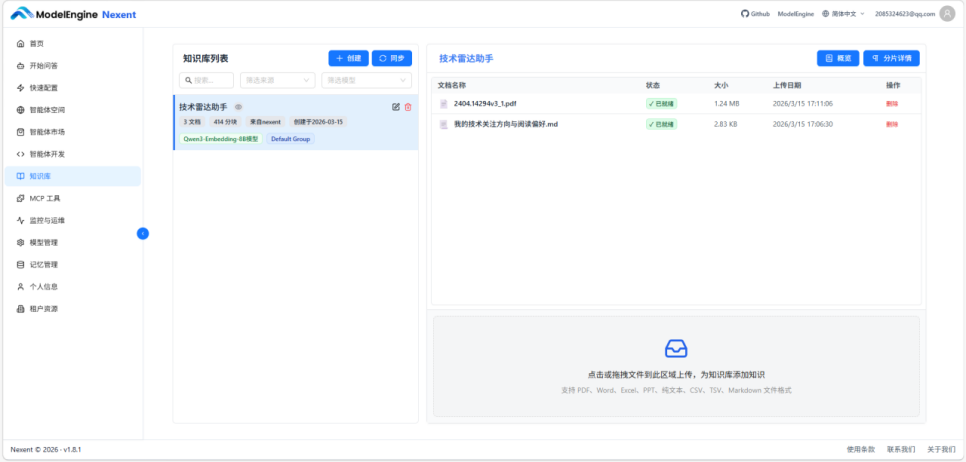
告别信息过载:基于 Nexent 构建开发者技术雷达智能体
告别信息过载:基于 Nexent 构建开发者技术雷达智能体
我有一个坏习惯:每天早上打开电脑,第一件事是刷 GitHub Trending,然后切 ArXiv,看一眼 HuggingFace Daily Papers,再去 X 上扫一圈技术账号,最后回来看看 Reddit 的 r/MachineLearning 有没有讨论热帖。这一套流程走完,一小时没了。
更麻烦的是,这还不算完。信息源是分散的,过滤是靠感觉的,有没有遗漏掉值得关注的东西,完全凭运气。上周 Meta 发了一篇推理优化的论文在 ArXiv,我是三天后才在别人的朋友圈看到的。
这种状态不是个别现象。技术信息的爆炸速度和人的注意力之间的错配,已经是很多开发者的默认痛点。LLM 领域尤其夸张,隔两周不跟进,感觉就像脱节了半年。
想用 AI 来帮忙聚合这些信息?方案不是没有。n8n 可以做,但要配置 Webhook、写 workflow,对不熟悉低代码工具的人门槛挺高。自己写一个爬虫加摘要脚本?能用,但维护成本在那里,工具更新了还得跟着改。还有一些专门的 AI 信息流产品,功能有限,而且往往是黑箱,没法按自己的需求定制偏好。
几周前我在 GitHub 上看到了 Nexent,介绍里有一句话直接吸引了我:"一个提示词,无限种可能。"——描述需求,自动生成智能体,不需要编排,不需要拖拉拽。我把这件事记了下来,决定花一个周末认真试一试,看能不能把这个每天浪费一小时的信息拼图,变成一个真正好用的技术雷达助手。
Nexent 是一个开源智能体平台,目前已发布 v1.8.1 版本。有两种方式上手:一是用官方提供的在线试用环境 try.nexent.tech,注册即用;二是自行拉取 GitHub 仓库用 Docker Compose 本地部署,更方便。

Nexent 有两种上手方式:在线试用环境 try.nexent.tech 注册即用,适合快速摸底;本地用 Docker Compose 拉起来,数据持久、响应更快,适合长期使用。
我两种都用了。在线版方便,但偶尔会有数据丢失的情况,配好的模型和知识库刷新后可能要重配;本地部署之后这个问题就消失了,而且因为少了网络中转,对话响应明显快了一截。如果你打算认真用超过一天,建议直接走本地部署,一次配好之后省心很多。Docker 部署的步骤官方文档写得很清楚,照着来半小时内能跑起来。
界面进去,左侧导航的模块分布是这样的:
- 模型管理:接入各家 API,配置系统默认模型
- 知识库:上传文档,构建可检索的个人语料库
- MCP 工具:接入外部工具,赋予智能体实时感知能力
- 智能体开发:核心功能,用自然语言描述 → 自动生成提示词 → 调试发布
- 智能体市场:安装他人发布的现成智能体
