PI系列最新工作-RL Token: Bootstrapping Online RL with Vision-Language-Action Models
原文发表在知乎,格式可能更规正一下,可以参考:《PI系列最新工作-RL Token: Bootstrapping Online RL with Vision-Language-Action Models》
官方博客:《Precise Manipulation with Efficient Online RL》。3.19号physical intelligence发表了一个在线强化学习来提升效果的方案。其实PI在以前发表过一篇pistar0.6的工作,也是用强化学习提升效果的,它们有什么不同呢?
1,pistar0.6简单的来讲是一种"准"在线强化学习方案,它通过多轮的数据收集,通过离线的方式进行训练来模拟一种在线的效果,并且它训练的是整个VLA模型,所以对数据量的要求还是挺高的。
2,本篇文章的工作更像一种"外挂",它不对VLA本身进行更新,而是外挂了一个critic/actor小模型,通过几分钟或几个小时量级的数据就可以解决某个具体的任务。关于外挂方案,多说一句,前期笔者研究过的字节跳动的gr-rl也是一种有意思的方案,它对flow matching中的初始noise进行外挂式优化,其它VLA部分也是冻结的。
关于本篇工作,有网友已经有不错的解析与分享:
1,Pi RLT 的主要思想
2,聊聊 RL Token:给 VLA 模型装上强化学习的小引擎
言归正传, 在此也讲一下笔者对本篇工作的理解:
解决的问题:
假设我们已经有一个pi0.6的基础VLA模型,已经在某个具体的任务之上做了ft,整体效果也还可以,但在某些困难的地方(例如精度要求较高的片段)效率很低,精度不满足需要。最直接的办法是把pi0.6在强化学习的环境上进行后训练,让其在实践中纠错与成长。目标很明确,但路径可能有些难:
Training the entire VLA with online RL could be too compute- and sample-inefficient to produce an improved policy in just a few hours. 可选的方案例如pistar0.6这种"准"在线强化学习方案,需要较多的数据与训练资源。或者用piRL方案,用ppo来进行on policy的强化学习,但这个方案面临同样的数据与资源的问题,且需求更多。具体来讲:
1,大模型在小数据量场景下易过拟合
在线 RL 微调时,真实机器人交互数据非常有限(论文中只有几小时、几百到上千个 episode)。对于一个大模型(如π0.6有数十亿参数),这些数据量相对于模型容量来说极小。大模型训练时,梯度信号需要穿过数十亿参数,信噪比低;你收集到的一条轨迹(sample),大模型用它更新后,policy 的变化可能很小或不稳定;而小网络可以用同样的样本更新多次(高 update-to-data ratio),快速收敛,从而榨干每个样本的价值。
2,计算效率低
这个不用多说,训练时,假如使用消费级显卡,更新一个几百万参数的小模型可能每秒都更新几十次,但对于一个几十亿参数的大模型,可能每秒只能更新0.x次,几十倍的计算效率差别。
方案:
笔者前期基于hil-serl作过两个实验,从零开始进行强化学习训练,在2小时内就可以学习到一个不错的效果。在这些背景下,若解决某个具体的场景问题,就可以用”小模型外挂“的方式来提升样本效率,降低计算资源需求。本篇工作的方案主要分为两个阶段:
一,RL token的生成:
架构图: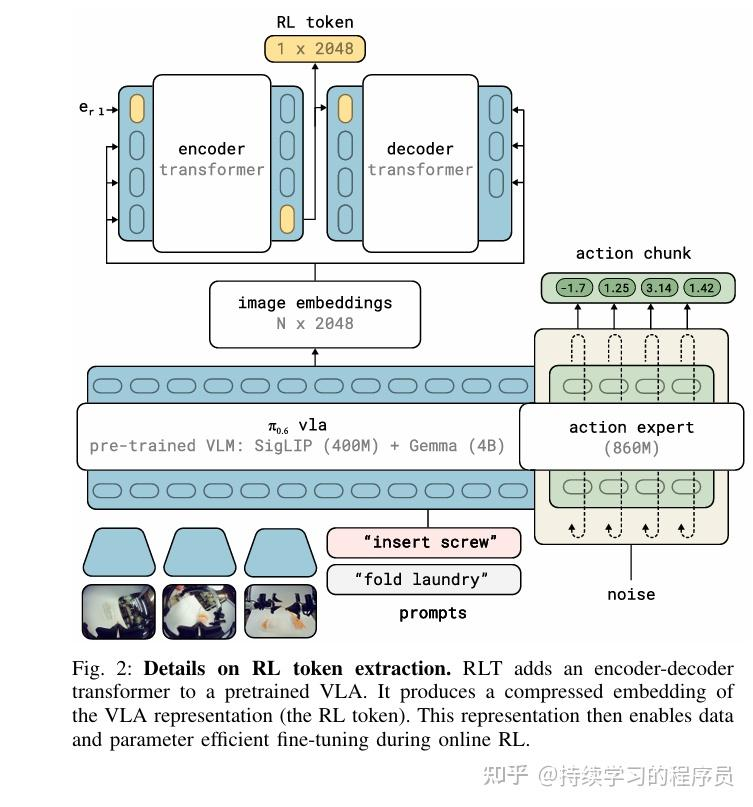
RL token是一个对任务信息的精炼浓缩,它可以作为强化学习中的state输入,当然也可以选择resnet等传统的方案,但效果会差一些,下面会有一个数据说明。
在基础的VLA模型之上添加一个encoder-decoder模块,这个模块目标是产出一个RL token给到强化学习来使用。encoder将VLA产出的 embeddings编码成一个token,decoder使用自回归的方式,将此token解码恢复成原始的embeddings信息。监督信息就是恢复前后的diff。这个过程有点像生成式模型中,会将图像编码成一个隐空间内的向量,然后将此向量再恢复成一张图片。
用具体的task数据对此encoder-decoder进行训练后,在后续就保持冻结状态。
RL token自回归训练方法:
对于每个训练样本:
1. 冻结的VLA输出 embeddings: z₁, z₂, ..., z_M
2. Encoder生成RL token: z_rl
3. Decoder逐个重构(自回归):
- 第1步: 输入 [z_rl] → 预测 z̃₁
- 第2步: 输入 [z_rl, z̃₁] → 预测 z̃₂
- 第3步: 输入 [z_rl, z̃₁, z̃₂] → 预测 z̃₃
- ...
