Agent-Trace: 揭开 AI Agent 对话的神秘面纱
引言
在 AI Agent 应用爆发的今天,无论是 Claude Code、OpenClaw 还是其他基于大模型的自动化工具,它们与 AI 模型的交互过程对开发者来说往往是一个"黑盒"。我们发送请求,得到响应,但中间发生了什么?Agent 是如何思考的?工具调用的参数是什么?这些问题困扰着许多想要深入理解 Agent 工作原理的开发者。
今天,我将为大家介绍一款开源工具——Agent-Trace,它能够完整记录和追踪 AI 对话的每一个细节,帮助你真正理解 Agent 的工作原理。
什么是 Agent-Trace?
Agent-Trace 是一个基于 Flask 开发的 AI 对话日志记录和追踪系统。它的核心功能是:
- 透明代理:拦截并转发所有 AI API 请求
- 完整记录:保存每次对话的请求和响应详情
- 实时查看:提供友好的 Web 界面浏览对话历史
- 双格式支持:同时支持 OpenAI 和 Anthropic API 格式
- 流式处理:完美支持流式和非流式请求
简单来说,它就像是一个"监控摄像头",能够记录下 Agent 与 AI 模型之间的所有交互细节。
项目地址: https://github.com/fw6669998/agent-trace
核心架构设计
整体架构图
客户端 (Claude Code/其他 Agent)
↓
Agent-Trace 代理服务
↓
AI API (OpenAI/Anthropic)
Agent-Trace 位于你的 Agent 工具和 AI API 之间,充当中间人的角色。所有的请求和响应都会经过它,从而被完整记录下来。
项目结构
agent-trace/
├── main.py # Flask 主应用(API 转发、路由)
├── api_tool.py # API 数据处理工具(解析请求/响应)
├── tool.py # 通用工具(数据库操作、日志记录)
├── requirements.txt # Python 依赖
├── .env # 环境配置文件
├── message.db # SQLite 数据库(自动生成)
└── static/
└── index.html # Web 管理界面
核心技术原理
1. API 请求转发机制
Agent-Trace 的核心是 Flask 应用,它通过动态路由捕获所有请求:
@app.route('/<path:path>', methods=['GET', 'POST', 'PUT', 'DELETE', 'PATCH', 'HEAD', 'OPTIONS'])
def forward_request(path):
# 构造目标 URL
target_url = f"{API_BASE_URL.rstrip('/')}/{path.lstrip('/')}"
# 识别 API 类型
api_type_map = {'v1/chat/completions': 'openai', 'v1/messages': 'anthropic'}
api_type = api_type_map.get(path, 'other')
# 转发请求到真实的 AI API
response = requests.request(
method=request.method,
url=target_url,
headers=headers,
data=raw_body,
stream=is_stream
)
关键点:
- 使用
<path:path>捕获任意路径的请求 - 自动识别是 OpenAI 还是 Anthropic 的 API 端点
