(二)人工智能算法之监督学习——线性回归
一、核心定义
线性回归是有监督、回归任务里最基础、最经典的机器学习算法。
核心目标:
用一条直线(一元)/ 超平面(多元),拟合自变量 X 和连续型因变量 Y 之间的线性相关关系,用来做数值预测。
二、适用场景
线性与非线性的区别
△线性: 两个变量之间的关系是一次函数关系的——图象是直线,叫做线性。
注意:线性是指广义的线性,也就是数据与数据之间的关系。
△非线性: 两个变量之间的关系不是一次函数关系的——图象不是直线,叫做非线性。
到底什么时候可以使用线性回归呢?统计学家安斯库姆给出了四个数据集,被称为安斯库姆四重奏: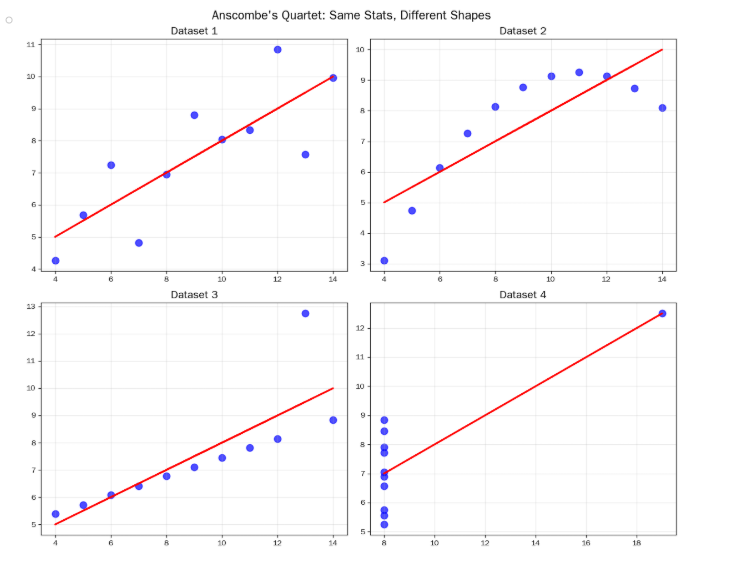
这 4 组数据:
均值几乎一样
方差几乎一样
相关系数几乎一样
线性回归方程几乎一样
但画出来完全不同:
数据集 1:正常线性关系
数据集 2:曲线关系(线性回归完全错误)
数据集 3:有一个异常点(干扰结果)
数据集 4:x 几乎不变,靠一个点强行拉出直线
================================================
安斯库姆四重奏 → 线性回归 5 大假设(必背)
每一条,都能在这 4 张图里找到铁证:
- 线性回归必须满足 线性关系假设
数据集 1:完美线性 ✅
数据集 2:明显曲线关系 ❌
结论:非线性数据强行用线性回归,结果完全错误。 - 误差项必须服从 正态分布,均值为 0
数据集 4:一个极端 outliers 强行拉出直线
误差分布严重偏离正态 ❌
结论:异常值会毁掉线性模型。 - 误差必须 同方差(齐方差)
误差不能随 x 变大 / 变小
图 2、图 3、图 4 都不满足 ❌ - 自变量 x 必须 有变异、有波动
数据集 4:x 几乎全是 8,只有一个 19
x 几乎无变化 ❌
结论:x 没波动,模型学不到任何规律。 - 多元线性回归:特征之间 相互独立、无多重共线性
特征不能互相推导
否则模型权重失效 ❌
====================================================
从这四个数据集的分布可以看出,并不是所有的数据集都可以用一元线性回归来建模。现实世界中的问题往往更复杂,变量几乎不可能非常理想化地符合线性模型的要求。因此使用线性回归,需要遵守下面几个假设:
1.线性回归是一个回归问题。
2.要预测的变量 y 与自变量 x 的关系是线性的(图2 是一个非线性)。
3.各项误差服从正太分布,均值为0,与 x 同方差(图4 误差不是正太分布)。
4.变量 x 的分布要有变异性。
5.多元线性回归中不同特征之间应该相互独立,避免线性相关。
●核心启示
先可视化数据,再建立模型!
