我用Claude Code做了一个TTS的文本转语音工作台(免费、已开源)(Claude Code保姆级图文配置+使用教程+中转站)(MiMo-V2-TTS教程)
我用Claude Code做了一个TTS的文本转语音工作台(免费、已开源)(Claude Code保姆级图文配置+使用教程+中转站)(MiMo-V2-TTS教程)
先给大伙看看AI做的页面长什么模样
项目地址(已开源): My-TTS
本项目需要python环境,安装好python后,点击start.bat,再通过浏览器打开localhost:5000即可使用
模型使用的是小米限时免费的
mimo-v2-tts模型,去Xiaomi MiMo 开放平台申请一个API Keys就行了,完全免费从开始开发到项目完成共计两小时,只能感慨AI的发展真的太快了
使用这个项目的时候注意事项:生成的音频文件在该项目的目录下,生成后不用的需要手动清理一下~
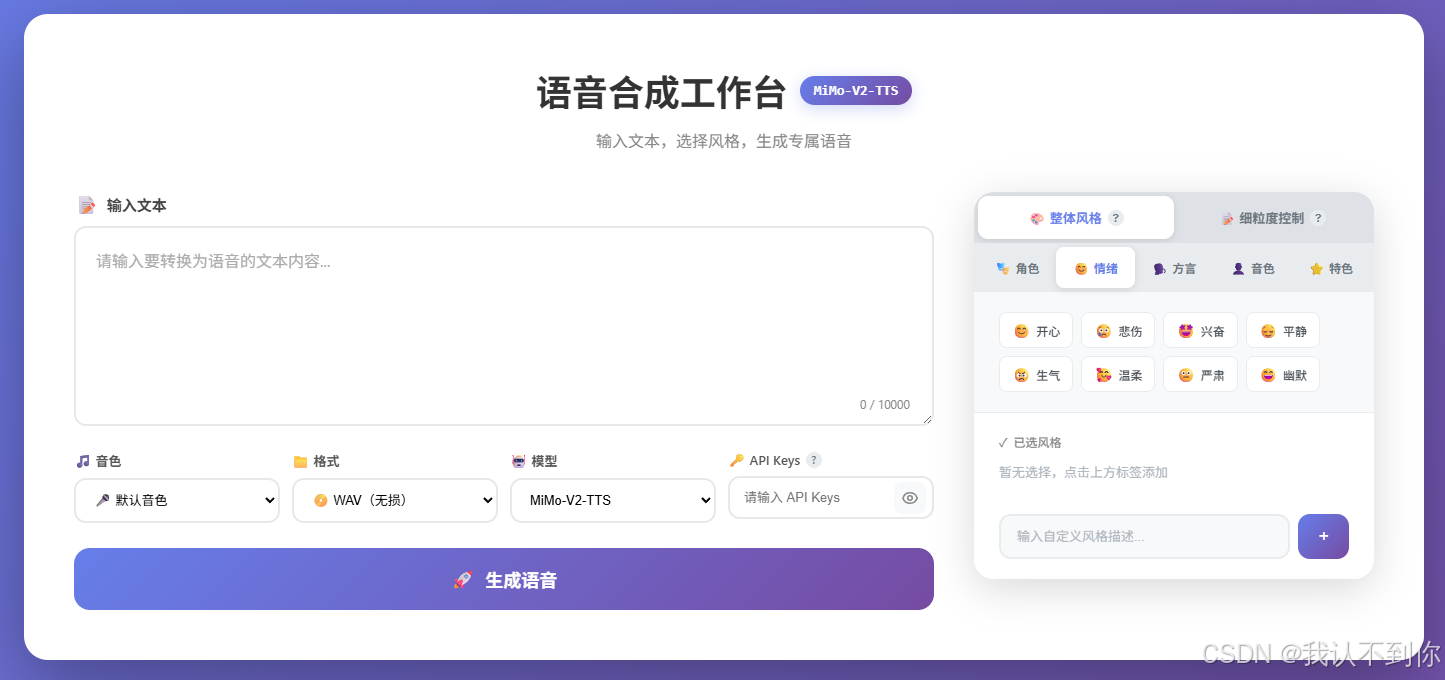
Claude Code 的使用
Claude Code 是一个代理编码工具,可以读取你的代码库、编辑文件、运行命令,并与你的开发工具集成。可在终端、IDE、桌面应用和浏览器中使用。
Claude Code 是一个由 AI 驱动的编码助手,可以帮助你构建功能、修复错误和自动化开发任务。它理解你的整个代码库,可以跨多个文件和工具工作以完成任务。
Claude Code 官方文档:Claude Code overview - Claude Code Docs
Claude Code 是一个通过大预言模型调用CLI(命令行界面)的AI工具,可以自定义大预言模型,但截止26年3月22日,最优秀的编码类模型是gpt-5.3-codex(OpenAI的产品Codex),其次就是claude-opus 4.6和claude-sonnet 4.6(Anthropic的产品Claude Code)
我是用的是claude-sonnet 4.6的模型,配置了一个中转站(里面也有claude-opus 4.6、GTP-5.4和gpt-5.3-codex的模型),20人民币 = 200美刀/月,有需要的朋友可以找我(我只提供渠道,这个中转站不是我维护的)
一、安装方式
# 1. 确保Node.js已安装(v18+)
node --version
