NLP —— 注意力机制Seq2Seq
一、注意力机制概念
Seq2Seq是啥,它和RNN、LSTM、GRU的关系和区别是啥?
1- Seq2Seq是一种模型架构,用于将一个序列映射到另一个序列。典型结构是 Encoder-Decoder(编码器-解码器)
2- RNN、LSTM、GRU是神经元内部结构
3- Seq2Seq模型的编码器和解码器通常由 RNN、LSTM 或 GRU 构成
4- 可以将Seq2Seq理解为房子,RNN、LSTM、GRU理解为建房子的砖
没有注意力机制之前存在的弊端:
弊端1: 如果翻译的句子很长很复杂,比如直接一篇文章输进去,模型的计算量很大,并且模型的准确率下降严重
弊端2: 没有考虑词与词之间的相关性,导致翻译效果比较差
结构
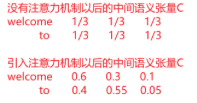
注意力机制的作用:就是为了解决上面提到的“信息利用不细致的问题”
当Decoder解码器在翻译内容的时候:
要翻译生成welcome的时候 -> 让解码器多关注编码器端的【欢迎】对应的信息
要翻译生成to的时候 -> 让编码器多关注编码器端的【来】对应的信息
...
这样就比只靠一个没有任何区分、不会发生变化的中间语义张量C,进行文本翻译的效果要更好
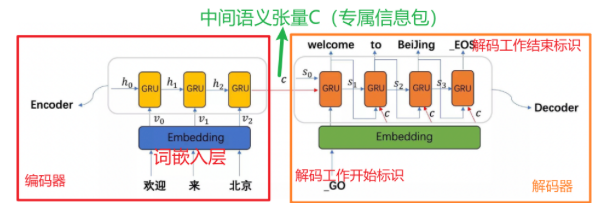
1 - Encoder:编码器,负责对输入的文本语义进行【理解】
v0、v1、v2 输入数据的词向量
h0、h1、h2 编码器各个时间步的隐藏状态
Embedding 编码器端的词嵌入层,将词索引变成词向量
2 - C 中间语义张量C,也可以叫做专属信息包
编码器中的GRU会把h0、h1、h2打包成一个总的信息包,再传递给到下游的编码器
3 - Decoder :解码器,负责生成/翻译得到文本【主生成】
解码器拿到中间语义张量C以后,结合自己的Embedding词嵌入层,从初始输入_Go开始进行文本内容的生成或者翻译的工作,使用GRU翻译得到英文
s0、s1、s2、s3:解码器端各个时间步的隐藏状态
注意力机制分类及实现
概念
1.软注意力:也称之为全局注意。注意力权重值分布在0-1之间,关注所有的词汇,但是不同词汇根据权重大小关注的程度不一样。
2.硬注意力: 也称之为局部注意。注意力权重值是0或者1,只关注哪些重要的部分,忽略次要的部分
3.自注意力: 也称之为内注意。通过输入项内部的"表决"来决定应该关注哪些输入项.
