Z-Image-Turbo开源文生图整合包使用教程:8G显存即可本地运行,中文提示词支持好,一键选择图片尺寸,支持一次批量生成多张,含完整安装流程
Z-Image-Turbo究竟是什么?
Z-Image-Turbo(中文名"造相")是阿里开源的一款文生图模型,全名是 Tongyi-MAI/Z-Image-Turbo,属于 Z-Image 系列中的速度版本。
这个系列目前有三个变种:Z-Image-Turbo、Z-Image-Base、Z-Image-Editor。其中 Turbo 版是最先开源的,也是用户最多的一个。
模型参数量是6B,也就是60亿参数。听起来不大,但实际跑起来的效果在开源模型里算头部水平。根据 AI Arena(一个基于人类真实投票的模型评测平台)的数据,Z-Image-Turbo 在文生图赛道全球排第四,开源模型排第一,Elo 分数 1025。这个成绩连 GPT-Image 1 和 Seedream 3.0 这些闭源模型都比不过它。
对普通用户来说,最实用的是它的硬件门槛——8G显存的显卡就能跑起来,生成一张1024分辨率的图片,速度在10秒以内。
这款软件能帮你赚到什么?
很多人问 AI 生图能做什么变现,这里直接说几个实际场景:
电商配图:各种电商品主图,找外包设计至少几十块一张,用 Z-Image-Turbo 批量生成,一次生成多张,挑最好的用,成本几乎为零。
自媒体配图:各种自媒体平台,每天需要大量配图。自己写提示词,几秒钟一张,不用找图库,也不用担心版权。
设计辅助:UI设计师、平面设计师用它快速出素材草稿,再进行二次加工,效率提升明显。
软件特点
速度快
Z-Image-Turbo 只需要 8 步推理就能出图,而 Stable Diffusion 系列通常要 20-50 步,Flux 系列更慢。实测数据显示:在 RTX 4090 上,Z-Image-Turbo 生成一张 1024x1024 的图只需要 2.3 秒,同样条件下 Flux 要 42 秒。
普通的 RTX 3060 或者 8G 显存的显卡,生成速度虽然不到 2 秒,但 10 秒以内基本没问题,2K 分辨率在 20 秒内也能完成。
中文提示词支持好
这一点是很多国内用户反馈最多的优点。过去用 Stable Diffusion 或者 Flux,中文提示词基本没用,必须翻译成英文,还经常因为翻译不准导致效果差。
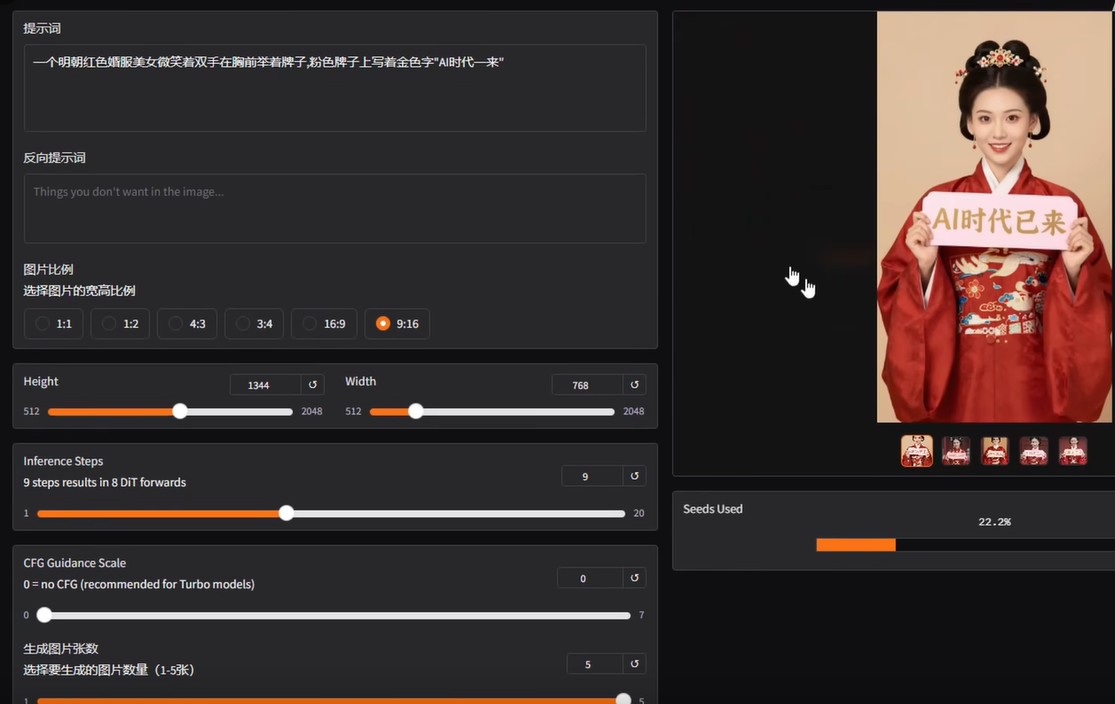
Z-Image-Turbo 用了 Qwen3-4B 作为文本编码器,对中文理解比较准确。你直接写"穿汉服的女孩站在江南水乡,烟雨朦胧",出来的图就是这个意思,不跑偏。中文文字渲染也能用,图片里的汉字不会乱码(虽然偶尔还是有一点瑕疵,但比以前好很多)。
一键选择图片尺寸
整合包的界面里可以直接选尺寸,不需要手动改参数。常用尺寸比如 1024x1024、1024x768、768x1024 这些都有预设,点一下就行。想要 2K 高清图也支持,最高可以出 2048x2048。
一次生成多张图片
整合包支持批量生图,一次可以设置生成 4 张、8 张,甚至更多。这个功能对接单的人来说很有用——同一个提示词批量出图,再从里面挑最好的给客户。
8G显存可用,显卡门槛低
量化版本最低 6G 显存也能跑,8G 是稳定运行的推荐配置。支持 NVIDIA N 卡(最多用户),也支持 AMD A 卡(通过 CPU 解码,速度稍慢),Mac M 系列芯片也支持。
开源免费,可商用
整个模型基于 Apache-2.0 协议开源,商用不需要付费授权,这对拿它接单的人来说是个很重要的点。
与其他同类软件详细对比
