计算机毕业设计:基于Django与LSTM的大众点评评价预测系统 Django框架 LSTM Hadoop Spark Hive 可视化 大数据 食品 食物(建议收藏)✅
·
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
技术栈
Python 语言、Django 框架、MySQL 数据库、深度学习 TensorFlow 与 Keras 构建的 LSTM 预测模型、Echarts 可视化库、selenium 爬虫技术、Hadoop 分布式存储、Spark 计算框架、Hive 数据仓库、大众点评数据源
功能模块
- 首页数据概况模块
- 美食类型分析模块
- 美食价格分析模块
- 美食评价分析模块
- 美食地区分析模块
- 美食词云图分析模块
- 美食数据中心模块
- 评价预测模块
- 注册登录模块
- 数据采集模块
项目介绍
本系统基于 Python 与 Django 框架开发,整合 Hadoop、Spark、Hive 大数据技术,构建美食数据分析与评价预测平台。系统通过 selenium 爬虫从大众点评抓取餐厅城市、店铺、餐类、地址、评论、星级、均价等数据,经清洗后存储于 MySQL 数据库及 Hive 数据仓库。前端借助 Echarts 实现数据概况、类型分布、价格区间、地区热度、评价趋势及词云图等多维度可视化分析。评价预测模块采用 TensorFlow 与 Keras 构建 LSTM 深度学习模型,用户输入均价、美食类型、口味评分等条件后输出星级预测结果。平台支持用户注册登录与数据中心管理,为餐饮行业提供数据驱动的决策支持。
2、项目界面
(1)首页–数据概况
该页面是美食数据分析可视化系统的首页,展示top10餐厅价格与评分分析、总体美食类型分布、城市均价分析,同时呈现最高价格、最多评论、最贵餐厅、最多类型等核心统计指标,还具备数据总览、类型分析、价格分析、评价分析、地区分析、美食词云图及评价预测等功能模块。
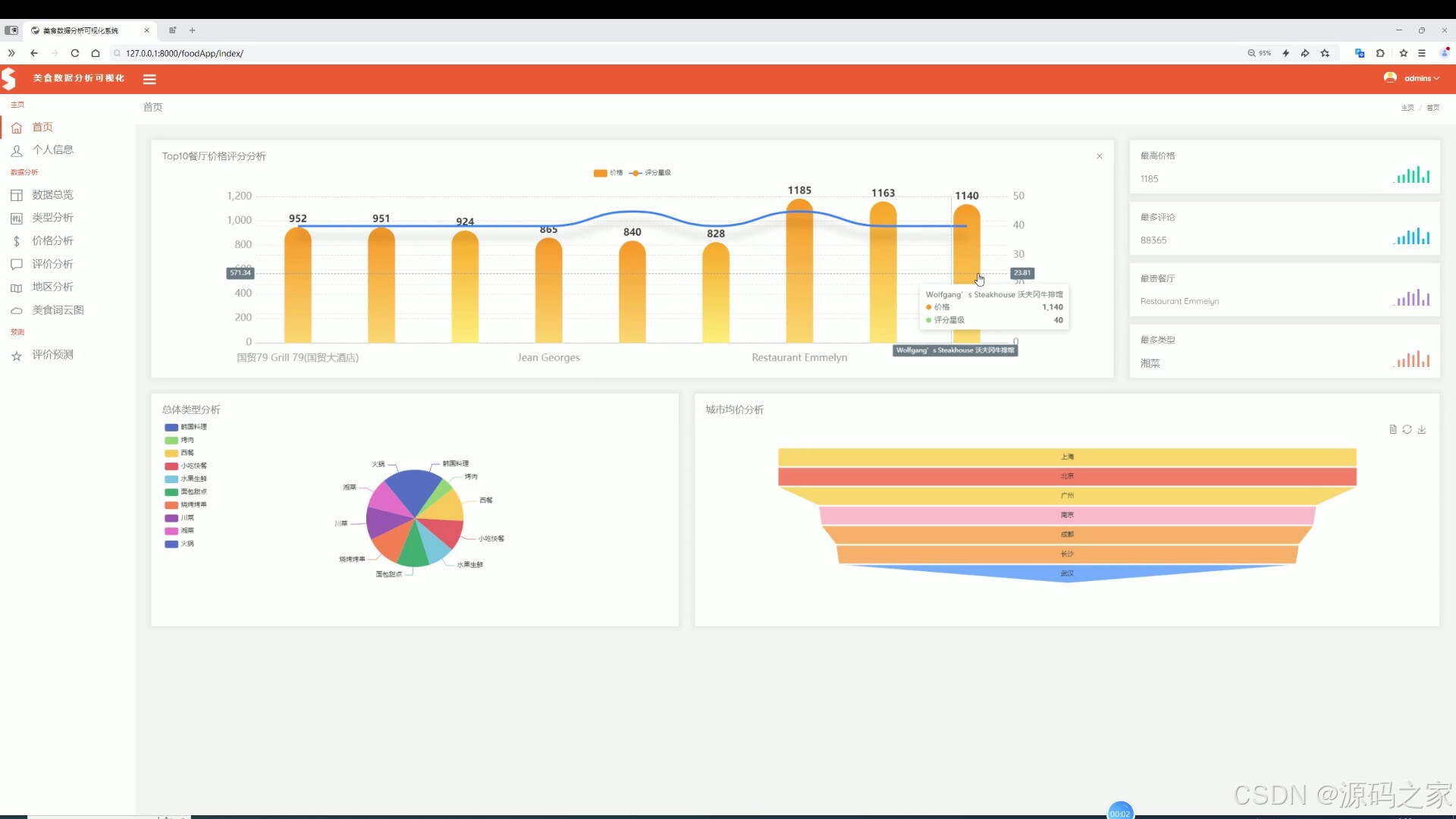
(2)美食类型分析
该页面是美食数据分析可视化系统的类型分析页,展示总体美食类型三大评分趋势、具体餐类占比分布以及类型热度评论量统计,同时具备数据总览、价格分析、评价分析、地区分析、美食词云图及评价预测等功能模块。
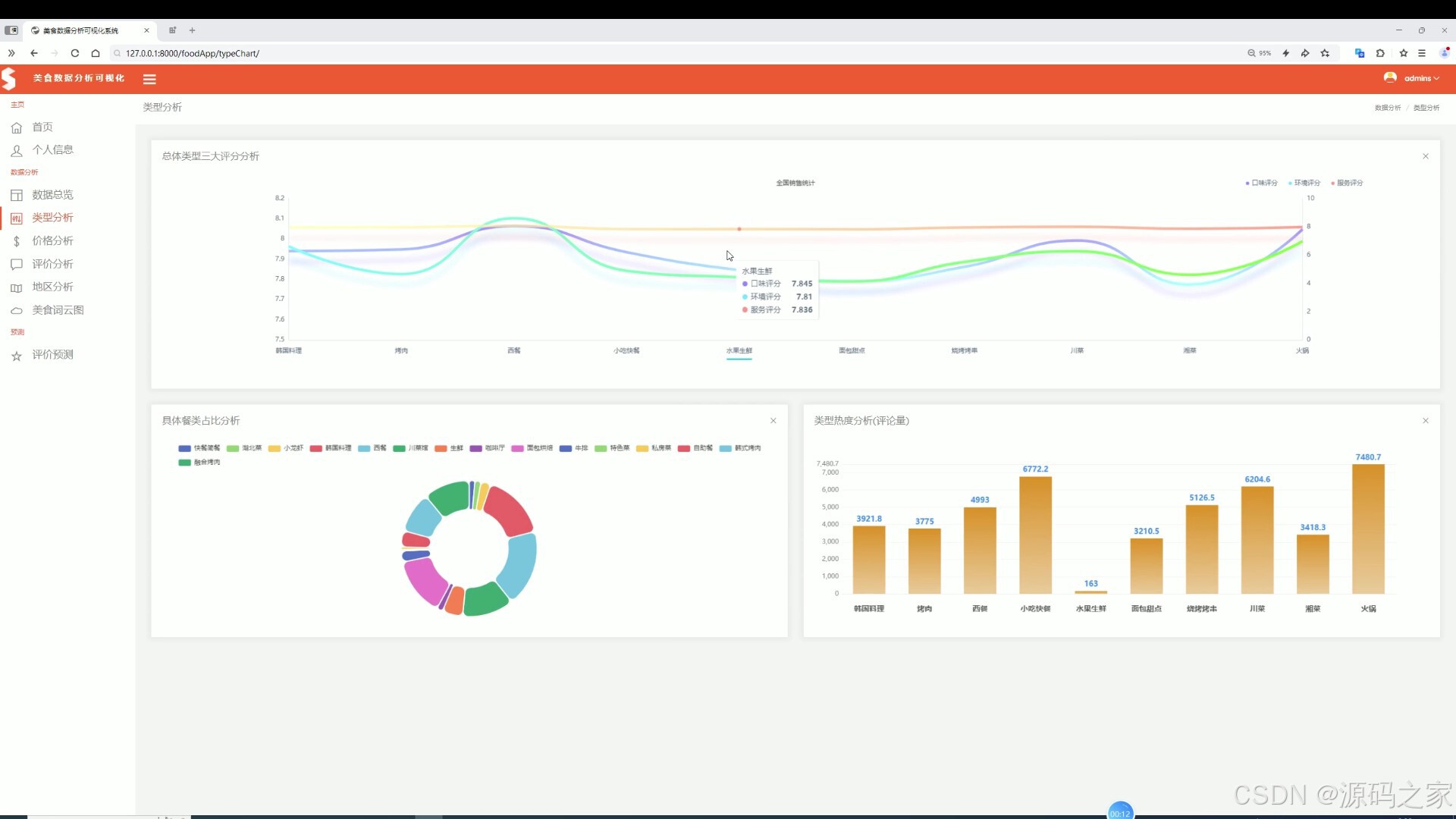
(3)美食价格分析
该页面是美食数据分析可视化系统的价格分析页,展示城市价格最大值分布、不同美食类型的价格平均值对比以及价格区间占比情况,同时具备数据总览、类型分析、评价分析、地区分析、美食词云图及评价预测等功能模块。
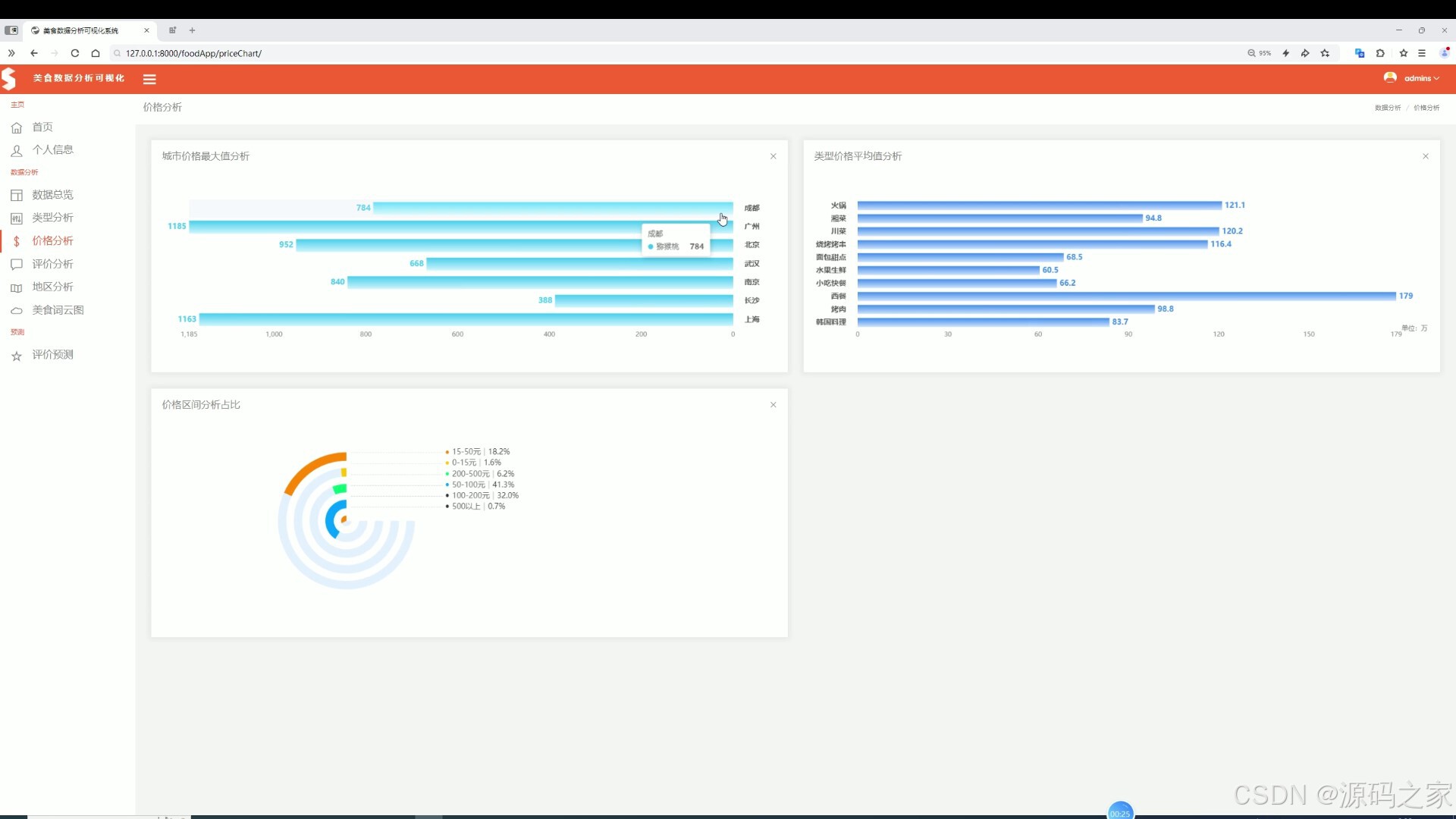
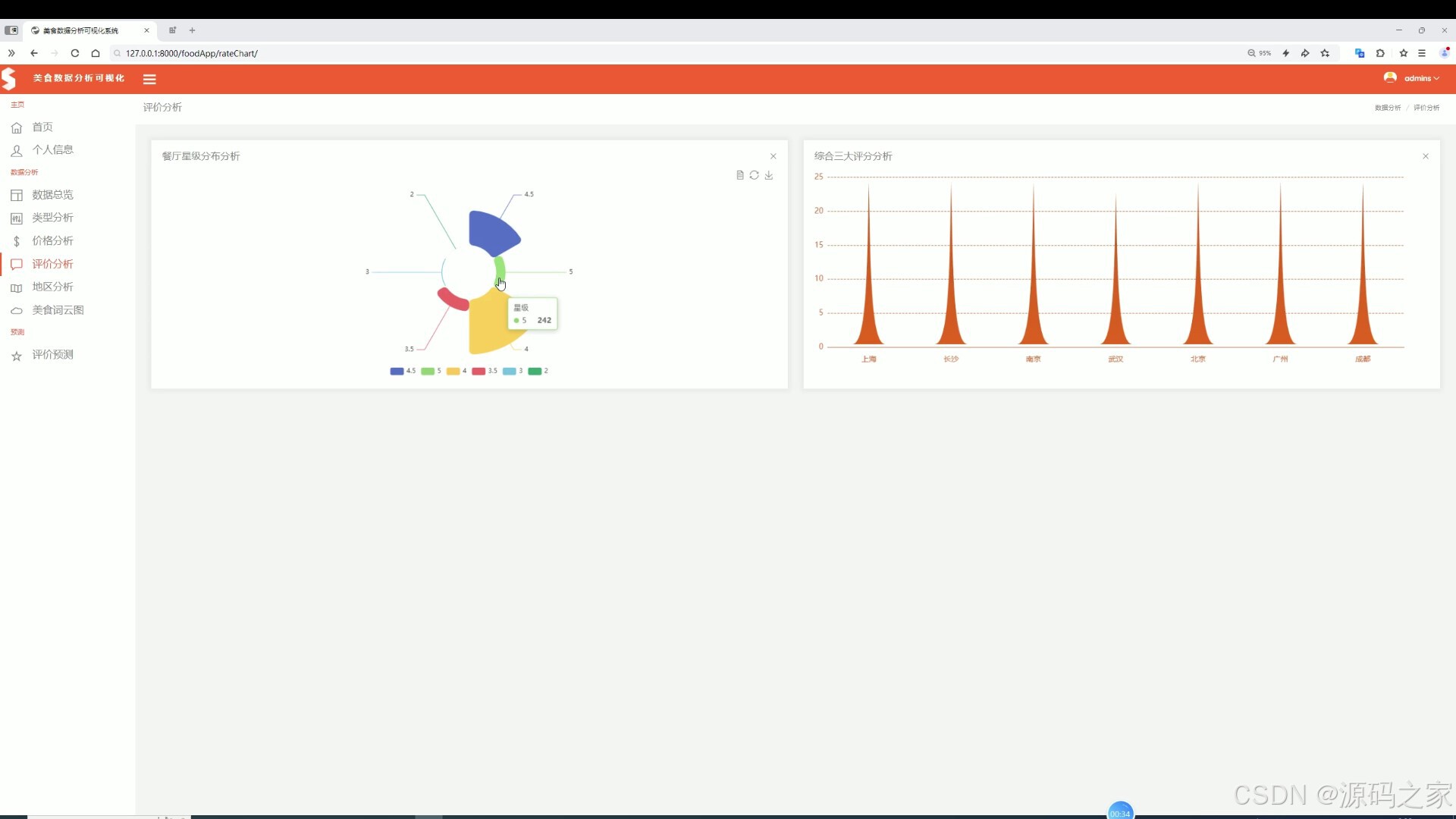
(4)美食评价分析
该页面是美食数据分析可视化系统的评价分析页,展示餐厅星级分布情况和各城市综合三大评分分布,同时具备数据总览、类型分析、价格分析、地区分析、美食词云图及评价预测等功能模块。
