无监督学习—聚类
无监督学习是机器学习的一个重要分支,其核心目标是从未标记的数据中发现隐藏的模式或结构。与监督学习不同,无监督学习不需要预先标记的训练数据,而是通过算法自动对数据进行分类或聚类。以下是几种常见的无监督分类方法。
K均值聚类(K-Means Clustering)
K均值聚类是一种基于距离的聚类算法,通过将数据点分配到K个簇中,使得每个数据点与其所属簇的中心(质心)距离最小化。算法步骤如下:
- 随机初始化K个质心。
- 将每个数据点分配到距离最近的质心所属的簇。
- 重新计算每个簇的质心(即簇内所有点的均值)。
- 重复步骤2和3,直到质心不再显著变化或达到最大迭代次数。
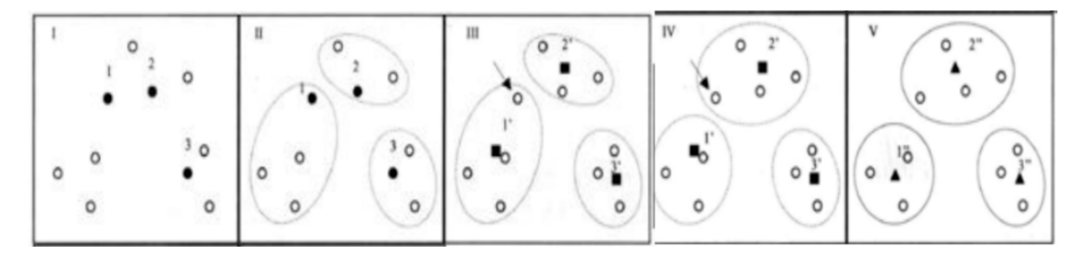
K均值聚类适用于数据分布呈球形或凸形的情况,但对初始质心的选择敏感,且需要预先指定K值。
层次聚类(Hierarchical Clustering)
层次聚类通过构建树状图(树状结构)来展示数据的层次关系,分为凝聚式(自底向上)和分裂式(自顶向下)两种方法。凝聚式层次聚类从每个数据点作为一个单独的簇开始,逐步合并最相似的簇,直到所有数据点属于同一个簇。
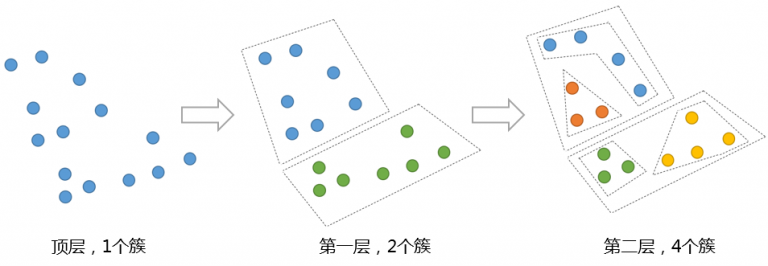
层次聚类的优点是不需要预先指定簇的数量,且可以通过树状图直观展示聚类过程。缺点是计算复杂度较高,不适合大规模数据集。
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)
DBSCAN是一种基于密度的聚类算法,能够发现任意形状的簇,并识别噪声点。其核心思想是将高密度区域的数据点划分为同一簇,低密度区域的数据点标记为噪声。
在DBSCAN算法中将数据点分为三类:
- 核心点(Core point):若样本的邻域内至少包含了MinPts个样本,则称样本点为核心点。
- 边界点(Border point):若样本的邻域内包含的样本数目小于MinPts,但是它在其他核心点的邻域内,则称样本点为边界点。
- 噪音点(Noise):既不是核心点也不是边界点的点
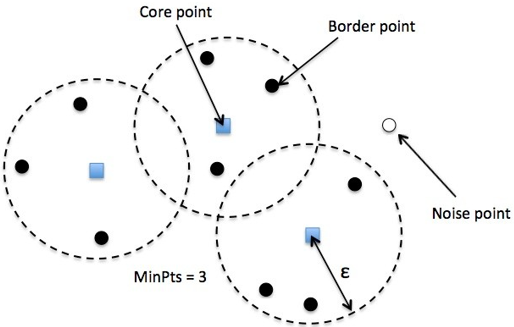
DBSCAN需要两个参数:邻域半径(ε)和最小点数(MinPts)。算法步骤如下:
- 对于每个数据点,计算其ε邻域内的点数。
- 如果邻域内点数≥MinPts,则将该点标记为核心点,并扩展形成簇。
- 重复上述过程,直到所有点被处理。
DBSCAN对噪声和异常值鲁棒,且不需要预先指定簇的数量,但对参数选择敏感。
主成分分析(Principal Component Analysis, PCA)与聚类结合
PCA是一种降维技术,通过线性变换将高维数据投影到低维空间,保留数据的主要方差。PCA可以与聚类方法结合,先对数据进行降维,再应用聚类算法,从而提高计算效率和聚类效果。
PCA适用于高维数据的预处理,但可能丢失非线性结构信息。
高斯混合模型(Gaussian Mixture Models, GMM)
高斯混合模型假设数据是由多个高斯分布混合生成的,通过期望最大化(EM)算法估计每个高斯分布的参数(均值、协方差)和混合系数。GMM能够生成软聚类(即每个数据点属于不同簇的概率),适用于数据分布复杂的情况。
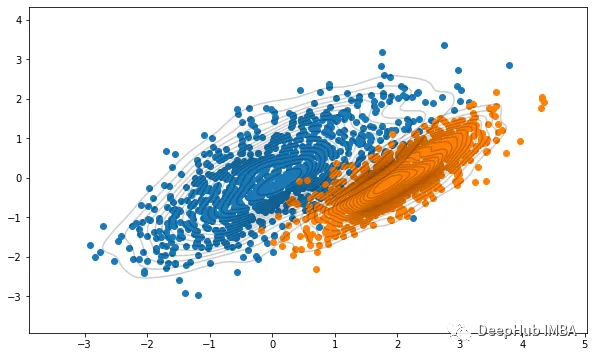
GMM的优点是能够捕捉数据的概率分布,但对初始参数敏感,且计算复杂度较高。
自组织映射(Self-Organizing Maps, SOM)
自组织映射是一种基于神经网络的聚类方法,通过竞争学习将高维数据映射到低维(通常是二维)的网格上,同时保持数据的拓扑结构。SOM的每个神经元代表一个簇,通过迭代调整神经元的权重,使得相似的输入数据映射到相近的神经元。
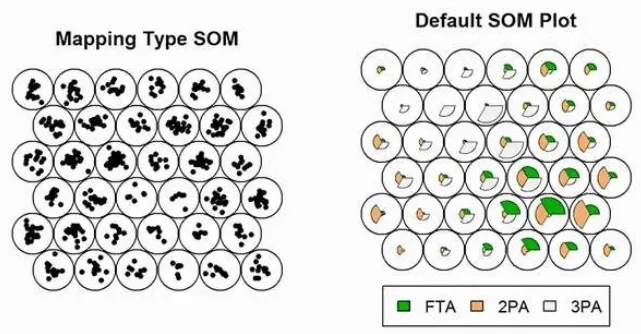
SOM适用于可视化高维数据,但对网络结构和学习参数的选择敏感。
总结
无监督学习中的分类方法多种多样,每种方法各有优缺点。K均值聚类简单高效,层次聚类适合小规模数据,DBSCAN对噪声鲁棒,GMM能够捕捉概率分布,SOM适合高维数据可视化,PCA可与其他聚类方法结合使用。实际应用中需根据数据特点选择合适的算法。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)