- 记忆管理:配置跨对话记忆,让智能体记住用户偏好
这个模块划分本身逻辑挺清晰,每一块对应一个具体的配置环节,新手按顺序往下走基本不会迷路。
从模型管理开始。我用的是硅基流动(SiliconFlow)作为推理后端,理由很简单:Qwen3 系列模型在上面有托管,价格合理,API 兼容 OpenAI 格式,接入成本低。
进入"模型管理"页面,点击"添加模型"。需要填的字段有四个:
- 模型名称:格式必须是 提供商/模型名,比如 siliconflow/Qwen/Qwen3.5-Plus
- API URL:填 https://api.siliconflow.cn/v1(注意这里的 /v1 后缀,下面会讲为什么这个地方容易踩坑)
- API Key:从硅基流动控制台复制
- 模型类型:选大语言模型
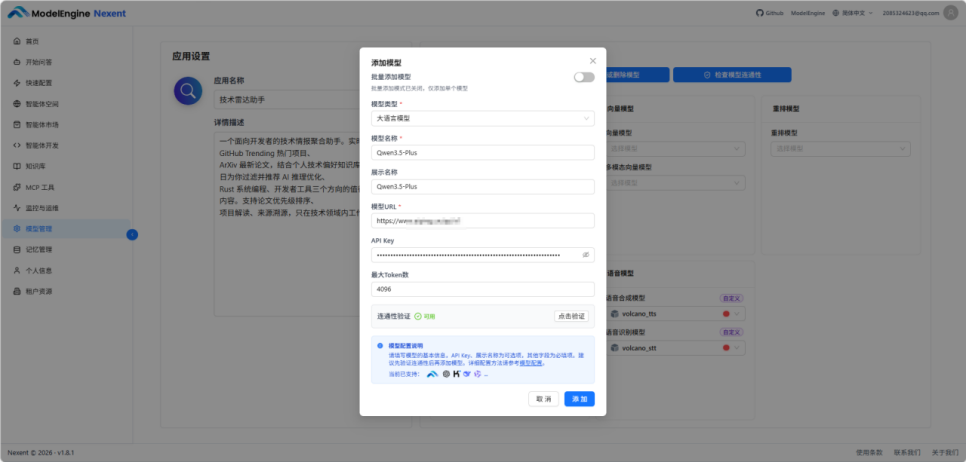
填完之后点"连通性验证",如果一切正常,会显示绿色的"连接成功",模型就进入了可用列表。
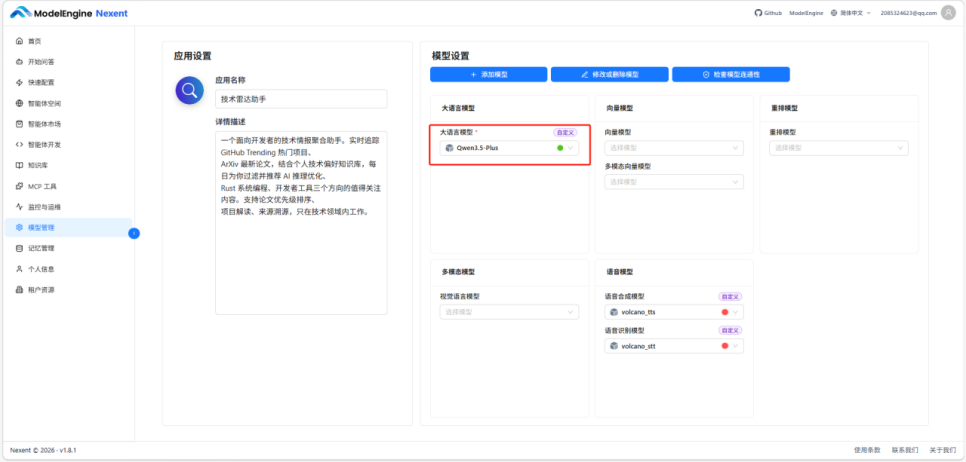
如果只是接一两个模型,单个填就行。但我想同时跑几个模型做横向对比——Qwen3.5-Plus、Qwen3-32B、Qwen2.5-Coder 各有侧重——逐个填写太低效。
批量导入的逻辑是:填入 API URL 和 Key,点击"拉取模型列表",系统会自动把该供应商下的全部可用模型枚举出来,你再逐个打开开关,选出要启用的那些。对于需要接多模型做对比测试的场景,这个方式省了大量重复操作。
接完模型之后还要配置"系统模型",也就是 Nexent 平台各个功能默认调用哪个模型。我的配置:
- 基础模型(LLM):Qwen/Qwen3.5-Plus
- 向量模型(Embedding):Qwen/Qwen3-Embedding-8B
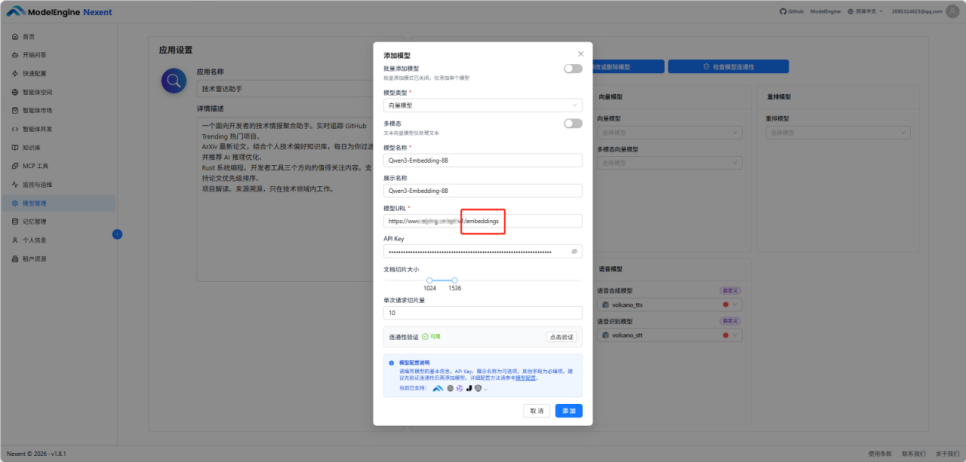
这里有一个实际踩过的坑,记一下:
|
踩坑:URL 后缀格式不对,连通性验证只说"连接失败" |
LLM 的 API URL 后缀是 /v1,向量模型的 URL 后缀是 /v1/embeddings,这两个必须分开填。我第一次把向量模型的 URL 也填成了 /v1,点验证,显示"连接失败",没有任何详细报错,就一行字。我排查了将近二十分钟,对比文档才发现后缀写错了。改成 /v1/embeddings 之后立刻通过。这个坑其实官方文档里是有说明的,只是容易被跳过。Nexent 的用户指南:https://doc.nexent.tech/zh/user-guide/home-page.html写得比较完整,建议在正式上手之前先通读一遍。
这个问题的根因在于错误提示太粗,只有"失败"两个字,没有具体是 HTTP 哪个状态码、请求路径是什么。对于有经验的人靠猜能查出来,对新用户就是一堵墙。官方后续如果能在错误提示里加上请求 URL 和返回码,体验会好很多。
