AI大模型应用面试:深度学习知识点汇总与面试指导
🎯 适用岗位:AI应用开发工程师、算法工程师、大模型应用工程师
📅 更新时间:2024年
📊 难度等级:⭐⭐⭐⭐(中高级)
⏱️ 阅读时长:约45分钟
目录
一、机器学习基础
问题1:机器学习的方式有哪几类?
标准回答:
机器学习主要分为三大类:
详细说明:
1. 监督学习(Supervised Learning)
- 定义:使用有标签的数据进行训练
- 特点:输入X和输出Y都已知,学习X→Y的映射关系
- 示例:
- 分类:垃圾邮件识别、图像分类
- 回归:房价预测、股票预测
2. 无监督学习(Unsupervised Learning)
- 定义:使用无标签的数据进行训练
- 特点:只有输入X,发现数据的内在结构和模式
- 示例:
- 聚类:客户分群、新闻聚类
- 降维:PCA、t-SNE
3. 强化学习(Reinforcement Learning)
- 定义:通过与环境交互学习最优策略
- 特点:通过奖励和惩罚机制学习
- 示例:
- 游戏AI:AlphaGo、Atari游戏
- 机器人控制:自动驾驶、机械臂
面试技巧:
回答时可以这样组织:
1. 先说三大类:监督学习、无监督学习、强化学习
2. 每类简要说明特点
3. 举1-2个实际例子
4. 如果有时间,可以提到半监督学习、自监督学习等扩展
问题2:每种方式对应的任务是什么?
标准回答:
详细说明:
| 学习方式 | 任务类型 | 具体任务 | 应用场景 |
|---|---|---|---|
| 监督学习 | 分类 | 二分类、多分类 | 垃圾邮件识别、疾病诊断 |
| 回归 | 线性回归、非线性回归 | 房价预测、销量预测 | |
| 无监督学习 | 聚类 | K-Means、DBSCAN | 客户分群、图像分割 |
| 降维 | PCA、t-SNE | 数据可视化、特征压缩 | |
| 生成 | GAN、VAE | 图像生成、文本生成 | |
| 强化学习 | 控制 | 策略优化 | 机器人控制、自动驾驶 |
| 游戏 | 博弈策略 | AlphaGo、游戏AI |
面试技巧:
回答时可以这样组织:
1. 按学习方式分类说明
2. 每类列举2-3个主要任务
3. 结合实际应用场景
4. 可以提到自己项目中用到的任务类型
问题3:为什么要划分数据集?数据集为什么要标准归一化?
标准回答:
3.1 为什么要划分数据集?
划分原因:
1. 防止过拟合
- 如果只用训练集,模型可能"记住"训练数据
- 需要独立的数据评估模型的泛化能力
2. 模型选择
- 验证集用于调整超参数
- 选择最优模型配置
3. 客观评估
- 测试集提供模型性能的客观评估
- 模拟真实场景的未知数据
常见划分比例:
- 小数据集:60%训练 + 20%验证 + 20%测试
- 中等数据集:80%训练 + 10%验证 + 10%测试
- 大数据集:98%训练 + 1%验证 + 1%测试
3.2 为什么要标准归一化?
归一化原因:
1. 加速收敛
- 不同特征的量纲不同,影响梯度下降速度
- 归一化后,所有特征在同一尺度,加速收敛
2. 提高精度
- 避免大数值特征主导模型
- 让模型更公平地学习每个特征
3. 数值稳定
- 避免数值计算中的溢出问题
- 提高数值计算的稳定性
常见归一化方法:
1. Min-Max归一化
X_normalized = (X - X_min) / (X_max - X_min)
# 范围:[0, 1]
2. Z-Score标准化
X_standardized = (X - X_mean) / X_std
# 均值为0,标准差为1
面试技巧:
回答时可以这样组织:
1. 数据集划分:先说目的(防止过拟合、模型选择、客观评估)
2. 说明三个数据集的作用
3. 归一化:先说问题(量纲不同、收敛慢)
4. 说明好处(加速收敛、提高精度、数值稳定)
5. 可以举一个具体的例子
问题4:机器学习常见的算法模型有哪些?