(5)美食地区分析
该页面是美食数据分析可视化系统的地区分析页,支持条件查询功能,可展示城市价格分布地图与地区餐饮热度统计,同时具备数据总览、类型分析、价格分析、评价分析、美食词云图及评价预测等功能模块。
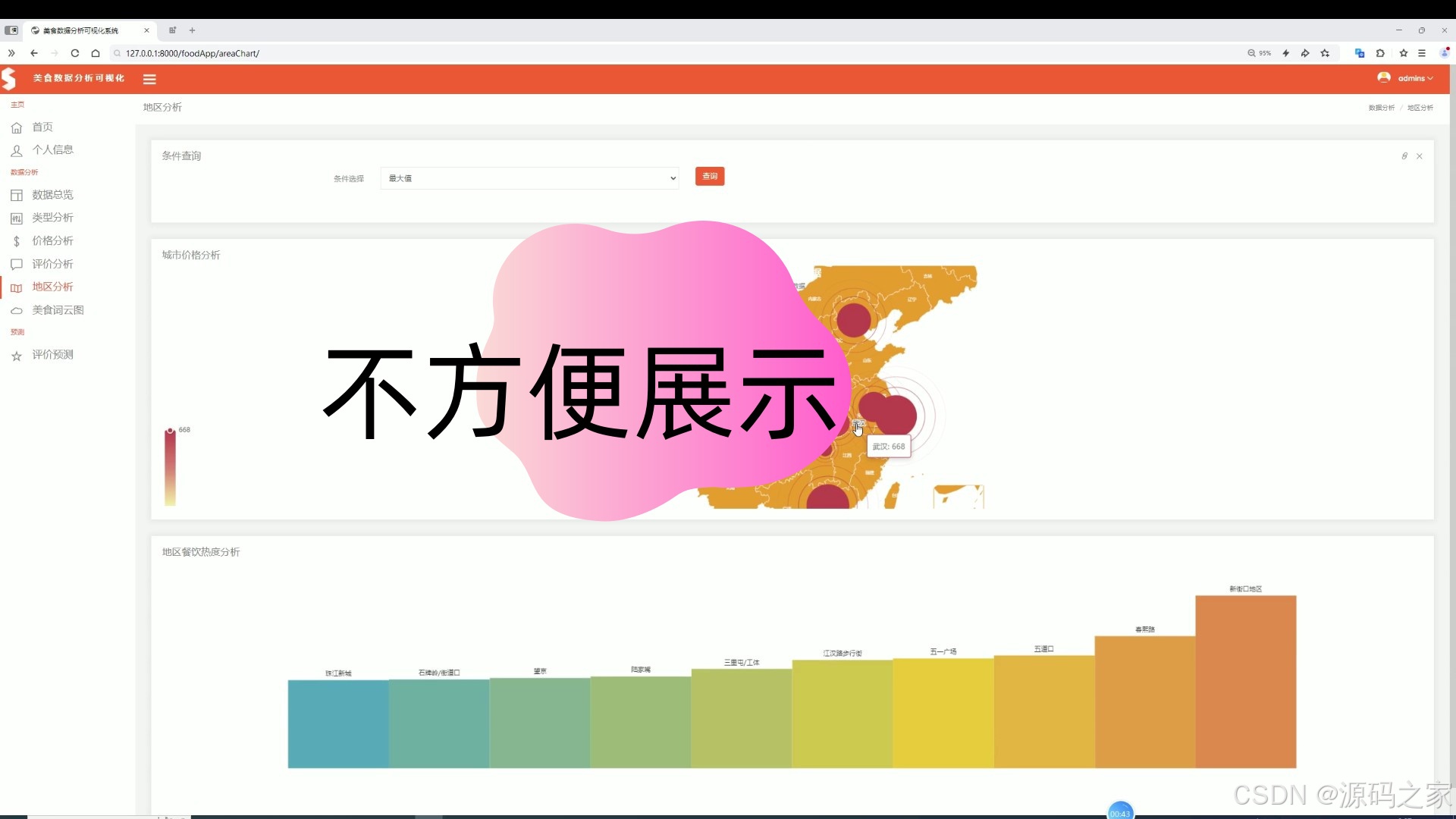
(6)美食词云图分析
该页面是美食数据分析可视化系统的美食词云图页,以词云形式直观展示各类美食类型的出现频次,直观呈现热门美食品类分布,同时具备数据总览、类型分析、价格分析、评价分析、地区分析及评价预测等功能模块。
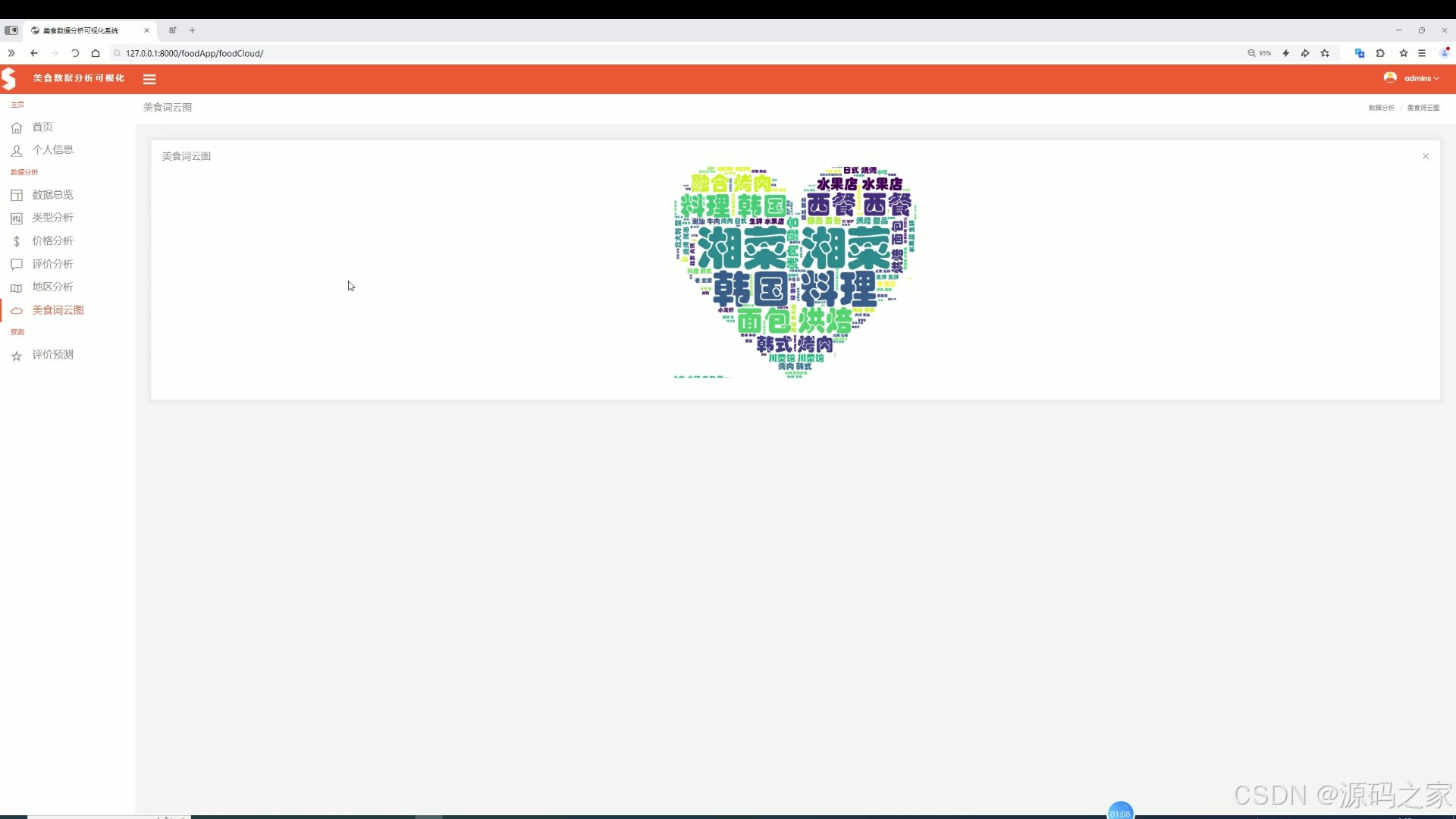
(7)美食数据中心
该页面是美食数据分析可视化系统的数据总览页,支持条件搜索功能,以列表形式展示餐厅的城市、店铺、餐类、地址、评论、星级、均价及各类评分等详细信息,同时具备类型分析、价格分析、评价分析、地区分析、美食词云图及评价预测等功能模块。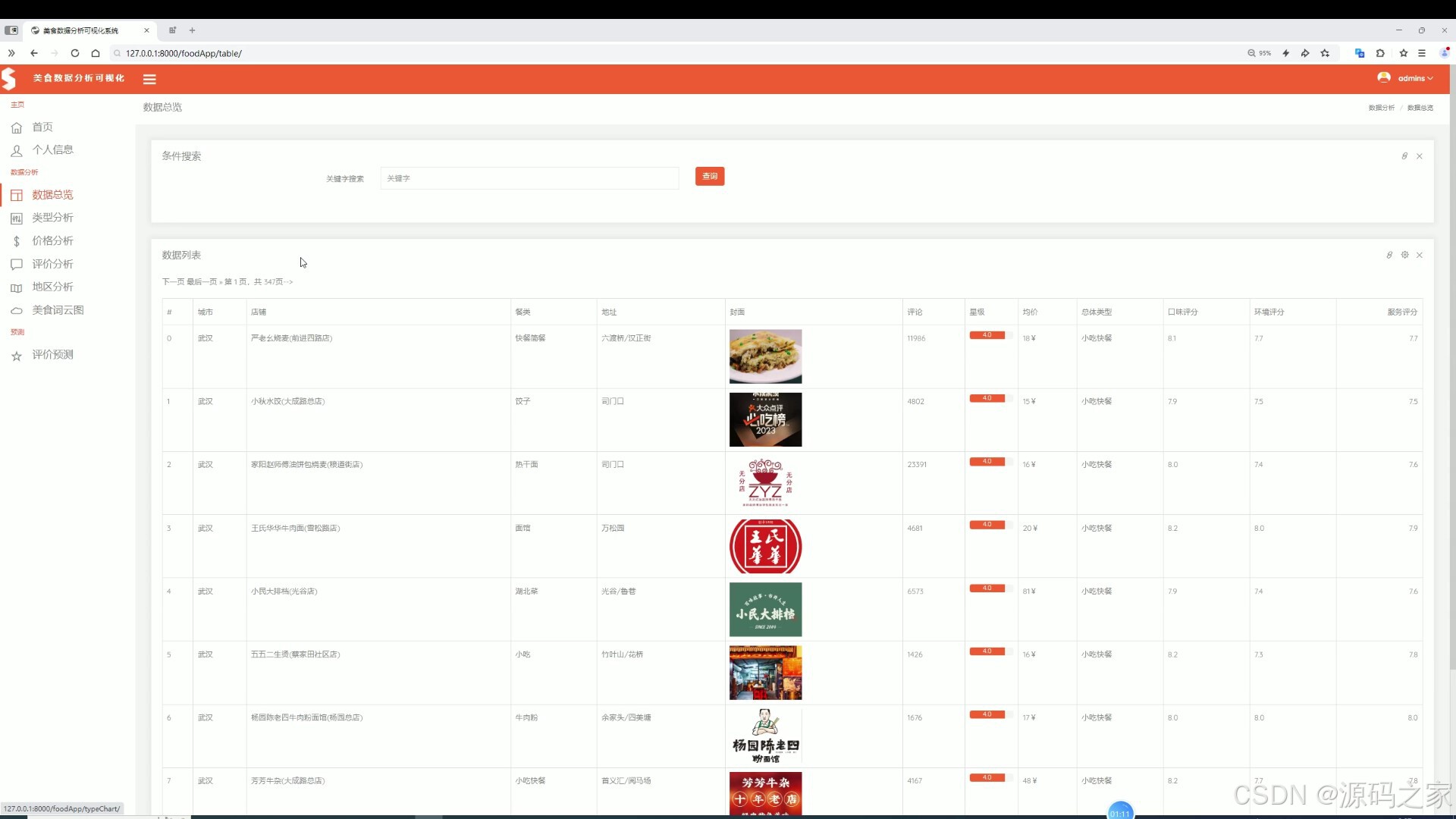
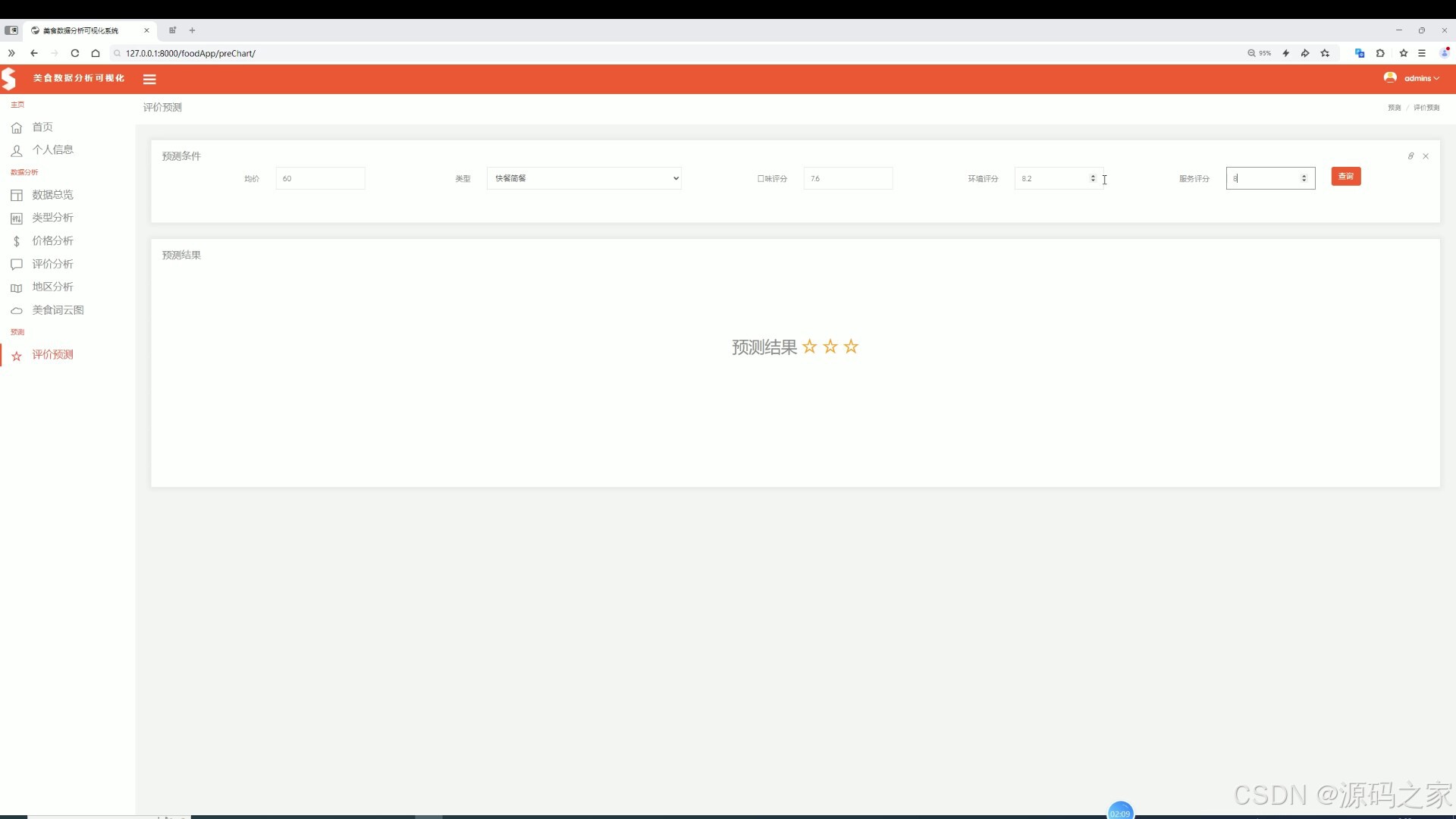
(8)评价预测----- LSTM 预测算法模型
该页面是美食数据分析可视化系统的评价预测页,支持输入均价、美食类型、口味评分、环境评分、服务评分等预测条件,点击查询后可直观展示对应的星级评价预测结果,同时具备数据总览、类型分析、价格分析、评价分析、地区分析及美食词云图等功能模块。
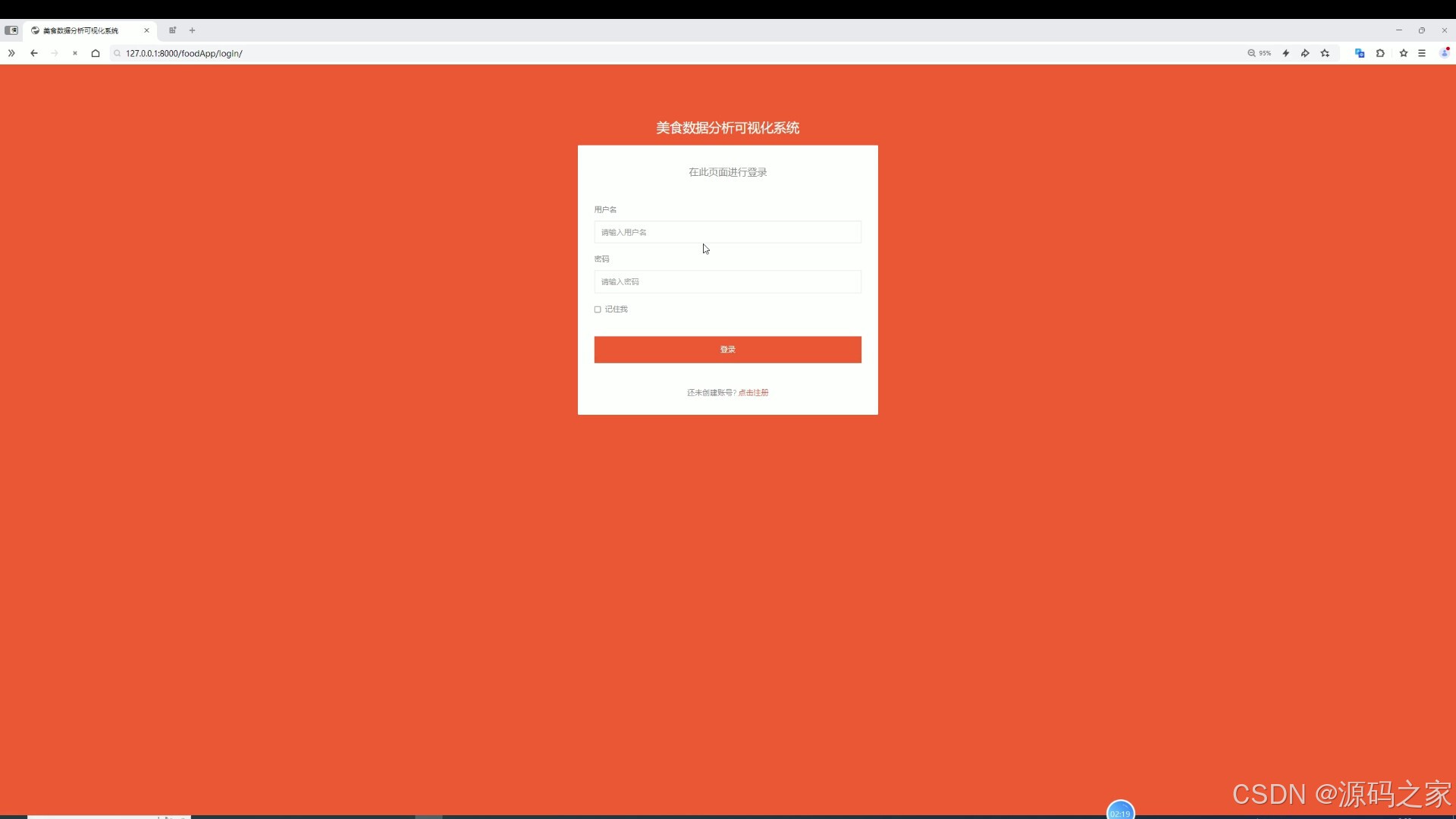
(9)注册登录
该页面是美食数据分析可视化系统的登录页,提供用户名和密码输入框,设有记住我选项与登录按钮,同时提供注册账号的跳转入口,完成身份验证后可进入系统使用数据总览、类型分析、价格分析、评价分析、地区分析、美食词云图及评价预测等功能模块。
(10)数据采集
该页面是美食数据分析可视化系统的爬虫数据采集界面,可编写并运行Python爬虫代码,从大众点评等平台抓取餐厅的城市、店铺、餐类、地址、评论、星级、均价等数据,并支持将采集到的数据保存为CSV文件,为后续的数据分析可视化与评价预测提供原始数据支撑。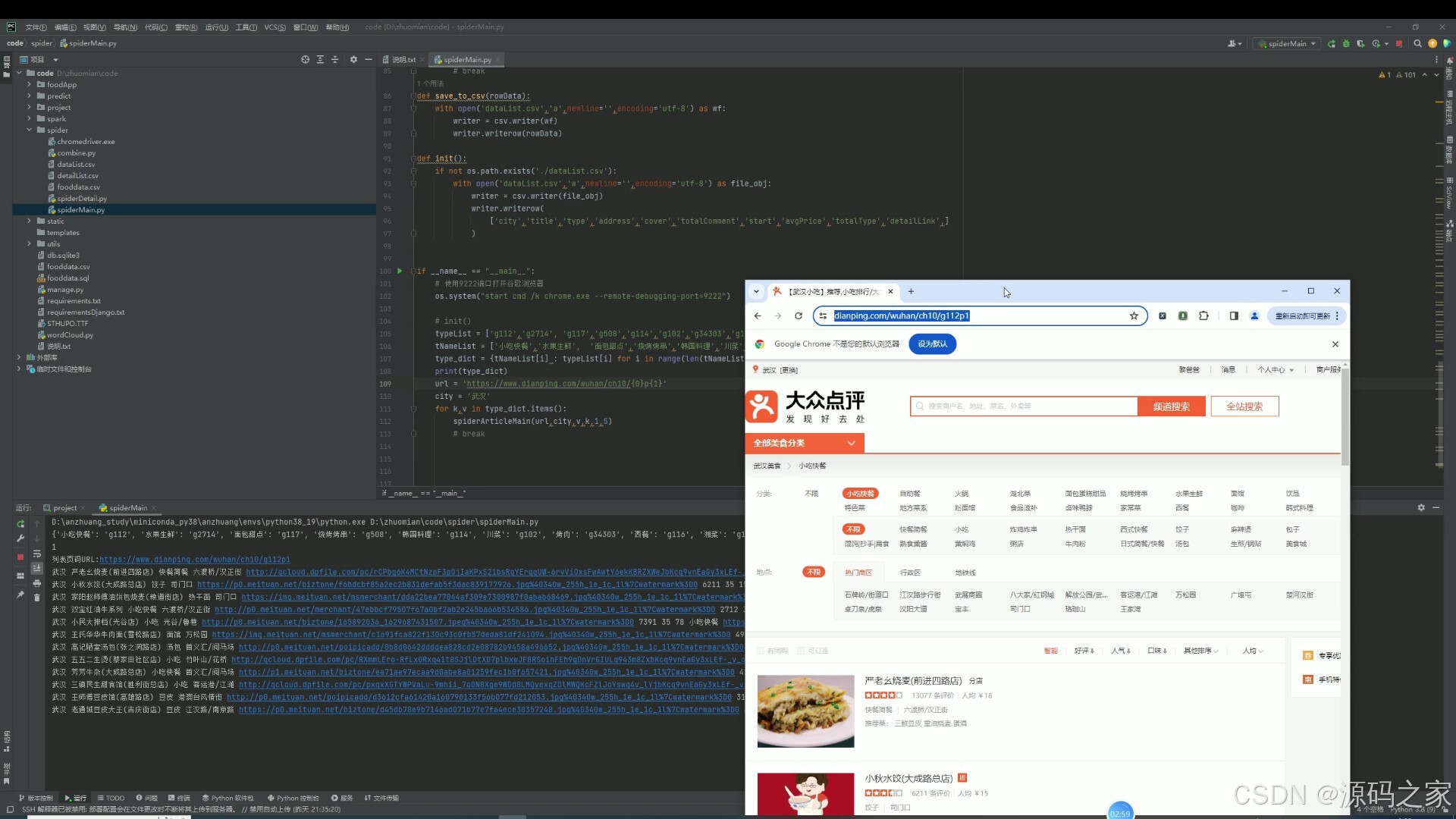
3、项目说明
一、技术栈简要说明
系统后端采用 Python 语言与 Django 框架构建,大数据处理依托 Hadoop 分布式存储、Spark 计算框架与 Hive 数据仓库,数据库选用 MySQL。数据采集使用 selenium 爬虫技术抓取大众点评餐厅信息,可视化部分通过 Echarts 图表库实现多种图形渲染,预测模块基于深度学习 TensorFlow 与 Keras 构建 LSTM 模型进行星级评价预测。
二、功能模块详细介绍
· 首页数据概况模块