不看图 → 必被数据欺骗
二、两种基础分类
1. 一元线性回归(单特征)
只有 1 个输入特征 x,拟合一条二维直线公式:y=wx+b
y:预测值(目标变量,连续数值,如房价、分数)
w:权重 / 斜率,代表 x 对 y 的影响大小
b:偏置 / 截距,基线修正项
举例:
核心含义:展示「受教育年限」与「收入」之间的正线性关系
残差线:黑色竖线长度代表模型预测的误差大小,线越长说明预测偏差越大
图像: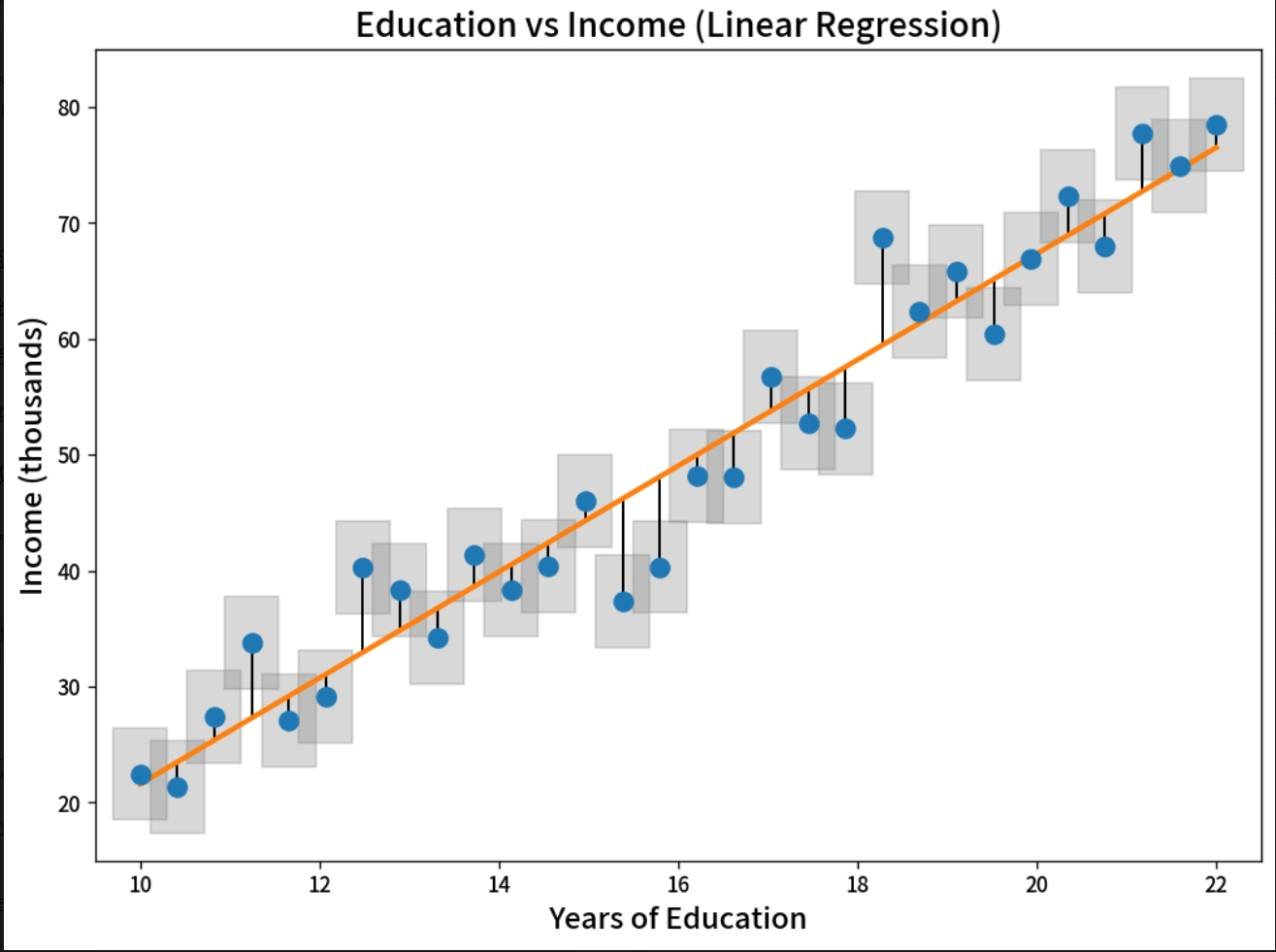
2. 多元线性回归(多特征)
有多个输入特征 x1, x2 … xn,
拟合高维超平面公式: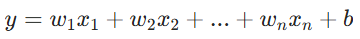
举例:用「面积、房龄、地段」多个特征预测房价
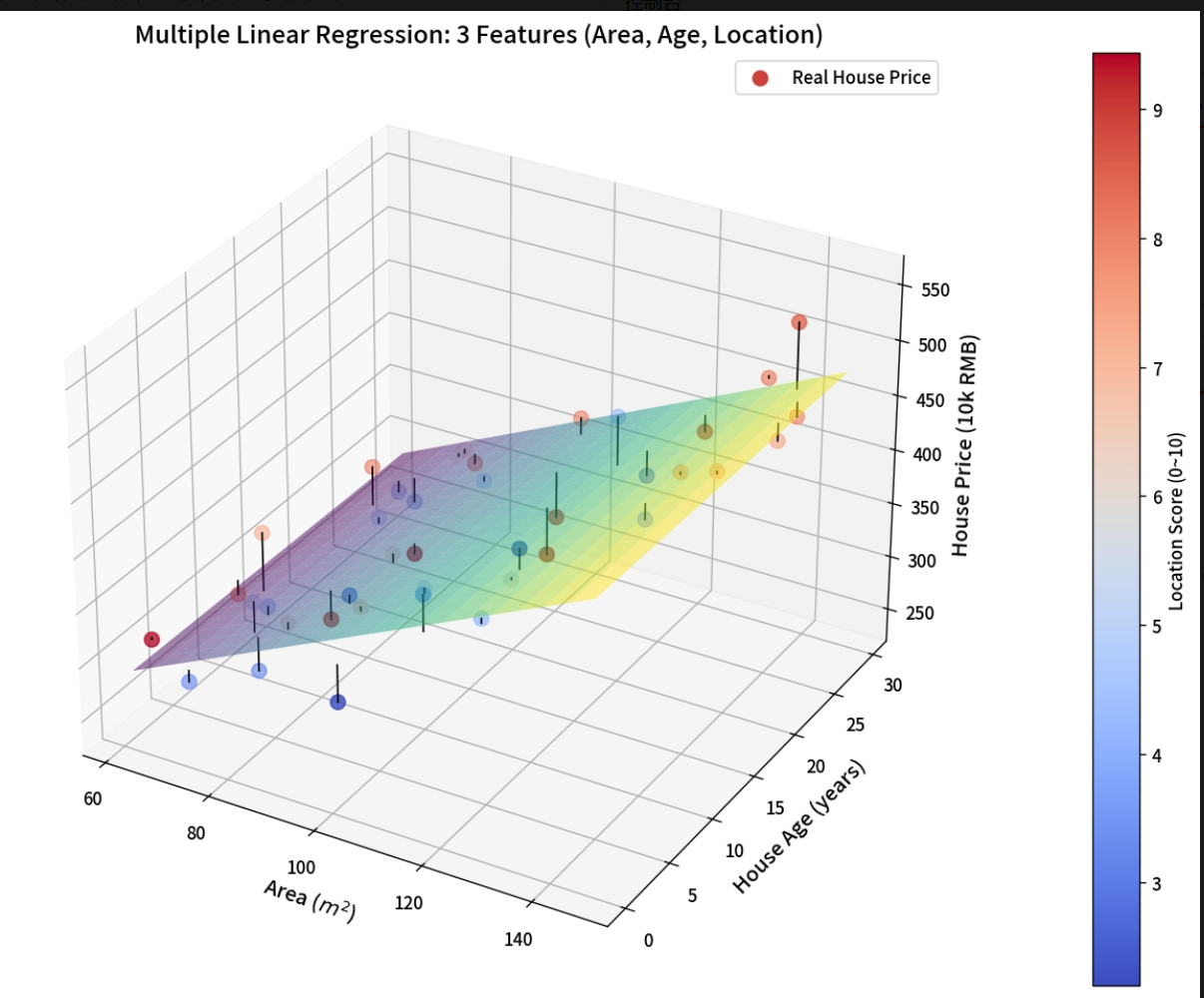
图表元素说明:
X 轴:房屋面积(m 2)
Y 轴:房龄(年)
Z 轴:房价(单位:十万元)
彩色渐变平面:多元线性回归拟合出的超平面,代表模型学到的「面积 + 房龄 + 地段→房价」的线性规律
红色 / 蓝色散点:真实房价样本点,颜色代表地段评分(暖色调 = 地段好,冷色调 = 地段差)
黑色竖线:连接每个真实点到拟合平面,直观展示残差(预测误差),线越长说明预测偏差越大
三、算法底层原理(核心思想)
1.初始化随机的w 和 b,得到初始预测线定义损失函数(平方误差损失 MSE)衡量真实值和预测值的差距: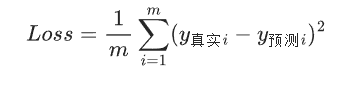
2.意义:让所有样本的误差平方和最小, 这条线就是最优拟合线
3.求解最优参数
两种解法:
正规方程:一步直接算出最优 w、b,小数据集超快
