GELU 激活函数深度解析:平滑激活范式、PyTorch 实战与大模型核心应用
摘要:GELU(Gaussian Error Linear Unit,高斯误差线性单元)是当前深度学习大模型时代的核心激活函数,凭借平滑非线性、梯度稳定、无神经元死亡的特性,全面替代 ReLU 成为 Transformer、GPT、LLaMA、BERT、ViT 等主流模型的标配激活函数。本文以通俗化视角解构 GELU 的核心逻辑,极简呈现数学原理,提供与 ReLU 对齐的 PyTorch 实战代码,并详解其核心优势与工业级应用场景,为深度学习模型开发与大模型微调提供实践指导。
关键词:GELU;激活函数;Transformer;大模型;PyTorch;深度学习
一、引言
在深度学习激活函数的演进中,ReLU 凭借简单高效成为隐藏层主流选择,但硬阈值截断、非平滑、神经元坏死等缺陷,在深层网络(尤其是 Transformer 架构)中会导致梯度不稳定、收敛速度慢等问题。
GELU 激活函数应运而生,它结合了高斯分布与线性单元的特性,实现了平滑、连续的非线性映射,完美适配大模型与深层 Transformer 的训练需求。如今,几乎所有主流大模型(GPT 系列、LLaMA、Qwen、BERT)均采用 GELU 作为核心激活函数,成为大模型时代的标准配置。
二、通俗理解:GELU 到底是什么?
我们用 **「平滑过渡」** 的逻辑,直观理解 GELU 与 ReLU 的核心区别:
- ReLU:像硬开关,输入≤0 直接归零(一刀切),输入 > 0 原样输出,粗暴且易出现神经元坏死;
- GELU:像渐变调光开关,输入为负数时缓慢衰减(不会直接归零),输入为正数时平滑激活,全程连续无断点。
打个比方:
- ReLU 对负输入:直接关闭阀门,信息完全丢失;
- GELU 对负输入:逐渐收窄阀门,保留微弱有效信息;
- 对正输入:两者都保留信息,但 GELU 更平滑,梯度传递更稳定。
核心结论:GELU 是 ReLU 的平滑升级版,保留了 ReLU 的核心优势,同时解决了它的所有缺陷。
三、极简数学原理(点到即止)
GELU 的数学定义极度简洁,无需复杂推导,仅需记住核心公式与物理意义:
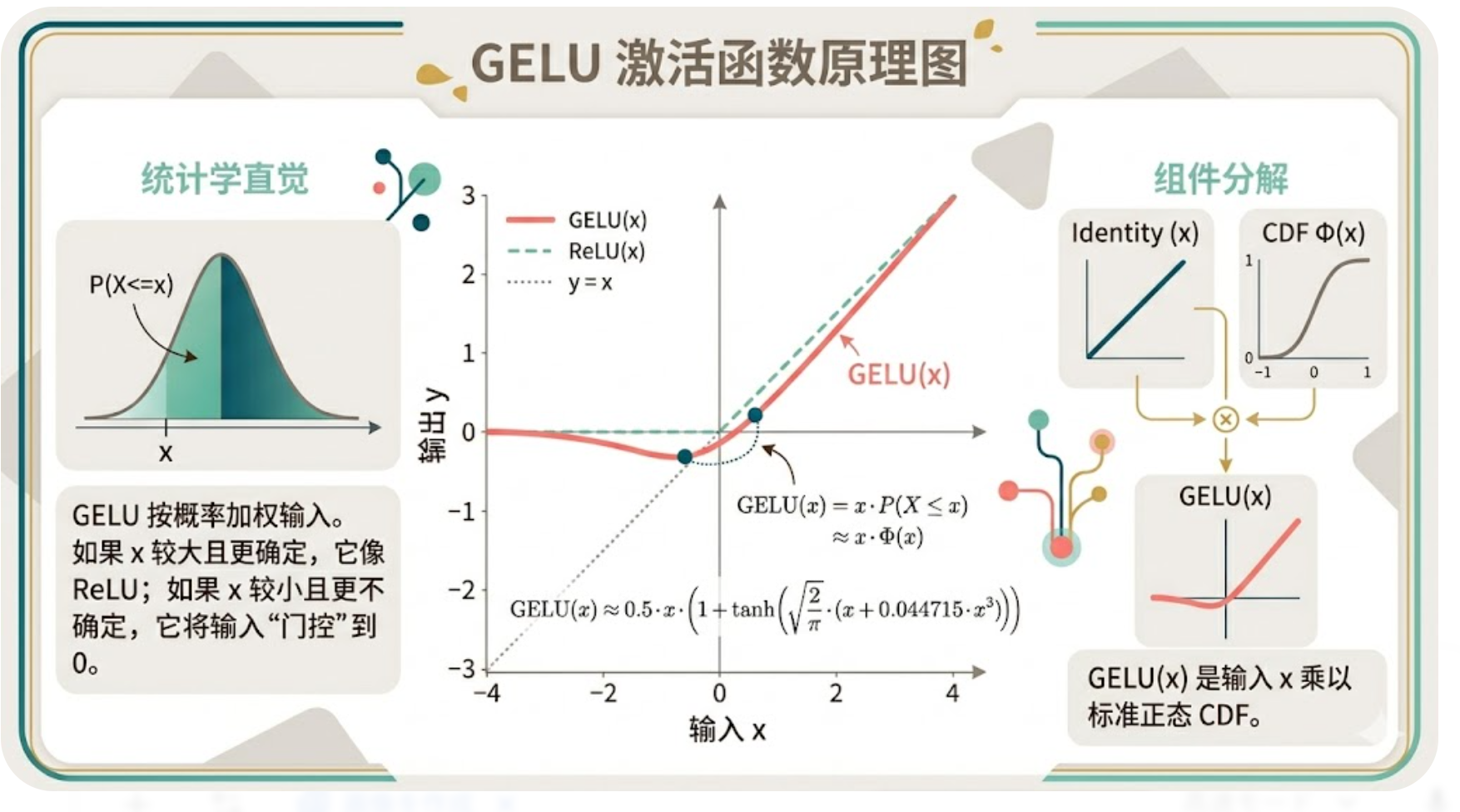
核心公式
GELU(x)=x⋅Φ(x)
其中 Φ(x) 为高斯累积分布函数,代表输入 x 服从正态分布的概率权重。
白话解释
- 不做硬截断,对所有输入赋予平滑的概率权重;
- 输入越大,权重越接近 1,输出越接近 x;
- 输入越小,权重平滑衰减,输出缓慢趋近于 0;
- 全程连续可导,无梯度突变、无神经元死亡。
四、PyTorch 代码实战(可直接运行)
本章节代码完全对齐你提供的 ReLU 代码风格,分为基础调用、结合线性层、完整模型集成三部分,开箱即用。
环境依赖
import torch
import torch.nn as nn
import torch.nn.functional as F
4.1 基础调用(独立使用 GELU)
# 输入张量(与ReLU测试输入完全一致)
x = torch.tensor([-3., 2.5, 0, 4., -1.2])
# GELU激活函数调用
gelu_output = F.gelu(x)