知识库解决的不是"每次都要重复说偏好"的问题——那个用系统提示词就够了。它真正的价值在于:把提示词装不下的大量参考内容变成可检索的上下文。
我的场景里有两份文档需要让智能体参考:一份手写的技术偏好说明,一篇 30 页的 LLM 推理综述。这些东西塞进提示词根本装不下,放知识库里,智能体每次按需检索相关片段注入上下文,覆盖面更宽,也不压缩推理空间。
知识库的意义在于:把这些偏好信息结构化存储,让智能体每次检索时自动召回,而不是依赖提示词里的上下文。
我准备了两份文档:
- 技术偏好说明(Markdown 格式):手写的,大约 800 字,列出我关注的技术方向、典型项目类型、不想看到的内容类别(比如纯科普文章、没有代码的产品新闻)
- 一份 LLM 推理综述(PDF 格式):从 ArXiv 下载的,约 30 页
两份文件上传后,系统会依次经历三个状态:解析中 → 入库中 → 已就绪。
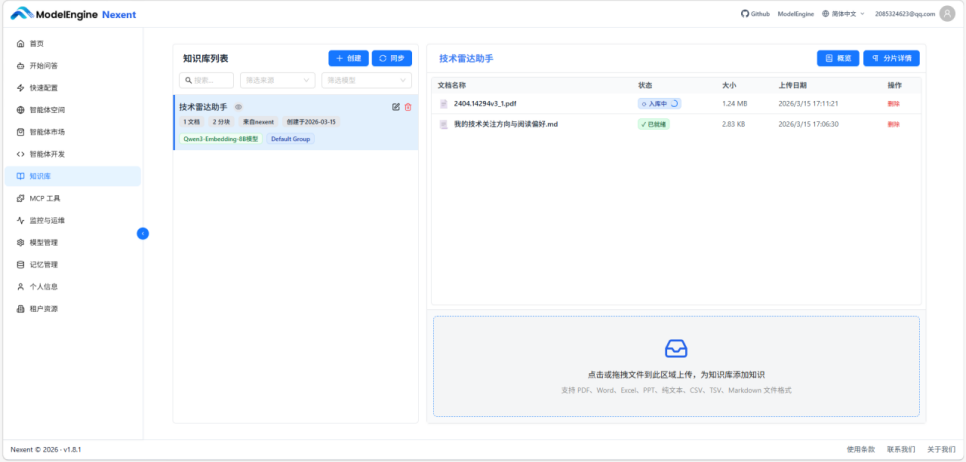
Markdown 文件处理速度很快,不到 10 秒进入就绪。PDF 慢很多,那份 30 页的综述等了将近 2 分钟。文档越大、排版越复杂,处理时间就越长,这在预期之内。
知识库里有一个功能叫"自动总结",点开文档条目可以看到 Nexent 对这份文档自动生成的摘要。乍一看觉得不重要,但这个总结的质量直接影响到多知识库场景下的检索路由精度。
简单说:当智能体同时挂载了多个知识库时,它在检索前会先根据总结判断"这个问题应该去哪个知识库找"。总结写得准,路由就准;总结写得模糊,很可能检索到错误的库,甚至检索不到任何相关内容。
我对比了两份文档的总结质量:
- Markdown 文档的总结:结构清晰,准确抓住了"LLM 推理优化"和"Rust 生态"两个核心主题,关键词提取精准
- PDF 综述的总结:相对笼统,提取出的是"人工智能、语言模型、深度学习"这类泛化词,细粒度不够
原因我猜测是 PDF 里的排版干扰——多栏布局、公式、参考文献列表——导致文本提取时结构被打乱,总结模型拿到的是一堆碎片化文字,质量自然不如结构化的 Markdown,可以使用更好的大模型比如Claude 4.6、ChatGPT 5.2、Deepseek 3.2这种,就能很好的避免这种情况的发生。
这个现象的实践启示是:上传给知识库的文档,越结构化越好。能用 Markdown 写的就不要用 PDF,Markdown 的总结质量肉眼可见地优于排版复杂的 PDF。如果确实需要上传 PDF,提前做好格式清理,去掉多栏布局和无关的页眉页脚,效果会好很多。
五、MCP 工具接入:用 GitMCP 赋予智能体实时感知能力
要做技术雷达助手,仅靠知识库里的静态文档是不够的——ArXiv 今天新出了哪些论文,模型的训练截止日期没法覆盖,必须依赖实时工具。