标准回答:
详细说明:
1. 监督学习算法
| 算法 | 类型 | 优点 | 缺点 | 应用场景 |
|---|---|---|---|---|
| 线性回归 | 回归 | 简单、可解释性强 | 只能处理线性关系 | 房价预测 |
| 逻辑回归 | 分类 | 简单、概率输出 | 只能处理线性可分 | 二分类问题 |
| 决策树 | 分类/回归 | 可解释性强、处理非线性 | 容易过拟合 | 特征选择 |
| 随机森林 | 分类/回归 | 不易过拟合、特征重要性 | 训练慢 | 风控模型 |
| XGBoost | 分类/回归 | 性能强、速度快 | 调参复杂 | 竞赛首选 |
| SVM | 分类 | 高维数据表现好 | 大数据集慢 | 文本分类 |
| 神经网络 | 分类/回归 | 表达能力强 | 需要大量数据 | 图像、NLP |
2. 无监督学习算法
| 算法 | 类型 | 应用场景 |
|---|---|---|
| K-Means | 聚类 | 客户分群、图像压缩 |
| DBSCAN | 聚类 | 异常检测、地理数据 |
| PCA | 降维 | 数据可视化、特征压缩 |
| t-SNE | 降维 | 高维数据可视化 |
| GAN | 生成 | 图像生成、数据增强 |
面试技巧:
回答时可以这样组织:
1. 按学习方式分类说明
2. 每类列举3-5个常用算法
3. 说明每个算法的特点和应用场景
4. 可以提到自己项目中用过的算法
问题5:评价回归任务的指标有哪些?
标准回答:
详细说明:
1. MAE(Mean Absolute Error)平均绝对误差
MAE = (1/n) * Σ|y_true - y_pred|
- 含义:预测值与真实值的平均绝对距离
- 优点:对异常值不敏感
- 缺点:不能反映误差的分布情况
2. MSE(Mean Squared Error)均方误差
MSE = (1/n) * Σ(y_true - y_pred)²
- 含义:预测值与真实值的平均平方距离
- 优点:数学性质好,可导
- 缺点:对异常值敏感
3. RMSE(Root Mean Squared Error)均方根误差
RMSE = √MSE
- 含义:MSE的平方根
- 优点:与原始数据同量纲,易于理解
- 缺点:对异常值敏感
4. MAPE(Mean Absolute Percentage Error)平均绝对百分比误差
MAPE = (100/n) * Σ|y_true - y_pred| / y_true|
- 含义:误差占真实值的百分比
- 优点:不受量纲影响
- 缺点:真实值为0时无法计算
5. R²(R-Squared)决定系数
R² = 1 - (SS_res / SS_tot)
= 1 - Σ(y_true - y_pred)² / Σ(y_true - y_mean)²
- 含义:模型解释的方差比例
- 范围:0-1,越接近1越好
- 优点:不受量纲影响,易于比较
面试技巧:
回答时可以这样组织:
1. 先列举常用指标:MAE、MSE、RMSE、R²
2. 说明每个指标的含义和公式
3. 说明优缺点和适用场景
4. 可以提到自己项目中用过的指标
问题6:什么是正则化,用自己的话表述一下
标准回答:
通俗解释:
正则化就是给模型"戴紧箍咒",防止模型"太聪明"导致过拟合。
具体来说:
1. 为什么需要正则化?
- 模型太复杂时,会"记住"训练数据的噪声
- 就像学生死记硬背,考试时遇到新题就不会了
- 正则化限制模型复杂度,让模型学到"规律"而不是"死记硬背"
2. 正则化的作用
- 防止过拟合:限制模型复杂度
- 特征选择:让不重要的特征权重趋近于0
- 提高泛化能力:让模型在新数据上表现更好
3. 常见正则化方法
L1正则化(Lasso)
Loss = MSE + λ * Σ|w|
- 特点:让部分权重变为0,实现特征选择
- 适用:特征选择、稀疏模型
L2正则化(Ridge)
Loss = MSE + λ * Σw²
- 特点:让权重变小,但不为0
- 适用:防止过拟合、处理共线性
Dropout
# 随机丢弃神经元
output = dropout(layer_output, p=0.5)
- 特点:训练时随机丢弃部分神经元
- 适用:神经网络正则化
面试技巧:
用自己的话表述:
1. 先用通俗的比喻:正则化就是给模型"戴紧箍咒"
2. 解释为什么需要:防止模型"太聪明"导致过拟合
3. 说明作用:防止过拟合、特征选择、提高泛化能力
4. 举例说明:L1、L2、Dropout
问题7:什么是超参数?
标准回答:
详细说明:
1. 什么是超参数?