=========================================================================
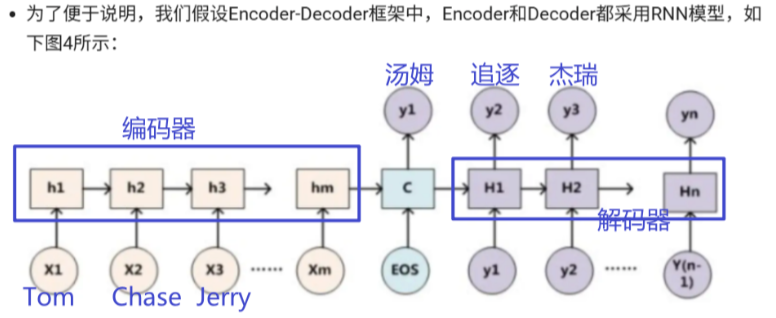
二、加了Attention的Encoder-Decoder框架
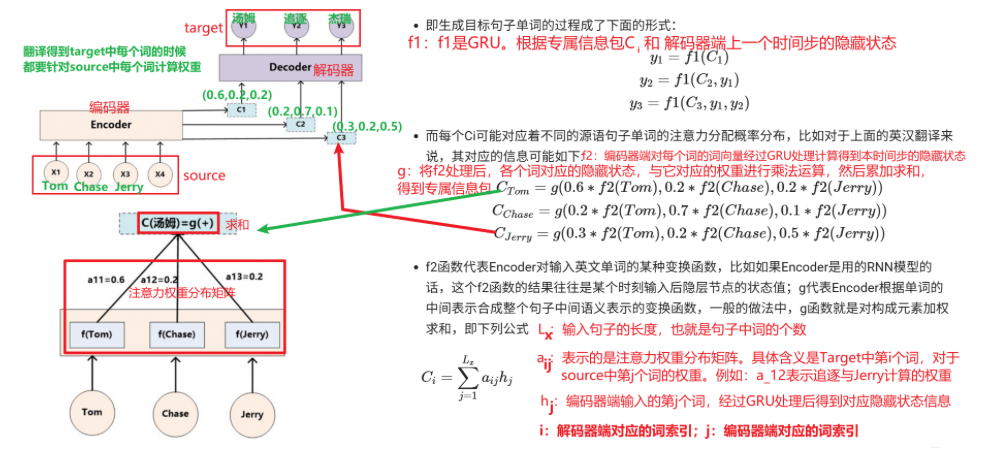
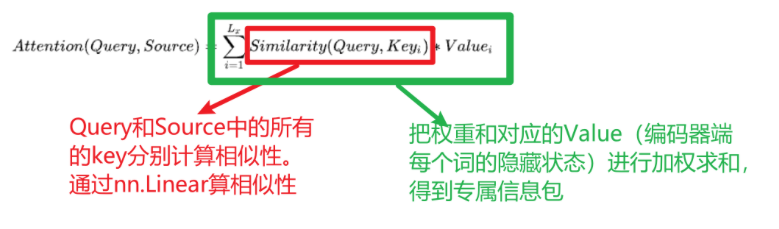
1、专属信息包C如何来的:权重值和对应的隐藏状态进行乘法,然后累加求和
2、为什么要有注意力机制?
当Decoder解码器生成/翻译得到某个词的时候,应该关注编码器端
中的哪些词。例如:翻译【汤姆】的时候,应该多关注【Tom】。
3、如何得到注意力概率分布
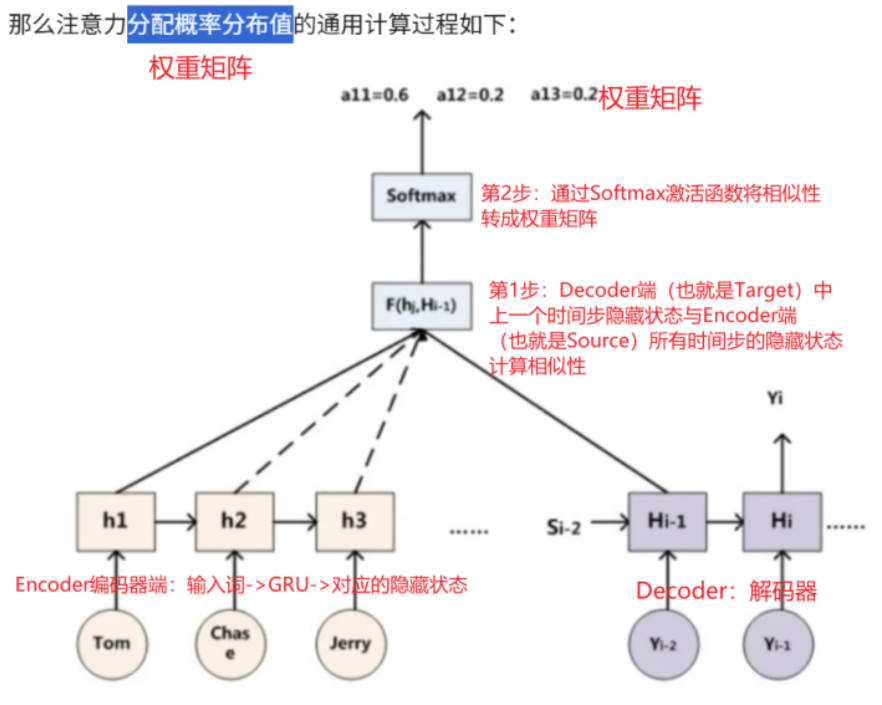 注意力分配权重的计算过程