MCP 的配置入口不在左侧导航的"MCP 工具"页面——那个功能还没上线,目前显示"即将推出"——而是在智能体开发页面内,创建智能体时选工具那一步,右侧有个"MCP 配置"按钮,点开进去配置。
我直接去 ModelScope MCP 广场 找现成的,搜索框输入 arxiv,出来三个结果,选第一个 ArXiv AI搜索服务(@blazickjp,Hosted 类型,下载量 20.5m,是三个里最活跃的)。
点进服务详情页,找到"服务配置"标签,选 Remote 传输类型。这里有个前提:必须登录 ModelScope 账号才能看到 URL,未登录状态下这块是空的。登录后页面会生成一个专属的 SSE 地址,格式类似:
|
Plain Text |
把这个 URL 复制下来,填入 Nexent。
有一点要提前知道:这个 URL 24 小时后会失效,到期后需要重新回到 ModelScope 刷新获取新地址,你也可以选择设定为长期有效。这是 Hosted 服务的设计,不是 bug,但用的时候要留意,如果某天智能体突然调不到 ArXiv 数据,多半是 URL 过期了。
在 MCP 配置弹窗的"添加 MCP 服务器"区域这样填:
|
点击图片可查看完整电子表格 |
|

点添加后,界面顶部出现绿色提示"正在自动更新工具列表,请勿关闭页面或取消操作",等十几秒,工具同步进来,点"连通性校验"确认绿灯即可。
这里有个没有任何提示的坑:服务器名称只能包含英文字母和数字,下划线、空格、短横线全部不允许。我第一次填了 ArXiv_AI ,点添加之后没有报错,工具也没出现,静默失败,完全不知道哪里出了问题。翻文档找到原因,改成 ArXivAI 立刻通过。输入时如果有实时校验提示会省掉很多排查时间,这是目前体验上比较明显的一个缺口。
对于 npm 上发布的 MCP 包,Nexent 支持用 JSON 配置的方式启动一个容器化服务。我接入了 ArXiv 论文搜索工具 @blazickjp/arxiv-mcp-server:
|
JSON |
端口填 3010,点添加,然后等容器拉起来。这个过程大概需要 30 秒到 1 分钟,第一次因为需要拉取 npm 包,可能稍慢。容器启动后工具会自动出现在列表里。
这是整篇文章最核心的部分,也是 Nexent 最让我印象深刻的地方。
创建新智能体,首先选工具。我的技术雷达助手最终选了三个:

点击图片可查看完整电子表格
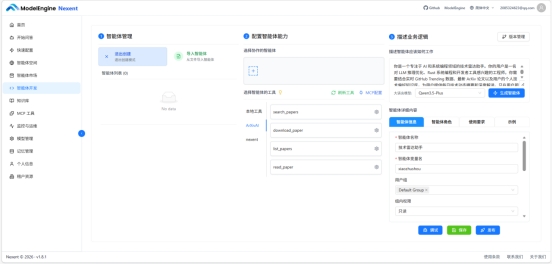
GitHub Trending 没有单独接 MCP,直接交给内置联网搜索处理——让智能体搜"GitHub Trending Rust today"效果完全够用,省去维护一个额外工具的麻烦。工具够用就行,不必为了配置丰富而多接没必要的服务。
