本地部署大模型-保姆级教程
-
Ollama 就是这辆车的**“发动机”**。它负责在后台轰鸣进行复杂的计算。但它没有漂亮的界面,只有一个黑乎乎的命令行窗口。
-
Chatbox 就是这辆车的**“方向盘、真皮座椅和中控屏幕”**。它负责给你一个像微信、ChatGPT 一样漂亮的聊天界面。
-
Qwen2.5:32b 就是你要加的**“顶级燃油”**(模型文件本身)。
第一步:安装“发动机”(Ollama)
⚠️ 特别警告(小白必看):
大模型文件非常大!一会我们要下载的模型大概有 20个G。Ollama 默认会把模型下载到你的 C盘。如果你的 C 盘空间不足,请先按下面的【附加步骤】修改保存路径。如果 C 盘空间很大(剩余 50G 以上),可以直接往下看。
-
打开浏览器,输入网址:https://ollama.com/
-
点击网页正中间巨大的 “Download”(下载)按钮。
-
选择 “Windows”,点击 “Download for Windows”。
-
下载完成后,双击那个名叫 OllamaSetup.exe 的文件,点击 “Install”(安装)。
-
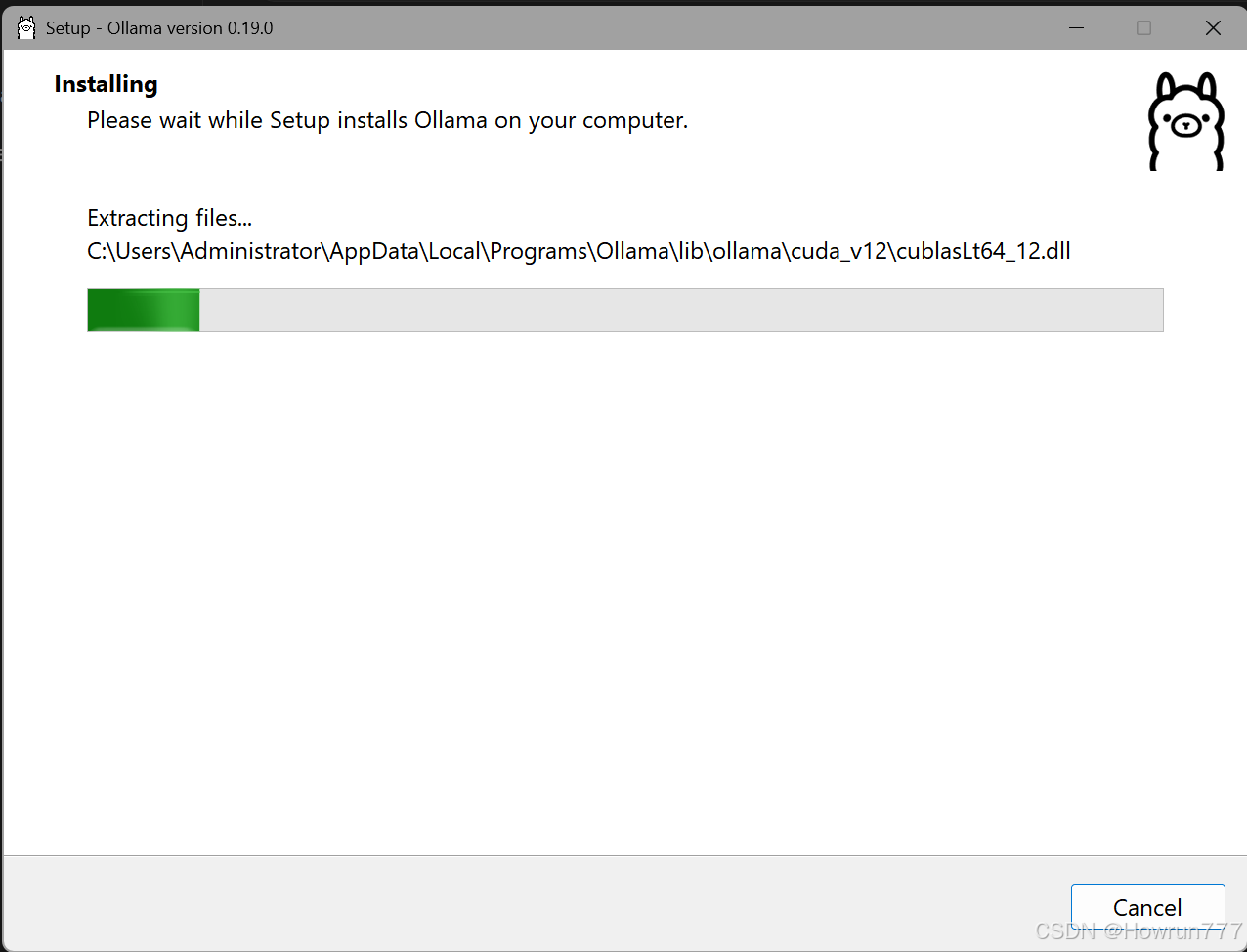
