AI | GPU 跑模型的可行性
一、显卡信息:核显 + 8GB独显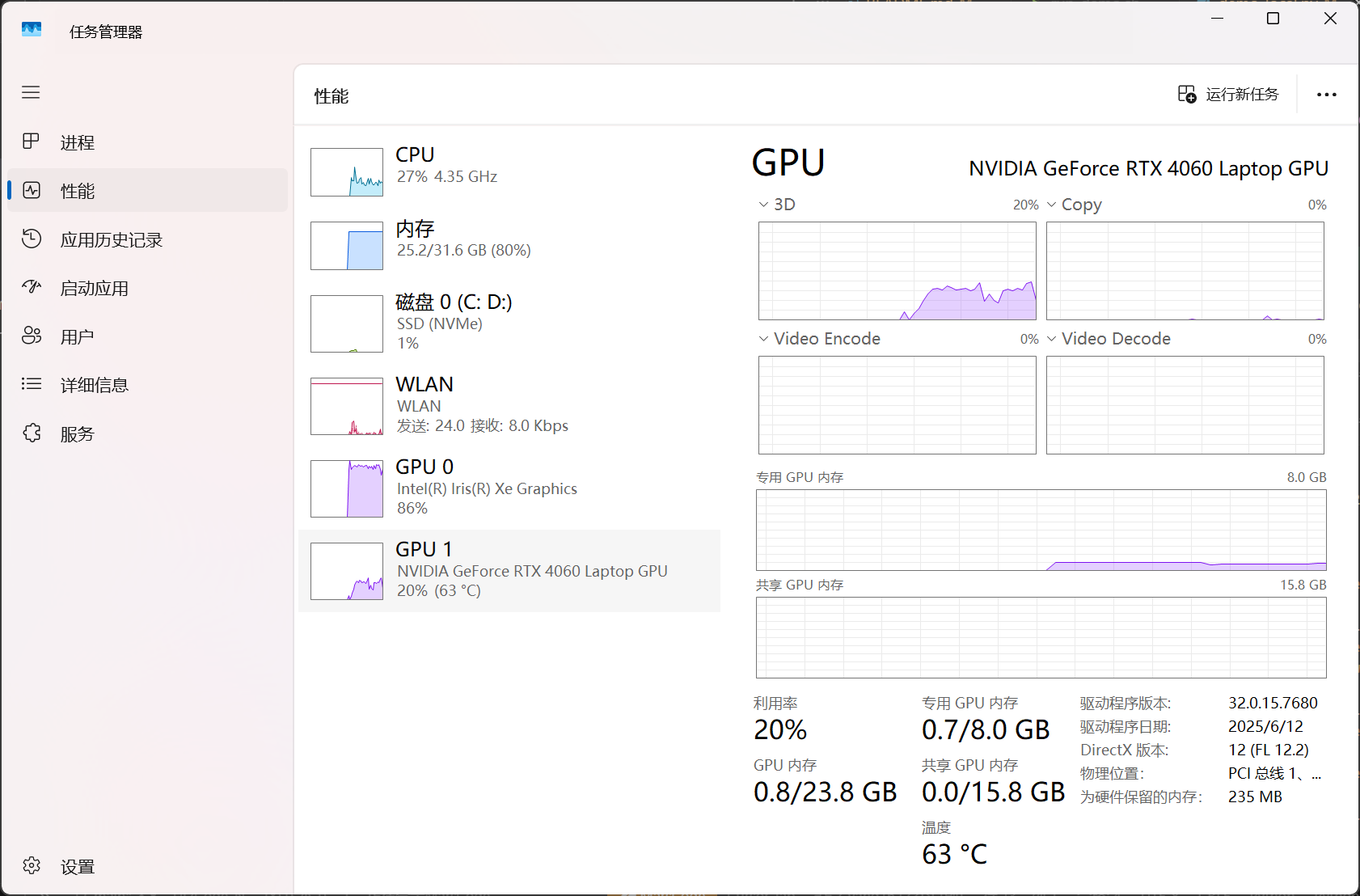
- GPU 1:NVIDIA GeForce RTX 4060 Laptop GPU
- 专用 GPU 内存(显存)= 8.0 GB(你理解的“8G”就是这个)
- “共享 GPU 内存 15.8 GB”是从系统内存借用的,不等于显存,速度也更慢
- GPU 0:Intel Iris Xe 是核显
至于“能不能运行当前的模型”,取决于你说的是哪种模型(LLM/文生图/语音等)和大小/量化方式:
- 一般结论:RTX 4060 Laptop 8GB 显存可以跑很多本地模型,但更大的模型需要更激进的量化、分层卸载到内存,或者直接不适合纯 GPU 跑。
常见经验(以本地大语言模型为例):
- 7B/8B:通常没问题(尤其是 4-bit 量化)
- 13B/14B:往往需要量化 + 可能部分上 CPU/内存,速度会明显下降
- 30B+:通常不太现实(仅靠 8GB 显存)
二、参数含义 | 8G 显卡对应可以跑的模型:
模型参数代表:
- 9B = 9 Billion parameters = 90 亿参数
- 每个参数通常是 16 bit (FP16/BF16) 或 32 bit(FP32)
- 粗算:90 亿参数 × 2 字节 ≈ 18 GB 显存,仅权重就超出你 8GB 了,所以需要 offload 或量化
如果它确实是两个 9B(比如一个负责“看图/理解”,一个负责“写代码”),那在你这张 RTX 4060 Laptop 8GB 上结论基本是:
原生 FP16/BF16 基本跑不动:单个 9B 仅权重就大约 9e9×29e9×2 字节 ≈ 18GB 显存,更别说还要 KV cache 和中间激活;两个就更不可能。
4bit/8bit 量化 才有机会:
- 单个 9B 4bit 通常显存占用大概 5–7GB(看实现/是否含额外模块/分辨率/上下文长度)。
- 两个 9B 同时常驻显存 大概率还是超过 8GB,除非做得非常极限、并且强力裁剪上下文/分辨率/关闭多余模块。