工具选完,进入描述环节。描述框里我写了这段:
|
你是一个专注于 AI 和系统编程领域的技术雷达助手。你的用户是一名对 LLM 推理优化、Rust 系统编程和开发者工具感兴趣的工程师。你需要结合最新 ArXiv 论文、联网搜索的实时动态以及用户的个人技术偏好知识库,为用户提供每日技术动态摘要和深度解读。只在用户明确询问的技术领域内工作,拒绝回答无关话题。 |
选模型:Qwen3.5-Plus,点"生成智能体"。
大约 8 秒后,系统生成了完整的提示词结构,包括:角色定义、工作流程说明、工具调用规则、输出格式规范、边界限制。生成的内容完整度出乎意料的高,不是填空式的模板,而是真的针对我的描述和工具组合逻辑定制了内容。
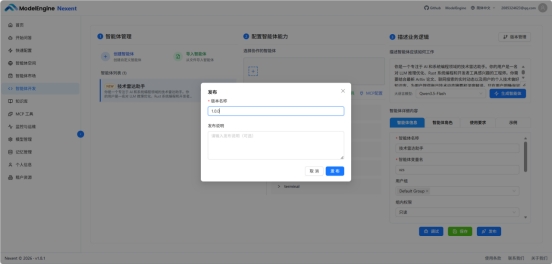
自动生成的提示词不是直接能用的,我做了三处具体修改:
修改一:工具调用顺序
自动生成的工作流程是:先知识库检索 → 再调用实时工具。对于"今天有什么新论文"这类时效性问题,顺序反了——应该先调 ArXiv MCP 拿实时数据,再结合知识库偏好过滤,否则实时数据会被当成补充而非主角。
原文:先检索知识库,再调用实时工具补充信息
改为:对于时效性问题,优先调用 ArXiv MCP 获取最新论文,再结合知识库中的个人偏好进行过滤和排序,最后用联网搜索兜底补充
修改二:输出格式的分节规则
自动生成的格式要求只说"按类别分组展示",太宽泛。我加了具体结构:
- 论文部分:标题(含 ArXiv 链接)+ 50 字摘要 + 与用户偏好的关联说明
- 项目/动态部分:来源 + 一句话说明为什么值得关注
- 每部分不超过 5 条,宁缺毋滥
修改三:拒答逻辑
自动生成的边界限制写的是"如果问题超出技术范畴,礼貌拒绝",太软。改成:
如果用户的问题与 AI、系统编程、开发者工具无关,直接说明"我只负责技术领域的信息整合,这个问题超出了我的服务范围",不做延伸回答
第一轮:测 ArXiv 工具调用 + 知识库偏好召回
问:「今天 LLM 推理优化方向有哪些值得看的新论文?」
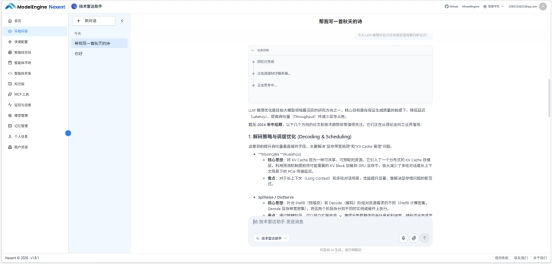
智能体先调用 ArXiv MCP 搜索 LLM inference optimization,返回 5 篇论文,再调用 knowledge_base_search 检索偏好文档,对这 5 篇按"是否涉及推理加速/量化/稀疏计算"重新排序,每篇后面加了一句"与你的关注方向关联度:高/中"。结果质量比预期好。
第二轮:测联网搜索覆盖 GitHub 动态
问:「GitHub 上 Rust 相关项目最近有什么值得关注的?」
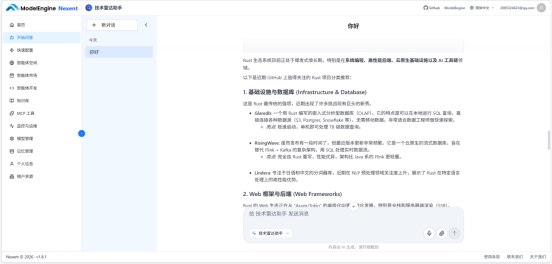
