AI Infra 深度解析:从算力底座到智能应用的技术桥梁
1. AI Infra的定义与边界
1.1 广义定义:支撑AI运行的完整技术栈
AI Infrastructure(AI基础设施)从广义上来说,是指能够使得AI系统运行的一切基础设施。这一概念涵盖了从底层硬件到顶层应用的完整技术栈,包括基础算力硬件(如GPU、NPU、TPU等各类加速芯片)、中间各层级的技术工具(如深度学习框架、分布式训练系统、推理优化引擎等)、以及顶层的各类软件平台(如模型开发平台、算力调度系统、MLOps工具链等)。根据2025年中国AI基础设施市场报告的定义,AI基础设施是支撑AI应用运行的硬件、软件和网络资源的集合,其核心要素包括数据、算法和算力三个维度,三者相互依存、缺一不可,共同构成了AI系统运行的基础环境。
1.2 狭义定义:连接算力与应用的技术桥梁
狭义的AI Infra更侧重于指代构建连接算力与智能应用的"技术桥梁"。它是从底层资源优化、工程效率提升到应用生态支撑的一整套软件生态系统,专注于解决"如何让AI跑得更好"这一核心问题。其核心价值可以概括为三个关键维度:第一是提升效率,通过优化计算资源利用率、改进并行策略、加速模型训练与推理过程来实现更高的吞吐量;第二是降低成本,通过减少硬件投入、降低能耗开销、提高资源复用率来实现经济效益的最大化;第三是补足功能,填补从硬件原始能力到应用实际需求之间的技术鸿沟,提供芯片厂商未能覆盖的软件能力。目前业内大多数提及AI Infra时,采用的正是这一狭义口径,聚焦于软件生态层面的技术创新与价值创造。
1.3 技术定位:承上启下的关键中间层
从技术架构的角度来看,AI Infra处于一个承上启下的关键位置,是整个AI技术栈中不可或缺的中间层。向下,它需要对接各种异构硬件设备,包括NVIDIA GPU、AMD GPU、华为昇腾NPU、寒武纪MLU、Google TPU等不同架构的加速芯片,以及InfiniBand、NVLink、RoCE等多种高速互联技术,通过硬件抽象层屏蔽底层差异,为上层提供统一的计算接口。