怎么判断安装成功了? 看你电脑右下角(显示时间的旁边,或者向上折叠的小箭头里),是不是多了一个可爱的黑白羊驼(Llama)小图标?如果有,说明发动机已经启动并在后台运行了!
上面图片中正在安装的:Ollama 软件本体(发动机本身)
这是什么? 你截图中正在解压的文件(你看那个 cuda_v12\cublasLt64_12.dll),其实是让你的显卡能够运转的核心驱动库和代码程序。
占多大空间? 整个 Ollama 软件本体其实非常小,通常只有几百 MB(连 1GB 都不到)。
为什么在 C 盘? 像这种底层的运行环境软件,Windows 默认都会把它安装在 C 盘的用户目录(AppData)下,以保证最高的运行权限和稳定性。这是改不了的,放在 C 盘也绝对不会撑爆你的硬盘。
上面是大模型文件(发动机的燃油)
这是什么? 这是一会儿你要在黑窗口里下载的 qwen2.5:32b,这是真正的“数据巨兽”。
占多大空间? 动辄十几 GB、二十几 GB,甚至几十 GB。
它去哪了? 默认会存在你的C盘里, 你最好是自己设置一下
【附加步骤:如何把模型存到 D 盘或 E 盘?(防 C 盘爆满)】
按键盘上的 Win 键,直接打字搜索“环境变量”,点击**“编辑系统环境变量”**。
点击右下角的**“环境变量”**按钮。
在上半部分的“用户变量”里,点击**“新建”**。
变量名 填入:OLLAMA_MODELS