- 保留原始请求的所有信息(方法、头、体)
- 自动注入配置的 API Key
2. 流式请求的精妙处理
现代 AI API 通常支持流式输出(SSE, Server-Sent Events),Agent-Trace 对流式请求做了特殊处理:
def generate():
answer_buffer = []
for chunkBytes in response.iter_lines():
if chunkBytes is None:
continue
chunkText = api_tool.get_chunk_answer(chunkBytes, api_type)
answer_buffer.append(chunkText) # 缓存每个 chunk
yield chunkBytes + b"\n" # 实时返回给客户端
finally:
answerStr = "".join(answer_buffer)
tool.log_chat(req_body, answerStr, api_type) # 记录完整响应
工作流程:
- 检测到
stream: true参数 - 启用
stream=True发起请求 - 逐行读取 SSE 数据流
- 实时转发给客户端(保持流式体验)
- 同时缓存所有内容用于后续记录
这种设计既保证了客户端的流式体验,又确保了完整响应被记录下来。
3. 智能解析 OpenAI 和 Anthropic 响应
两种 API 格式有不同的响应结构,Agent-Trace 分别实现了解析逻辑:
OpenAI 格式解析
def get_openai_no_stream_answer(rsp_body):
message = rsp_body['choices'][0]['message']
answer = message['content']
# 处理工具调用
if 'tool_calls' in message:
answer += f'\n[工具调用:{message["tool_calls"][0]["function"]["name"]}]:\n'
answer += message["tool_calls"][0]["function"]['arguments']
return answer
Anthropic 格式解析
def get_anthropic_no_stream_answer(rsp_body):
answer = ""
for item in rsp_body['content']:
if item['type'] == 'text':
answer += item['text']
elif item['type'] == 'tool_use':
answer += f'\n[工具调用:{item["name"]}]:\n'
answer += json.dumps(item['input'], ensure_ascii=False)
return answer
关键差异:
- OpenAI 使用
choices[0].message结构 - Anthropic 使用
content数组,支持多模态内容 - 工具调用的字段名和结构完全不同
4. 从复杂对话中提取关键信息
Agent 对话通常包含多轮交互,Agent-Trace 智能提取最近的用户输入:
OpenAI 格式
def get_openai_recent_question(req_body):
# 获取 messages 数组的最后一个消息
content = req_body['messages'][-1]['content']
# 处理多模态内容(可能是列表)
if isinstance(content, list):