梯度下降:迭代优化,不断减小损失,大数据、深度学习通用
四、适用场景 & 优缺点
✅ 优点
简单易懂、可解释性极强(权重 w 能看特征影响力)
训练快、计算成本低、不易过拟合
输出连续数值,适配绝大多数基础预测场景
❌ 缺点
仅拟合线性关系,无法捕捉非线性规律
对异常值、噪声极度敏感
特征多重共线性会严重影响模型效果
📌 典型业务场景
教育:用学情数据预测学生考试分数(贴合你的教学场景)
金融:销量预测、营收预估
房产:房价估价
五、补充实操小要点(教学 / 数据分析可用)
数据预处理:归一化、剔除异常值、检验共线性
评价指标: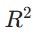 (拟合优度,越接近 1 效果越好)、MAE、MSE
(拟合优度,越接近 1 效果越好)、MAE、MSE
不满足线性时:可升级多项式回归,拟合曲线
六:实操代码:
1.一元线性回归
# ====================== 【1】导入需要用到的工具库 ======================
# numpy:用来生成数据、做数学计算
import numpy as np
# matplotlib:用来画图,可视化展示
import matplotlib.pyplot as plt
# LinearRegression:sklearn 内置的线性回归模型
from sklearn.linear_model import LinearRegression
# 评价指标:MSE均方误差、R²决定系数,用来评估模型好坏
from sklearn.metrics import mean_squared_error, r2_score