Z-Image-Turbo vs Stable Diffusion
| 对比项 | Z-Image-Turbo | Stable Diffusion |
|---|---|---|
| 推理步数 | 8步 | 20-50步 |
| 中文支持 | 原生支持 | 基本不支持 |
| 8G显存 | 稳定运行 | 大模型勉强,部分模型跑不了 |
| 出图速度 | 快 | 较慢 |
| 生态插件 | 刚起步 | 成熟,插件极多 |
| 学习成本 | 整合包低,ComfyUI中等 | 使用复杂,门槛高 |
SD 生态是最完整的,LoRA、Controlnet、各种风格模型数以万计。Z-Image-Turbo 在这方面刚起步,目前插件和扩展还不多。但如果你只是要出图,不需要精细调控,Z-Image-Turbo 的中文友好度和速度优势很明显。
Z-Image-Turbo vs Flux(包括 Flux2)
Flux 系列,尤其是 Flux2,参数量是 32B,需要很高的显存才能跑,生成一张图的时间内 Z-Image-Turbo 能出 20 张。
实测对比:Flux 在色彩还原上稍强,生成红色、绿色这类特定颜色更准;Z-Image-Turbo 在光影表现和人像细节(发丝、皮肤纹理)上更好,人脸生成的"翻车率"也低一些。具体数据是 Flux 约有 12% 的图会出现"Flux 下巴"问题(下颌线处理过硬),Z-Image-Turbo 的整体故障率在 7-8%。
对于国内用户来说,Flux 不支持中文提示词,这个缺点很致命。
Z-Image-Turbo vs Midjourney
Midjourney 是收费的,每个月订阅费用不低,还有生图数量限制,图片存在服务器上,隐私性也一般。Z-Image-Turbo 本地跑,数据不出去,生成数量不限,更适合有隐私要求或者批量出图需求的用户。
画质上,Midjourney 的艺术风格和美学调校确实更成熟,审美天花板高,但在写实类图片上两者差距没那么大。
安装教程
整合包方式是最推荐新手的方法,不需要配置 Python 环境,不需要装各种依赖,下载解压就能用。
第一步:确认电脑配置
在下载之前先确认自己的电脑配置够不够:
- 显卡:NVIDIA 显卡,显存 8G 及以上(推荐 RTX 3060 或更高)
- 内存:16G 及以上
- 硬盘:至少 20G 空余空间(模型文件大)
- 系统:Windows 10/11 64位(N卡用户);Mac M系列也支持
如果你的显卡是 6G 显存的 RTX 3060,可以试试量化版本(int4),速度稍慢但能跑起来。
AMD 显卡用户注意:目前支持 CPU 解码模式,出图速度比 N 卡慢很多,可以用,但不推荐作为主力工具。
第二步:下载整合包
整合包的下载地址
https://pan.quark.cn/s/0944a4345950
整合包通常有两个版本:
- WebUI 版:界面简单,操作像网页一样,适合完全的新手
- ComfyUI 版:节点式工作流,功能更强,适合有一点基础的用户
新手建议下 WebUI 版,上手更快。
整合包文件大小通常在 10G-15G 左右(包含模型权重文件),下载需要一定时间,建议用下载工具(比如 IDM)分段下载。
第三步:解压和放置模型文件
把整合包下载到一个路径比较短的位置,比如 D:\ZImage,路径里不要有中文、空格,否则有可能报错。
解压后,文件夹结构大概是这样的:
ZImage整合包/
├── run.bat(启动文件)
├── ComfyUI/(或 WebUI/)
│ ├── models/
│ │ ├── diffusion_models/(放主模型文件)
│ │ └── vae/(放VAE文件)
│ └── ...