- 第i步: 输入 [z_rl, z̃₁, ..., z̃_{i-1}] → 预测 z̃_i
4. 计算MSE损失: Σᵢ ‖z̃ᵢ - zᵢ‖²
5. 反向传播更新encoder和decoder参数
为什么用自回归的方式进行训练:
如果 decoder 可以一次性直接重建整个序列,那么 RL token 就不需要保留“序列结构”信息,而只需保留一个“全局概要”。但通过自回归的方式,decoder 必须逐个 token 地预测后续 token,这就迫使 RL token 不仅要包含全局信息,还要保留序列中每个 token 的上下文关系和顺序依赖。
效果:
replacing the RL token with a ResNet-10 encoder reduces throughput by 50%, confirming that our token encodes manipulation-relevant structure that an off-the-shelf encoder trained on standard computer vision tasks does not provide.
RL token的设计相比传统的ResNet-10可以提升50%的呑吐。
二,在线强化学习: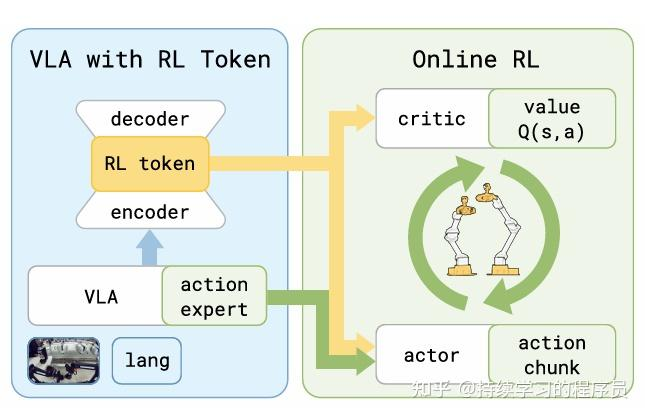
在线强化学习使用的就是td3风格的经典的强化学习pipeline。
critic网络:
输入:
the input state is x = (zrl,sp), and sp denotes the proprioceptive state information, zrl(s) denotes the RL token extracted for state s
训练方法:
用td3算法,就是标准的off-policy时序差分算法
actor网络:
输入:
x跟critic中的x是一样的,
是VLA模型输入的参考action chunk。这个参考action chunk有两层意思:
1,Conditioning on
exposes the actor directly to the VLA’s predicted actions, so that online RL refines a strong initial proposal rather than learning from scratch.
2,A second benefit is that the sampled reference chunk preserves mode information from the VLA’s multimodal action distribution, which would otherwise be difficult for a unimodal Gaussian actor to recover。翻译一下就是这个单峰的(unimodal)的高斯actor很难表达动作的多模态性(multimodal),所以给一个参考action chunk可以保留动作的多模态性。
输出:
输出是一个高斯分布
训练方法:
除了常规的Q loss外,还加了一个使输出动作接近参考动作的约束,也就是中括号后的第二部分。这个loss整体上跟离线强化学习算法中的td3+bc很类似,不过原理存在本质不同。
以上核心算法就讲完了,除此之外有一些细节:
1, 论文中给的算法是一个同步的算法,也就是rollout->train这种顺序执行,但效率低,所以作者说了To remain compute and time-efficient during training, we perform the rollouts and learning asynchronously.最终实现的是一个异步算法,也就是一个进程负责rollout,一个负责train,这两个进程间有rollout数据和训练参数的传递,类似于文章《强化学习Actor/Learner框架介绍(lerobot版) - 知乎》。
2,we pick a stride of 2 and save transitions corresponding to <
,<
, <
,… to the replay buffer。这样做可以大幅提高样本效率:同样的执行时间,能产生 5 倍(若C=10、stride=2)的训练样本。也就是策略仍然在t=0,C,2C,…生成动作块,但 critic 可以利用中间状态进行更密集的更新。
3,For practicality and efficiency of learning, we apply RLT to improve the critical phase of each task we consider– corresponding to the most difficult sections which require high-precision– and let the base VLA perform the easier parts of the task。也就是对于整体任务,有较难的部分片段或精度要求较高的片段,那么可以只用强化学习提升这一段,而较容易的片段仍然交给VLA来进行即可。在训练的时候,可以由人工来选择在某个时间点由哪个模块生成动作:人工,RL actor或VLA。训练完成后,这个数据收集起来后,可以用这个数据训练一个小模型,在推理部署的时候,可以由这个小模型来决定由哪个模块生成动作。
4,for a random subset of transitions in each training batch, we replace the reference chunk with zeros before passing it to the actor. This forces the actor to maintain an independent action-generation pathway, while still allowing it to exploit the VLA action distribution whenever the reference chunk is present。在强化训练时候,VLA产生的参考动作,在50%的机率被设置为零(dropout),这样可以避免RL的actor网络“偷懒”的原样copy参考动作。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)