作为系统首页,展示 top10 餐厅价格与评分分析、总体美食类型分布、城市均价分析,同时呈现最高价格、最多评论、最贵餐厅、最多类型等核心统计指标,提供数据总览、类型分析、价格分析、评价分析、地区分析、美食词云图及评价预测等功能模块入口。
· 美食类型分析模块
展示总体美食类型三大评分趋势、具体餐类占比分布以及类型热度评论量统计,通过图表直观呈现不同美食类型的用户评分与关注度差异。
· 美食价格分析模块
展示城市价格最大值分布、不同美食类型的价格平均值对比以及价格区间占比情况,帮助用户了解各地餐饮消费水平与价格结构。
· 美食评价分析模块
展示餐厅星级分布情况和各城市综合三大评分分布,通过可视化图表呈现用户评价的集中趋势与地域差异。
· 美食地区分析模块
支持条件查询功能,展示城市价格分布地图与地区餐饮热度统计,直观呈现不同地区的餐饮市场活跃度与价格水平。
· 美食词云图分析模块
以词云形式直观展示各类美食类型的出现频次,呈现热门美食品类分布,帮助用户快速把握市场热点。
· 美食数据中心模块
支持条件搜索功能,以列表形式展示餐厅的城市、店铺、餐类、地址、评论、星级、均价及各类评分等详细信息,实现数据集中管理与检索。
· 评价预测模块
基于 LSTM 深度学习模型,用户输入均价、美食类型、口味评分、环境评分、服务评分等预测条件后,系统输出对应的星级评价预测结果,为商家提供经营决策参考。
· 注册登录模块
提供用户名和密码输入框,设有记住我选项与登录按钮,同时提供注册账号的跳转入口,完成身份验证后可访问系统各项功能模块。
· 数据采集模块
提供爬虫数据采集界面,支持编写并运行 Python 爬虫代码,从大众点评等平台抓取餐厅的城市、店铺、餐类、地址、评论、星级、均价等数据,并可保存为 CSV 文件,为后续分析与预测提供原始数据支撑。
三、项目总结
本系统基于 Python 与 Django 框架开发,整合 Hadoop、Spark、Hive 大数据技术,构建美食数据分析与评价预测平台。系统通过 selenium 爬虫从大众点评抓取餐厅城市、店铺、餐类、地址、评论、星级、均价等数据,经清洗后存储于 MySQL 数据库及 Hive 数据仓库。前端借助 Echarts 实现数据概况、类型分布、价格区间、地区热度、评价趋势及词云图等多维度可视化分析。评价预测模块采用 TensorFlow 与 Keras 构建 LSTM 深度学习模型,用户输入均价、美食类型、口味评分等条件后输出星级预测结果。平台支持用户注册登录与数据中心管理,为餐饮行业提供数据驱动的决策支持。
4、核心代码
#coding:utf8
#导包
from pyspark.sql import SparkSession
from pyspark.sql.functions import monotonically_increasing_id
from pyspark.sql.types import StructType,StructField,IntegerType,StringType,FloatType
from pyspark.sql.functions import count,mean,col,sum,when,max,min,avg
