Dexter深度解析:如何用多Agent架构打造自主金融研究AI
一、为什么需要金融AI Agent?
1.1 传统金融研究的痛点
作为开发者,你是否遇到过这样的场景:需要分析一家上市公司的财务状况,却要花费数小时甚至数天时间?
传统金融研究面临三大挑战:
- 数据分散:财务数据分布在SEC filings、财报、新闻、社交媒体等多个来源
- 分析耗时:需要人工阅读、提取、对比、验证大量信息
- 实时性差:市场瞬息万变,人工分析难以跟上节奏

传统金融研究需要人工完成多个环节,效率低下
1.2 AI Agent带来的变革
AI Agent的出现,让自动化金融研究成为可能。不同于传统的"问答式"AI,Agent具备自主规划、执行、验证的能力,能够像人类分析师一样思考和行动。
Dexter的核心价值:
- ✅ 自主规划:将复杂问题分解为可执行的步骤
- ✅ 实时数据:接入SEC filings、股票市场等实时数据源
- ✅ 自我验证:检查分析结果的准确性和一致性
- ✅ 持久记忆:记住历史研究,避免重复工作
二、Dexter是什么?核心特性解析
2.1 项目定位与价值
Dexter是一个开源的自主金融研究AI Agent,专为处理复杂金融问题而设计。它不仅是一个工具,更是一个完整的多Agent系统架构示例。
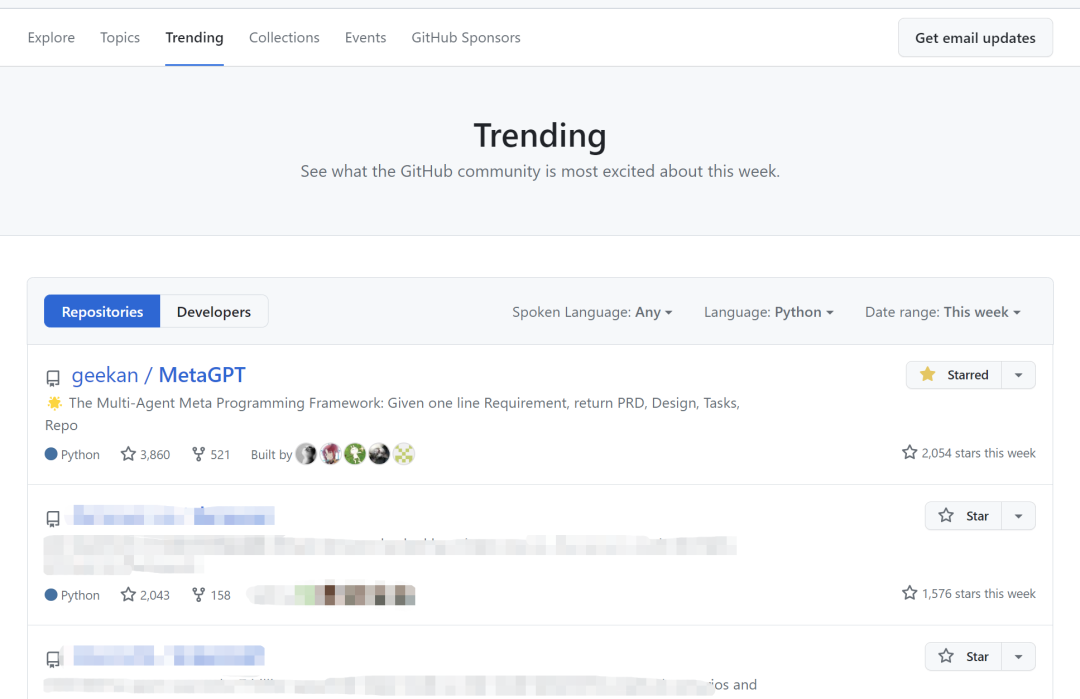
Dexter在GitHub Trending上表现亮眼
项目亮点:
| 特性 | 说明 | 价值 |
|---|---|---|
| 自主规划 | 智能分解复杂查询 | 提升分析效率 |
| 多Agent协作 | 规划、执行、验证三层架构 | 确保结果可靠 |
| 实时数据 | 接入SEC、市场数据API | 数据准确及时 |
| 持久记忆 | SQLite存储历史研究 | 避免重复劳动 |
| 开源免费 | MIT协议 | 可商用可定制 |
2.2 核心功能一览
1. 智能任务规划
// 示例:用户提问
"分析苹果公司过去四个季度的收入增长情况"
// Dexter自动分解为:
步骤1: 获取苹果公司股票代码(AAPL)
步骤2: 从SEC filings获取季度财报
步骤3: 提取收入数据
步骤4: 计算增长率
步骤5: 生成分析报告
2. 实时金融数据集成
Dexter集成了多个金融数据源:
- SEC Filings:美国证券交易委员会备案文件
- Stock Market API:实时股票价格、历史数据
- Financial Datasets API:专业金融数据集
Dexter可以自动获取和分析SEC备案文件
3. 持久化记忆系统
// 最新版本新增功能
- 持久化Markdown记忆
- 混合SQLite召回机制
- Agent flush集成
2.3 技术栈分析
前端/交互层:TypeScript (98.7%)
AI框架:LangChain
数据存储:SQLite
API集成:SEC API、Financial Datasets API
部署方式:支持Docker容器化
三、多Agent架构设计揭秘
Dexter最核心的创新在于其多Agent协作架构。这种设计模拟了人类分析师团队的工作方式,通过分工协作提升效率和可靠性。
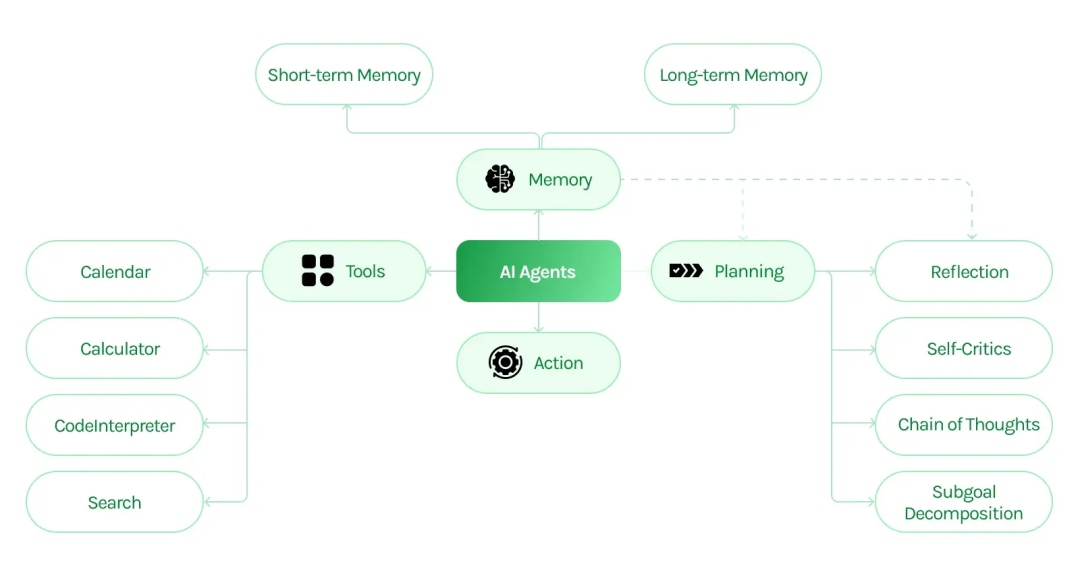
Dexter的多Agent协作架构
3.1 规划Agent:智能任务分解
规划Agent(Planning Agent)是整个系统的"大脑",负责理解用户需求并制定执行计划。