- 定义:在模型训练前需要手动设定的参数
- 特点:不能通过训练数据学习得到
- 作用:控制模型的学习过程和复杂度
2. 常见超参数
| 超参数 | 含义 | 典型值 | 影响 |
|---|---|---|---|
| 学习率 | 梯度下降的步长 | 0.001-0.1 | 收敛速度、稳定性 |
| 批次大小 | 一次训练的样本数 | 16-256 | 训练速度、泛化能力 |
| 训练轮数 | 遍历数据集的次数 | 10-1000 | 欠拟合/过拟合 |
| 隐藏层数 | 神经网络的深度 | 2-100 | 模型复杂度 |
| 神经元数 | 每层的神经元数量 | 64-1024 | 模型容量 |
| 正则化系数 | 正则化的强度 | 0.001-0.1 | 过拟合控制 |
| Dropout率 | 神经元丢弃概率 | 0.2-0.5 | 过拟合控制 |
3. 超参数 vs 模型参数
| 特性 | 模型参数 | 超参数 |
|---|---|---|
| 获取方式 | 训练过程中学习 | 训练前手动设定 |
| 示例 | 权重、偏置 | 学习率、批次大小 |
| 优化方式 | 梯度下降等 | 网格搜索、贝叶斯优化 |
| 数量 | 通常很多(百万级) | 通常较少(几十个) |
面试技巧:
回答时可以这样组织:
1. 定义:训练前手动设定的参数
2. 特点:不能通过训练学习
3. 举例:学习率、批次大小、训练轮数等
4. 对比:与模型参数的区别
二、模型训练与评估
问题8:模型训练是在做什么事情?用自己的话表述一下,学习率是什么?
标准回答:
8.1 模型训练是在做什么?
通俗解释:
模型训练就是"不断试错,逐步优化"的过程。
具体来说:
1. 初始化
- 随机初始化模型参数(权重和偏置)
- 就像学生刚开始学习,什么都不会
2. 前向传播
- 用当前参数计算预测值
- 就像学生做题,给出答案
3. 计算损失
- 比较预测值和真实值的差距
- 就像老师批改作业,指出错误
4. 反向传播
- 计算每个参数对损失的贡献
- 就像学生分析错误原因
5. 更新参数
- 根据梯度调整参数
- 就像学生改正错误,下次做得更好
6. 循环迭代
- 重复上述过程,直到损失足够小
- 就像学生反复练习,直到掌握知识
8.2 学习率是什么?
通俗解释:
学习率就是"每次改正错误的步子大小"。
具体来说:
1. 定义
- 学习率控制参数更新的步长
- 公式:
新参数 = 旧参数 - 学习率 × 梯度
2. 作用
- 学习率太大:步子太大,可能跨过最优解,甚至发散
- 学习率太小:步子太小,收敛太慢,训练时间长
- 学习率适中:稳定收敛,快速找到最优解
3. 学习率调整策略
- 固定学习率:全程使用相同学习率
- 学习率衰减:随着训练逐渐减小学习率
- 自适应学习率:Adam、AdaGrad等自适应调整
面试技巧:
用自己的话表述:
1. 模型训练:不断试错,逐步优化的过程
2. 用学生学习的类比:做题→批改→分析→改正→反复练习
3. 学习率:每次改正错误的步子大小
4. 说明学习率大小的影响:太大震荡,太小太慢
三、神经网络基础
问题9:什么是神经网络?
标准回答:
详细说明:
1. 定义
- 神经网络是一种模拟人脑神经元连接的数学模型
- 由大量相互连接的节点(神经元)组成
- 通过学习数据中的模式来完成预测任务
2. 基本结构
神经元(Neuron)
output = activation(W * X + b)
- X:输入特征
- W:权重
- b:偏置
- activation:激活函数
层级结构
- 输入层:接收原始数据
- 隐藏层:提取特征,进行非线性变换
- 输出层:输出预测结果
3. 工作原理
- 前向传播:数据从输入层流向输出层
- 计算损失:比较预测值和真实值
- 反向传播:计算梯度,更新参数
- 迭代训练:重复上述过程
面试技巧:
回答时可以这样组织:
1. 定义:模拟人脑神经元连接的数学模型
2. 结构:输入层、隐藏层、输出层
3. 工作原理:前向传播、反向传播
4. 可以画一个简单的神经网络图
问题10:深度学习的深在哪?
