LangChain详解:大模型应用开发框架(通俗理解+专业解析+Python实战)
LangChain详解:大模型应用开发框架(通俗理解+专业解析+Python实战)
摘要:随着大语言模型(LLM)的普及,单纯调用模型API已无法满足复杂业务需求——如何让大模型“记住”对话历史、“调用”外部工具、“处理”本地文档?LangChain作为开源的大模型应用开发框架,通过组件化设计,完美解决了这些痛点,成为大模型落地的“必备工具”。本文从通俗类比、专业解析、核心组件、基础实战、避坑技巧五个维度,完整讲解LangChain的核心价值与使用方法,助力开发者快速上手,高效构建LLM应用。
关键词:LangChain;大模型应用开发;LLM;Python;Prompt模板;Chain;Agent;Memory
一、引言:为什么需要LangChain?
在大模型应用开发中,我们常遇到这样的困境:
-
直接调用GPT、LLaMA等模型API,每次对话都是“一次性交互”,模型记不住上一轮的内容(无记忆);
-
想让模型处理本地PDF、Excel文档,或调用搜索引擎、计算器,却无法实现灵活对接(无工具调用能力);
-
复杂任务需要多步操作(如“翻译→总结→生成报告”),需手动拼接代码,开发效率极低(无流程编排能力)。
LangChain的核心价值的就是“打破这些困境”——它不训练大模型,也不替代大模型,而是作为“大模型的连接器与工具箱”,将大模型与外部资源(文档、工具、数据库)串联起来,让原本“只会聊天”的大模型,变成能处理复杂任务的“多面手”,大幅降低LLM应用的开发门槛。
如今,LangChain已成为大模型应用开发的行业标准,广泛用于智能问答、对话机器人、文档分析、自动化报告生成等场景,是算法工程师、AI开发者必备的核心工具之一。
二、通俗理解LangChain:不用“从零造轮子”,只需“搭积木”
很多新手刚接触LangChain时,会被“组件”“链”“代理”等术语吓住,其实它的逻辑特别简单,用两个生活化类比,就能彻底搞懂,全程无复杂概念。
2.1 类比1:大模型是“聪明但不会干活”的新人,LangChain是它的“工作手册+工具箱”
我们把**大模型(如GPT-4、LLaMA)**比作一个刚入职、智商极高但毫无工作经验的新人:
-
新人很聪明(大模型理解能力、生成能力强),但记不住事情——你上午跟他说的工作要求,下午他就忘了(对应大模型“无记忆”,每次API调用都是独立的);
-
新人不会用工具——让他算一个复杂数据,他不会用计算器;让他查最新资讯,他不会用搜索引擎(对应大模型“无工具调用能力”,知识截止到训练数据);
-
新人不会串联任务——让他完成“整理文档→提取重点→生成报告”,他不知道先做什么、后做什么,需要你一步步指挥(对应大模型“无流程编排能力”)。
而LangChain,就是给这个新人配备的“工作手册+工具箱”:
-
工作手册(PromptTemplate):提前写好标准话术,告诉新人“该做什么、怎么做”,不用每次都重复指挥;
-
笔记本(Memory):让新人把重要信息记下来,下次交流时能快速回忆,不用反复重复;
-
工具箱(Tools):给新人配备计算器、搜索引擎、文档阅读器等工具,让他能自主完成复杂任务;
-
任务清单(Chain):把复杂任务拆成多步,让新人按顺序执行,不用你一步步指挥;
-
主管(Agent):如果任务复杂,让主管帮新人判断“该用什么工具、先做哪步”,自主完成工作。
2.2 类比2:大模型是“手机”,LangChain是“应用商店+系统管家”
另一个更直观的类比:大模型就像一台性能强大的手机,本身具备通话、上网等基础功能(对应大模型的文本生成、理解能力);而LangChain就像手机的“应用商店+系统管家”:
-
应用商店(Tools):提供各种“APP”(搜索引擎、文档处理工具、数据库查询工具),让手机能完成更多复杂功能(如查天气、办公、购物);
-
系统管家(Chain+Agent):把多个APP串联起来,完成单一APP做不到的复杂操作(如“打开地图→查路线→叫车”),还能自动判断该用哪个APP;
-
记忆功能(Memory):记住你的使用习惯(如常用APP、聊天记录),让体验更流畅。
核心结论:LangChain的本质就是“模块化+流程化”——把大模型的能力拆成独立组件,再按业务需求像搭积木一样组合,让开发者不用从零编码,就能快速构建复杂的LLM应用,实现“用大模型解决实际问题”。
三、LangChain专业解析:定义、核心价值与核心组件
3.1 什么是LangChain?