变量值 填入你想保存的路径,比如:D:\OllamaModels (注意:你需要提前在 D 盘建好这个文件夹)。
一路点“确定”保存。然后鼠标右键点击电脑右下角的“羊驼”图标,选择“Quit Ollama”退出,再从开始菜单重新打开 Ollama,以后模型就都会下载到 D 盘了。
第二步:下载“模型”(Qwen3:32B)
现在,我们要让后台的发动机开始下载“通义千问 320亿参数”这个顶级模型。
-
打开命令行黑窗口: 按键盘上的 Win + R 键,会弹出一个“运行”小窗口。在里面输入 cmd,然后按回车(Enter)。
-
这时会弹出一个黑色的窗口。
-
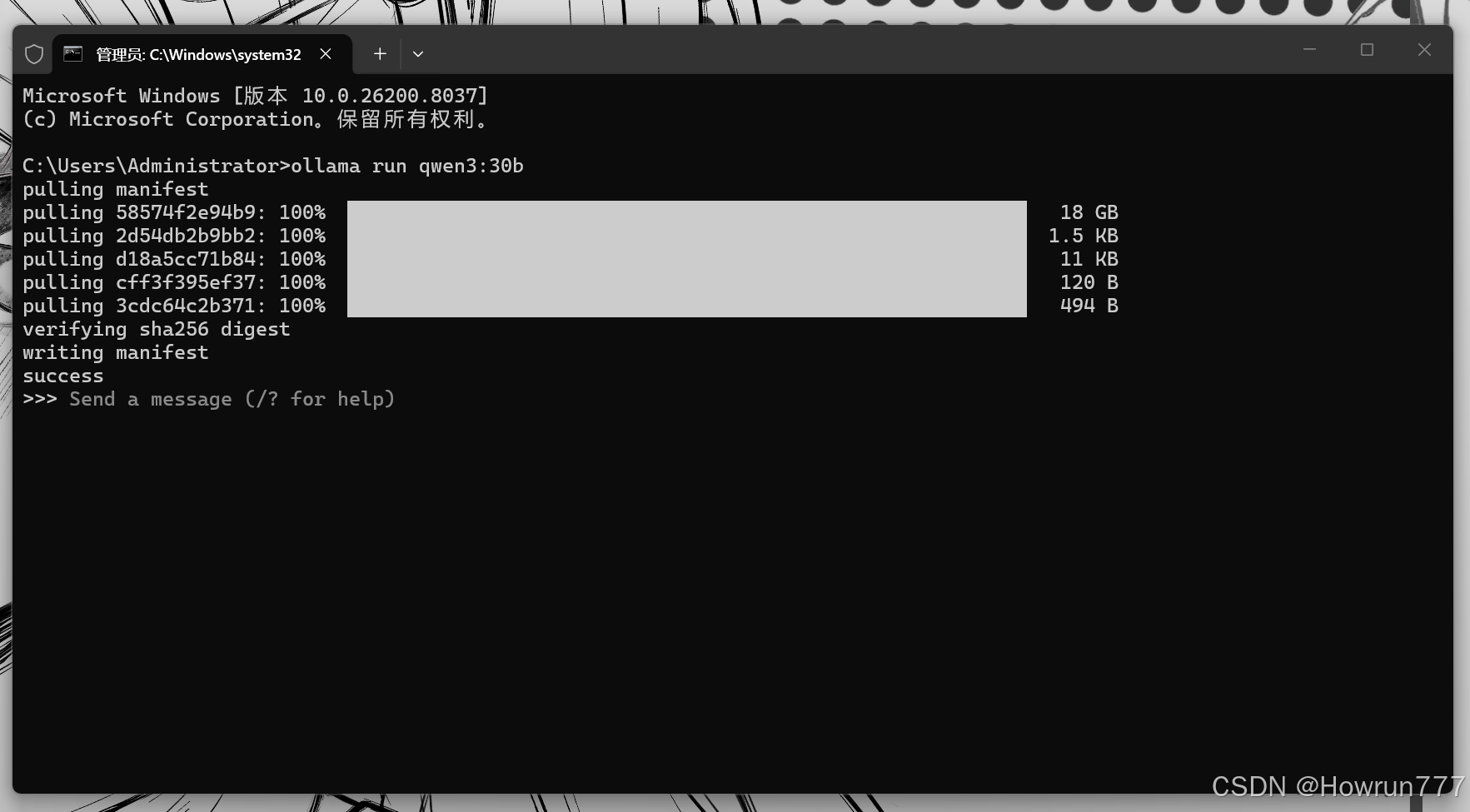
输入魔法口令: 把你的输入法切换到英文,在黑窗口里输入这行代码(注意中间有空格,冒号是英文冒号):
ollama run qwen3:30b -
按下回车键(Enter)。
-
耐心等待: 屏幕上会出现 pulling manifest,然后出现下载进度条。因为你的 5090 显存有 32G,这个匹配它的模型大概有 20GB 左右大小。根据你的网速,这可能需要 10 分钟到半个小时。
-
下载完成的标志: 当进度条走完,黑窗口里出现 >>> 符号时,说明下载好了!