向上,它需要支撑各类AI应用的开发与部署需求,包括大语言模型、多模态模型、推荐系统、自动驾驶等不同场景,提供标准化的开发框架、高效的训练工具和稳定的推理服务。AI Infra作为中间层的这一定位,使其成为实现"算力民主化"的关键技术支撑,让更多企业和开发者能够低门槛地使用先进的AI能力。
下图展示了AI技术栈的层次结构,清晰呈现了AI Infra在整个生态中的定位: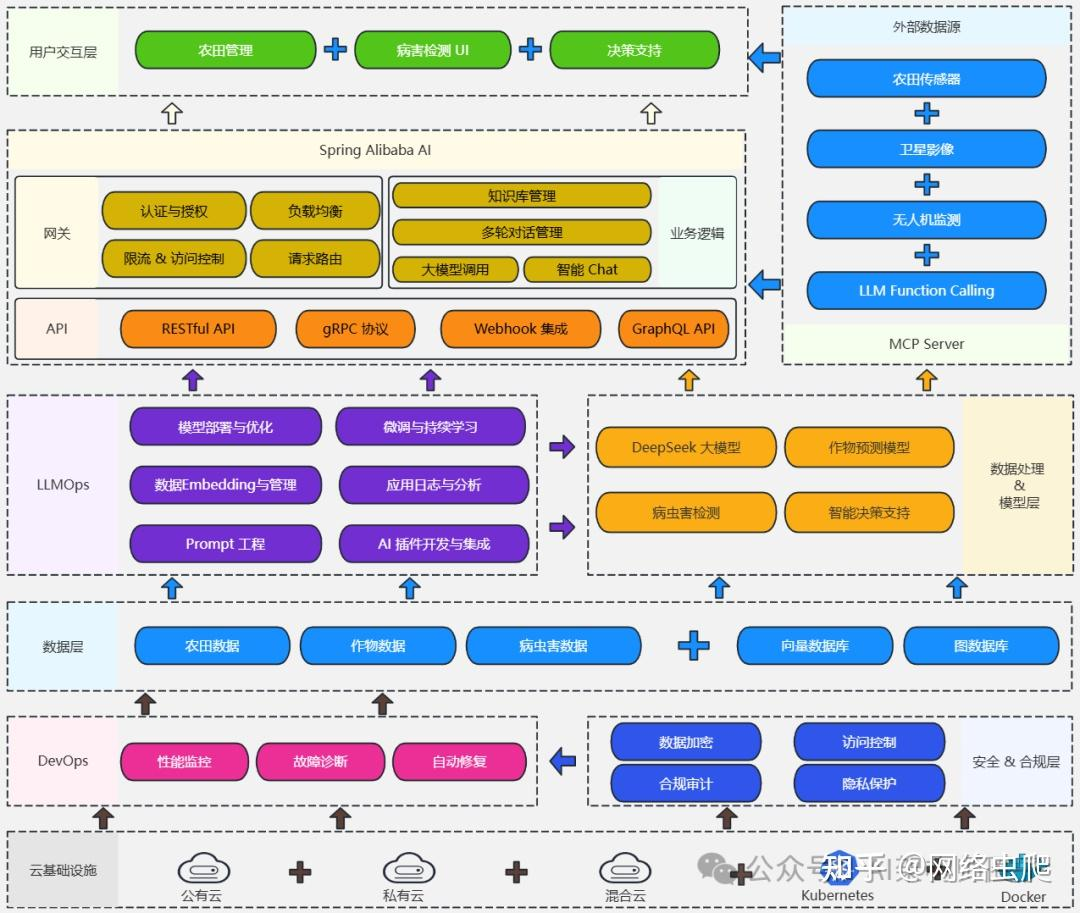
2. 生态构成:从硬件到应用的全栈体系
AI Infra软件生态是一个覆盖"硬件层、系统与底层、框架与工具、模型与算法、推理层、服务与管理、应用层"的全栈式体系,旨在打通从芯片算力到行业应用之间的完整技术链条,实现计算资源的高效调度、模型的快速部署和业务价值的全面释放。这一体系的每一层都承担着特定的技术职责,层与层之间通过标准化接口进行交互,共同构成了支撑AI大规模应用的完整基础设施。
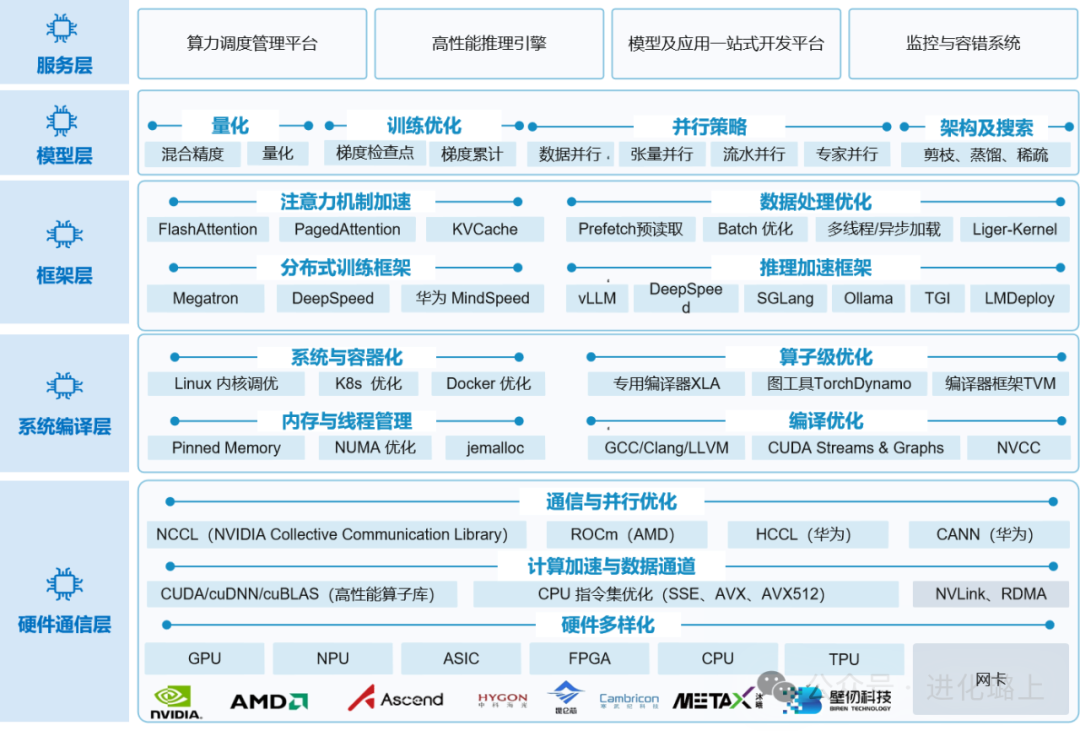
2.1 硬件层(Hardware Layer):算力生态的物理基石
硬件层作为整个算力软件生态系统的基石,承担着为上层提供强大、异构且可扩展计算底座的核心职责。这一层包括多种类型的计算设备,涵盖通用GPU(如NVIDIA A100/H100系列、AMD MI300系列)、AI专用加速芯片NPU(如华为昇腾910/310、寒武纪MLU370/590)、以及Google TPU、ASIC、FPGA等定制化硬件。除计算芯片外,高速互联技术同样是硬件层的关键组成部分,包括NVIDIA NVLink(单链路带宽可达900GB/s,实现GPU间高速直连)、InfiniBand网络(延迟低至微秒级,是大规模集群训练的首选)、以及基于以太网的RoCE技术(成本效益更优,适合中等规模部署)。此外,海量数据存储解决方案(如分布式文件系统、高性能SSD阵列、对象存储等)也是硬件层不可或缺的组成部分,为大规模数据集的读取和训练过程中Checkpoint的保存提供高效支撑。