from pyspark.sql import functions as F
if __name__ == '__main__':
#构建
spark = SparkSession.builder.appName("sparkSQL").master("local[*]").\
config("spark.sql.shuffle.partitions", 2). \
config("spark.sql.warehouse.dir", "hdfs://node1:8020/user/hive/warehouse"). \
config("hive.metastore.uris", "thrift://node1:9083"). \
enableHiveSupport().\
getOrCreate()
sc = spark.sparkContext
#读取
fooddata = spark.read.table("fooddata")
#需求一 价格TOP10评分
top_ten_price = fooddata.orderBy(fooddata.avgPrice.desc()).limit(10)
result1 = top_ten_price.select("title","start","avgPrice")
df = result1.toPandas()
# print(df)
# sql
result1.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \
option("dbtable", "maxPriceTop"). \
option("user", "root"). \
option("password", "root"). \
option("encoding", "utf-8"). \
save()
result1.write.mode("overwrite").saveAsTable("maxPriceTop", "parquet")
spark.sql("select * from maxPriceTop").show()
#需求二 totalType
result2 = fooddata.groupby("totalType").count()
# sql
result2.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \
option("dbtable", "typeCount"). \
option("user", "root"). \
option("password", "root"). \
option("encoding", "utf-8"). \
save()
result2.write.mode("overwrite").saveAsTable("typeCount", "parquet")