标准回答:
详细说明:
1. "深"的含义
- 层数深:神经网络有很多层(10-100+层)
- 特征深:学习层次化的特征表示
- 抽象深:从低级特征到高级语义
2. 深度的价值
层次化特征学习
原始数据
↓
低级特征(边缘、纹理)
↓
中级特征(形状、部件)
↓
高级特征(物体、语义)
↓
预测结果
示例:图像识别
- 第1层:学习边缘、纹理
- 第2层:学习形状、部件
- 第3层:学习物体、场景
- 第4层:学习语义、概念
3. 为什么需要深度?
- 表达能力:深层网络可以学习更复杂的函数
- 特征复用:低级特征可以组合成高级特征
- 自动特征工程:不需要人工设计特征
面试技巧:
回答时可以这样组织:
1. 直接回答:层数多(10-100+层)
2. 解释价值:层次化特征学习
3. 举例说明:图像识别的特征层次
4. 说明优势:表达能力强、自动特征工程
问题11:一个简单神经网络结构有哪些,经典神经网络架构有哪些,解决什么问题?
标准回答:
11.1 简单神经网络结构
基本组件:
- 输入层:接收原始特征
- 隐藏层:进行非线性变换
- 输出层:输出预测结果
- 激活函数:引入非线性
- 损失函数:评估预测误差
11.2 经典神经网络架构
详细说明:
1. CNN(卷积神经网络)
- 解决问题:图像识别、计算机视觉
- 核心思想:局部连接、权值共享、池化
- 经典模型:LeNet、AlexNet、VGG、ResNet
- 应用场景:图像分类、目标检测、图像分割
2. RNN(循环神经网络)
- 解决问题:序列数据建模
- 核心思想:处理序列数据,保留历史信息
- 经典模型:RNN、LSTM、GRU
- 应用场景:文本生成、语音识别、机器翻译
3. Transformer
- 解决问题:长序列依赖、并行计算
- 核心思想:自注意力机制
- 经典模型:BERT、GPT、LLaMA
- 应用场景:NLP、大模型、多模态
面试技巧:
回答时可以这样组织:
1. 简单结构:输入层、隐藏层、输出层
2. 经典架构:CNN、RNN、Transformer
3. 每个架构说明:解决问题、核心思想、经典模型、应用场景
4. 可以提到自己项目中用过的架构
问题12:什么是激活函数,常见的激活函数有哪些?
标准回答:
详细说明:
1. 什么是激活函数?
- 定义:引入非线性变换的函数
- 作用:让神经网络学习非线性关系
- 必要性:没有激活函数,多层神经网络等价于单层
2. 常见激活函数
Sigmoid
f(x) = 1 / (1 + e^(-x))
- 范围:(0, 1)
- 优点:输出在0-1之间,适合概率输出
- 缺点:梯度消失、输出不以0为中心
- 应用:二分类输出层
Tanh
f(x) = (e^x - e^(-x)) / (e^x + e^(-x))
- 范围:(-1, 1)
- 优点:输出以0为中心
- 缺点:梯度消失
- 应用:隐藏层
ReLU(最常用)
f(x) = max(0, x)
- 范围:[0, +∞)
- 优点:计算简单、缓解梯度消失、稀疏激活
- 缺点:神经元死亡(输入<0时梯度为0)
- 应用:隐藏层(默认选择)
Leaky ReLU
f(x) = max(0.01x, x)
- 优点:解决ReLU神经元死亡问题
- 应用:隐藏层
Softmax
f(x_i) = e^(x_i) / Σe^(x_j)
- 作用:将输出转换为概率分布
- 应用:多分类输出层
面试技巧:
回答时可以这样组织:
1. 定义:引入非线性变换的函数
2. 作用:让神经网络学习非线性关系
3. 列举常见激活函数:Sigmoid、Tanh、ReLU、Softmax
4. 说明每个函数的特点和应用场景
四、深度学习核心概念
问题13:什么是前向传播?
标准回答:
详细说明:
1. 定义
- 前向传播是数据从输入层流向输出层的过程
- 逐层计算每一层的输出,最终得到预测值
2. 计算过程
# 第1层
z1 = W1 · X + b1
a1 = activation(z1)
# 第2层
z2 = W2 · a1 + b2
a2 = activation(z2)
# 输出层
y_pred = W3 · a2 + b3
3. 作用
- 将输入数据转换为预测输出
- 为反向传播提供计算图
面试技巧:
回答时可以这样组织:
1. 定义:数据从输入层流向输出层
2. 计算过程:逐层线性变换+激活函数
3. 作用:得到预测值,为反向传播做准备
问题14:什么是反向传播?