| 硬件类型 | 代表产品 | 核心优势 | 典型应用场景 |
|---|---|---|---|
| 通用GPU | NVIDIA A100/H100, AMD MI300 | 生态完善、通用性强 | 大模型训练与推理 |
| 国产NPU | 华为昇腾910/310, 寒武纪MLU | 自主可控、政策支持 | 信创项目、国产替代 |
| 云端TPU | Google TPU v4/v5 | 专为张量优化 | 云端大规模训练 |
| 边缘芯片 | FPGA, 专用ASIC | 低延迟、低功耗 | 边缘推理、实时处理 |
下图展示了典型的GPU集群网络拓扑结构,说明了NVLink和InfiniBand在节点内和跨节点通信中的协同工作方式: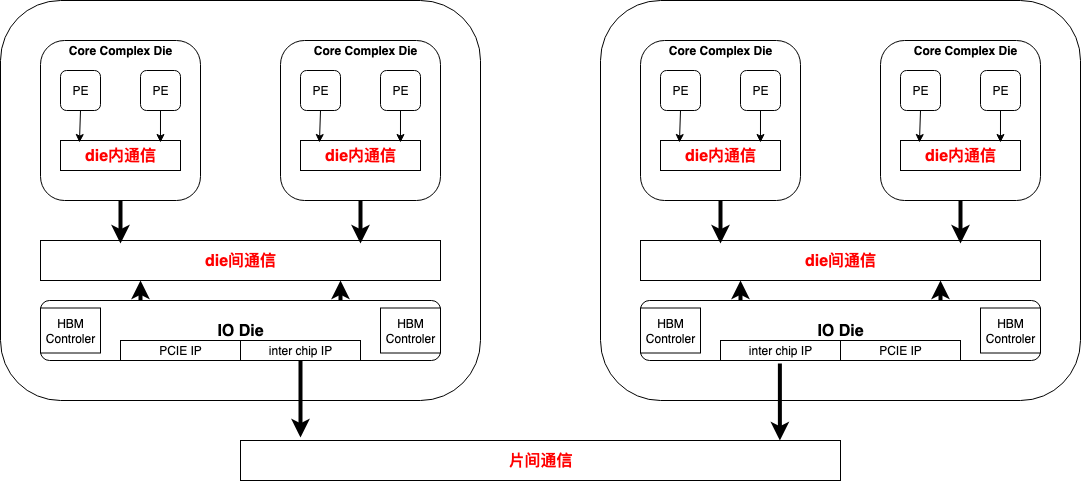
2.2 系统与底层(System & Infrastructure Layer):硬件抽象与资源管理
系统与底层负责操作系统、驱动程序及基础运行环境的构建,其核心目标是实现硬件抽象、资源统一管理和高并发处理能力。这一层的关键组件包括:操作系统与驱动程序,如针对AI优化的Linux发行版、国产操作系统、以及各芯片厂商提供的驱动和运行时环境(CUDA Runtime、ROCm、CANN等);并行与通信库,如MPI消息传递接口、NVIDIA NCCL集合通信库、华为HCCL等,这些库提供了高效的GPU间数据同步原语,是分布式训练的基础;内存与线程管理机制,包括GPU显存管理、统一内存寻址、CUDA Stream并发执行等;以及异构计算支持,实现CPU、GPU、NPU等不同计算单元的协同工作。通过这些组件的有机组合,系统与底层确保了不同硬件之间的无缝协作和高效资源共享,为上层框架和应用提供了稳定可靠的运行基础。其中,NCCL的AllReduce操作是分布式训练中最关键的通信原语,它将所有GPU上的梯度进行求和归约并广播到每个GPU,确保模型参数的同步更新。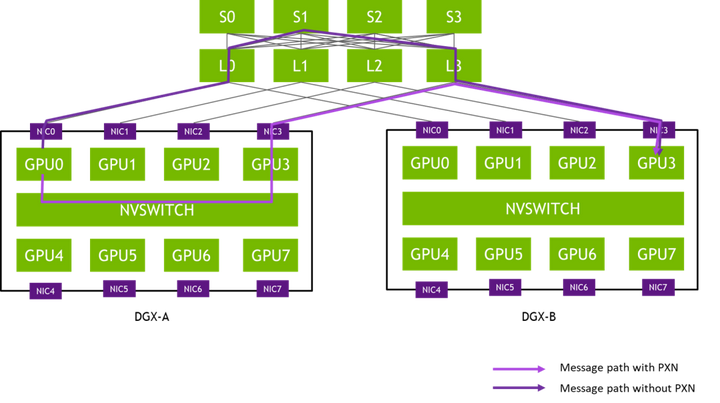