spark.sql("select * from typeCount").show()
#需求三 城市均价
reuslt3 = fooddata.groupby("city").agg(F.avg("avgPrice").alias("averagePrice"))
# sql
reuslt3.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \
option("dbtable", "cityAvg"). \
option("user", "root"). \
option("password", "root"). \
option("encoding", "utf-8"). \
save()
reuslt3.write.mode("overwrite").saveAsTable("cityAvg", "parquet")
spark.sql("select * from cityAvg").show()
#类型分析
result4 = fooddata.groupby("totalType").agg(avg("totalComment").alias("commentAvg"))
# sql
result4.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \
option("dbtable", "typeComment"). \
option("user", "root"). \
option("password", "root"). \
option("encoding", "utf-8"). \
save()
result4.write.mode("overwrite").saveAsTable("typeComment", "parquet")
spark.sql("select * from typeComment").show()
#需求五
result5 = fooddata.groupby("totalType").agg(
avg("tasterate").alias("avgTasterate"),
avg("envsrate").alias("avgEnvsrate"),
avg("serverate").alias("avgServerate"),
)
# sql
result5.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \
option("dbtable", "typeRate"). \
option("user", "root"). \
option("password", "root"). \
option("encoding", "utf-8"). \
save()
result5.write.mode("overwrite").saveAsTable("typeRate", "parquet")
spark.sql("select * from typeRate").show()