智能体没有调用 MCP,转而调用内置联网搜索,搜索了"GitHub Trending Rust",拿到当天热门项目列表,结合知识库里我对 Rust 系统编程的偏好筛选后,保留了 4 个相关项目,每个附了简短说明。联网搜索接 GitHub Trending 的效果完全够用,通过。
发布后切换到"开始问答",正式开始用。
问了一个综合性问题:「最近 LLM 推理效率方面有没有同时涉及量化和 KV Cache 优化的工作,找几篇新的论文,按照我的关注度帮我排个优先级」
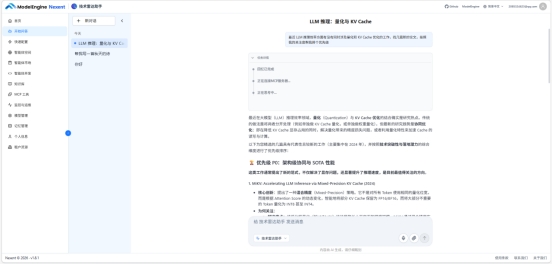
响应流程:
- ArXiv MCP 搜索 quantization KV cache LLM inference 2025,返回 8 篇论文
- 知识库检索命中偏好文档,提取出"量化优先关注 W4A8 以下方案""KV Cache 优先关注访存效率而非纯压缩比"两个具体偏好
- 综合两个信息源对 8 篇论文重新排序,给出带说明的优先级列表
回答末尾有来源标注:每篇论文附了 ArXiv 链接,知识库命中部分标了"依据:[技术偏好文档]第 3 节"。信息可以溯源,不是凭空生成的。
同一个问题去问裸 LLM,得到的是泛泛的"近期热门方向有……",没有个人化过滤,没有论文链接,没有溯源。这个差距是实质性的。
Nexent 支持配置"协作 Agent",主智能体可以调度子智能体完成子任务。我另外建了一个专门负责"论文摘要提炼"的子智能体,只配了 ArXiv MCP 和联网搜索,提示词专注于摘要质量,然后挂载到主智能体的协作列表里。
Nexent 有个智能体市场,里面有官方和社区发布的现成智能体。我装了一个"PubMed文献助手"试了试,走一遍安装流程:
选定智能体 → 选择本地使用的模型(需要手动指定,不继承原作者的选择)→ 确认工具权限 → 安装完成,出现在我的智能体列表。
流程设计整体顺畅,选型和安装在同一页面完成,没有跳转,没有多余步骤。
但安装完后有一个容易踩的坑:该智能体原本配置了知识库,安装到我的环境后,原作者的私有知识库自然不存在,系统会自动基于我自己有权限的知识库重新检索。这个行为本身合理,但安装完成时没有任何提示,我是发现回答质量不对劲后翻文档才找到原因的。
建议官方补一条安装后提示:「该智能体包含知识库检索工具,当前将基于你的知识库运行,如需达到原作者预设效果,请上传对应文档并绑定。」小改动,能省掉很多初次使用者的困惑。
在反复使用的过程中,我注意到了两个比较容易被忽略的功能。
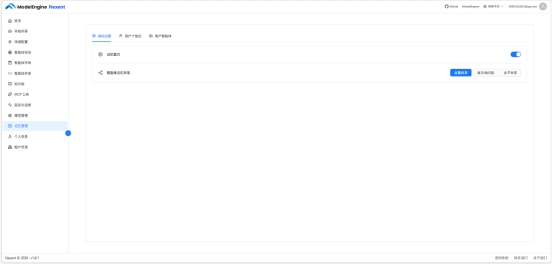
Nexent 有记忆系统,可以跨对话保留用户的偏好和历史上下文。开启后,每次对话结束,系统会自动提取关键信息(比如"用户关注 LLM 量化")存入记忆库,下次对话时自动附加到上下文里。