核心职责:
- 解析用户查询意图
- 将复杂问题分解为子任务
- 确定任务执行顺序
- 分配任务给执行Agent
实现原理:
// 简化的规划Agent逻辑
class PlanningAgent {
async plan(query: string) {
// 1. 分析查询意图
const intent = await this.analyzeIntent(query);
// 2. 分解任务
const subtasks = await this.decomposeTasks(intent);
// 3. 生成执行计划
const plan = await this.createPlan(subtasks);
return plan;
}
}
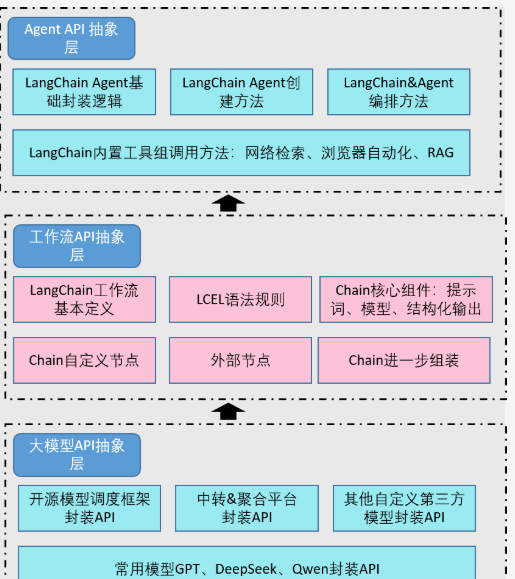
LangChain Agent的工作流程
3.2 执行Agent:数据获取与处理
执行Agent(Execution Agent)是系统的"手脚",负责具体的数据获取和处理工作。
核心职责:
- 调用金融数据API
- 爬取SEC filings
- 处理结构化数据
- 执行计算任务
数据源集成:
// 执行Agent的工具集
const tools = {
// SEC filings查询
secFilingsSearch: async (ticker: string) => {
return await secAPI.getFilings(ticker);
},
// 股票价格查询
stockPrice: async (ticker: string) => {
return await marketAPI.getPrice(ticker);
},
// 财务数据提取
financialData: async (filingId: string) => {
return await financialAPI.extract(filingId);
}
};
3.3 验证Agent:结果校验机制
验证Agent(Verification Agent)是系统的"质检员",确保分析结果的准确性和可靠性。
核心职责:
- 检查数据完整性
- 验证计算准确性
- 识别逻辑矛盾
- 标注置信度
验证流程:
class VerificationAgent {
async validate(result: AnalysisResult) {
// 1. 数据完整性检查
const completeness = this.checkCompleteness(result);
// 2. 计算准确性验证
const accuracy = this.verifyCalculations(result);
// 3. 逻辑一致性检查
const consistency = this.checkConsistency(result);
// 4. 生成置信度评分
const confidence = this.calculateConfidence({
completeness,
accuracy,
consistency
});
return { isValid: confidence > 0.8, confidence };
}
}
验证Agent确保输出结果的可靠性
3.4 三者协作流程
完整的工作流程:
用户查询
↓
[规划Agent] 分析意图 → 分解任务 → 生成计划
↓
[执行Agent] 获取数据 → 处理分析 → 生成初步结果