#需求6 精确类型
result6 = fooddata.groupby("type").count()
# sql
result6.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \
option("dbtable", "specificType"). \
option("user", "root"). \
option("password", "root"). \
option("encoding", "utf-8"). \
save()
result6.write.mode("overwrite").saveAsTable("specificType", "parquet")
spark.sql("select * from specificType").show()
#需求七 价格分析
reuslt7 = fooddata.groupby("city").agg(max("avgPrice").alias("maxAvgPrice"))
# sql
reuslt7.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \
option("dbtable", "maxPriceCity"). \
option("user", "root"). \
option("password", "root"). \
option("encoding", "utf-8"). \
save()
reuslt7.write.mode("overwrite").saveAsTable("maxPriceCity", "parquet")
spark.sql("select * from maxPriceCity").show()
#需求八 价格分类
fooddata_with_category = fooddata.withColumn(
"prcieCategory",
when(col("avgPrice").between(0,15),'0-15元')
.when(col("avgPrice").between(15, 50), '15-50元')
.when(col("avgPrice").between(50, 100), '50-100元')
.when(col("avgPrice").between(100, 200), '100-200元')
.when(col("avgPrice").between(200, 500), '200-500元')
.otherwise('500以上')
)
reuslt8 = fooddata_with_category.groupby("prcieCategory").count()
# sql
reuslt8.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \
option("dbtable", "categoryPrice"). \