注意力分配权重的计算过程
① 计算相似性
使用相似性计算工程,对比Decoder上一个时间步的隐藏状态和Encoder中每个单词的隐藏状态计算相似性,看谁更重要。
②将相似性转成权重矩阵
使用softmax激活函数,将上面的相似性转为权重(概率),并且权重值之和为1
③ 加权求和
使用第2步的权重矩阵与Encoder中每个单词的隐藏状态进行乘法和加法运算,得到专属学习包
三、Attention机制的本质思想
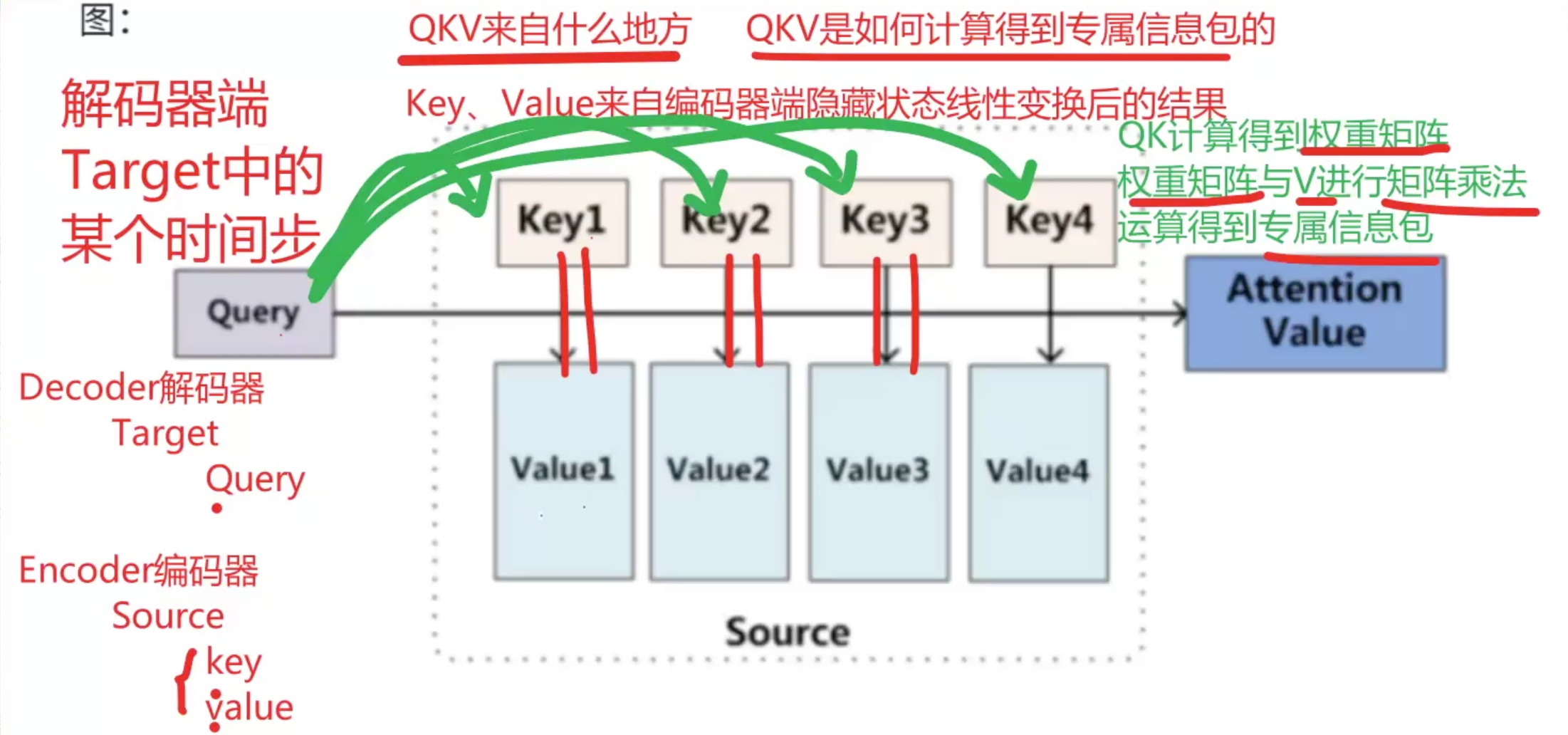
绝大多数情况下 Key和Value 完全一样,张量形状和张量数字。
Key、Value来至编码器端隐藏状态线性变换后的结果
当前Q = K = V 的时候是自注意力机制。(后面会专门写一篇)
四、Pytorch中注意力机制计算原理
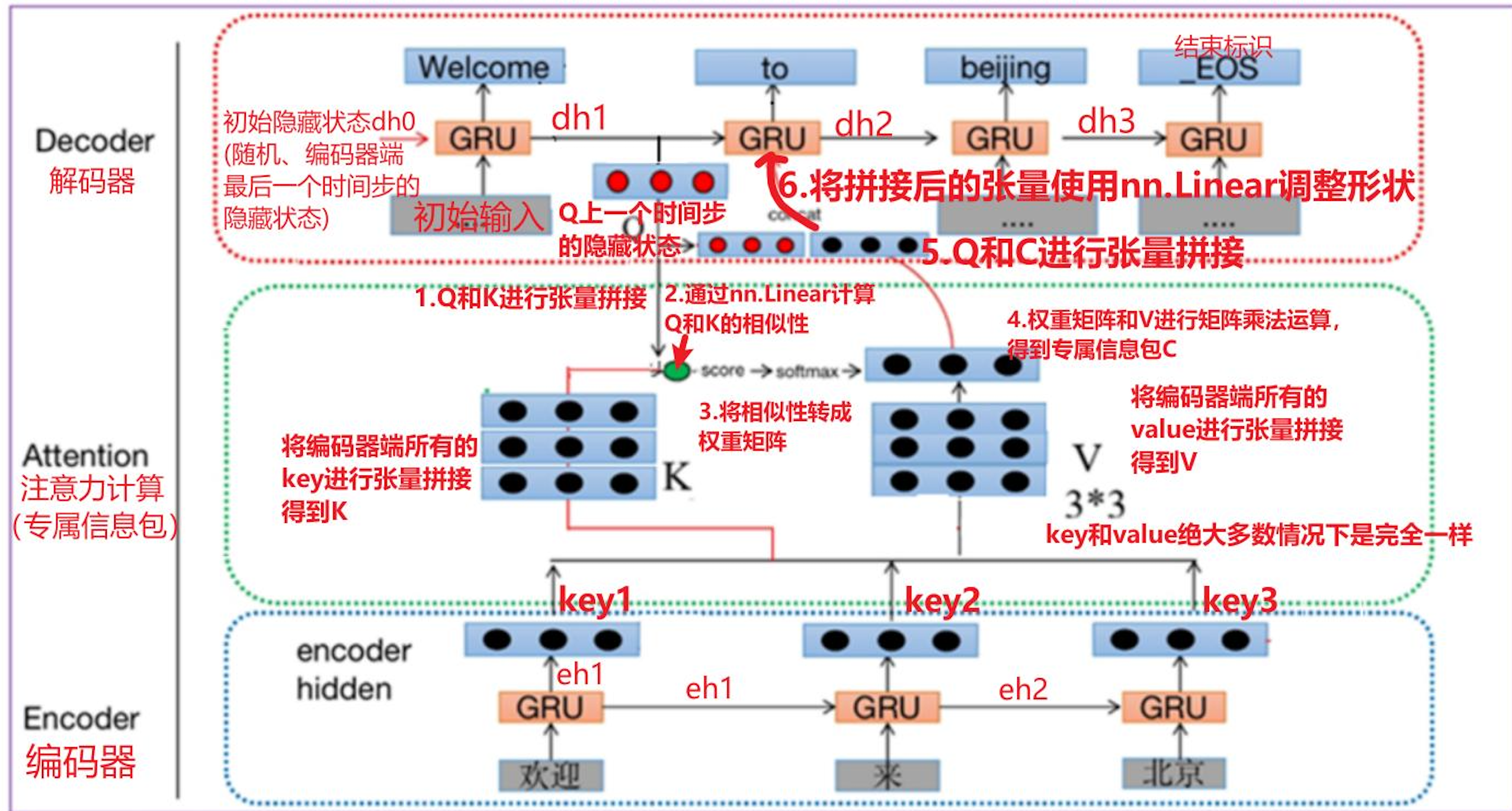
1-6步 专属信息包里面的计算步骤