-
你可以试着在这个黑窗口的 >>> 后面打字,比如输入 你好,按回车,它就会回复你。但这黑窗口太丑了,我们输入 /bye 然后按回车退出它,把黑窗口关掉。
第三步:安装“漂亮外壳”(Chatbox)
-
打开浏览器,输入网址:https://chatboxai.app/zh
-
点击 “免费下载” -> 选择 “Windows 下载”。
-
下载完成后,双击安装包,一路“下一步”安装好,并打开它。
第四步:把外壳和发动机连起来(最终配置)
这是最后一步,让 Chatbox 去调用刚才下载好的模型。
-
打开 Chatbox 后,点击左下角的 “设置”(一个齿轮图标)。
-
在弹出的设置窗口里,找到 “模型提供商” (或者叫 AI Provider)。
-
在下拉菜单里,向下滚动,找到并选择 “Ollama API”。
-
此时下面会出现设置选项:
-
API 域名 (API Host):保持默认的 http://127.0.0.1:11434 不动。(这串数字的意思是“我的本机电脑”)。
-
模型 (Model):点击下拉菜单,里面应该已经出现了你刚才下载的 qwen2.5:32b。选中它!
-
-
点击底部的 “保存”。
🎉 恭喜你!大功告成!
现在,你可以回到 Chatbox 的主界面,在底部的输入框里对它说:
“你好,请你写一个赛博朋克风格的科幻故事开头。”
问题:
1.能不能下载多个模型?
这就好比你的 F 盘是一个巨大的**“地下车库”**,你可以往里面停无数辆顶级跑车(大模型)。
不过,作为小白,你需要了解一个非常重要的**“硬盘 vs 显存”**的概念,这样才不会让你的电脑卡死:
下载(存放在 F 盘)= 无限多 💾
只要你的 F 盘空间够大,你把列表里带有 ⬇️ 图标的模型全部点一遍下载都没问题。
一个 30b 或 27b 的模型,大概占用 20GB 的硬盘空间。
一个 8b 的小模型,大概占用 5GB 的硬盘空间。
你可以下载 5 个不同的模型,随时备用。运行(使用 5090 显卡)= 一次最好只开一个 🚀
虽然你的车库(F盘)里有很多车,但你(显卡)一次只能开一辆车出门。
你的 RTX 5090 有 32GB 显存,这是极其珍贵的“脑容量”。
当你选中 qwen3:30b 跟它聊天时,它会瞬间占用你大概 20GB 的显存。
注意: 如果你在这个时候,又打开另一个窗口,同时去运行另一个 gemma3:27b,这就需要 20G + 18G = 38G 显存。此时显存(32G)不够用了,电脑就会严重卡顿,甚至报错。
2.如何选择模型
(一)本地可部署开源模型(可下载离线运行,数据完全本地处理)
这类均为开源可商用版本,核心优势是隐私性拉满,无调用费用,能力上限取决于本地硬件算力,参数越大对显存要求越高。
gpt-oss:120b / 20b
- 定位:GPT-OSS 的本地部署版本,功能与云端版一致,为通用对话大模型。
- 部署门槛:20B 版本需高端消费级显卡(24G 以上显存);120B 版本需专业级服务器 / 多卡集群,普通消费级硬件无法流畅运行。
gemma3:27b / 12b / 4b / 1b
- 厂商 / 定位:Google 谷歌基于 Gemini 技术架构开源的轻量级通用大模型,全系列开源可免费商用,端侧友好。
- 核心功能:通用对话、文本创作、基础推理、轻量代码补全、多语言翻译,谷歌技术背书,兼容性、稳定性极强,适配本地离线助手、端侧 AI 应用开发。
- 版本差异:
- 27B/12B:中大型版本,能力全面,适合复杂通用任务,需 16G/24G 以上显存;
- 4B/1B:超轻量版本,1B 可在手机 / 嵌入式设备运行,普通电脑就能流畅部署,仅适配轻量对话、简单任务。
deepseek-r1:8b
- 厂商 / 定位:深度求索开源的推理专用大模型,80 亿参数轻量化本地版本,对标 OpenAI o1 的推理能力。