标准回答:
详细说明:
1. 定义
- 反向传播是利用链式法则计算梯度的过程
- 从输出层向输入层反向传递误差
2. 计算过程
# 计算损失
loss = loss_function(y_pred, y_true)
# 计算输出层梯度
∂L/∂y = ∂loss/∂y_pred
# 反向传播到第2层
∂L/∂W2 = ∂L/∂y · ∂y/∂W2
∂L/∂b2 = ∂L/∂y · ∂y/∂b2
# 反向传播到第1层
∂L/∂W1 = ∂L/∂W2 · ∂W2/∂a1 · ∂a1/∂W1
∂L/∂b1 = ∂L/∂W2 · ∂W2/∂a1 · ∂a1/∂b1
# 更新参数
W2 = W2 - learning_rate · ∂L/∂W2
W1 = W1 - learning_rate · ∂L/∂W1
3. 核心思想
- 链式法则:复合函数的导数等于各层导数的乘积
- 梯度传播:误差从输出层向输入层传播
- 参数更新:根据梯度调整参数
面试技巧:
回答时可以这样组织:
1. 定义:利用链式法则计算梯度
2. 过程:从输出层向输入层反向传递误差
3. 核心思想:链式法则、梯度传播、参数更新
问题15:什么是损失函数,说一个你知道的损失函数?
标准回答:
详细说明:
1. 什么是损失函数?
- 定义:衡量模型预测值与真实值差距的函数
- 作用:指导模型优化方向
- 目标:最小化损失函数
2. 常见损失函数
MSE(均方误差)- 回归任务
MSE = (1/n) * Σ(y_true - y_pred)²
- 应用:回归问题
- 特点:对异常值敏感
交叉熵损失 - 分类任务
Cross-Entropy = -Σy_true * log(y_pred)
- 应用:多分类问题
- 特点:衡量概率分布的差异
二元交叉熵 - 二分类任务
Binary Cross-Entropy = -[y*log(ŷ) + (1-y)*log(1-ŷ)]
- 应用:二分类问题
- 特点:适合概率输出
面试技巧:
回答时可以这样组织:
1. 定义:衡量预测值与真实值差距的函数
2. 作用:指导模型优化方向
3. 举例:MSE(回归)、交叉熵(分类)
4. 说明应用场景
五、Transformer架构
问题16:什么是词嵌入?
标准回答:
"深度学习"] --> B[分词
----------------------^ Expecting 'SQE', 'DOUBLECIRCLEEND', 'PE', '-)', 'STADIUMEND', 'SUBROUTINEEND', 'PIPE', 'CYLINDEREND', 'DIAMOND_STOP', 'TAGEND', 'TRAPEND', 'INVTRAPEND', 'UNICODE_TEXT', 'TEXT', 'TAGSTART', got 'STR'
详细说明:
1. 定义
- 词嵌入是将词语转换为稠密向量的技术
- 每个词对应一个固定长度的实数向量
2. 为什么需要词嵌入?
- 计算机只能处理数字:文本需要转换为数值
- 保留语义信息:相似词语的向量距离近
- 降低维度:相比One-Hot编码,维度更低
3. 常见词嵌入方法
| 方法 | 特点 | 应用 |
|---|---|---|
| Word2Vec | 预训练词向量 | 传统NLP |
| GloVe | 全局词共现统计 | 传统NLP |
| BERT Embedding | 上下文相关 | 现代NLP |
| Transformer Embedding | 可学习、上下文相关 | 大模型 |
4. 词嵌入的优势
- 语义相似性:相似词语的向量距离近
- 类比关系:向量运算可以表示语义关系
- 例如:
King - Man + Woman ≈ Queen
- 例如:
- 降维:从词汇表大小降到几百维
面试技巧:
回答时可以这样组织:
1. 定义:将词语转换为稠密向量
2. 为什么需要:计算机只能处理数字、保留语义信息
3. 常见方法:Word2Vec、BERT Embedding
4. 优势:语义相似性、类比关系、降维
问题17:Transformer的全称是什么?它主要分成哪两部分,分工是什么?