↓
[验证Agent] 检查准确性 → 验证逻辑 → 标注置信度
↓
输出最终报告
协作示例:
假设用户提问:“比较苹果和微软过去一年的营收增长”
-
规划Agent:
- 任务1:获取AAPL过去4个季度营收
- 任务2:获取MSFT过去4个季度营收
- 任务3:计算增长率
- 任务4:对比分析
-
执行Agent:
- 调用SEC API获取财报
- 提取营收数据
- 计算增长率
-
验证Agent:
- 检查数据是否完整(4个季度)
- 验证计算是否正确
- 确认对比逻辑合理
四、实战:从零开始使用Dexter
4.1 环境准备
系统要求:
- Node.js 18+
- Python 3.8+(如需使用Python工具)
- OpenAI API Key
安装步骤:
# 1. 克隆项目
git clone https://github.com/virattt/dexter.git
cd dexter
# 2. 安装依赖
npm install
# 3. 配置环境变量
cp .env.example .env
# 编辑.env文件,填入API密钥
# OPENAI_API_KEY=your_key_here
# FINANCIAL_DATASETS_API_KEY=your_key_here

在终端中执行安装命令
4.2 快速上手
启动Dexter:
# 使用uv运行(推荐)
uv run dexter-agent
# 或使用npm
npm start
第一个查询:
// 在交互模式下输入
> "分析特斯拉2024年Q4的财务表现"
// Dexter自动执行:
✓ 规划:分解为5个子任务
✓ 执行:获取SEC filings数据
✓ 验证:检查数据准确性
✓ 输出:生成分析报告
输出示例:
📊 特斯拉2024 Q4财务分析报告
核心指标:
- 营收:$25.2B(同比增长12%)
- 净利润:$2.1B(同比增长8%)
- 毛利率:18.2%(同比下降1.5个百分点)
关键发现:
1. 汽车业务营收增长稳健,主要受益于Model Y销量提升
2. 能源存储业务增速显著,同比增长35%
3. 自动驾驶业务仍处于投入期,影响整体利润率
风险提示:
- 市场竞争加剧,价格压力持续
- 原材料成本波动影响毛利率
置信度:85%(数据来源:SEC filings,计算已验证)
4.3 典型应用场景
场景1:投资决策支持
// 查询示例
"评估英伟达的投资价值,考虑财务表现、市场地位和竞争格局"
// Dexter输出:
- 财务分析(营收、利润、现金流)
- 行业对比(与AMD、Intel对比)
- 风险评估(竞争、监管、技术)
- 投资建议(买入/持有/卖出)
场景2:竞品分析
// 查询示例
"对比分析Snowflake和Databricks的商业模式和财务表现"
// Dexter输出:
- 商业模式对比
- 营收增长趋势
- 客户获取成本
- 市场份额分析
场景3:风险评估
// 查询示例
"分析WeWork破产对共享办公行业的影响"
// Dexter输出:
- WeWork财务状况回顾
- 行业连锁反应分析
- 竞争对手机会评估
- 投资风险提示
五、技术亮点与实现细节
5.1 实时金融数据集成
Dexter的数据集成策略值得开发者学习:
多数据源架构:
// 数据源抽象层
interface DataSource {
name: string;
fetch(query: Query): Promise<Data>;