# ====================== 【2】构造模拟数据(学习时长 → 考试分数) ======================
# 固定随机种子,保证每次运行生成的数据完全一样,方便教学演示
np.random.seed(42)
# 生成自变量 x:学习时长(1~10小时,共50个数据点)
# reshape(-1,1):把数据变成二维格式,sklearn 要求输入必须是二维
x = np.linspace(1, 10, 50).reshape(-1, 1)
# 生成因变量 y:考试分数
# 真实关系:分数 = 6 * 学习时长 + 20
# 加上随机噪声 np.random.randn(),模拟真实学生成绩的波动
y = 6 * x + 20 + np.random.randn(50, 1) * 3
# ====================== 【3】创建线性回归模型 ======================
# 初始化模型对象
model = LinearRegression()
# 训练模型:让模型学习 x 和 y 的关系
model.fit(x, y)
# 输出训练好的模型参数(对应公式 y = w*x + b)
print(f"斜率 w = {model.coef_[0][0]:.2f}") # w:x对y的影响程度
print(f"截距 b = {model.intercept_[0]:.2f}") # b:基准分数
# ====================== 【4】用训练好的模型做预测 ======================
# 输入 x,让模型预测分数 y
y_pred = model.predict(x)
# ====================== 【5】模型效果评估 ======================
# 均方误差 MSE:预测值和真实值的平均误差平方,越小越好
mse = mean_squared_error(y, y_pred)
# 决定系数 R²:拟合优度,越接近1说明模型拟合得越好
r2 = r2_score(y, y_pred)
# 打印评估结果
print(f"均方误差 MSE = {mse:.2f}")
print(f"决定系数 R² = {r2:.2f}")
# ====================== 【6】绘图可视化(无中文,避免报错) ======================
# 解决负号显示异常问题
plt.rcParams['axes.unicode_minus'] = False
# 绘制散点图:蓝色点代表真实的成绩数据
plt.scatter(x, y, color='blue', label='Real Data')
# 绘制直线:红色线代表模型学到的拟合直线
plt.plot(x, y_pred, color='red', linewidth=2, label='Fitted Line')
# 设置坐标轴标签
plt.xlabel('Study Hours') # x轴:学习时长
plt.ylabel('Score') # y轴:考试分数
plt.title('Linear Regression Demo') # 图表标题
plt.legend() # 显示图例
plt.show() # 展示图片
运行结果如下: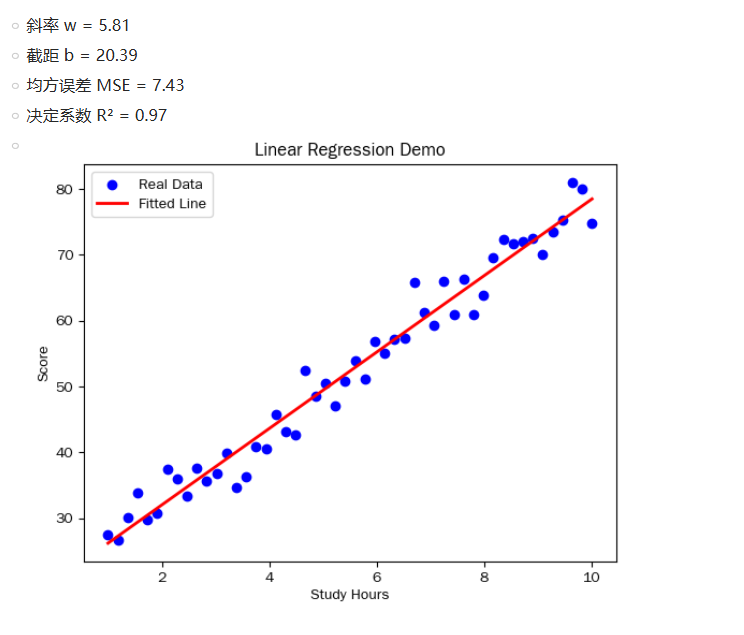
2.多元线性回归
2 个特征版本
预测分数的版本:
特征 1:学习时长
特征 2:刷题数量
→ 共同预测考试分数,完美适配课堂讲解!