实际体验:连续对话了几天后,我问的问题里已经不需要再说"我关注 LLM 推理优化"这类背景了,智能体会主动按这个方向过滤和推荐。这个功能跟知识库偏好文档是互补的——知识库是静态的主动配置,记忆是动态的被动积累。长期使用下来,两者叠加,智能体对你的偏好理解会越来越准。
当然,记忆也有问题:它是基于对话提取的,如果某一轮你临时换了话题或者在讨论别人的需求,提取出来的记忆可能是错的。目前没有看到"手动编辑记忆"的入口,只有"清空全部记忆",这个粒度有点粗,期待后续版本细化。
Nexent 有多用户体系,管理员可以创建多个账号,设置不同角色权限。对于小团队来说,可以给不同成员配置不同的知识库访问权限,让某些内部文档只对特定人可见。我在自己的本地部署版本里试了试,给一个测试账号限制了知识库权限,确认隔离是有效的。
在这个周末实验结束后,我的技术雷达助手实际运行了一周多,基本代替了我每天早上手动刷信息的习惯。说完全替代不准确——偶尔它的 ArXiv 搜索结果和我手动找的不完全一致——但大部分工作日,它给的东西已经够用,节省了我每天大概 40 分钟的信息整合时间。
把这次体验客观拆一下。
提示词自动生成的完成度超出预期。它生成的不是填空模板,而是真的结合了我选的工具和描述,生成了有逻辑的工作流程说明。给了我一个质量不错的起点,而不是要我从零开始手写。
MCP 双接入方式的设计很实用。URL 方式适合接现成服务,npx 方式覆盖了大量 npm 生态里的工具包,两者并行,工具生态基本没有短板。
知识溯源机制是我认为最有价值的设计之一。回答带来源标注,信息可追溯,这对技术场景来说尤其重要——你需要知道某条结论是从哪篇论文来的,而不只是"AI 说的"。
工具测试功能的设计很务实。在把工具绑给智能体之前,先验证工具能不能跑通、返回什么格式,把调试工具问题和调试智能体行为问题分开,节省了大量排查时间。
版本管理给了调优过程安全感。改坏了能回滚,有这个保障,修改起来会更大胆,而不是每次改提示词都如临大敌。
模型接入的错误提示太粗。连通性验证失败只显示"连接失败",没有 HTTP 状态码,没有请求路径,排查成本高。加三行错误信息能解决 80% 的新用户困惑。
复杂 PDF 解析质量不稳定。多栏布局、公式密集的学术 PDF,入库后自动总结质量明显下降。对知识库来说这是核心功能,PDF 解析器的健壮性值得专门投入。
MCP 命名规则缺少实时校验。填入不合规的 Server Name 点添加后静默失败,不报错,用户完全不知道为什么工具没有出现。输入时实时拦截是最简单的修复方案。
智能体市场安装后缺少知识库引导。已经在上文说过,不重复了。
记忆管理粒度过粗。有清空功能但没有单条编辑或删除,错误的记忆会一直影响后续对话,直到被覆盖或手动清空。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 26
26 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)