LangChain是一个开源的大模型应用开发框架,由Python和JavaScript库组成,核心目标是“增强大模型的能力,降低LLM应用的开发门槛”。它通过标准化的接口,将大模型与外部数据、工具、记忆系统连接起来,支持组件的自由组合,实现端到端的LLM应用开发。
关键补充:LangChain不生产大模型,也不替代大模型,而是作为“中间层”,解决大模型“不会记忆、不会调用工具、不会串联任务”的核心痛点,让大模型从“嘴炮工具”变成“落地神器”。
3.2 LangChain的核心价值
-
组件化设计:将LLM应用的核心模块(提示、记忆、工具等)拆分成独立组件,可自由组合、复用,降低开发成本;
-
多模型兼容:统一了主流大模型的调用接口,支持OpenAI、LLaMA、ChatGLM、通义千问等,切换模型无需重写代码;
-
外部资源对接:无缝对接外部文档(PDF、Excel)、数据库(MySQL、MongoDB)、工具(搜索引擎、计算器),扩展大模型的能力边界;
-
流程编排能力:通过Chain、Agent实现多步骤任务的自动化执行,无需手动干预;
-
低代码开发:提供丰富的预置组件和模板,开发者可快速搭建原型,加速LLM应用落地。
3.3 LangChain核心组件(必懂,奠定实战基础)
注意:模块组件名称随着langchain版本的更新会发生变化,具体看下载了什么版本的langchain。
LangChain的所有功能,都基于6个核心组件的组合,理解这些组件,就掌握了LangChain的“积木块”,后续实战就能灵活运用。每个组件先讲通俗理解,再讲专业用法,新手也能轻松掌握。

3.3.1 Models(模型组件)——大模型的“大脑”
通俗理解:就是我们要调用的大模型,是整个应用的“智能来源”,负责理解文本、生成内容。
专业解析:LangChain封装了两类核心模型接口,统一了调用方式,无需关注不同模型的API差异:
-
LLM:输入文本,输出文本(如GPT-3.5的text-davinci-003),适合文本生成、摘要等场景;
-
ChatModel:输入“消息列表”(用户消息、系统提示),输出“消息”(如GPT-4、ChatGLM),更适合对话场景。
核心作用:提供智能能力,是所有LangChain应用的基础。
3.3.2 Prompts(提示组件)——给大模型的“指令脚本”
通俗理解:就是提前定义好的“标准话术”,告诉大模型“该做什么”,避免手动拼接字符串的麻烦,让输出更规范。
专业解析:核心是PromptTemplate(提示模板),支持动态传入变量,生成个性化提示词。比如定义一个“产品起名”模板,传入不同产品名称,就能自动生成对应的提示词。
核心作用:精准控制大模型的输出,规范提示词格式,提升开发效率。
3.3.3 Chains(链组件)——组件的“连接器”
通俗理解:把多个组件(模型、提示、记忆)按顺序串联起来,形成完整的任务流程,就像“流水线”一样,自动完成多步操作。
专业解析:LangChain提供多种预置链,满足不同场景需求:
-
LLMChain:最基础的链,由“提示模板+模型”组成,直接输出结果;
-
SequentialChain:按顺序执行多个链,前一个链的输出作为后一个链的输入(如“翻译→总结”);
-
RouterChain:根据输入内容,自动选择对应的链执行(如判断问题类型,再调用问答链或翻译链)。
核心作用:实现多步骤任务的自动化,避免手动拼接代码。
3.3.4 Memory(记忆组件)——大模型的“笔记本”
通俗理解:保存对话历史或中间结果,让大模型“记住”之前的内容,实现连贯的多轮对话。
专业解析:LangChain提供多种记忆类型,适配不同场景:
-
ConversationBufferMemory:简单保存所有对话历史,适合短对话;
-
ConversationSummaryMemory:自动总结对话历史,适合长对话(避免输入Token超标);
-
ConversationTokenBufferMemory:按Token数量保存历史,精准控制输入长度。
核心作用:解决大模型“健忘”的痛点,实现自然、连贯的多轮交互。
3.3.5 Tools(工具组件)——大模型的“外挂能力”
通俗理解:给大模型配备的“工具包”,让大模型能调用外部资源,弥补自身缺陷(如知识滞后、不会计算)。
专业解析:LangChain支持多种内置工具,也可自定义工具:
-
搜索引擎:如Google Search、百度搜索,获取实时信息;
-
计算工具:如llm-math,完成精确的数学计算;
-
文档工具:如PDFLoader、CSVLoader,读取本地文档;
-
数据库工具:如SQLDatabase,查询MySQL、PostgreSQL等数据库;
-
自定义工具:编写自己的函数(如查天气、调用内部API),对接业务系统。
核心作用:扩展大模型的能力边界,让大模型从“凭记忆回答”变成“能主动获取信息”。
3.3.6 Agents(代理组件)——工具的“决策者”