标准回答:
详细说明:
1. Transformer全称
- 全称:Attention Is All You Need
- 论文:2017年Google发表的论文
- 创新:完全基于注意力机制,无需RNN/CNN
2. 两大部分
Encoder(编码器)
- 功能:理解输入序列,提取特征
- 特点:双向注意力,可以看到完整输入
- 应用:BERT、文本分类、命名实体识别
Decoder(解码器)
- 功能:生成输出序列,预测下一个token
- 特点:单向注意力,只能看到之前的内容
- 应用:GPT、文本生成、机器翻译
3. 工作流程
输入序列 → Encoder → 语义表示 → Decoder → 输出序列
面试技巧:
回答时可以这样组织:
1. 全称:Attention Is All You Need
2. 两部分:Encoder(编码器)、Decoder(解码器)
3. 分工:
- Encoder:理解输入,提取特征,双向注意力
- Decoder:生成输出,预测下一个token,单向注意力
4. 应用:BERT(Encoder-only)、GPT(Decoder-only)
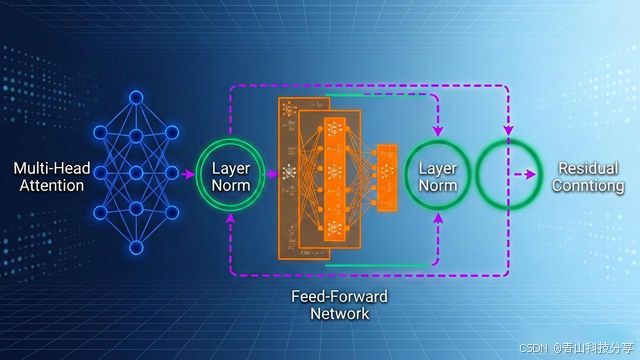
问题18:说出你印象深刻的组件,思考它解决什么问题?能不能从架构删去它呢?
标准回答:
我印象最深刻的组件是:残差连接
F(X)] B --> C[残差连 -----------------------^ Expecting 'SQE', 'DOUBLECIRCLEEND', 'PE', '-)', 'STADIUMEND', 'SUBROUTINEEND', 'PIPE', 'CYLINDEREND', 'DIAMOND_STOP', 'TAGEND', 'TRAPEND', 'INVTRAPEND', 'UNICODE_TEXT', 'TEXT', 'TAGSTART', got 'PS'
详细说明:
1. 残差连接解决什么问题?
问题:梯度消失
- 深层网络训练困难
- 梯度在反向传播过程中逐渐消失
- 导致深层网络难以训练
解决方案:残差连接
# 普通连接
output = F(x)
# 残差连接
output = x + F(x)
原理:
- 梯度可以直接通过残差连接传递
- 即使F(x)的梯度很小,梯度仍可通过x传递
- 缓解梯度消失问题
2. 能不能删去残差连接?
答案:不能!
原因:
- 梯度消失:删去后,深层网络无法训练
- 性能下降:实验证明,删去残差连接后性能大幅下降
- 深度限制:没有残差连接,网络深度受限(通常不超过20层)
实验证明:
- ResNet-50(有残差):准确率76%
- PlainNet-50(无残差):准确率仅60%
面试技巧:
回答时可以这样组织:
1. 选择一个组件:残差连接
2. 解决问题:梯度消失、深层网络训练困难
3. 能否删去:不能,会导致性能大幅下降
4. 实验证明:ResNet vs PlainNet的性能对比
问题19:你如何理解注意力机制?
标准回答:
通俗解释:
注意力机制就是"找重点"。
具体来说:
1. 核心思想
- 在处理序列时,不同位置的重要性不同
- 注意力机制让模型关注重要的位置
- 就像人看图时,会关注重点区域
2. 三要素
Query(查询)
- “我要找什么”
- 例如:翻译时,当前要翻译的词
Key(键)
- “我是什么”
- 例如:源语言中的每个词
Value(值)
- “我的内容是什么”
- 例如:源语言中每个词的语义信息
3. 计算过程
# 1. 计算注意力分数
scores = Q · K^T / √d_k
# 2. Softmax归一化
attention_weights = softmax(scores)
# 3. 加权求和
output = attention_weights · V
4. 为什么有效?
- 动态权重:根据输入动态计算权重
- 长距离依赖:直接连接任意距离的位置
- 并行计算:所有位置同时计算
面试技巧:
用自己的话表述:
1. 通俗解释:注意力机制就是"找重点"
2. 三要素:Query(查询)、Key(键)、Value(值)
3. 计算过程:计算分数→归一化→加权求和
4. 为什么有效:动态权重、长距离依赖、并行计算
六、大模型微调
问题20:微调解决什么问题?LoRA微调跟传统微调的区别是什么?