validate(data: Data): boolean;
}
// 具体实现
class SECSource implements DataSource {
name = "SEC Filings";
async fetch(query: Query) {
const filings = await this.api.getFilings(query.ticker);
return this.parse(filings);
}
validate(data: Data) {
return data.fields.length > 0;
}
}
class MarketDataSource implements DataSource {
name = "Stock Market";
async fetch(query: Query) {
return await this.api.getMarketData(query.ticker);
}
validate(data: Data) {
return data.price > 0;
}
}
Dexter可以实时获取股票市场数据
数据缓存策略:
// SQLite缓存实现
class DataCache {
async get(key: string) {
const cached = await this.db.query(
'SELECT * FROM cache WHERE key = ? AND expiry > ?',
[key, Date.now()]
);
if (cached) {
return JSON.parse(cached.value);
}
return null;
}
async set(key: string, value: any, ttl: number) {
await this.db.query(
'INSERT INTO cache (key, value, expiry) VALUES (?, ?, ?)',
[key, JSON.stringify(value), Date.now() + ttl]
);
}
}
5.2 持久化记忆系统
最新版本的Dexter引入了持久化记忆功能,这是一个重要的技术升级:
记忆系统架构:
class MemorySystem {
// 混合召回机制
async recall(query: string) {
// 1. 从SQLite检索相关记忆
const memories = await this.sqlite.search(query);
// 2. 使用向量相似度排序
const ranked = await this.rankBySimilarity(memories, query);
// 3. 返回最相关的记忆
return ranked.slice(0, 5);
}
// Agent flush集成
async flush(agentId: string) {
// 将Agent的工作记忆持久化到存储
const workingMemory = await this.getWorkingMemory(agentId);
await this.save(workingMemory);
await this.clearWorkingMemory(agentId);
}
}
实际应用:
// 用户再次询问相关问题时
用户:"苹果的营收增长情况如何?"
Dexter:"根据我之前的分析,苹果过去四个季度的营收增长率为..."
