深度学习ReLU激活函数详解(新手友好,附实战代码)
深度学习ReLU激活函数详解(新手友好,附实战代码)
摘要:ReLU(Rectified Linear Unit,修正线性单元)是深度学习中最常用、最基础的激活函数,没有之一。它的核心作用是给神经网络注入非线性,解决线性模型无法拟合复杂数据的问题,同时具备计算速度快、不易梯度消失的优势。本文避开复杂数学推导,只讲清ReLU基本原理,重点分享多框架实战代码、避坑技巧和实际应用,全程新手友好。
关键词:ReLU;激活函数;深度学习;实战代码;新手教程;梯度消失
一、开篇直击:为什么ReLU是深度学习“宠儿”?
做深度学习的同学肯定会发现,不管是CNN、MLP还是Transformer,隐藏层几乎清一色用ReLU作为激活函数——它没有Softmax的复杂计算,没有Sigmoid的梯度消失隐患,凭什么成为“标配”?
答案很简单:简单、高效、好用。
神经网络的核心是“拟合复杂数据”,而线性模型(比如y=wx+b)只能处理线性关系,无法应对图像、文本等复杂数据。激活函数的作用就是注入“非线性”,让模型能学习到复杂的特征映射。
而ReLU的优势的的是:计算极简单(判断输入是否大于0)、训练速度快,还能有效缓解梯度消失问题,这也是它能替代Sigmoid、Tanh,成为深度学习隐藏层“首选”的核心原因。
总结一句话:隐藏层用ReLU,高效又省心;输出层按需选(Softmax/Sigmoid),ReLU是构建深度学习模型的“基础组件”。
二、通俗理解:ReLU到底在做什么?
ReLU的逻辑简单到离谱,不用懂复杂理论,一句话就能说透:对输入的数值,大于0就保留原样,小于等于0就置为0。
用生活化的例子类比:就像我们筛选有用信息——有用的信息(输入>0)我们全部保留,没用的信息(输入≤0)直接丢弃,这样既能保留有效特征,又能简化计算。
举个直观例子:
假设神经网络某一层的输出(未经过激活)是[-3, 2.5, 0, 4, -1.2],经过ReLU处理后,结果会变成[0, 2.5, 0, 4, 0]。
核心逻辑:过滤负数值,保留正数值,注入非线性,同时让模型计算更高效(没有指数、对数运算)。
三、ReLU基本数学原理(点到即止,不堆砌)
不用记复杂推导,只需要掌握核心公式和2个关键特性,足够应对实战即可,这也是新手最需要掌握的内容。
3.1 核心公式(仅此一个,记牢够用)
设输入为x(可以是单个数值、向量或矩阵),ReLU的计算公式如下,简单到不用刻意记忆:
ReLU(x)=max(0,x)\text{ReLU}(x) = \max(0, x)ReLU(x)=max(0,x)
白话解释(不用懂推导):
-
当输入x > 0时,ReLU输出就是x本身(保留正数值);
-
当输入x ≤ 0时,ReLU输出就是0(过滤负数值);
-
核心作用:注入非线性,让模型能学习到复杂的特征映射,同时简化计算。
-
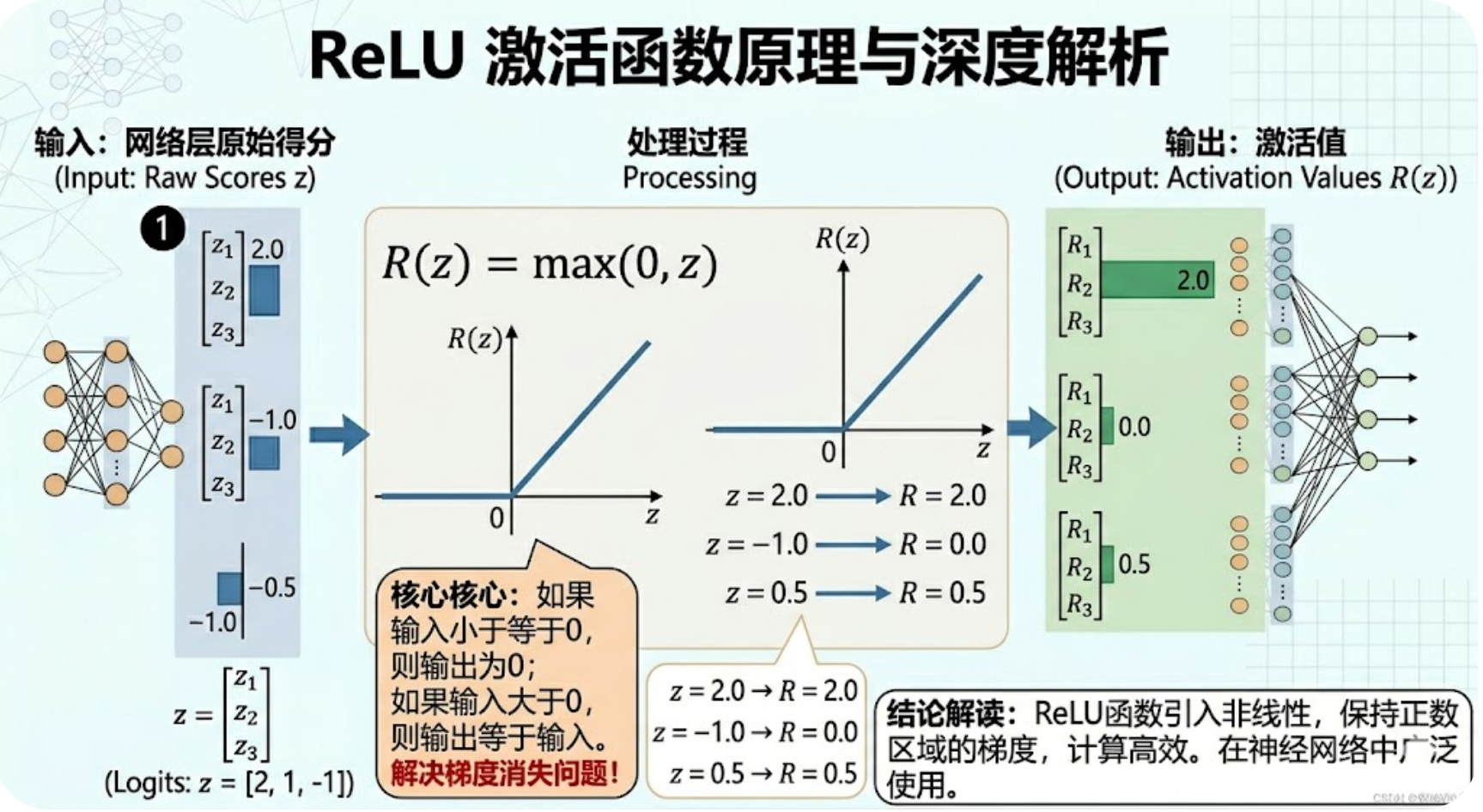