① Q和K进行张量拼接
② 通过线性变化 nn.Linear计算 Q和K的相似度
③ 将相似性转换权重矩阵
④ 权重矩阵和V进行矩阵乘法运算,得到专属信息包
⑤ Q 和 C 进行张量拼接
⑥ 将拼接后的张量使用 线性变化 nn.Linear调整形状
注意力计算公式
计算规则前提
1- 当Q、K、V相等, 称作自注意力
2- 当Q、K、V不相等时,称为一般注意力(包括软注意力、硬注意力)
3- 自注意力 和 一般注意力的区别,只是数据层面(也就是QKV是否相等)的区别
4- 具体计算得到 自注意力 和 一般注意力,有如下的3种公式。目前使用最多的是第1个和第3个。
注意:
1: 不要将注意力的三种类别(软注意力、硬注意力、自注意力) 和 注意力计算的3个公式搞混
2: 也就是下面的3个公式,即能够算软注意力,也能够算自注意力
3: Transformer框架中使用的是第3个公式算自注意力,原因是除以根号dk
三种规则方法
-
公式1: 将Q和K进行纵轴拼接,然后经过线性变换,再经过Softmax进行处理得到权重,最后和V进行相乘
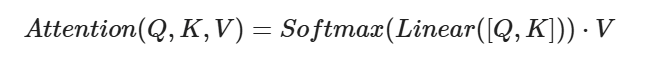
-
公式2:将Q和K进行纵轴拼接,接着经过一次线性变化,然后进过tanh激活函数处理,再进行sum求和,再经过softmax进行处理得到权重,最后和V进行张量的乘法
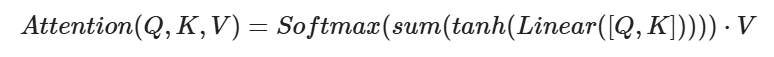
-
公式3:将Q和K的转置进行点乘,然后除以一个缩放系数,再经过softmax进行处理得到权重,最后和V进行张量的乘法
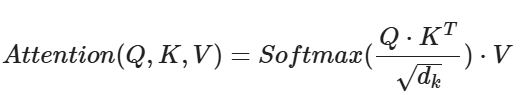
注意:dk是k的维度,等于词向量的维度 或者 隐藏状态维度
防止矩阵点乘运算结果过大,导致Softmax计算后概率值出现极端值,极大或极小。避免模型对这些极值学习的不好
K为什么要转置?