print("PyTorch GELU基础输出:", gelu_output.numpy())
运行结果

4.2 结合线性层(模拟神经网络隐藏层)
# 定义线性层(输入维度5,输出维度3)
linear = nn.Linear(5, 3)
# 模拟2个样本,5维特征
x_batch = torch.randn(2, 5)
# 线性层 + GELU激活(大模型标准写法)
hidden_output = F.gelu(linear(x_batch))
print("\n隐藏层(线性层+GELU)输出:\n", hidden_output.detach().numpy())
print("输出形状:", hidden_output.shape) # 输出形状:(2, 3)
运行结果

4.3 完整小模型集成(Transformer 风格)
import torch
import torch.nn as nn
# 定义类Transformer前馈网络(GELU标准应用场景,教学专用)
class TransformerFFN(nn.Module):
def __init__(self, in_dim, hidden_dim):
super().__init__()
# 第一层线性变换:输入维度 → 隐藏层维度
self.fc1 = nn.Linear(in_dim, hidden_dim)
# 第二层线性变换:隐藏层维度 → 还原输入维度
self.fc2 = nn.Linear(hidden_dim, in_dim)
# GELU激活函数(大模型/Transformer标配)
self.act = nn.GELU()
def forward(self, x):
# 步骤1:第一层线性层计算
x_fc1 = self.fc1(x)
# 步骤2:GELU激活(核心步骤)
x_gelu = self.act(x_fc1)
# 步骤3:第二层线性层输出最终结果
x_output = self.fc2(x_gelu)
# 教学专用:返回所有中间结果
return x_fc1, x_gelu, x_output
# ===================== 教学测试(打印完整信息) =====================
# 初始化模型:输入维度8,隐藏层维度16
ffn = TransformerFFN(in_dim=8, hidden_dim=16)
# 构造测试输入:2个样本,每个样本8维特征(固定随机数方便教学)
torch.manual_seed(42)
test_input = torch.randn(2, 8)
# 前向传播,获取所有中间结果
fc1_out, gelu_out, final_out = ffn(test_input)
# ===================== 分步打印教学信息 =====================
print("="*60)
print("【教学演示】Transformer前馈网络 + GELU 工作流程")
print("="*60)
# 1. 原始输入
print("\n1. 原始输入张量:")
print("输入形状:", test_input.shape)
print("输入值:\n", test_input)
