编码器-解码器范式。整体架构如图 4 所示。
输入模态。MapTR 以车载摄像头的环视图像作为输入。MapTR 也兼容其他车载传感器(如 LiDAR 和 RADAR)。将 MapTR 扩展到多模态数据既直接又简单。而且,得益于合理的置换等价建模,即使仅使用相机输入,MapTR 的性能也显著优于其他使用多模态输入的方法。
地图编码器。MapTR 的地图编码器从多个车载摄像头的图像中提取特征,并将特征转换为统一的特征表示,即 BEV 表示。给定多视图图像 I={I1,…,IK}I = \{I_1, \dots, I_K\}I={I1,…,IK},我们利用传统的骨干网生成多视图特征图 F={F1,…,FK}F = \{F_1, \dots, F_K\}F={F1,…,FK}。然后,2D 图像特征 FFF 被转换为 BEV 特征 B∈RH×W×CB \in \mathbb{R}^{H \times W \times C}B∈RH×W×C。默认情况下,我们采用 GKT (Chen et al., 2022b) 作为基本的 2D 到 BEV 转换模块,考虑到其易于部署特性和高效率。MapTR 兼容其他转换方法并保持稳定的性能,例如 CVT (Zhou & Krähennbühl, 2022)、LSS (Philion & Fidler, 2020; Liu et al., 2022c; Li et al., 2022b; Huang et al., 2021)、可变形注意力 (Li et al., 2022c; Zhu et al., 2021) 和 IPM (Mallot et al., 1991)。消融研究见表 4。
地图解码器。我们提出了一种分层查询嵌入方案,以显式编码每个地图元素。具体而言,我们定义了一组实例级查询 {qiins}i=0N−1\{q^{\text{ins}}_i\}_{i=0}^{N-1}{qiins}i=0N−1 和一组由所有实例共享的点级查询 {qjpt}j=0Nv−1\{q^{\text{pt}}_j\}_{j=0}^{N_v-1}{qjpt}j=0Nv−1。每个地图元素(索引为 iii)对应一组分层查询 {qijhie}j=0Nv−1\{q^{\text{hie}}_{ij}\}_{j=0}^{N_v-1}{qijhie}j=0Nv−1。第 iii 个地图元素的第 jjj 个点的分层查询公式化为:
qijhie=qiins+qjpt.(10) q^{\text{hie}}_{ij} = q^{\text{ins}}_i + q^{\text{pt}}_j. \quad (10) qijhie=qiins+qjpt.(10)
地图解码器包含多个级联的解码器层,用于迭代更新分层查询。在每个解码器层中,我们采用多头自注意力机制(MHSA)使分层查询相互交换信息(包括实例间和实例内)。受 BEVFormer (Li et al., 2022c) 的启发,我们采用可变形注意力 (Zhu et al., 2021) 使分层查询与 BEV 特征进行交互。每个查询 qijhieq^{\text{hie}}_{ij}qijhie 预测参考点 pijp_{ij}pij 的 2D 归一化 BEV 坐标 (xij,yij)(x_{ij}, y_{ij})(xij,yij)。然后,我们在参考点周围采样 BEV 特征并更新查询。
地图元素通常具有不规则形状,并且需要长距离上下文。每个地图元素对应一组具有灵活且动态分布的参考点 {pij}j=0Nv−1\{p_{ij}\}_{j=0}^{N_v-1}{pij}j=0Nv−1。参考点 {pij}j=0Nv−1\{p_{ij}\}_{j=0}^{N_v-1}{pij}j=0Nv−1 可以适应地图元素的任意形状,并为地图元素学习捕获信息丰富的上下文。
MapTR 的预测头很简单,由一个分类分支和一个点回归分支组成。分类分支预测实例类别得分。点回归分支预测点集 V^\hat{V}V^ 的位置。对于每个地图元素,它输出一个 2Nv2N_v2Nv 维向量,代表 NvN_vNv 个点的归一化 BEV 坐标。
5 结论
MapTR 是一种用于高效在线矢量化高精地图构建的端到端结构化框架,它采用简单的编码器-解码器 Transformer 架构和二分匹配策略,基于所提出的排列等价建模进行地图元素学习。大量实验表明,所提方法能够在具有挑战性的 nuScenes 数据集上精确感知任意形状的地图元素。我们希望 MapTR 能够作为自动驾驶系统的基础模块,推动下游任务(例如运动预测和规划)的发展。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 1
1 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)