Nano vLLM推理框架解析(llm_engine篇)
Nano-vLLM 是一个极简版本的 LLM (大型语言模型) 推理引擎。它剔除了工业级框架(如原版 vLLM)中海量的边界情况调试、硬件适配代码和复杂的网络接口组件,而仅用不到 1500 行的纯 Python / PyTorch 代码,硬核实现了高并发推理中的三大“黑魔法”。
核心技术点速览
- Continuous Batching (连续批处理):不再像传统方式那样把长度不同的多个请求死死绑定在一起等最短的生成完,而是实现“随进随出”,谁卡顿了踢走谁,谁新来了就趁机插进来一起算。
- PagedAttention (分页注意力机制):类似于操作系统底层的“分页内存”,因为文本生成的长度是未知的,过去由于必须一次性申请一长段连续显存导致了巨大的内存浪费(碎片化)。这里的解决方案是把显存切成一个个小的“方块(Blocks)”,生成一个切一片,用指针连接,彻底消灭显存碎片。
- Tensor Parallelism (张量并行):通过 Python 多进程以及底层的参数切片,让你能轻松把一个巨大的模型拆开放在多张 GPU 上加速计算。
example.py这个文件是整个nano vllm的入口
import os
from nanovllm import LLM, SamplingParams
from transformers import AutoTokenizer
def main():
# 定义 Hugging Face 模型的本地路径
path = os.path.expanduser("~/huggingface/Qwen3-0.6B/")
tokenizer = AutoTokenizer.from_pretrained(path)
# 初始化 LLM 引擎,启用 eager 模式(不使用 CUDA graph,便于调试),设置张量并行度为 1 (单卡)
llm = LLM(path, enforce_eager=True, tensor_parallel_size=1)
# 定义生成时的采样参数 (温度设为 0.6,最大生成长度为 256 个 token)
sampling_params = SamplingParams(temperature=0.6, max_tokens=256)
prompts = [
"introduce yourself",
"list all prime numbers within 100",
]
# 使用模型分词器自带的聊天模板(chat template)对 prompt 进行统一格式化
prompts = [
tokenizer.apply_chat_template(
[{"role": "user", "content": prompt}],
tokenize=False,
add_generation_prompt=True,
)
for prompt in prompts
]
# 调用大模型生成文本
outputs = llm.generate(prompts, sampling_params)
# 打印每个 prompt 及其对应的模型输出结果
for prompt, output in zip(prompts, outputs):
print("\n")
print(f"Prompt: {prompt!r}")
print(f"Completion: {output['text']!r}")
if __name__ == "__main__":
main()
当在运行 example.py 里的 llm.generate() 时,会进行以下几个流程:
- 大脑中枢(nanovllm/engine/llm_engine.py) 引擎启动时,它根据 Tensor Parallel 数量,开辟了若干个后台子进程(ModelRunner),随时准备在多卡上并行跑模型。
当调用 generate 时,把你的字符串提示词(Prompt)交给分词器转换成 ID,封装成一个排队的请求对象(Sequence),丢给调度器。 - 请求的载体(nanovllm/engine/sequence.py) 一个 Sequence 的一生就是一次对话生成。
它内部维护着 WAITING(排队中) -> RUNNING(计算中) -> FINISHED(生成完毕) 的状态变化。并且记录了自己当前被分配到了哪些物理内存块指针。 - 内存管理大师(nanovllm/engine/block_manager.py) 不再有连续的巨大显存,有的是一个个容量为 256 tokens(由 kvcache_block_size 决定)的 Block 方块。
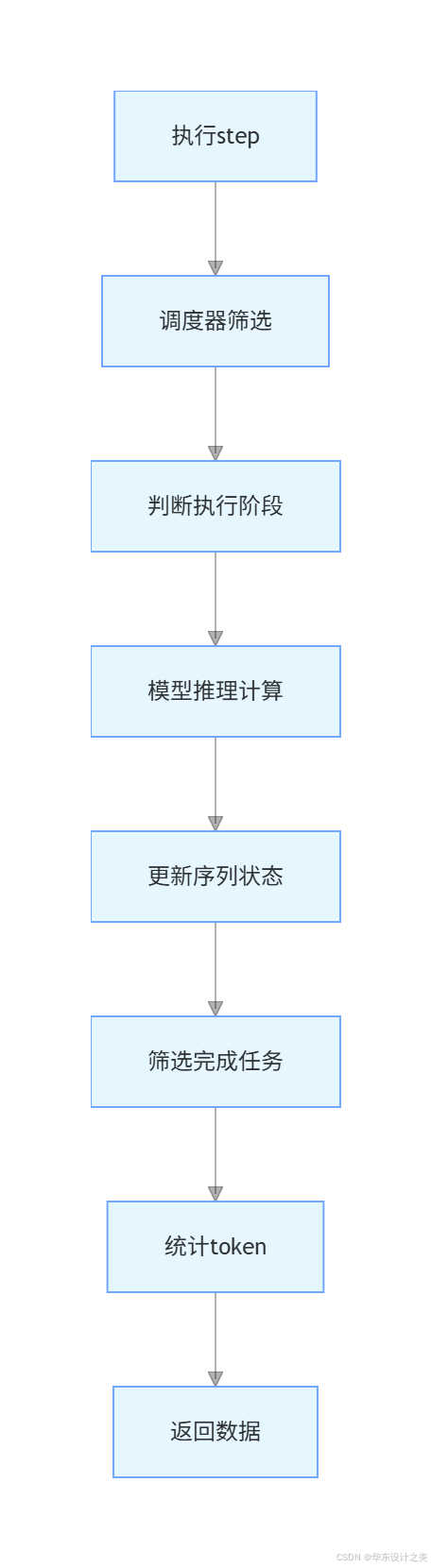
BlockManager 是大内总管,它决定什么时候在系统中寻找一块空闲 free_block 给模型写新生成的词,而且支持 Prefix Caching(前缀重用):如果两个请求提了类似的问题,它会通过 Hash 识别出相同,直接用同一个内存块,节省资源。 - 发号施令的管家(nanovllm/engine/scheduler.py) 这是逻辑最精妙的地方所在。引擎每一“步(step)”都会呼叫它。
它负责决定:当前时刻,有这么多排队的新请求、生成到一半的老请求,到底谁可以进入 GPU 进行正向传播计算?
它的原则: 新请求只要带进来不会因为 Prompt 太长导致 GPU 显存溢出,就优先插队去计算首尾(这叫做 Prefill 阶段)。如果暂时没有新请求,就推着目前已经在 GPU 里的老请求们再往前走一步,逐字吐出一个 Token(这叫做 Decode 阶段)。在这个过程中如果某个请求因为变长申请不到物理块了,调度器会无情地把它 抢占(Preempt) 踢回排队池。
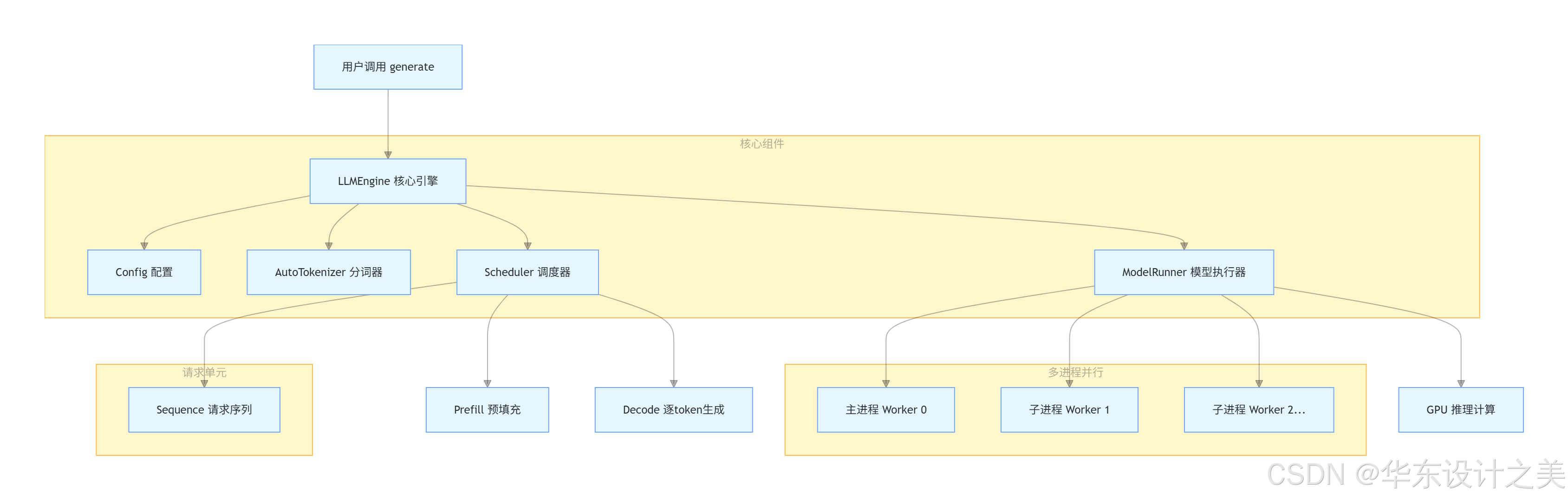
1.llm_engine.py
LLMEngine 是 nano-vllm 的最核心大脑,对外提供生成接口,对内管理多进程(张量并行)、模型执行、调度器、分词器,是连接用户请求和模型推理的中间层。
import atexit # 程序退出时自动执行清理函数(优雅关停)
from dataclasses import fields # 解析数据类字段(提取配置参数)
from time import perf_counter # 高精度计时器(计算推理吞吐量)
from tqdm.auto import tqdm # 命令行进度条
from transformers import AutoTokenizer # HuggingFace 分词器(文本转Token)
import torch.multiprocessing as mp # PyTorch 多进程(实现张量并行)
# nano-vllm 自定义核心模块
from nanovllm.config import Config # 引擎配置类(模型、并行数等)
from nanovllm.sampling_params import SamplingParams # 采样参数(温度、TopK、最大长度等)
from nanovllm.engine.sequence import Sequence # 序列类(封装单个用户的生成请求)