可行的运行方式(更现实):
- 串行加载:一次只把一个 9B 放到 GPU,用完卸载再加载另一个(慢,但能跑)。
- 一上 GPU、一上 CPU(或部分 offload):能跑但会明显变慢,且吃内存。
- 换更小模型/单模型版本:体验通常最好。
如果你把项目里模型的实际名称/加载方式贴一下(例如 demo_local.py 里是 from_pretrained(...) 还是走 API、是否有 load_in_4bit / device_map),我可以直接判断:你现在这套代码在 8GB 上能否跑通,以及该改哪些参数最省事。
三、UI2Code模型:
实际加载方式:仓库里的 demo/demo_local.py 实际上只加载一个模型(zai-org/UI2Code_N,README 也写它基于 GLM-4.1V-9B-Base)。
SFT 和 RL(更准确叫 RLHF/GRPO/DPO 等)通常是同一底座模型的不同训练阶段/不同权重版本,推理时一般只加载其中一个 checkpoint。
脚本加载(关键点):
- torch_dtype=torch.bfloat16(基本等同 FP16 级别显存压力)
- device_map="auto"(优先塞进 NVIDIA CUDA 显卡,不够就会拆到 CPU;不会用 Intel 核显来分担)
- max_new_tokens=8192(生成很长,KV cache 很吃显存)
结论:在你 4060 Laptop 8GB 上“行不行”?—— 不行!
- 按当前脚本(BF16 + 8192 tokens)大概率不行/很容易爆显存,即使勉强跑起来也可能非常慢或不稳定。
- 不是“核显+独显一起跑”:PyTorch/CUDA 基本只用 NVIDIA 独显;Intel 核显不会自动参与分摊。
能跑通的路线:
- 路线 A(最推荐,最快跑通):用 API 方式复现
你仓库里 demo/demo_web.py 就是走 OpenAI 兼容 API 的思路——把模型部署在显存更大的机器/服务器上,本机只当客户端。
没有大机器 / 云服务还有没戏?