3.2 2个关键特性(了解即可,不用死记)
-
特性1:计算高效。仅需判断输入是否大于0,没有指数、对数等复杂运算,CPU/GPU计算速度极快,适合深层神经网络训练。
-
特性2:缓解梯度消失。当x > 0时,ReLU的导数为1,梯度能完整传递回前层,避免了Sigmoid函数中“梯度随层数增加而趋近于0”的问题,让深层网络能正常训练。
3.3 简单数值示例(直观验证)
已知输入向量x = [-5, 3, 0, 7.2, -2.1],代入ReLU公式计算:
-
逐个判断输入:-5≤0→0,3>0→3,0≤0→0,7.2>0→7.2,-2.1≤0→0;
-
最终输出:[0, 3, 0, 7.2, 0];
验证:符合ReLU“留正去负”的核心逻辑,计算简单,结果直观。
四、实战避坑:ReLU常见问题及解决方案(新手必看)
ReLU虽然简单,但实战中也有坑,新手很容易踩雷,重点讲2个最常见的问题,给出直接能用的解决方案,避免模型训练失败。
4.1 常见问题1:死亡ReLU(神经元坏死)
问题描述:训练过程中,部分神经元的输入始终≤0,导致ReLU输出一直为0,这些神经元无法更新参数(梯度为0),相当于“坏死”,模型性能下降。
解决方案(直接用,不用懂原理):
-
使用ReLU的变种(首选):比如Leaky ReLU、ReLU6,允许负输入有微小输出,避免神经元坏死;
-
调整学习率:学习率不要太大,避免参数更新幅度过大,导致神经元输入长期为负;
-
初始化参数:合理初始化神经网络权重(如Xavier初始化),让神经元输入尽量落在正区间。
4.2 常见问题2:输出无负值
问题描述:ReLU输出始终≥0,无法处理需要负输出的场景(如回归任务)。
解决方案:回归任务的输出层不用ReLU,直接用线性层(无激活);隐藏层仍可使用ReLU,不影响模型性能。
五、多框架实战代码(可直接复制运行,新手友好)
重点来了!以下代码覆盖NumPy(手动实现,理解底层)、PyTorch、TensorFlow,还有ReLU结合神经网络的完整实战案例,带详细注释,无需修改核心逻辑,复制就能运行,适合新手快速套用。
5.1 NumPy手动实现(理解底层逻辑)
import numpy as np
def relu(x: np.ndarray) -> np.ndarray:
"""
ReLU激活函数手动实现(新手可直接复制)
:param x: 输入(可单数值、向量、矩阵),shape任意
:return: ReLU处理后的输出,shape与输入一致
"""
# 核心逻辑:大于0保留,小于等于0置为0
return np.maximum(0, x)
# 测试代码(运行即可验证效果)
if __name__ == "__main__":
# 单数值测试
x_single = -2.5
print("单数值输入ReLU输出:", relu(x_single)) # 输出:0.0
# 向量测试
x_vector = np.array([-3, 2.5, 0, 4, -1.2])
