CVPR‘26 | 1条顶50条!北大董豪团队联合智元提出Real2Edit2Real,提升具身数据效率
具身智能的持续发展离不开高质量的数据集,但是采集成本同样也是令人头疼的问题:
海量机器人本体、大规模数采场地、人工采集与核验,要构建一个高质量数据集,成本飞速增加。
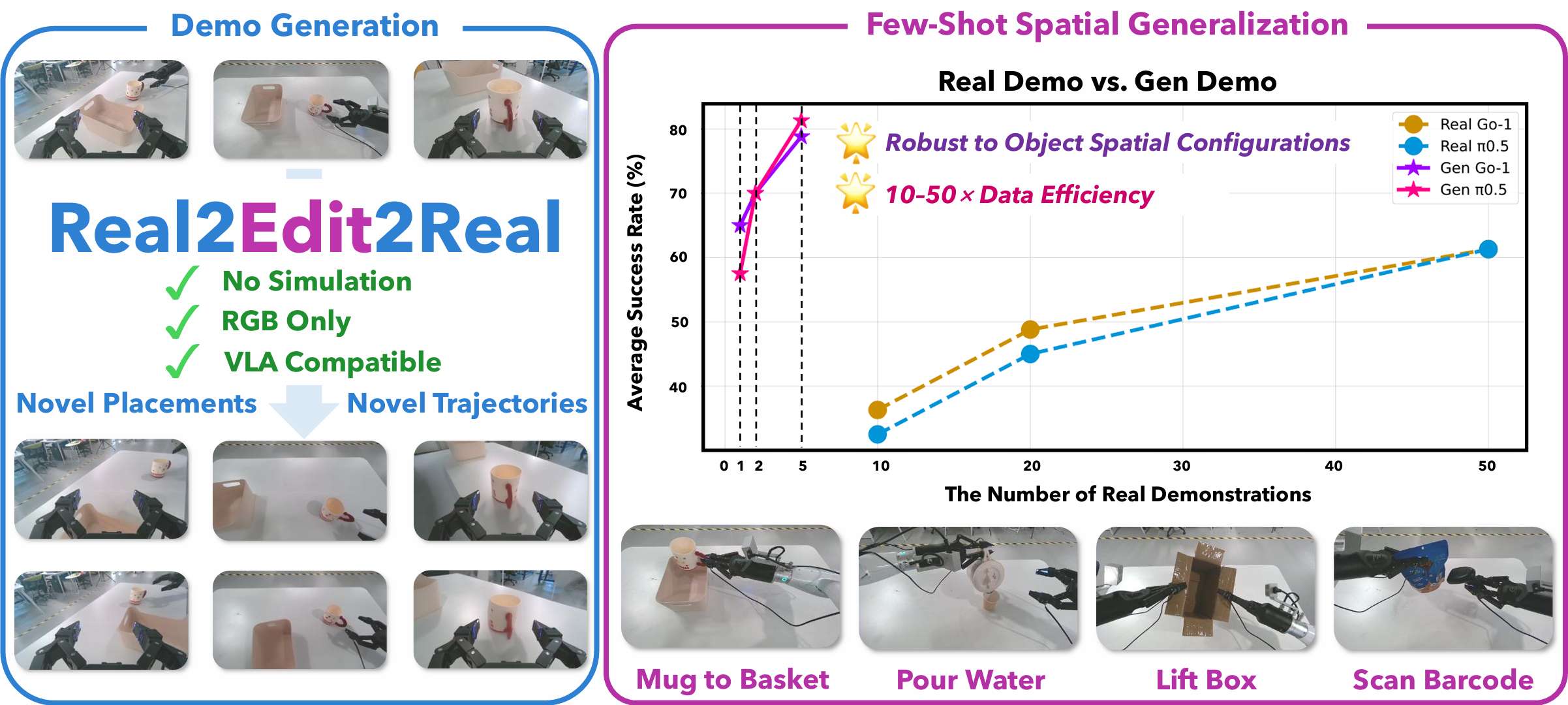
针对这样的成本难题,北京大学董豪团队与智元机器人联合提出一种名为Real2Edit2Real的全新数据生成范式,仅需要采1-5条真机数据,机器人就能自动脑补出高质量的空间泛化、纹理泛化数据,操作成功率超过50条真机数据,将机器人学习的数据效率提升了 10-50 倍。
该工作已被CVPR 2026接收,代码已开源。
- 论文:https://arxiv.org/abs/2512.19402
- 代码:https://github.com/Real2Edit2Real/Real2Edit2Real
- 项目主页:https://real2edit2real.github.io
研究背景
近年来,得益于大规模数据集以及强大的模型架构如VLA、Diffusion Policy等,具身操作学习取得了显著进展。然而,这些方法很大程度上依赖于高质量、多样化的数据。为了减轻重复数据采集的负担,一种有效的策略是基于少量的采集数据生成新数据。
现有的数据生成方案可以分为两类。
- 基于数字孪生与物理仿真的方法:如MimicGen、Real2Render2Real等会面临视觉和物理鸿沟,且需要对被操作物体构建数字资产,限制了其应用规模。
- 基于3D编辑的方法:如DemoGen等通过3D编辑增强点云数据,但无法生成对应的RGB视频,从而无法用于VLA、Diffusion Policy等基于视频的策略模型。