- 便宜的云 GPU(比如 24GB / 48GB 显存的 A10、L40S、A100 等),只在要跑的时候开机,用完关机。
- 本机通过 openai 兼容 API 调用云端模型(就像你 demo_web.py 里那样),本地几乎不占显存。
- 典型平台:国外有 RunPod、Vast.ai、Lambda、Paperspace 等,国内也有不少云 GPU 服务(不点名)。
如果你暂时不想折腾云,也可以先走 B/C 在本机体验一个“能跑但可能慢/略降质”的版本。
- 路线 B(本机硬跑,但会慢):CPU offload + 降低生成长度
- 把 max_new_tokens 从 8192 降到 512/1024/2048(这是最立竿见影的显存开关)
- 允许 device_map="auto" 把部分层放到 CPU(能跑但慢)
- 降低生成长度,是指 降低一次性 “能生成的最长长度”,模型不会变“笨”。
- 对于 UI → HTML/CSS 这种任务,很多场景 1024–2048 tokens 就够用,再长也基本很难用完 8192。→ 【tokens 改 2048】
- 路线 C(本机更像“能用”):4bit/8bit 量化加载
需要引入量化依赖(常见是 bitsandbytes + accelerate),然后用 4bit 配置加载;是否能在你环境直接顺利装好取决于 Windows/CUDA 组合,但这是 8GB 上想跑 9B 最常见的办法。
量化依赖是指什么?
量化 = 把权重从 16bit → 8bit / 4bit 存储和计算,以用更少显存换一些精度。
常见做法(以 Transformers 为例):
① 安装库:
- bitsandbytes:最常见的 8bit/4bit 量化推理库
- 搭配 transformers + accelerate 使用
② 加载时写类似(示例):
from transformers import AutoModelForCausalLM, BitsAndBytesConfig quant_config = BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_compute_dtype=torch.float16, bnb_4bit_use_double_quant=True, bnb_4bit_quant_type="nf4", ) model = AutoModelForCausalLM.from_pretrained( MODEL_ID, quantization_config=quant_config, device_map="auto", )
对你来说,量化的意义是:
- 原来 18GB 才放得下的 9B,在 4bit 量化后可能 6–8GB 左右,配合减 tokens 和部分 offload,有机会在 8GB 卡上跑起来。
- 代价是:生成细节、鲁棒性略有下降,但一般仍可用。
“还能复现这个模型吗?”
- 能复现:但8GB 显存通常需要走 路线 A(远端部署)或 路线 C(量化)/ 路线 B(offload + 降 tokens,速度换可运行)。
- 如果你说的“两个 9B(SFT 和 RL)”是指 HF 上有两个权重版本:你一次选一个加载即可,不需要也不应该两个同时常驻。
改到“8GB 尽量能跑”的版本:
我可以把 demo/demo_local.py 改成可选 4bit 量化 + 自动降 max_new_tokens + 更稳的显存配置。你更想要哪条路线:B(不加依赖,先跑通)还是 C(加量化依赖,尽量跑得动)?
四、论文路线:“系统工程 + 中间表示(UI Schema)+ 可交互迭代”
不改/少改模型训练,把 UI2Code^N 当作“黑盒生成器”,你在外面做一层可控、可评测、可演示的改造。
原因很现实:短周期、风险低、8GB 显存也能做(走 API/远端推理),而且论文叙事完整。
用现成 UI2Code_N + 你设计的 UI Schema + 系统/工具层改造
> 来实现“可视化前端代码生成与交互式修正系统”。
这条路线对于硕士论文是足够有工程深度和创新点的,也更可控。如果你愿意,下一步我可以帮你:
- 直接给出一个具体的 UI Schema JSON 草案,
- 再给一段示例:如何改当前 demo 的 prompt,让模型尝试输出这个 Schema。
方案 A:UI Schema 中间层 + 组件级生成
定义 UI Schema 层(JSON 格式)
写 schema → 代码的渲染器
demo 里展示:局部重渲染代码

方案 B:交互式修正循环 + 自动评测指标(不动代码生成结构)
循环(代码渲染-截图-对齐评分-再提示修复)
自动迭代、停止条件、对齐的指标
改动 demo 管线,需考虑 指标的可靠性
不要 复现/再训练 SFT/RL
建议:推理层 走 远端/API(如 仓库的 demo_web.py ),本机做 UI/管线/评测。
论文代码库改造的“硬成果”:UI Schema 规范 + Schema 编辑器/可视化 + 组件级重生成 + 自动评测脚本 + Demo。
任务:
定义 schema.json格式
模型 按格式输出(prompt 约束 + json 校验/自动修复)
交互编辑(Gradio:点选组件改文本/颜色/间距) → 局部重渲染
评测:文本一致性+基础布局指标


GPU 训
API 调

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)