通俗理解:给大模型配的“主管”,负责分析用户问题,判断“是否需要调用工具”“调用哪个工具”“按什么顺序调用”,自主完成复杂任务。
专业解析:Agent会根据用户输入,结合工具的描述,制定执行计划,调用工具获取结果,再整理成最终答案。常见类型:
-
Zero-shot React Description:根据工具描述,直接判断调用哪个工具,适合简单场景;
-
Conversational React Description:带记忆的代理,结合对话历史判断工具调用,适合对话场景;
-
Structured Input:处理结构化数据(如表格)的代理,适合数据分析场景。
核心作用:实现复杂任务的自主决策,无需开发者手动指定工具调用逻辑。
四、LangChain基础实战:Python入门(可直接运行)
本节基于Python,实现LangChain的基础用法,涵盖核心组件的使用,代码带详细注释,新手可直接复制运行,快速上手。如果想使用更稳定版的可以下载v0.3.x版本。以下代码使用的是最新版本。

以下代码版本:
-
Name: langchain Version: 1.2.13
-
Name: langchain-classic Version: 1.0.3
-
Name: langchain-community Version: 0.4.1
-
Name: langchain-core Version: 1.2.23
特别注意langchain的包的导入,因为langchain的更新后会将包拆分到不同模块,所以路径会不同,并且在新版本中有些模块的调用名以及方式都不同需要注意。同时在该案例中使用的是使用ollama本地部署的一个千问的小模型,如果想用其他模型可以从ollama中下载或者使用API调用。如果使用本地部署的ollama中的模型,需要先启动ollama服务,在命令行中启动ollama serve可以使用ollama list去查看下载了什么模型
4.1 环境搭建
首先安装LangChain及相关依赖,这里以对接OpenAI模型为例(国内用户可替换为ChatGLM、通义千问等):
# 安装核心依赖
pip install langchain langchain-classic langchain-community langchain-core langchain-ollama
# 若需处理文档,额外安装:pip install pypdf python-docx
4.2 实战1:基础LLM调用(Model+Prompt+Chain)
实现“根据产品名称,生成3个科技感名字”的简单任务,用到Model、PromptTemplate、LLMChain三个核心组件,如果使用API调用模型的需要创立.env文件存放密钥:
from langchain_core.prompts import ChatPromptTemplate
from langchain_ollama import OllamaLLM
from dotenv import load_dotenv
import os
# 加载环境变量(读取 API 密钥)
load_dotenv()
# 1. 初始化模型(使用本地 Ollama 的千问模型)
llm = OllamaLLM(
model="qwen2.5:1.5b", # 本地模型名称
temperature=0.7, # 随机性,0~1,越小越严谨
)
# 2. 定义提示模板(动态传入产品名称)
prompt = ChatPromptTemplate.from_template(
"给一个{product}起 3 个有科技感的名字,要求简洁、好记,每个名字不超过 8 个字,无需额外解释。"
)
# 3. 构建链(串联提示模板和模型)
chain = prompt | llm
# 4. 执行链,获取结果
result = chain.invoke({"product": "智能手表"})
print("生成的产品名称:")
print(result)
运行结果(参考):
核心说明:通过PromptTemplate定义标准化提示,LLMChain串联组件,无需手动拼接提示词,开发效率大幅提升。
4.3 实战2:多轮对话(加入Memory)
实现“带记忆的对话机器人”,让模型记住之前的对话内容,用到RunnableWithMessageHistory组件:
from langchain_ollama import OllamaLLM
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_message_histories import ChatMessageHistory
from dotenv import load_dotenv
import os
load_dotenv()
# 1. 初始化模型
llm = OllamaLLM(
model="qwen2.5:1.5b",
temperature=0.7
)
# 2. 创建提示模板
prompt = ChatPromptTemplate.from_messages([