① K和V的形状是相同的,假设K的形状是[N个词, M的隐藏状态]
② Q是单个时间步的隐藏状态,形状是[1, M的隐藏状态]
③ 为了能和V进行矩阵乘法运算,那么K需要转置
举例:
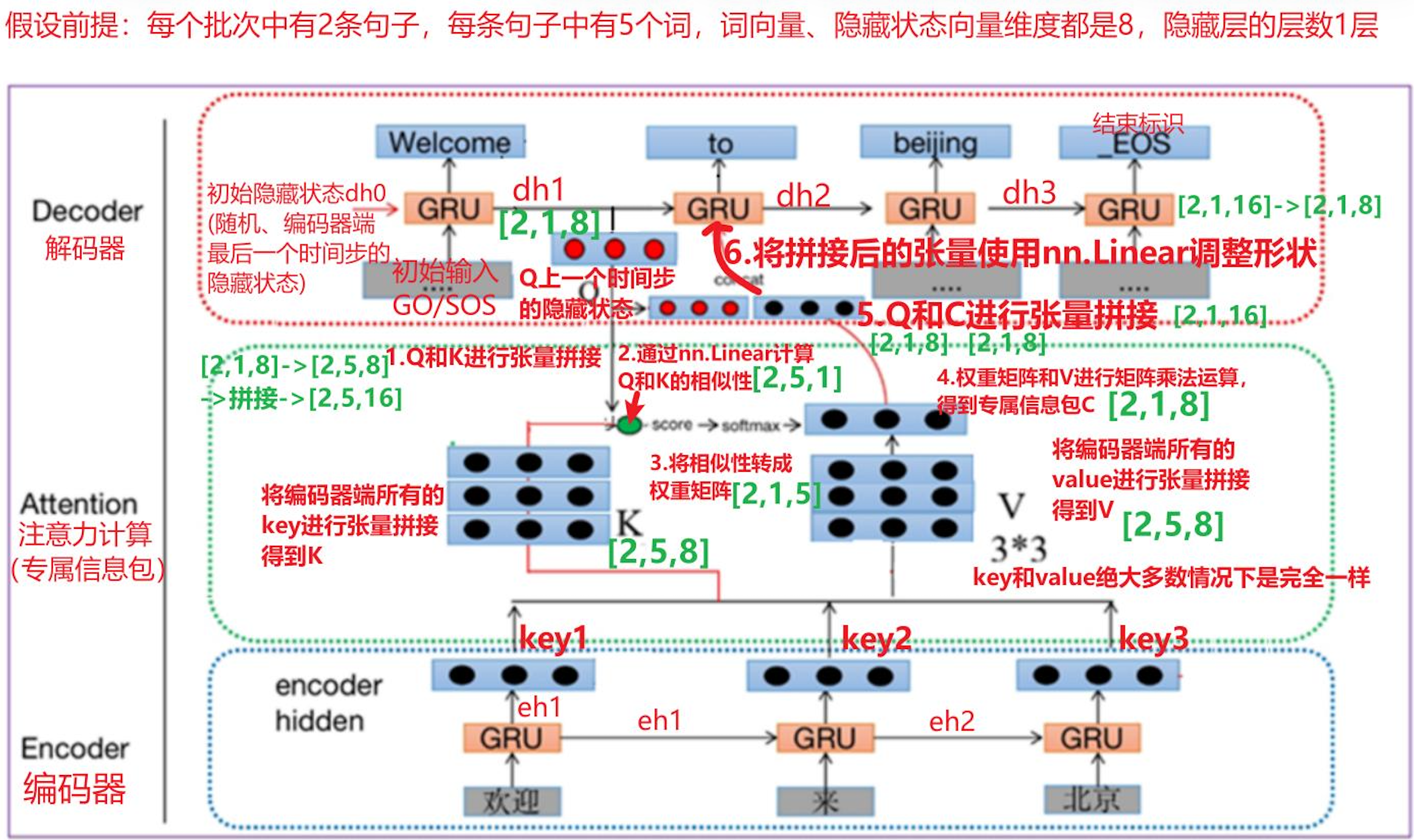
①
K和V的张量形状 【batch_size, seq_len, hidden_size】
K和V:【2,5,8】 2条句子,每个句子5个词,向量维度8
Q: query,张量形状[batch_size,num_layers,hidden_size] -> [2,1,8]
Q和K目前不能直接拼接,需要将Q的形状 由 [2,1,8] -> [2,5,8]
②
nn.Linear(in_features=16,out_features=1)
使用线性层对QK拼接后的结果计算相似性 nn.Linear -> 【2,5,1】
为什么是1? 2条句子,5个词。Q要和每个K计算权重->每个词都要算1个权重, 权重10 = 2 * 5 * 1
③
【2,5,1】 -> 【2,1,5】 ?
因为V 是【2,5,8】 要做矩阵乘法运算。【2,5,1】 不能直接相乘
调换维度后 ->. softmax 得到权重矩阵
④
【2,1,5】@ 【2,5,8】 -> 【2,1,8】
⑤
Q和C进行张量拼接
【2,1,8】拼接 【2,1,8】 -> 【2,1,16】
⑥
对拼接后的张量进行形状调整,以满足Decoder端GRU输入数据的要求 nn.Linear(in_features=16,out_features=8)
使用nn.linear调整形状
【2,1,16】 -> 【2,1,8】
代码

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)