- 核心功能:垂直优化数学推理、逻辑推理、代码推理,擅长复杂问题分步拆解、思维链优化,是本地部署场景下,解题、代码调试、复杂逻辑处理的首选,12G 以上显存即可流畅运行。
qwen3-coder:30b
- 定位:通义千问 Qwen3 代码专用版的本地部署版本,300 亿参数。
- 核心功能:与云端 480B 版功能一致,平衡了代码能力和部署门槛,支持全编程语言的生成、调试、重构,24G 以上显存可部署,是本地离线开发、代码助手的首选。
qwen3-vl:30b / 8b / 4b
- 定位:通义千问 Qwen3 多模态视觉版的本地部署版本。
- 核心功能:与云端 235B 版功能一致,可离线完成图片理解、OCR、图表解读、视觉问答,适配涉密文档解析、离线工业视觉、本地多模态助手场景。
- 部署门槛:30B 需 24G 以上显存,8B/4B 可在 12G/8G 显存的消费级显卡流畅运行。
qwen3:30b / 8b / 4b
- 定位:通义千问 Qwen3 的基础通用版,全场景本地部署通用大模型。
- 核心功能:覆盖日常对话、知识问答、文本创作、长文本理解、通用推理等全 NLP 场景,是本地通用助手的主流选择。
- 版本差异:30B 能力最全面,8B 是消费级显卡的甜点级选择,4B 适配低算力设备的轻量场景。
(二)云端闭源模型(仅 API 调用,无本地部署权限)
这类均为各厂商的旗舰级大参数量版本,能力天花板高,无需本地算力,按调用量计费,数据需上传云端。
gpt-oss:120b-cloud / 20b-cloud
- 厂商 / 定位:社区开源复刻 GPT 架构的通用大语言模型,云端服务版本。
- 核心功能:通用文本对话、知识问答、长文本理解、基础逻辑推理、内容创作,对标 GPT 系列的开源实现。
- 版本差异:120B(1200 亿参数)是大参数量版,长文本、复杂推理能力更强;20B 是轻量化版,响应速度更快,适合轻量通用任务。
deepseek-v3.1:671b-cloud
- 厂商 / 定位:国内深度求索(DeepSeek)的旗舰级通用大模型,6710 亿参数 MoE(混合专家)架构,云端版本。
- 核心功能:目前商用领域顶级的通用能力,覆盖超长上下文理解、高阶数学 / 逻辑推理、全场景代码生成、多轮深度对话、专业知识问答,MoE 架构兼顾了超大参数量和推理效率。
qwen3-coder:480b-cloud
- 厂商 / 定位:阿里达摩院通义千问 Qwen3 的代码专用旗舰版,4800 亿参数云端版本。
- 核心功能:垂直优化代码能力,支持全主流编程语言,可完成项目级代码生成、架构设计、漏洞检测、调试重构、技术文档生成,是国内代码能力第一梯队的商用模型。
qwen3-vl:235b-cloud
- 厂商 / 定位:阿里达摩院通义千问 Qwen3 的多模态视觉语言旗舰版,2350 亿参数云端版本。
- 核心功能:可理解图片、图表、视频帧等视觉内容,完成 OCR 识别、图文问答、复杂图表解读、视觉逻辑推理、多模态内容创作,能精准解析图片里的文字、场景、数据与逻辑。
minimax-m2:cloud
- 厂商 / 定位:国内 MiniMax 公司的旗舰级通用大模型,云端闭源版本。
- 核心功能:主打超长上下文共情对话、沉浸式角色扮演、长文本创作、多模态内容生成,对话流畅度、创作质感、长对话连贯性优势突出,适配内容创作、智能陪伴等场景。
glm-4.6:cloud
- 厂商 / 定位:智谱 AI 的 GLM-4 系列升级旗舰版,国内主流商用通用大模型,云端闭源版本。
- 核心功能:全场景通用能力,覆盖复杂推理、长文本处理、多模态理解、工具调用、代码生成、企业级知识问答,适配智能体开发、企业服务、通用对话等全场景。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)