AI算力中心热管理技术实践:从被动散热到主动智控的四层破局架构
为何要耗费巨资将数据中心“藏”进深海、“送”上太空?难道传统散热方式真的无法支撑AI算力的需求?其实,传统认知中“热管理=降温”的思维,早已跟不上高密度、高负载的算力时代。如今的热管理,已成为关乎算力寿命、系统稳定性与长期TCO(总拥有成本)的核心工程命题。本文从技术痛点、行业误区、实践方案与价值落地维度,拆解AI时代数据中心热管理的破局之道,为开发者与技术决策者提供可落地参考。
一、算力透支:热量背后的三大技术痛点
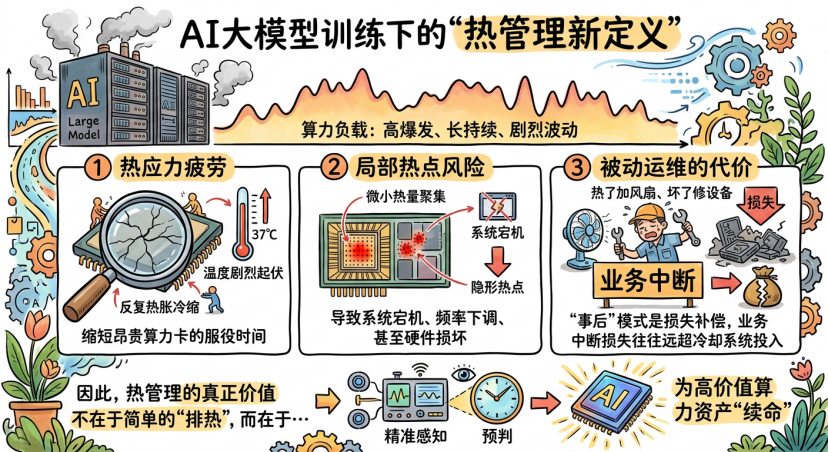
回归工程本质,热本身并非问题,无法感知的“热应力”才是透支算力资产生命周期的关键。AI大模型 训练、高性能推理等场景中,算力负载呈现高爆发、长持续、剧烈波动特征,对硬件造成三重不可逆损伤:
1. 热应力疲劳:硬件寿命的“慢性杀手”
负载波动导致芯片温度短时间内剧烈起伏(温差可达20℃以上),硬件材料在反复热胀冷缩中产生微裂纹,长期累积会缩短GPU、CPU 等核心部件服役周期。行业数据显示,长期处于温度波动环境的算力硬件,故障率提升3-5倍,寿命缩短40%以上。
2. 局部热点:系统宕机的“定时炸弹”
即便数据中心整体散热达标,密集算力单元内部仍易形成微米级局部热点(温度超100℃)。这些“隐形热点”难以被传统监测捕捉,却是系统宕机、GPU频率下调、硬件烧毁的核心诱因,单次宕机可能造成百万级损失。
3. 被动运维:高负载场景的“成本陷阱”
传统“热了加风扇、坏了修设备”的被动运维模式,在AI业务不间断需求下极易陷入恶性循环。硬件故障或过热停机带来的业务中断 、数据恢复、算力重置成本,往往远超冷却系统本身投入。
综上,AI时代热管理的核心价值,是通过精准感知、动态预判与智能调控,为高价值算力资产“续命”,最大化硬件投资回报率。
二、PUE陷阱:盲目追低能效的隐性风险
“碳中和”战略下,PUE(电能利用效率)成为数据中心能效核心评价指标,但单一追求极致低PUE,极易陷入“效率陷阱”。部分数据中心为压低PUE,压缩冷却系统冗余、简化监测环节、强制设备极限运行,这种短视操作在AI高负载场景下风险凸显:
液冷作为高密度算力散热主流方案,并非“一劳永逸”。接头老化、管路疲劳、冷却液性能漂移、泵组磨损等问题长期累积,缺乏冗余设计时,微小故障可能引发全系统瘫痪;无全局智能调控时,单一冷却环节故障(如CDU流量异常)会快速传导,演变为集群宕机,损失远超PUE节省的电费。
PUE优化的核心前提是保障算力寿命与系统稳定,牺牲可靠性换能效,本质是“捡芝麻丢西瓜”。
三、破局思路:四层技术架构实现主动管理
热管理需从“被动补救”转向“事前预判、事中调控、事后优化”的主动管理,依托“物理基础-虚拟仿真-全域感知-智能决策”四层架构,构建全链路闭环体系。
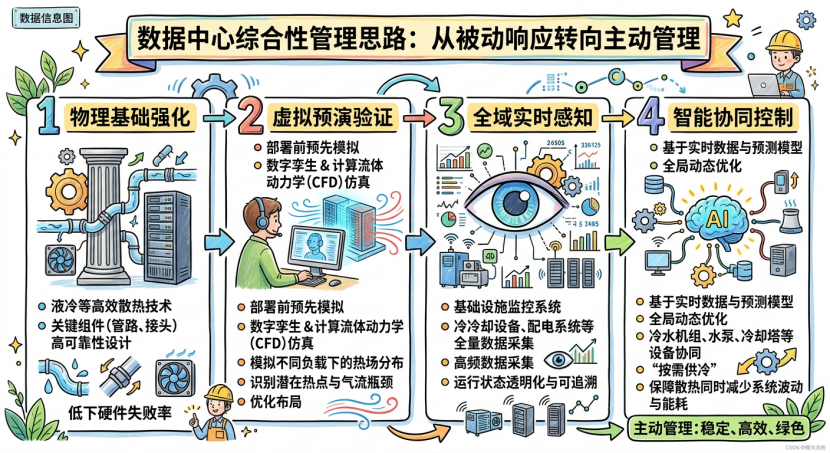
1. 物理基础强化:高可靠液冷硬件筑牢底座
单机柜功率密度突破50kW的场景下,液冷成为唯一可行散热路径。核心是采用工业级高可靠液冷硬件,解决渗漏、老化等痛点:部署CDU、高密度液冷管路等核心设备,支持单芯片1500W TDP散热,单机柜散热能力达1300kW;采用军工级密封工艺与抗疲劳材质,适配多种冷却液;提供“液对气”“液对液”双路径,覆盖新建与改造场景。