("system", "You are a helpful assistant."),
MessagesPlaceholder(variable_name="history"),
("human", "{input}")
])
# 3. 创建可运行对象
chain = prompt | llm
# 4. 管理对话历史
message_history = ChatMessageHistory()
def get_chat_history():
return message_history
# 5. 包装成带历史的链
chain_with_history = RunnableWithMessageHistory(
chain,
get_chat_history,
input_messages_key="input",
history_messages_key="history"
)
# 6. 多轮对话
print("对话开始(输入'退出'结束):")
while True:
user_input = input("用户:")
if user_input == "退出":
break
response = chain_with_history.invoke(
{"input": user_input},
config={"configurable": {"session_id": "default"}}
)
print(f"AI:{response}\n")
# 查看对话历史
print("对话历史:")
print(message_history.messages)
运行示例: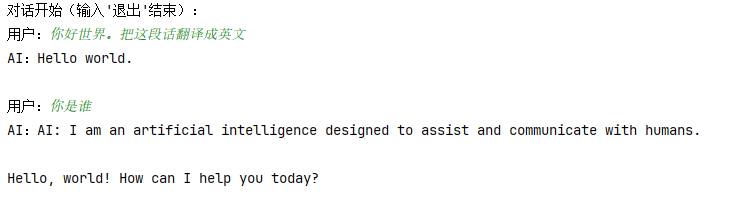
核心说明:Memory组件自动保存对话历史,每次调用时,会将历史内容传入模型,实现连贯对话。
五、LangChain常见应用场景
LangChain的应用场景广泛,涵盖AI开发的多个领域,结合企业级实战经验,重点介绍以下5个核心场景:
5.1 智能问答系统(RAG)
结合本地文档(PDF、Word、知识库),构建“基于自有数据的问答系统”,比如企业知识库问答、产品手册问答。核心流程:加载文档→文本分块→语义嵌入→向量检索→生成回答,无需训练模型,直接复用大模型能力。
5.2 对话机器人
开发带记忆、能调用工具的智能客服、虚拟助手,比如电商客服(查询订单、解答售后)、企业办公助手(查询考勤、流程咨询),支持多轮连贯对话,自主处理简单任务。
5.3 文档智能处理
自动化处理文档,比如PDF解析、合同提取、简历筛选、报告生成,将繁琐的人工文档处理工作交给AI,提升效率,减少错误。
5.4 数据分析与报告生成
对接CSV、Excel、数据库等结构化数据,通过Agent调用分析工具,自动生成数据分析报告,比如销售数据趋势分析、用户行为分析,无需手动编写分析代码。
5.5 自动化工作流
串联多个工具和任务,实现端到端的自动化,比如“接收邮件→提取关键信息→生成回复→发送邮件”“爬取网页内容→总结重点→生成文档”。

六、总结与学习路径
6.1 总结
LangChain的核心不是“替代大模型”,而是“让大模型更有用”——它通过组件化设计,将大模型与外部资源、工具、记忆系统连接起来,解决了大模型“健忘、不会用工具、不会串联任务”的痛点,大幅降低了LLM应用的开发门槛。
核心要点回顾:
-
LangChain = 组件化框架 + 大模型连接器 + 工具集;
-
6个核心组件:Models、Prompts、Chains、Memory、Tools、Agents,可自由组合;
-
核心优势:多模型兼容、组件复用、外部资源对接、低代码开发;
-
适用场景:智能问答、对话机器人、文档处理、数据分析等。
6.2 学习路径(新手友好)
-
基础阶段:掌握6个核心组件的概念和基础用法,完成本文的实战案例,熟悉LangChain的调用逻辑;
-
进阶阶段:学习RAG(检索增强生成)、多工具协同、自定义组件,实现复杂场景(如本地文档问答);
-
实战阶段:开发具体应用(如智能客服、文档分析工具),结合Docker部署,实现工业级落地。
七、参考资料与源码
-
LangChain官方文档:https://python.langchain.com/docs/get_started/introduction;
-
LangChain GitHub源码:https://github.com/langchain-ai/langchain;
-
相关参考:LangChain核心组件解析、企业级应用实战案例。
最后
如果觉得这篇文章对你有帮助,欢迎点赞+收藏+关注!后续会持续更新LangChain进阶实战、RAG技术、大模型应用落地相关内容,一起学习进步~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 15
15 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)