本文提出Real2Edit2Real,一个基于3D控制的具身数据生成方案,建立起了3D可编辑性与视频数据生成之间的桥梁。该方案不依赖于任何仿真引擎或数字资产,可直接接入数采管线,生成多视角操作视频数据,可用于VLA训练。为了评估数据生成的质量和效率,我们在四个真机操作任务上进行了实验,涵盖了从单臂到双臂的操作。实验结果表明,仅从 1-5 条真机数据进行生成,其策略成功率可以达到或超过使用50条真机数据,将数据效率提高了 10-50 倍。
Real2Edit2Real 方案解析
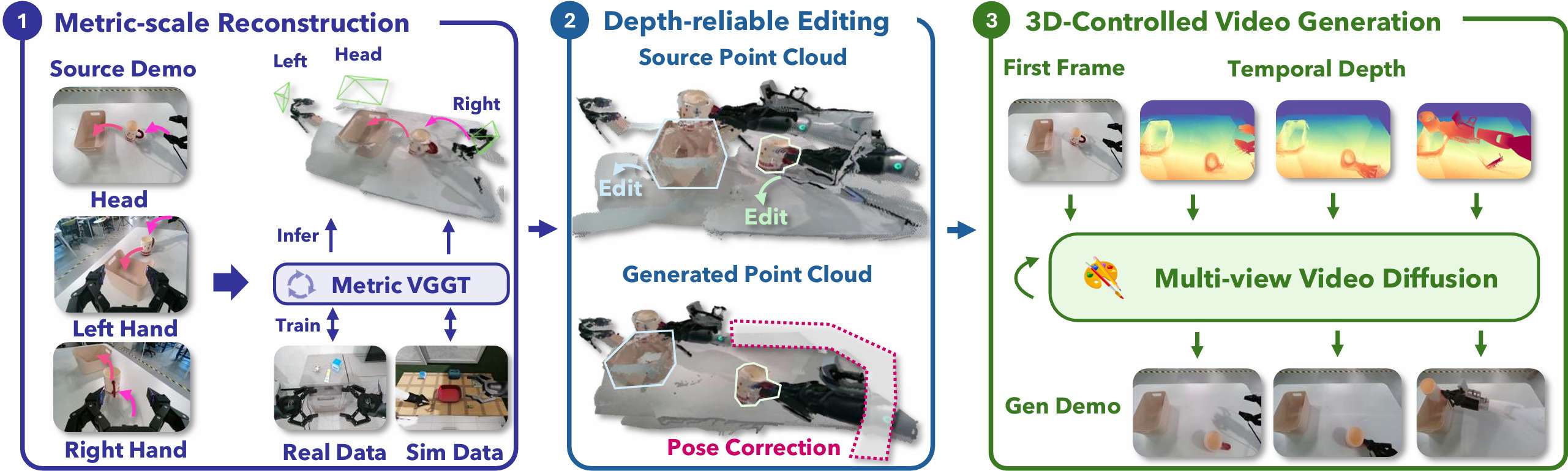
Real2Edit2Real的核心思想在于建立3D重建的可编辑性与2D视频生成的真实性之间的桥梁:
- 真实尺度的几何重建:利用多视角 RGB 视频,重建出带有精确尺寸的 3D 场景。团队提出了一种混合训练范式,结合仿真数据的精确深度和真机数据的几何尺度,训练端到端重建模型VGGT在具身操作中准确重建3D场景。
- 深度可靠的空间编辑:在重建后的3D场景直接移动物体位姿,并同步规划机器人的运动轨迹。关键点在于机器人姿态校正,即如果物体动了,机械臂的逆运动学也要跟着变,通过对新的轨迹对应的URDF重新投影,生成符合物理逻辑的深度图。
- 3D 控制的视频生成:利用深度图作为核心控制信号,配合动作、边缘等信息,引导视频生成模型合成出视觉逼真、多视角一致的新视频数据。
通过”重建-编辑-生成“的三阶段流程,Real2Edit2Real实现了对具身数据的精确3D控制与广泛增强。
真实尺度的几何重建
该模块的任务是从多视角 RGB 视频中恢复精确的 3D 几何结构。为了解决机器人视角下相机位姿不准和深度图噪声大的问题,团队提出了一种混合训练范式:
- 相机位姿监督:在真实场景中,手眼标定往往存在系统误差。因此,模型仅使用仿真数据来监督相机位姿的学习,因为仿真环境能提供绝对准确的位姿真值。