print("向量输入ReLU输出:", relu(x_vector)) # 输出:[0. 2.5 0. 4. 0. ]
# 矩阵测试(模拟神经网络某一层输出)
x_matrix = np.array([[-1, 2], [3, -4], [0, 5]])
print("矩阵输入ReLU输出:\n", relu(x_matrix))
5.2 PyTorch实现(实战最常用)
PyTorch内置ReLU函数,支持批量处理,无需手动实现,重点注意:ReLU通常用在隐藏层,配合线性层使用。
import torch
import torch.nn.functional as F
# 1. 基础使用(直接调用ReLU函数)
x = torch.tensor([-3., 2.5, 0, 4., -1.2]) # 注意:必须是float类型
relu_output = F.relu(x)
print("PyTorch ReLU基础输出:", relu_output)
# 2. 结合线性层(模拟神经网络隐藏层)
# 定义线性层(输入维度5,输出维度3)+ ReLU激活
linear = torch.nn.Linear(5, 3)
x_batch = torch.randn(2, 5) # 2个样本,每个样本5维特征
hidden_output = F.relu(linear(x_batch))
print("\n隐藏层(线性层+ReLU)输出:\n", hidden_output)
print("输出形状:", hidden_output.shape) # 输出形状:(2, 3),与线性层输出一致
5.3 TensorFlow/Keras实现
用法与PyTorch类似,内置ReLU函数,可直接调用,也可在神经网络中作为激活函数参数传入,新手可直接套用。
import tensorflow as tf
# 1. 基础使用(直接调用ReLU函数)
x = tf.constant([-3., 2.5, 0, 4., -1.2])
relu_output = tf.nn.relu(x)
print("TensorFlow ReLU基础输出:", relu_output.numpy()) # numpy()转为数组,便于查看
# 2. 结合Keras线性层(模拟隐藏层)
# 方式1:先线性层,再ReLU
linear = tf.keras.layers.Dense(4, input_shape=(6,)) # 输入6维,输出4维
x_batch = tf.random.normal((3, 6)) # 3个样本,每个样本6维特征
hidden_output = tf.nn.relu(linear(x_batch))
print("\n隐藏层输出:\n", hidden_output.numpy())
# 方式2:线性层中直接指定ReLU激活(更简洁,实战常用)
dense_relu = tf.keras.layers.Dense(4, activation='relu', input_shape=(6,)) # 内置ReLU