from nanovllm.engine.scheduler import Scheduler # 调度器(vllm核心:批处理、调度任务)
from nanovllm.engine.model_runner import ModelRunner # 模型执行器(真正跑模型推理)engine核心片段generate
需要注意关于下述代码使用方法
config_kwargs = {k: v for k, v in kwargs.items() if k in config_fields}
# 等价于
# 初始化空字典
config_kwargs = {}
# 遍历kwargs的所有键值对
for k, v in kwargs.items():
# 筛选:键在指定字段中
if k in config_fields:
# 加入新字典
config_kwargs[k] = v
# 例子
# 1. 定义【允许保留的字段】(列表/集合/元组都可以)
config_fields = ["name", "age", "gender"]
# 2. 模拟【kwargs】(函数接收的关键字参数)
kwargs = {"name": "小明", "age": 18, "city": "北京", "gender": "男", "score": 90}
# 3. 执行筛选代码
config_kwargs = {k: v for k, v in kwargs.items() if k in config_fields}
# 4. 输出结果
print(config_kwargs)
# 运行结果
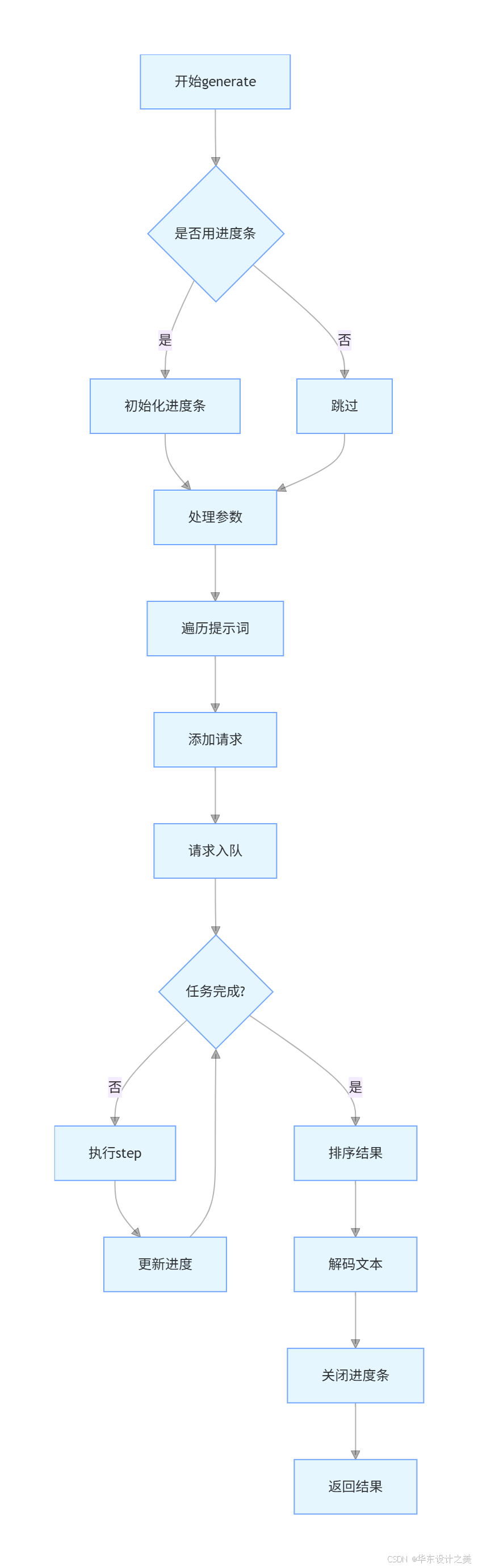
{'name': '小明', 'age': 18, 'gender': '男'} def generate(
self,
prompts: list[str] | list[list[int]],
sampling_params: SamplingParams | list[SamplingParams],
use_tqdm: bool = True,
) -> list[str]:
# 如果启用进度条,初始化tqdm对象,总数为传入提示词的数量
if use_tqdm:
pbar = tqdm(total=len(prompts), desc="Generating", dynamic_ncols=True)
# 如果只传了一个采样参数,就将其变成列表以对应每一个prompt
if not isinstance(sampling_params, list):
sampling_params = [sampling_params] * len(prompts)
# 遍历成对的prompt和采样参数,然后挨个调用add_request把它们推入系统的等待队列
for prompt, sp in zip(prompts, sampling_params):
self.add_request(prompt, sp)
# 准备一个字典存放所有序列的最终生成结果
outputs = {}
# 预填充阶段和解码阶段的吞吐量统计初始值设为0
prefill_throughput = decode_throughput = 0.
# 主循环:只要系统里还有任务没处理完,就不断地执行step()
while not self.is_finished():
# 记录执行前的时间点
t = perf_counter()
# 执行一步计算
output, num_tokens = self.step()
# 如果启用了进度条,则动态计算吞吐量速度
if use_tqdm:
if num_tokens > 0:
# token统计>0代表此时正在批量计算Prefill,用处理的token量除以消耗的时间
prefill_throughput = num_tokens / (perf_counter() - t)
else:
# token统计<0代表是Decode阶段,取绝对值除以消耗的时间
decode_throughput = -num_tokens / (perf_counter() - t)
# 更新进度条后面的速度显示信息
pbar.set_postfix({
"Prefill": f"{int(prefill_throughput)}tok/s",
"Decode": f"{int(decode_throughput)}tok/s",
})
# 遍历刚才执行这一步所产生并完成的所有结果
for seq_id, token_ids in output:
# 存入到字典中,以序列所属的ID为键
outputs[seq_id] = token_ids
# 每完成一个请求,让主界面的进度条前进1步
if use_tqdm:
pbar.update(1)
# 当一切结束后,将字典中的结果拿出来,并按输入时的请求先后顺序(seq_id)进行排序
outputs = [outputs[seq_id] for seq_id in sorted(outputs.keys())]
# 用分词器把一长串数字的token_ids重新解码成人类可读的文字文本,加上原来的token_ids组合成最终返回的格式
outputs = [{"text": self.tokenizer.decode(token_ids), "token_ids": token_ids} for token_ids in outputs]
# 完成后关闭进度条
if use_tqdm:
pbar.close()
# 返回最终的结果列表给调用者
return outputstqdm 是 Python 生态中最主流、最轻量的命令行进度条库,核心作用是给耗时任务添加可视化的进度条,效果如下:
Generating: 50%|█████▏ | 5/10 [00:02<00:02, 2.1it/s, Prefill=1024tok/s, Decode=512tok/s]而上述engine过程涉及调度,推理,多进程,模型等多个方面,对外给用户提供极简的生成接口,对内管理所有底层组件。
多 GPU 进程管理、请求排队、模型推理、进度监控、结果转换
通过init初始化配置,并通过exit完善,add_request 接收请求(完成用户提示词到殷勤内部标准数据转换的过程),通过step完成单步推理(每次生成一个token,调度器派单,执行器推理,并更新状态进行速算),通过is_finished 判断任务完成,generate 对外接口(完成用户输入调用)。
我们用用户输入一句提示词,模拟引擎全流程:
- 用户调用:
engine.generate("你好")- 翻译:分词器把「你好」转成 token
[123, 456]- 封装:创建
Sequence包裹,交给调度器排队- 调度:调度执行选中这个订单,进入
Prefill阶段- 模型推理:多进程任务执行模型计算,处理提示词
- 循环生成:进入
Decode阶段,每次生成 1 个 token- 完成:生成到结束符,停止推理
- 翻译回文字:token 转成人类可读的文本
- 返回结果:给用户返回生成的文本
整体流程:
generate执行流程:
step单步推理流程:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)