# 2. 第一层线性层输出
print("\n2. 第一层线性层(fc1)输出:")
print("形状:", fc1_out.shape)
print("输出值(前5个):\n", fc1_out[0][:5]) # 打印第一个样本的前5个值
# 3. GELU激活后输出(核心对比)
print("\n3. GELU激活后输出:")
print("形状:", gelu_out.shape)
print("输出值(前5个):\n", gelu_out[0][:5])
# 4. 最终输出
print("\n4. 第二层线性层(fc2)最终输出:")
print("最终输出形状:", final_out.shape)
print("最终输出值:\n", final_out)
print("="*60)
运行结果

五、GELU 的核心优势(为什么大模型都用它?)
- 平滑连续:全程可导,梯度传递稳定,深层网络收敛更快;
- 无神经元死亡:解决 ReLU 负输入梯度为 0 导致的神经元坏死问题;
- 高斯先验适配:符合神经网络权重的正态分布特性,大模型训练更稳定;
- 兼容 ReLU 优点:保留稀疏激活特性,计算效率高,无额外性能损耗。
六、GELU 核心应用场景
GELU 是大模型与 Transformer 架构的专属激活函数,核心应用覆盖全领域:
1. 自然语言处理(NLP)
- 大语言模型:GPT、LLaMA、Qwen、ChatGLM;
- 预训练模型:BERT、RoBERTa、ALBERT;
- 文本生成、语义理解、机器翻译。
2. 计算机视觉(CV)
- 视觉 Transformer(ViT)、Swin Transformer;
- 图像分类、目标检测、图像分割。
3. 多模态模型
- CLIP、Flux、Stable Diffusion 等文生图 / 图生文模型。
4. 通用深度学习
- 深层神经网络、小样本学习、联邦学习。
七、GELU vs ReLU 选型对比
表格
| 特性 | ReLU | GELU |
|---|---|---|
| 平滑性 | 非连续、硬截断 | 连续平滑、无断点 |
| 神经元死亡 | 存在 | 无 |
| 梯度稳定性 | 弱 | 强 |
| 适用场景 | 轻量 CNN、传统网络 | Transformer、大模型 |
| 工业级标配 | 传统网络 | 现代大模型、Transformer |
选型准则:轻量传统网络用 ReLU,大模型 / Transformer 必用 GELU。
八、总结
GELU 激活函数是深度学习激活范式的里程碑式升级,它以极简的设计解决了 ReLU 的核心缺陷,凭借平滑、稳定、高效的特性,成为大模型时代的工业标准。
本文从通俗视角解构 GELU 逻辑,极简呈现数学原理,提供对齐 ReLU 风格的 PyTorch 实战代码,覆盖基础调用、层集成、模型应用全流程。在大模型开发、Transformer 搭建、预训练模型微调中,GELU 是无需犹豫的首选激活函数。
参考资料
- PyTorch 官方文档:torch.nn.GELU
- Gaussian Error Linear Units (GELU) 原始论文
- Transformer、BERT、GPT 官方实现

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)