hidden_output2 = dense_relu(x_batch)
print("\n简洁版隐藏层输出:\n", hidden_output2.numpy())
5.4 实战拓展:ReLU结合完整神经网络(PyTorch,可直接运行)
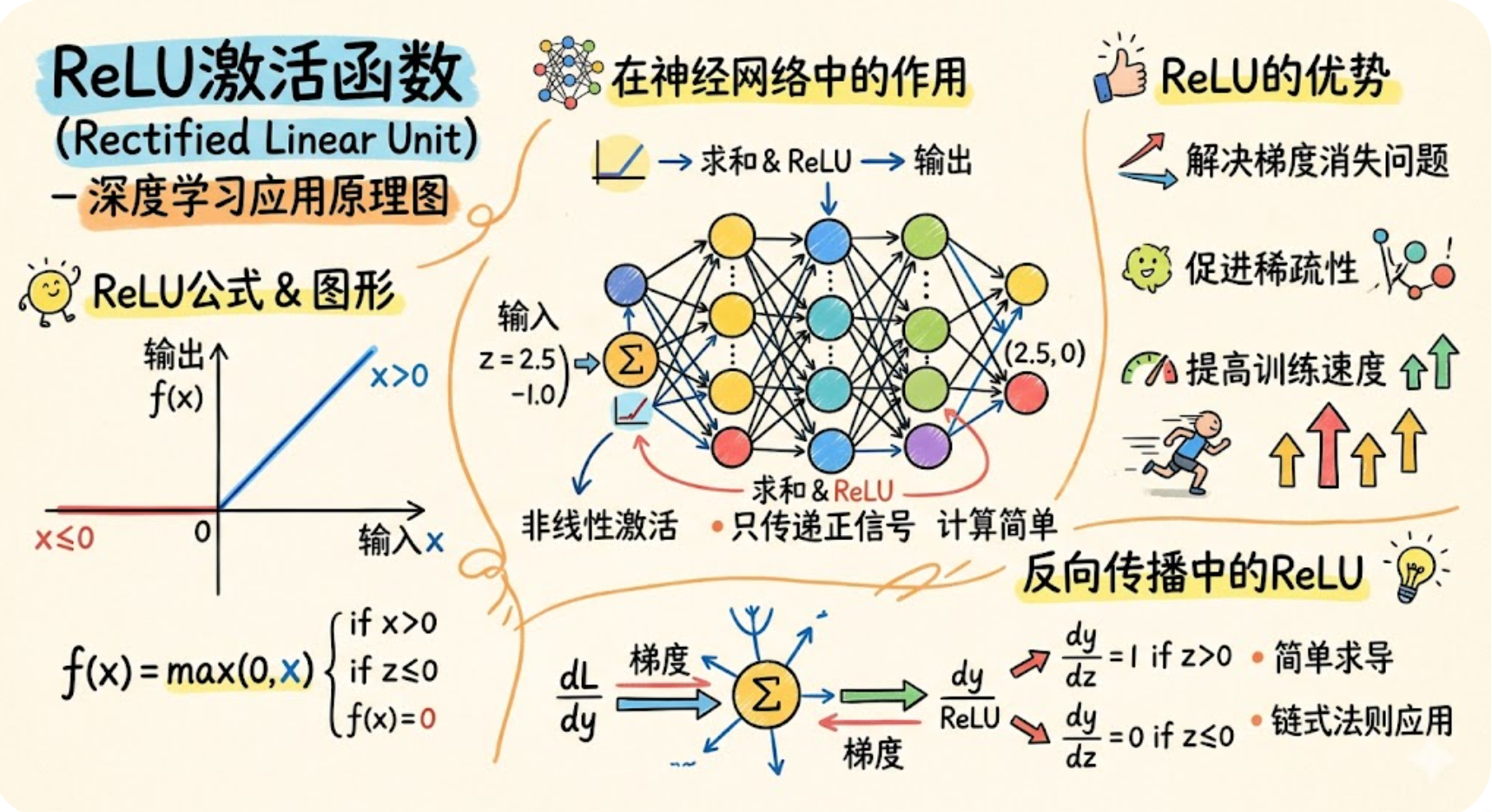
新增一个“ReLU+简单神经网络”的完整实战案例,模拟分类任务,帮你快速理解ReLU在实际模型中的应用,新手可直接复制运行,直观看到ReLU的作用。
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
# 1. 定义完整神经网络(输入层+2个隐藏层+输出层,隐藏层用ReLU)
class SimpleNet(nn.Module):
def __init__(self, input_dim, hidden_dim, num_classes):
super(SimpleNet, self).__init__()
# 输入层 -> 隐藏层1(ReLU激活)
self.fc1 = nn.Linear(input_dim, hidden_dim)
# 隐藏层1 -> 隐藏层2(ReLU激活)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
# 隐藏层2 -> 输出层(多分类用Softmax,ReLU用在隐藏层)
self.fc3 = nn.Linear(hidden_dim, num_classes)
# ReLU激活函数(可单独定义,也可直接调用F.relu)
self.relu = nn.ReLU()
def forward(self, x):
# 前向传播:输入 -> 隐藏层1 -> ReLU -> 隐藏层2 -> ReLU -> 输出层
out = self.fc1(x)
out = self.relu(out) # 隐藏层1激活
out = self.fc2(out)
out = self.relu(out) # 隐藏层2激活
out = self.fc3(out)
return out
# 2. 初始化模型、损失函数、优化器
input_dim = 8 # 输入特征维度(模拟数据)
hidden_dim = 16 # 隐藏层神经元数量
num_classes = 2 # 二分类任务(可修改为多分类)
model = SimpleNet(input_dim, hidden_dim, num_classes)
# 损失函数:交叉熵损失(二分类/多分类通用)
criterion = nn.CrossEntropyLoss()
# 优化器:随机梯度下降(新手友好,易调试)
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 3. 模拟训练数据(10个样本,每个样本8维特征,标签为0/1)