- 深度图监督:由于真实传感器采集的深度图在反光或无纹理表面会失效,团队结合了仿真数据的“无噪深度”和真实数据的“几何度量”,对重建模型进行微调。
这一步实现了从 2D 像素到 3D 点云的转化,核心成果是获得了一个具备真实尺度且位姿准确的 3D 重建场景。
深度可靠的空间编辑
该模块的核心是在3D空间合成物体新位姿并生成操作轨迹。为确保深度图能有效控制视频生成,研究团队通过轨迹合成、深度投影与姿态校正,解决了点云编辑中的空洞、噪声及运动学不一致问题。
- 轨迹合成:算法将原始真机数据分解为运动段与技能段。当物体移至新位姿时,技能段中机器人的点云同步应用相同变换,以保持机器人与物体的交互关系不变,而运动段则根据新位姿重新进行运动规划。
- 深度投影:由于相机固定在末端执行器上,编辑点云后相机位姿也会随之更新。算法将编辑后的点云重新投影生成深度图,并利用背景修复与深度过滤技术消除因位置变动产生的空洞,确保深度信息平滑完整。
- 机器人姿态校正:为避免机械臂整体平移而导致错误的运动学,该模块仅对末端执行器进行空间变换,并利用 URDF 模型对机械臂进行逆运动学求解与深度重绘。这一步确保了生成的机器人动作在物理和运动学上是合理且连贯的。
通过上述步骤,该模块不仅合成了符合运动学约束的新动作序列,还为后续的视频生成模型提供了高精度的 3D 控制条件。
3D控制的视频生成
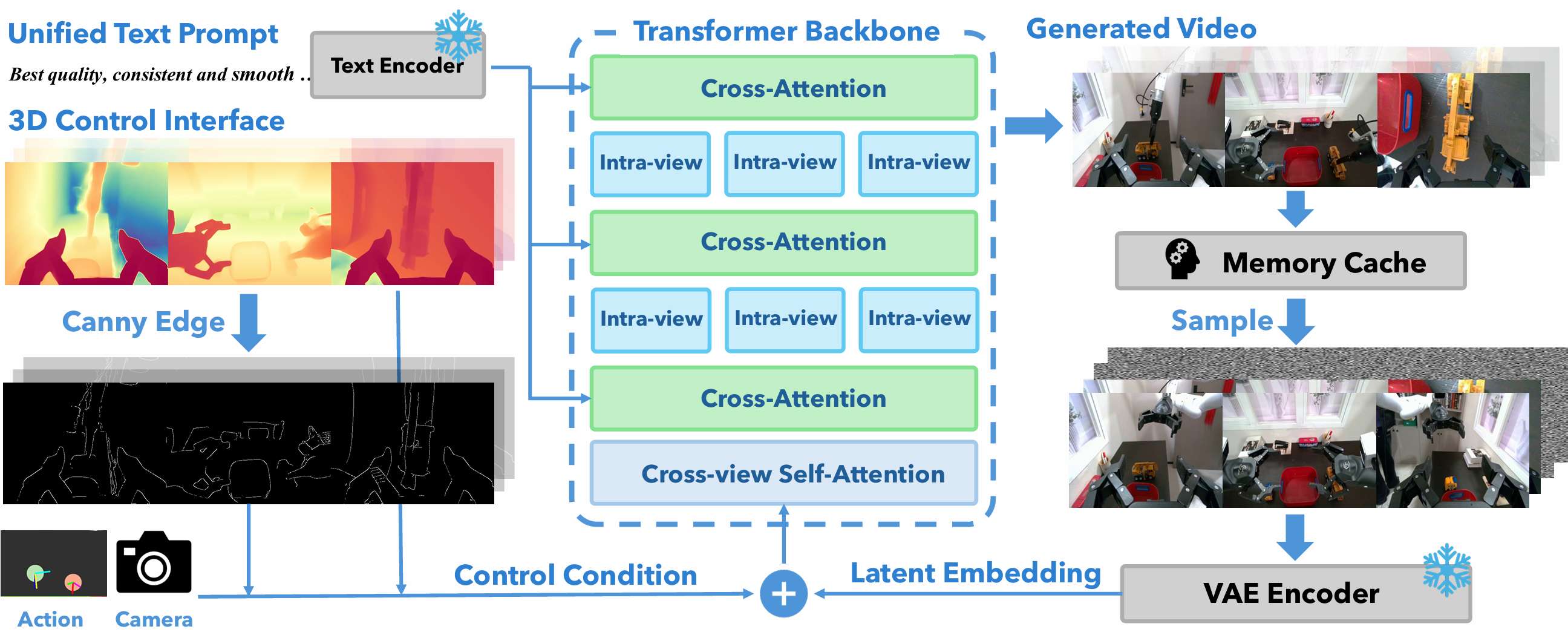
该模块基于DiT架构,将编辑后的深度图等 3D 控制信号转化回多视角 2D 视频。包含三个关键设计:
- 多条件控制接口: 将深度图作为主控制信号,并引入 Canny 边缘、机器人动作和射线图作为辅助输入。这些信号强制要求模型生成的视频必须符合 3D 几何结构。
- 双重注意力机制: 包含“视角内注意力”和“跨视角注意力”。前者负责捕捉单视角空间细节,后者负责确保多个相机(如头、左腕、右腕)在同一时间戳看到的物体是一致的。