# ====================== 【1】导入工具库 ======================
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# ====================== 【2】生成 多特征 模拟数据 ======================
np.random.seed(42) # 固定随机种子,保证结果可复现
# 特征1:学习时长(小时),50个样本
study_hours = np.linspace(1, 10, 50)
# 特征2:刷题数量(题数),50个样本
practice = np.linspace(5, 50, 50)
# 把两个特征 合并成 二维特征矩阵(多元回归要求输入X是二维)
X = np.column_stack((study_hours, practice))
# 生成真实分数 y:分数 = 3*时长 + 0.5*刷题数 + 15 + 噪声
y = 3 * study_hours + 0.5 * practice + 15 + np.random.randn(50) * 2
# ====================== 【3】训练 多元线性回归模型 ======================
model = LinearRegression()
model.fit(X, y) # 用多特征训练模型
# 输出模型公式:y = w1*x1 + w2*x2 + b
print("===== 多元线性回归模型参数 =====")
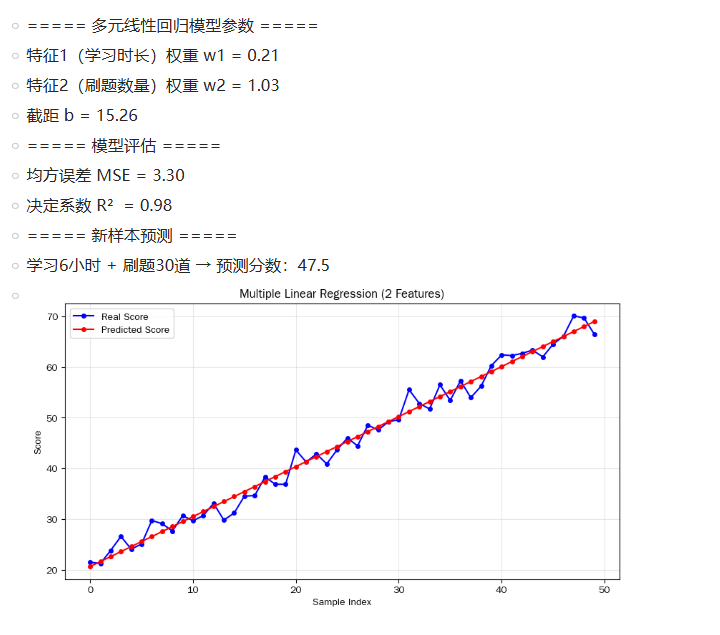
print(f"特征1(学习时长)权重 w1 = {model.coef_[0]:.2f}")
print(f"特征2(刷题数量)权重 w2 = {model.coef_[1]:.2f}")
print(f"截距 b = {model.intercept_:.2f}")
# ====================== 【4】模型预测与评估 ======================
y_pred = model.predict(X)
mse = mean_squared_error(y, y_pred)
r2 = r2_score(y, y_pred)
print(f"\n===== 模型评估 =====")
print(f"均方误差 MSE = {mse:.2f}")
print(f"决定系数 R² = {r2:.2f}")
# ====================== 【5】可视化(真实值 vs 预测值) ======================
plt.rcParams['axes.unicode_minus'] = False
# 绘制:真实分数(蓝色)、预测分数(红色)
plt.figure(figsize=(10, 5))
plt.plot(y, 'bo-', label='Real Score', markersize=4)
plt.plot(y_pred, 'ro-', label='Predicted Score', markersize=4)
plt.xlabel('Sample Index')
plt.ylabel('Score')
plt.title('Multiple Linear Regression (2 Features)')
plt.legend()
plt.grid(alpha=0.3)
plt.show()
# ====================== 【6】实战预测(新学生分数预测) ======================
# 输入:[学习时长, 刷题数量]
new_student = [[6, 30]]
score_pred = model.predict(new_student)
print(f"\n===== 新样本预测 =====")
print(f"学习6小时 + 刷题30道 → 预测分数:{score_pred[0]:.1f}")
运行结果:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)