x_train = torch.randn(10, input_dim) # 模拟输入特征
y_train = torch.tensor([0, 1, 0, 1, 0, 1, 0, 1, 0, 1]) # 模拟标签
# 4. 简单训练(5轮,便于新手理解)
for epoch in range(5):
model.train() # 切换训练模式
optimizer.zero_grad() # 清空梯度
logits = model(x_train) # 模型输出(未经过Softmax)
loss = criterion(logits, y_train) # 计算损失
loss.backward() # 反向传播求梯度
optimizer.step() # 更新模型参数
print(f"第{epoch+1}轮训练,损失值:{loss.item():.4f}")
# 5. 测试模型(查看ReLU激活后的隐藏层输出)
with torch.no_grad(): # 禁止梯度计算,节省资源
x_test = torch.randn(1, input_dim) # 单个测试样本
# 查看隐藏层1的输出(经过ReLU激活)
hidden1_out = model.relu(model.fc1(x_test))
print("\n测试样本 - 隐藏层1(ReLU激活后)输出:\n", hidden1_out.numpy())
# 查看最终输出(可通过Softmax转为概率)
logits_test = model(x_test)
prob_test = F.softmax(logits_test, dim=-1)
print("测试样本 - 最终概率分布:", prob_test.numpy().round(4))
print("测试样本 - 预测类别:", torch.argmax(prob_test).item())

样例说明:该代码完整模拟了“ReLU+神经网络”的训练流程,ReLU仅用在隐藏层,负责注入非线性,输出层用Softmax做分类。代码注释详细,新手可直接运行,直观看到ReLU如何处理隐藏层输出,以及模型训练过程。
六、ReLU vs 其他激活函数(选型口诀,记牢不踩坑)
新手常混淆ReLU与其他激活函数,不用记复杂理论,看表格+口诀,就能快速选型,避免用错场景。
| 对比维度 | ReLU | Sigmoid | Softmax |
|---|---|---|---|
| 适配场景 | 神经网络隐藏层(首选) | 二分类输出层、多标签分类 | 单标签多分类输出层 |
| 核心优势 | 计算快、缓解梯度消失、不易过拟合 | 输出在(0,1),可解读为概率 | 概率和为1,适配多分类 |
| 常见缺点 | 存在死亡ReLU、无负输出 | 梯度消失、计算较慢 | 存在指数溢出、计算开销高 |
| 选型口诀(记牢够用):隐藏层用ReLU,二分类输出用Sigmoid,单标签多分类输出用Softmax。 |