标准回答:
详细说明:
20.1 微调解决什么问题?
问题:预训练模型的局限性
- 专业性不足:预训练模型是通用的,缺乏领域知识
- 任务不匹配:预训练任务与实际任务不一致
- 输出不规范:输出格式不符合业务需求
解决方案:微调
- 在特定领域数据上继续训练
- 让模型适应特定任务
- 提高模型在特定任务上的性能
20.2 LoRA微调 vs 传统微调
| 特性 | 传统微调 | LoRA微调 |
|---|---|---|
| 参数更新 | 更新所有参数 | 只更新低秩矩阵 |
| 参数量 | 100% | 0.1-1% |
| 显存占用 | 大(16GB+) | 小(4-8GB) |
| 训练速度 | 慢 | 快 |
| 切换成本 | 高(需要重新加载模型) | 低(只切换LoRA权重) |
| 性能 | 最高 | 接近传统微调 |
LoRA核心原理:
# 传统微调
W' = W + ΔW # 更新所有参数
# LoRA微调
W' = W + BA # 只更新低秩矩阵B和A
# B: d×r, A: r×d, r << d
面试技巧:
回答时可以这样组织:
1. 微调解决的问题:预训练模型专业性不足、任务不匹配
2. LoRA vs 传统微调:参数量、显存、速度、切换成本
3. LoRA原理:低秩矩阵分解,只更新少量参数
问题21:LoRA微调的优势在哪?为什么可以使用低秩矩阵来实现微调?
标准回答:
21.1 LoRA微调的优势
详细说明:
1. 参数高效
- 参数量减少90%以上
- 例如:7B模型 → 只需训练58M参数
2. 显存友好
- 显存占用降低4倍
- 可以在消费级显卡上训练
3. 训练快速
- 训练速度快,迭代周期短
- 适合快速原型验证
4. 灵活切换
- 可以为不同任务训练不同的LoRA权重
- 切换时只需加载不同的LoRA权重
21.2 为什么可以使用低秩矩阵?
理论依据:
1. 低秩假设
- 预训练模型的权重更新矩阵ΔW具有低秩特性
- 即ΔW可以用两个小矩阵的乘积近似
2. 内在维度理论
- 模型适应新任务所需的参数维度远小于原始维度
- 权重更新可以在低维子空间中完成
3. 数学证明
# 原始参数
参数量 = d × d = d²
# LoRA参数
参数量 = d × r + r × d = 2dr
# 当 r << d 时
2dr << d²
# 例如:d=4096, r=8
原始参数:4096² = 16,777,216
LoRA参数:4096×8×2 = 65,536
减少比例:99.6%
面试技巧:
回答时可以这样组织:
1. LoRA优势:参数高效、显存友好、训练快速、灵活切换
2. 为什么可以用低秩矩阵:
- 低秩假设:权重更新矩阵具有低秩特性
- 内在维度理论:适应新任务所需维度远小于原始维度
- 数学证明:参数量从d²减少到2dr
问题22:LLaMA Factory 是什么?
标准回答:
详细说明:
1. 定义
- LLaMA Factory是一个开源的大模型微调框架
- 提供一站式的大模型训练、微调、评估解决方案
2. 核心特点
支持多种模型
- LLaMA系列、Qwen、ChatGLM、Baichuan等主流模型
支持多种微调方法
- LoRA、QLoRA、全量微调、Prefix Tuning等
易用性
- WebUI界面:可视化操作,无需编程
- 命令行工具:脚本化训练,适合批量任务
功能完整
- 数据处理、模型训练、效果评估、模型导出
3. 使用场景
- 快速微调大模型
- 对比不同微调方法
- 批量训练多个模型
面试技巧:
回答时可以这样组织:
1. 定义:开源的大模型微调框架
2. 特点:支持多种模型、多种微调方法、易用性强
3. 使用场景:快速微调、方法对比、批量训练
问题23:微调的数据集长什么样子?