2. 虚拟预演验证:数字孪生+CFD规避部署风险
传统“先部署、后调试”模式易导致后期整改,数字孪生+CFD仿真可实现“先仿真、后部署”:基于NVIDIA Omniverse搭建1:1数字孪生模型,模拟不同负载、环境下的热场分布与热点位置,提前识别瓶颈;优化机柜布局与气流设计,确保部署后无局部热点,散热效率提升30%以上。
3. 全域实时感知:BMS实现状态透明化
通过BMS(基础设施监控系统)构建热管理数据底座:实时采集CDU、冷机、GPU服务器等核心设备的200+关键参数(采集频率1秒/次);搭建可视化 平台,异常状态实时告警;自动存储历史数据,支持多维度追溯,同时追踪能耗与碳排放,满足合规要求。
4. 智能协同控制:AI智控动态优化能效
基于实时数据与AI算法 构建全局协同控制体系:群控调优统筹各类冷却设备,避免系统失衡,冷却能耗降低40%,PUE稳定在1.06-1.1;负荷预测融合多维度数据,提前调节供冷策略;故障预警可提前7-30天发现潜在问题,避免突发停机。
四、Fii科技服务一站式解决方案:闭环守护算力资产
针对上述四个层级的整合需求,工业富联基于自身在硬件制造与软件研发方面的积累,打造了数据中心一站式管理解决方案,主要覆盖以下能力:
1.液冷硬件基础设施
提供CDU、高密度液冷管路、快速接头等核心组件,硬件按工业级标准设计,重点解决液冷系统在长期运行中的可靠性问题(如接头密封、管路抗疲劳、冷却液兼容性等)。
2. Omniverse + CFD 仿真
基于NVIDIA Omniverse平台搭建数据中心数字孪生模型,结合CFD仿真,在方案规划阶段对气流组织、热点分布、热安全裕量进行模拟评估,支持”先仿真、后部署”的工程方法。
3. BMS基础设施监控
对CDU、空调、冷机、UPS等核心设备进行参数采集与状态监测,提供能耗与碳排放数据追踪、自动告警和维护工单管理,作为系统的数据底座。
4.AI节能智控系统
其自主研发的算法系统,主要包含三项功能:
群控调优:统筹冷水机组、水泵、冷却塔与末端空调的协同运行,避免单点优化导致的系统失衡。
负荷预测:结合历史运行数据、业务排程与气象信息,预判冷负荷变化趋势,调节供冷策略。
故障诊断:持续监测设备健康状态,对异常进行预警并辅助定位根因。
四个模块之间形成"硬件—仿真—监控—决策"的闭环,目的是将原本分散的热管理环节整合为统一体系。
五、价值总结:热管理是算力时代核心竞争力
AI算力时代,热管理已从辅助环节升级为决定算力寿命、业务连续性与长期TCO的核心竞争力。无论采用何种散热方案,均需回归两大核心:是否延长算力服役周期,是否平衡能效与可靠性。
从“建得快”到“管得好”是行业成熟的必然趋势,Fii科技服务将以高可靠硬件、智能化软件与全链路服务,助力企业实现高效、稳定、低成本运营。
你所在的数据中心是否面临高密度散热、局部热点或PUE优化难题?
在热管理方案选型、部署运维中遇到过哪些痛点?
欢迎留言交流,共探最佳实践。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 5
5 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)