- 平滑物体重定位: 通过插值技术将物体在起始位置和目标编辑位置之间建立平滑的移动轨迹,避免视频在第一帧出现物体突变的现象。
这一步利用可控视频生成技术,将 3D 编辑结果渲染为高保真的视频数据,并确保多视角之间的时间与空间一致性。
实验效果
论文在抓放、倒水、抬箱子、扫条形码等四个真机任务上进行了测试,覆盖单臂与双臂任务。
数据效率分析
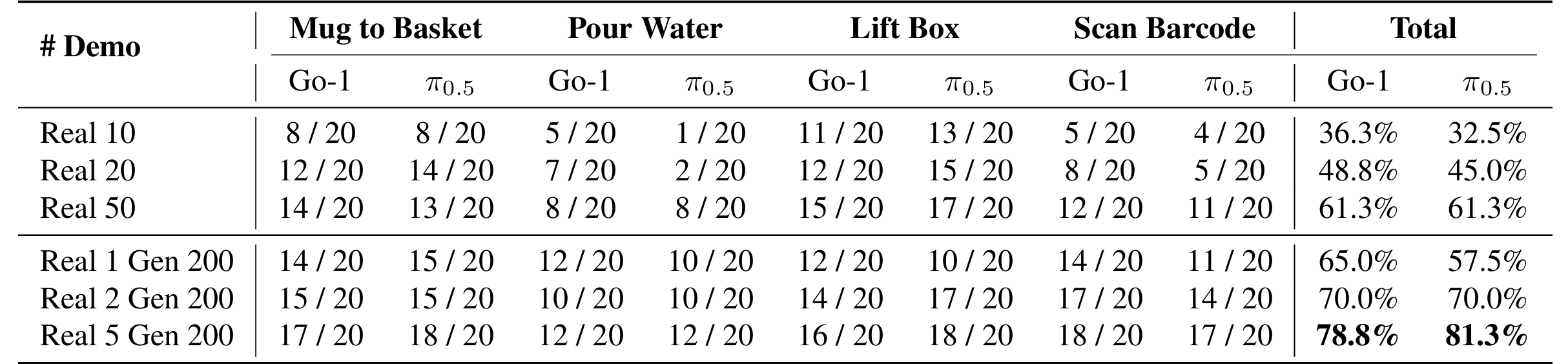
这两种策略仅利用1–5条真机数据,其表现便能媲美甚至超越那些利用50条手工采集数据的策略,数据效率提升10–50倍。
团队对比了仅使用少量真机数据生成与大规模纯手动采集数据的性能差异。
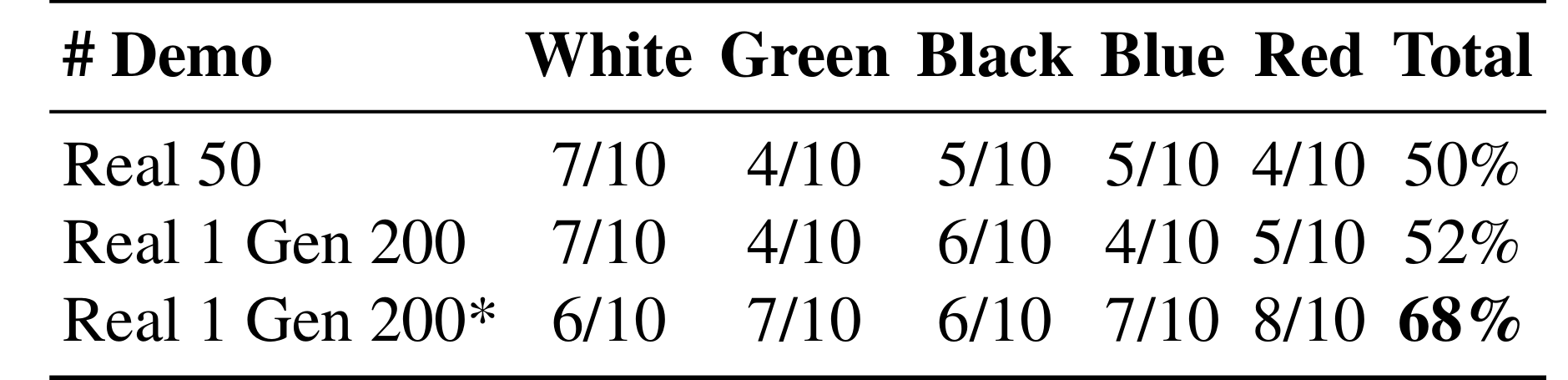
- 实验显示,仅通过1条真机数据生成的200条增强数据,训练出的策略性能就足以与50条手动采集的真机数据平起平坐。
- 当提供5条真机数据时,生成数据让π0.5策略的平均成功率直接冲到了81.3%。相比之下,即使费时费力采集了 50 条真机数据,成功率也仅在 60% 左右。这意味着该范式不仅省力,甚至优于人类反复操作。
纹理编辑与高度编辑


为了验证模型是否真的理解了物理空间,而非仅仅模仿像素,团队进行了超越原始分布的泛化测试。
- **纹理编辑:**团队在编辑时改变了首帧中桌面的颜色和纹理。结果显示,生成模型能够准确生成新纹理下的操作数据,使得机器人在面对全新纹理时依然能精准定位物体并完成交互。
- **高度编辑:**Real2Edit2Real 通过 3D 控制接口,可以精确修改物体的 Z 轴坐标。实验证明,即便原始数据都在低位进行,机器人也能在从未见过的高位任务中保持极高的操作准确度。
消融实验