主模型文件 z_image_turbo_bf16.safetensors 需要放在 models/diffusion_models/ 目录下。
VAE 文件 ae.safetensors 放在 models/vae/ 目录下(注意:这个 VAE 和 Flux 的 VAE 是通用的,如果你之前用过 Flux,可能已经有了)。
第四步:启动软件
找到整合包根目录下的 run.bat(Windows 系统),双击运行。
第一次启动会自动检测环境,可能要等几分钟。启动成功后,命令行窗口会显示一个本地地址,通常是:
http://127.0.0.1:8188
把这个地址复制到浏览器(Chrome 或 Edge)打开,就能看到操作界面了。
第五步:加载工作流
如果是 ComfyUI 版,需要加载工作流文件(JSON格式)。
整合包里通常已经附带了几个工作流文件,找到 workflow 文件夹,把里面的 JSON 文件直接拖进浏览器里的 ComfyUI 画布,工作流会自动加载。
如果想用官方推荐的工作流,可以去 ComfyUI 官方中文文档找:
https://docs.comfy.org/zh-CN/tutorials/image/z-image/z-image-turbo
下载工作流图片(工作流信息嵌在图片里),拖进 ComfyUI 即可。
第六步:设置参数和生图
工作流加载完之后,找到提示词输入框(通常标注为 positive prompt 或者 text),输入你的描述。
参数设置建议:
- 推理步数(steps):推荐设置 8,这是官方推荐的平衡点。追求速度可以设 6,质量会稍差一点;设 10 以上基本没有额外提升。
- 图片尺寸:1024x1024 是标准尺寸,人像可以用 768x1024(竖版),风景建议 1024x768(横版)。
- guidance_scale:这个参数必须设为 0,Z-Image-Turbo 的技术特性决定的,设成其他值效果会变差。
- 批量数量(batch size):设为 4 或者 8,一次生成多张,再挑最好的用。
- 采样器:推荐用 ClownShark 采样器,配合 ralston_2s 调度方案效果比较好。
第七步:输入提示词生成图片
中文提示词直接写,比如:
一位穿着白色连衣裙的年轻女性,站在向日葵花田里,阳光明媚,背景模糊,人像摄影风格
也可以加上一些修饰词提升画质:
专业摄影,高清,景深效果,自然光,真实感
点击"运行"或者"Queue Prompt"按钮,等几秒到十几秒,图片就生成出来了。
生成的图片可以在界面上直接右键保存,也可以在 ComfyUI/output/ 文件夹里找到。
使用过程中的几个注意点
关于随机性:Z-Image-Turbo 有个已知的问题,就是同一个提示词生成的多张图太像了(技术上叫"seed 不敏感")。如果你发现批量生成的图都差不多,可以去找 ComfyUi-ConditioningNoiseInjection 这个插件,它专门解决这个问题,能让每次生成的构图有更多差异。
关于显存不够:如果 8G 显存跑 bf16 版本感觉卡,可以换 int4 量化版本(文件名带 svdq-int4 的),显存占用会少一些,速度稍慢,画质差别不大。
关于手部细节:Z-Image-Turbo 生成的手部偶尔会有变形,这是目前大部分文生图模型的共同问题,遇到这种情况多生成几张挑选就行。
关于文字渲染:图片里的中文文字生成比以前好很多,但复杂汉字或者长段文字还是可能出现错误,需要用后期工具修一下。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 13
13 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)