recent_question = content[-1]['content']
else:
recent_question = content
return recent_question
Anthropic 格式
def get_anthropic_recent_question(req_body):
# Anthropic 的 messages 是嵌套结构
content = req_body['messages'][-1]['content'][-1]
if 'text' in content:
recent_question = content['text']
elif 'content' in content:
recent_question = content['content']
# 处理工具返回结果
if content['type'] == 'tool_result':
recent_question = '[工具调用结果:]\n' + recent_question
return recent_question
实际应用场景
场景 1:调试 Claude Code 的自动化脚本
当你使用 Claude Code 执行复杂任务时,可能不理解为什么它会做出某些决策。通过 Agent-Trace,你可以:
- 看到完整的思考过程
- 检查工具调用的具体参数
- 分析错误产生的原因
示例:
用户问题:帮我重构这个项目的代码结构
Claude 的思考过程(通过 Agent-Trace 可见):
1. 分析当前目录结构
2. 调用 file_read 工具读取关键文件
3. 调用 file_write 工具创建新结构
4. 调用 shell_exec 执行移动命令
场景 2:学习 Agent 设计模式
观察成熟的 Agent 工具如何与大模型交互,是学习 Agent 设计的最佳方式。你可以看到:
- Prompt 的组织方式
- 上下文管理的策略
- 工具调用的时机和参数格式
- 错误处理的机制
场景 3:优化 Token 使用
通过分析 request_body,你可以:
- 查看每次请求消耗的 token 数量
- 优化 prompt 长度
- 减少不必要的上下文信息
- 降低成本
安装与配置
快速开始
# 1. 克隆项目
git clone <repository-url>
cd agent-trace
# 2. 安装依赖
pip install -r requirements.txt
# 3. 配置环境变量
# 编辑 .env 文件
API_BASE_URL=https://api.openai.com
API_KEY=sk-your-api-key
# 4. 启动服务
python main.py
配置客户端
将你的 Agent 工具的 API 端点指向本地代理:
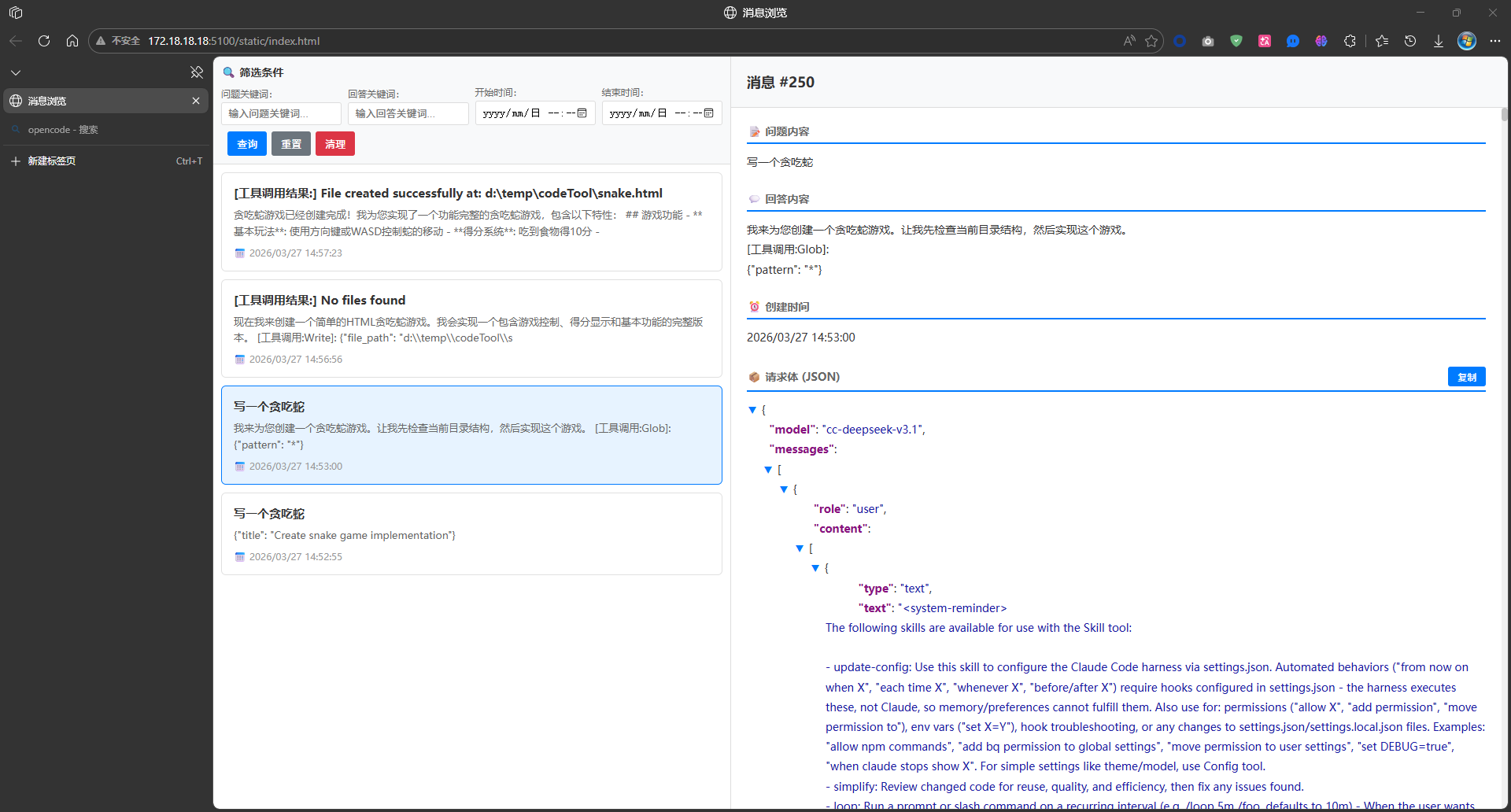
访问 Web 界面
浏览器打开 http://localhost:5100,你将看到:
- 左侧面板:对话列表,支持关键词筛选和时间范围过滤
- 右侧面板:选中对话的详细信息,包括:
- 用户问题
- AI 回答
- 完整请求体(JSON 格式,可折叠)
工具调用追踪
对于包含工具调用的对话,Agent-Trace 会特别标注:
[工具调用:create_file]:
{
"path": "/app/main.py",
"content": "print('Hello World')"
}
这对于理解 Agent 的行为至关重要。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)