为了探究 Real2Edit2Real 框架中核心模块的作用,团队进行了消融实验:

- 几何重建: 团队对比了预训练与真机-仿真混合微调的VGGT的重建效果。结果显示,通过模拟数据与真实数据的混合训练,系统消除了相机姿态漂移并有效滤除环境噪声,从而重建出具备准确真实尺度的3D场景,确保了后续所有编辑操作都基于真实的物理尺度。

- 姿态校正: 实验验证了姿态修正模块对数据生成的影响。结果表明,相比于不符合运动学的平移,姿态校正能够根据末端执行器的位姿,自动解算出符合运动学约束的关节配置,使生成的视频数据在物理上连贯且无视觉模糊,从而产生可供策略模型学习的有效数据。

- 平滑物体重定位: 实验还对比了去除平滑物体重定位模块带来的影响。该模块能够引导模型生成将物体移动到特定位姿的连续视频,解决了因物体位姿跳变而引起的形态崩溃问题,显著提升了生成视频数据的质量。
总结
Real2Edit2Real致力于绕过复杂的数字孪生与物理仿真,直接接入数采管线,将统一的 3D 控制接口的精确性与可控视频生成模型的真实性相结合,让少量的真机数据也能迸发出规模化的效果,为解决具身智能的数据采集难题提供了一条高效捷径。
We’re Hiring!
北大董豪团队持续招聘具身智能与世界模型实习生,欢迎投递简历:
hao.dong@pku.edu.cn
hwfan25@stu.pku.edu.cn
重磅!
VLA+RL方向首个系统教程来啦!Online RL/Offline RL/test time RL等~
推荐阅读
我们用低成本的机械臂完成pi0/pi0.5/GR00T/世界模型等VLA任务~
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?
1v1 科研论文辅导来啦!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)