// 系统自动召回历史研究,避免重复工作
5.3 工具链设计
Dexter的工具链设计遵循"单一职责"原则:
工具定义:
// 工具接口
interface Tool {
name: string;
description: string;
execute(params: any): Promise<any>;
}
// 具体工具实现
const tools = {
// SEC查询工具
secSearch: {
name: "sec_search",
description: "搜索SEC备案文件",
execute: async (ticker: string) => {
return await secAPI.search(ticker);
}
},
// X平台搜索工具(新增)
xSearch: {
name: "x_search",
description: "搜索X平台公开信息",
execute: async (query: string) => {
return await xAPI.search(query);
}
},
// 财务计算工具
financialCalc: {
name: "financial_calculator",
description: "执行财务计算",
execute: async (operation: string, data: any) => {
return calculate(operation, data);
}
}
};
工具选择策略:
// Agent根据任务类型选择合适工具
class ToolSelector {
selectTool(task: Task): Tool {
if (task.type === 'sec_filing') {
return tools.secSearch;
} else if (task.type === 'social_sentiment') {
return tools.xSearch;
} else if (task.type === 'calculation') {
return tools.financialCalc;
}
throw new Error('No suitable tool found');
}
}
六、开发者视角的思考
6.1 架构设计的启示
从Dexter的架构中,我们可以学到几个重要的设计原则:
1. 分层解耦
展示层(用户交互)
↓
协调层(Agent编排)
↓
执行层(工具调用)
↓
数据层(API集成)
这种分层设计使得每一层都可以独立演进,降低了系统复杂度。
2. 职责单一
每个Agent只负责一个核心职责:
- 规划Agent:只管规划,不管执行
- 执行Agent:只管执行,不管验证
- 验证Agent:只管验证,不管规划
3. 可扩展性
新增功能只需添加新的工具或Agent,不影响现有系统:
// 添加新工具
tools.newsSearch = {
name: "news_search",
description: "搜索新闻",
execute: async (query) => { ... }
};
// 添加新Agent
agents.sentimentAgent = new SentimentAgent();
Dexter的架构设计体现了现代AI系统的最佳实践
6.2 可扩展性分析
优点:
- ✅ 模块化设计,易于扩展
- ✅ 工具抽象,支持快速集成新数据源
- ✅ Agent独立,可并行开发
潜在改进方向:
-
支持更多数据源
- 中国A股数据(东方财富、同花顺API)
- 港股数据
- 加密货币市场数据
-
增强验证机制
- 引入第三方数据源交叉验证
- 使用机器学习模型检测异常数据
-
优化记忆系统
- 引入向量数据库(如Pinecone、Weaviate)
- 实现更智能的上下文召回
-
支持多语言
- 当前主要支持英文查询
- 可扩展中文、日文等多语言支持
6.3 实际应用中的挑战
挑战1:API成本
// 每次查询可能调用多次LLM
const costPerQuery = {
planning: 0.002, // 规划Agent
execution: 0.005, // 执行Agent(多次调用)
verification: 0.001, // 验证Agent
total: 0.008 // 约$0.008/查询
};
// 优化建议:
// 1. 使用更便宜的模型(如GPT-3.5)处理简单任务
// 2. 实现查询缓存,避免重复调用
// 3. 批量处理,减少API调用次数
挑战2:数据延迟
// SEC filings更新可能有延迟
// 解决方案:
const dataFreshness = {
secFilings: '1-2天延迟',
stockPrice: '实时',
news: '几分钟延迟'
};
// 建议:在报告中标注数据时间戳
挑战3:结果可解释性
// 用户可能不理解Agent的推理过程
// 解决方案:提供详细的执行日志
class ExplainableAgent {
async execute(task: Task) {
const steps = [];
steps.push({ action: '规划', detail: '分解为3个子任务' });
steps.push({ action: '执行', detail: '调用SEC API获取数据' });
steps.push({ action: '验证', detail: '检查数据完整性' });
return { result, steps };
}
}
七、总结与展望
7.1 核心要点回顾
通过深入解析Dexter项目,我们学到了:
-
多Agent协作是解决复杂问题的有效范式
- 规划、执行、验证三层架构确保结果可靠性
- 职责分离降低系统复杂度
-
金融AI Agent的核心要素
- 实时数据集成能力
- 智能任务规划能力
- 结果验证机制
-
开源项目的价值
- 提供了完整的实现参考
- 可定制、可扩展
- 社区驱动持续改进
7.2 行动建议
如果你是开发者:
- 动手实践:克隆项目,运行第一个查询
- 阅读源码:理解Agent协作的实现细节
- 尝试扩展:添加新的数据源或工具
- 贡献代码:向项目提交PR,参与开源社区
如果你是技术决策者:
- 评估适用性:分析Dexter是否适合你的业务场景
- 成本分析:评估API调用成本与收益
- 团队培训:组织团队学习Agent架构设计
- 试点项目:选择小场景进行试点验证
如果你是学习者:
- 系统学习:深入学习LangChain、Agent架构
- 项目实战:基于Dexter构建自己的金融AI Agent
- 关注社区:追踪项目更新,学习最佳实践
声明: 本文基于Dexter项目开源代码和相关文档撰写,仅供技术学习交流。金融投资有风险,AI分析结果仅供参考,不构成投资建议。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 15
15 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)