七、ReLU常见应用场景(实战必知)
ReLU的应用场景非常广泛,几乎所有深度学习模型的隐藏层都能用到,重点记3个高频场景,新手实战中一定会遇到:
-
神经网络隐藏层(核心场景):CNN、MLP、Transformer、RNN等模型的隐藏层,优先使用ReLU,提升训练速度,缓解梯度消失,让深层网络能正常训练。
-
计算机视觉任务:图像分类、目标检测、图像分割等任务中,CNN的卷积层之后,必用ReLU激活,提取复杂的图像特征。
-
自然语言处理任务:文本分类、情感分析、BERT微调等任务中,Transformer的隐藏层,常用ReLU及其变种(如GELU),提升模型训练效率和性能。
八、ReLU优缺点(简化版,实战够用)
8.1 优点
-
计算高效:仅需判断输入是否大于0,无复杂运算,CPU/GPU加速明显,适合深层网络。
-
缓解梯度消失:x>0时导数为1,梯度能完整传递,解决了Sigmoid/Tanh的梯度消失问题。
-
稀疏性优势:过滤负数值,让模型输出具有稀疏性,减少冗余特征,提升模型泛化能力。
-
实战友好:主流框架内置实现,无需手动推导,新手可快速上手,适配绝大多数深度学习任务。
8.2 缺点(避坑重点)
-
死亡ReLU:训练中部分神经元可能长期输出0,无法更新参数,导致模型性能下降(解决方案见第四部分)。
-
无负输出:无法处理需要负输出的场景(如回归任务),输出层需改用线性层。
-
对学习率敏感:学习率过大会导致大量神经元坏死,需合理调整学习率。
九、总结(新手必看)
ReLU其实很简单,不用被“激活函数”“非线性”这些术语吓住,核心总结3点,记牢就能应对实战:
-
核心作用:给神经网络注入非线性,让模型能拟合复杂数据,同时缓解梯度消失,提升训练速度。
-
核心公式:记住 ReLU(x)=max(0,x)\text{ReLU}(x) = \max(0, x)ReLU(x)=max(0,x) 即可,实战中直接调用框架内置函数,无需手动实现。
-
关键避坑:注意死亡ReLU问题,可选用Leaky ReLU变种、调整学习率,避免模型训练失败。
对于深度学习新手来说,掌握ReLU的基本原理和实战代码,就能轻松构建深层神经网络,后续随着实战经验增加,再逐步尝试ReLU的变种(Leaky ReLU、GELU),进一步优化模型性能即可。
参考资料
-
PyTorch官方文档:torch.nn.ReLU 详细说明
-
TensorFlow官方文档:tf.nn.relu 实现细节
-
深度学习实战:ReLU激活函数的应用技巧与避坑指南
-
基于数据集细分及波段筛选的船只检测方法研究
如果本文对你有帮助,欢迎点赞、收藏、关注!
(注:文档部分内容可能由 AI 生成)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 12
12 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)