option("user", "root"). \
option("password", "root"). \
option("encoding", "utf-8"). \
save()
reuslt8.write.mode("overwrite").saveAsTable("categoryPrice", "parquet")
spark.sql("select * from categoryPrice").show()
# 类型均价
reuslt9 = fooddata.groupby("totalType").agg(avg("avgPrice").alias("allAvgPrice"))
# sql
reuslt9.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \
option("dbtable", "typePrice"). \
option("user", "root"). \
option("password", "root"). \
option("encoding", "utf-8"). \
save()
reuslt9.write.mode("overwrite").saveAsTable("typePrice", "parquet")
spark.sql("select * from typePrice").show()
#需求十 星级分布
result10 = fooddata.groupby("start").count()
# sql
result10.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \
option("dbtable", "startCount"). \
option("user", "root"). \
option("password", "root"). \
option("encoding", "utf-8"). \
save()
result10.write.mode("overwrite").saveAsTable("startCount", "parquet")
spark.sql("select * from startCount").show()
#需求十一
fooddata_with_mixrate = fooddata.withColumn("mixrate",
col("tasterate")+col("envsrate")+col("serverate"))
reuslt11 = fooddata_with_mixrate.groupby("city").agg(avg("mixrate").alias("avgMixrate"))
# sql
reuslt11.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \
option("dbtable", "mixrateAvg"). \