标准回答:
详细说明:
1. 数据格式
JSON格式
{
"instruction": "请根据以下要求生成一道题目",
"input": "年级:高一\n科目:数学\n知识点:二次函数",
"output": "已知二次函数f(x) = x² - 4x + 3,求f(x)的最小值。"
}
JSONL格式(推荐)
{"instruction": "请根据以下要求生成一道题目", "input": "年级:高一\n科目:数学\n知识点:二次函数", "output": "已知二次函数f(x) = x² - 4x + 3,求f(x)的最小值。"}
{"instruction": "请判断以下题目的质量", "input": "题目:1+1=?", "output": "题目质量较差,建议增加难度和知识点考查。"}
2. 数据要求
质量要求
- 数据准确:内容正确无误
- 格式规范:符合模型输入格式
- 多样性:覆盖各种场景
数量要求
- 简单任务:100-1000条
- 中等任务:1000-10000条
- 复杂任务:10000+条
3. 数据示例
教育题目生成
{
"instruction": "你是一位专业的教育出题专家。请根据以下要求生成一道高质量题目。",
"input": "年级:高一\n科目:数学\n题型:选择题\n难度:中等\n知识点:二次函数的最值问题",
"output": "题干:已知二次函数f(x) = x² - 4x + 3,求f(x)的最小值。\n选项:A. -1 B. 0 C. 1 D. 3\n答案:A\n解析:将二次函数配方:f(x) = (x-2)² - 1,当x=2时取得最小值-1。"
}
面试技巧:
回答时可以这样组织:
1. 数据格式:JSON或JSONL格式
2. 包含字段:instruction(指令)、input(输入)、output(输出)
3. 数据要求:质量准确、格式规范、数量充足
4. 举一个具体例子
问题24:参考案例中训练集和验证集划分大概比例是多少?
标准回答:
详细说明:
1. 常见划分比例
小数据集(<10000条)
- 训练集:60%
- 验证集:20%
- 测试集:20%
- 原因:数据少,需要更多数据验证
中等数据集(10000-100000条)
- 训练集:80%
- 验证集:10%
- 测试集:10%
- 原因:平衡训练和验证
大数据集(>100000条)
- 训练集:98%
- 验证集:1%
- 测试集:1%
- 原因:数据充足,少量数据即可验证
2. 微调场景的划分
LoRA微调
- 训练集:90%
- 验证集:10%
- 原因:数据量通常较少
QLoRA微调
- 训练集:90%
- 验证集:10%
- 原因:数据量通常较少
3. 实际案例
E教千问项目
- 总数据:5000条
- 训练集:4500条(90%)
- 验证集:500条(10%)
LLaMA Factory默认
- 训练集:90%
- 验证集:10%
面试技巧:
回答时可以这样组织:
1. 常见比例:小数据60/20/20,中等数据80/10/10,大数据98/1/1
2. 微调场景:通常90%训练,10%验证
3. 实际案例:E教千问项目90/10划分
七、面试技巧总结
7.1 回答结构化
回答模板:
1. 先说结论:直接回答问题
2. 再解释原因:说明原理和机制
3. 举例说明:结合实际案例
4. 总结升华:说明应用场景或优势
7.2 常见问题应对
| 问题类型 | 应对策略 | 示例 |
|---|---|---|
| 概念题 | 定义+特点+应用 | 什么是神经网络? |
| 原理题 | 原理+过程+优势 | 反向传播原理? |
| 对比题 | 对比维度+表格 | LoRA vs 传统微调? |
| 应用题 | 场景+方案+效果 | 如何解决过拟合? |
7.3 面试注意事项
1. 回答技巧
- ✅ 先说结论,再展开
- ✅ 用自己的话表述,不要背诵
- ✅ 结合项目经验
- ✅ 举具体例子
2. 避免的问题
- ❌ 回答过于简单(只说定义)
- ❌ 回答过于复杂(偏离主题)
- ❌ 没有实际经验支撑
- ❌ 不能举例说明
3. 加分项
- ✅ 结合最新技术发展
- ✅ 提到实际项目经验
- ✅ 能够深入浅出
- ✅ 有自己的理解
八、总结
8.1 知识点回顾
8.2 面试准备清单
基础知识:
- 机器学习三大方式
- 常见算法和评价指标
- 神经网络基本结构
- 激活函数和损失函数
深度学习:
- 前向传播和反向传播
- 正则化和优化方法
- 经典网络架构
- Transformer原理
大模型:
- 词嵌入和注意力机制
- LoRA微调原理
- 数据集格式
- 实际项目经验
8.3 学习建议
理论学习:
- 理解基本概念和原理
- 掌握核心算法和模型
- 了解最新技术发展
实践积累:
- 动手实现经典模型
- 参与实际项目
- 积累项目经验
面试准备:
- 整理知识点
- 准备项目案例
- 练习表达能力
祝你面试成功!加油!🚀

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 14
14 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)