机器学习 —— KNN算法(模型算法)
KNN算法思想
若一个样本在特征空间中的K个最相似的样本大多数术语某一个类别,则该样本也属于这个类别。
解决问题:
KNN算法既能解决分类(多数表决)问题,也能解决回归(计算平均值)问题
1.分类问题
(有监督)-> 有特征,有标签 标签是离散的 如:猫狗猪
<1> 算距离
<2> 升序排列
<3> 分类(多数表决) 如(1,1,1,1,0,0,0,1,1,1) 则值就是1
<4> 如果多数属于这个类别,未知样本也属于这个类别
2.回归问题
(有监督)-> 有特征,有标签,标签是连续的 如:房价-> 100万、50万、300万...
<1> 算距离
<2> 升序排列
<3> 回归(计算平均值) 如(10,20,30,40,50,60,70,80,90,100) 则值就是55
from sklearn.neighbors import KNeighborsClassifier,KNeighborsRegressor #分类、回归
#1.创建模型(算法)对象 分类
model1 = KNeighborsClassifier(n_neighbors=3) #离你最近的N个 这里是3个邻居
#2.准备训练集 二维的
x1_train = [[1],[2],[3],[4]]
y1_train = [0,0,0,1]
#3.准备测试集
x1_test = [[5]]
#4. 模型训练
#参1 训练集 特征, 参2 训练集 标签
model1.fit(x1_train, y1_train)
y1_test = model1.predict(x1_test)
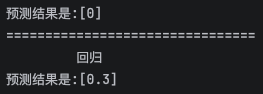
print(f'预测结果是:{y1_test}')
print('================================')
print(' 回归 ')
#1.创建模型(算法)对象 回归
model2 = KNeighborsRegressor(n_neighbors=3) #离你最近的N个 这里是3个邻居
x2_train = [[0, 0, 1],[1, 1, 0],[3, 10, 10],[4, 11, 12]]
y2_train = [0.1, 0.2, 0.3, 0.4]
x2_test = [[3, 11, 10]]
model2.fit(x2_train, y2_train)
y2_test = model2.predict(x2_test)
print(f'预测结果是:{y2_test}')ne_neighbors = 3 取最近三个。
x1_train 实际用到 [2],[3],[4] y1_train 实际用到 0,0,1
多数表决 所以结果是 0
x2 也是取得后三个, 也y2_train 实际取0.2,0.3,0.4
平均下y2_traion的值是0.3 所以平均值是0.3 是预测结果
算距离公式
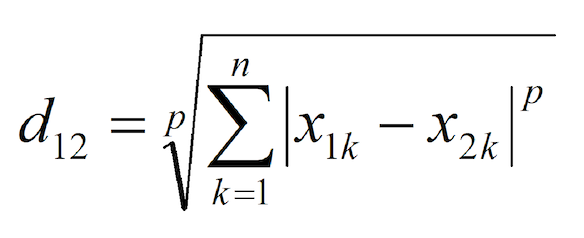
其中p 是一个变参数:
p = 1, 是就曼哈顿距离
p = 2, 就是欧式距离
p -> 无穷大, 就是切比雪夫距离
根据 p 的不同,闽氏距离可表示某一类种的距离
欧式距离:
p = 2 , n 表示几维
问题:ABCD 四个点 用 X = [[1,1],[2,2],[3,3],[4,4]],求AB距离
解析
<1> 二维 n = 2,因为一个子列表里面只有2个数据
<2> x1 = 1, x2 = 1, y1 = 2, y2 = 2
<3>套公式
 根号默认值是 2
根号默认值是 2
k = 1 到 n = 2的累加 ![]()
这里二维的。可以看做是 三角形的勾股定理
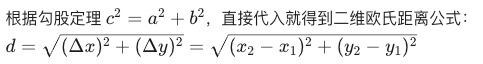
曼哈顿距离:
看完上面 欧式距离 那么 曼哈顿距离就更好理解
二维平面两点 a (x,y) 与 b (x,y) 间的曼哈顿距离 p = 1,n = 2
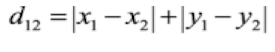
n维空间点 a(x11,x12,x13.....x1n) 与 b(x21,x22,x23......x2n)的曼哈顿距离
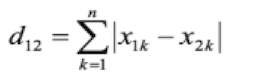
闵可夫斯基距离:
即闵氏距离 了解即可
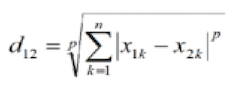

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)