option("user", "root"). \
option("password", "root"). \
option("encoding", "utf-8"). \
save()
reuslt11.write.mode("overwrite").saveAsTable("mixrateAvg", "parquet")
spark.sql("select * from mixrateAvg").show()
# 价格最大最小
result12 = fooddata.groupby("city").agg(
max("avgPrice").alias("maxAvfPrice"),
avg("avgPrice").alias("avgAvfPrice"),
min("avgPrice").alias("minAvfPrice"),
)
# sql
result12.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \
option("dbtable", "mamCity"). \
option("user", "root"). \
option("password", "root"). \
option("encoding", "utf-8"). \
save()
result12.write.mode("overwrite").saveAsTable("mamCity", "parquet")
spark.sql("select * from mamCity").show()
#需求十三
total_comments_df = fooddata.groupby("address").agg(
sum("totalComment").alias("sumTotalComment")
)
reuslt13 = total_comments_df.orderBy(col("sumTotalComment").desc()).limit(10)
# sql
reuslt13.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \
option("dbtable", "hotAddress"). \
option("user", "root"). \
option("password", "root"). \
option("encoding", "utf-8"). \
save()
reuslt13.write.mode("overwrite").saveAsTable("hotAddress", "parquet")
spark.sql("select * from hotAddress").show()
5、项目列表



6、项目获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 19
19 0
0- 0



 已为社区贡献67条内容
已为社区贡献67条内容

所有评论(0)