2.3 框架与工具层(Frameworks & Tools Layer):开发效率的核心支撑
框架与工具层提供了开发大模型所需的核心工具链,其根本目的是降低AI开发门槛,提升模型训练效率与跨平台兼容性。这一层的主要组件包括:深度学习框架(如PyTorch、TensorFlow、MindSpore、PaddlePaddle等),它们提供了自动微分、张量运算、模型定义等基础能力,其中PyTorch凭借其动态图特性和良好的开发体验,已成为大模型研发的事实标准;分布式训练工具(如PyTorch DDP、Horovod、DeepSpeed、Megatron-LM等),支持数据并行、模型并行、流水线并行等多种并行策略,使得在数百甚至数千张GPU上训练万亿参数模型成为可能;编译与算子优化工具,包括高性能算子库(如cuDNN、CANN)、AI编译器(如TVM、MLIR、XLA等),负责将高层模型定义转换为高效的底层执行代码;以及性能分析与调优工具(如NVIDIA Nsight、PyTorch Profiler等),帮助开发者识别性能瓶颈并进行针对性优化。
下图展示了三种主要的分布式训练并行策略及其组合方式:
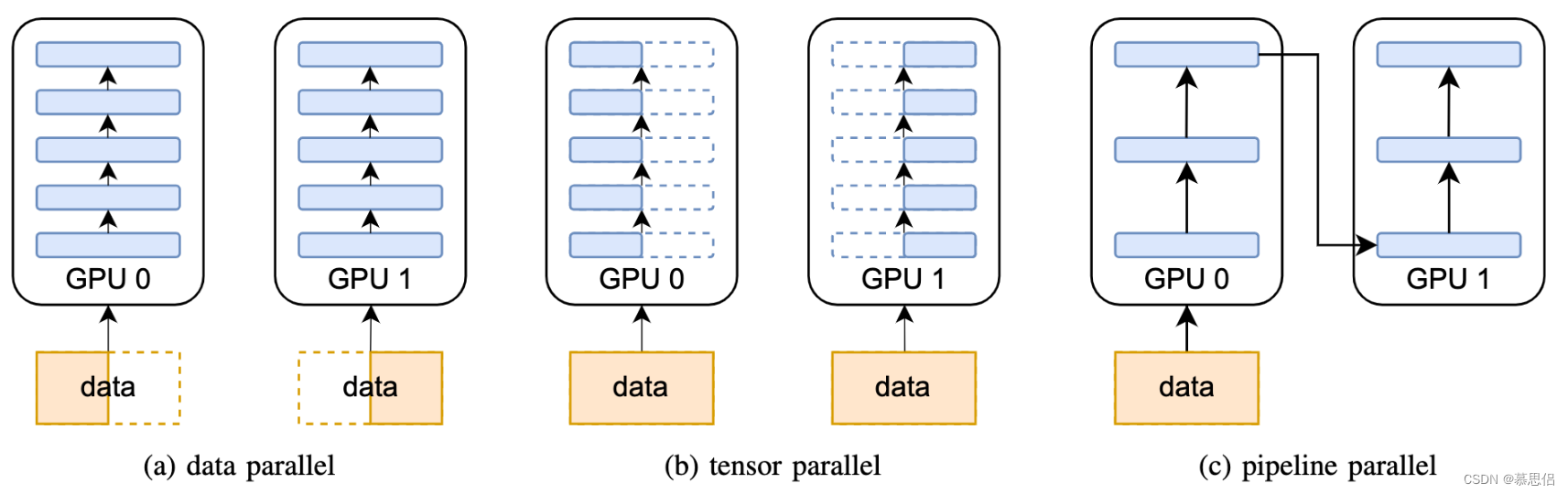
三种并行策略详解:
-
数据并行(Data Parallelism):将训练数据划分为多个子批次,分配到不同GPU上,每个GPU持有完整的模型副本,计算梯度后通过AllReduce同步。适合模型能放入单卡显存的场景。
-
模型/张量并行(Tensor Parallelism):将模型的参数矩阵切分到多个GPU上,每个GPU只持有部分参数。适合单层参数量巨大的模型,如GPT系列。
-
流水线并行(Pipeline Parallelism):将模型按层切分到不同GPU上,通过微批次(micro-batch)实现流水线式的并行计算,减少GPU空闲时间。
…详情请参照古月居

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)