# 2. 安装Claude Code
npm install -g @anthropic-ai/claude-code
# 3. 验证安装
claude --version
# 可以先不忙启动 claude 我们先配置一下中转站再启动
# 4. 启动并认证
claude
二、配置第三方中转站的两种方式
1、通过命令行改配置文件实现
实现逻辑就是通过修改~/.claude.json文件实现
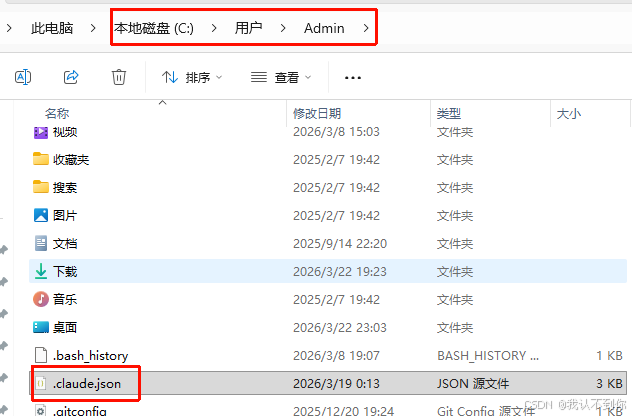
windows:打开CMD窗口输入回车即可
powershell -c "$p=Join-Path $env:USERPROFILE '.claude.json';$j=@{env=@{ANTHROPIC_BASE_URL='中转站地址';ANTHROPIC_AUTH_TOKEN='中转站API Key'};hasCompletedOnboarding=$true}|ConvertTo-Json -Depth 3;[IO.File]::WriteAllText($p,$j,[Text.Encoding]::UTF8);Write-Host 'Claude Code configured!'"
linux、macOS:我没有mac系统,这里只做参考
cat <<'EOF' > ~/.claude.json && echo "Claude Code configured!"
{"env":{"ANTHROPIC_BASE_URL":"http://39.96.215.72:64597","ANTHROPIC_AUTH_TOKEN":"sk-55eefa3f-afad-41a9-a8bd-2003cd73c998"},"hasCompletedOnboarding":true}
EOF
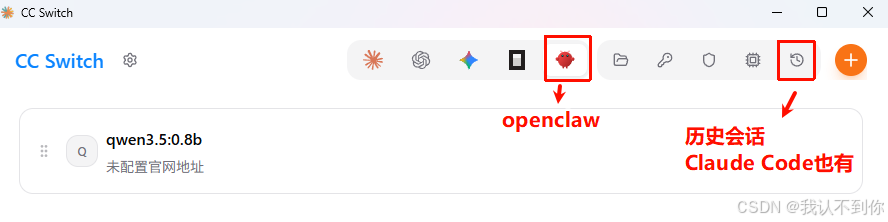
2、通过CC Switch实现配置(可视化)
CC Switch 是一个 Claude Code / Codex / Gemini CLI / Openclaw 的全方位辅助工具。
CC Switch 可以帮我们轻松管理这几个热门工具的 API 配置,就好比给你的开发工具箱来了个智能整理助手,所有工具的配置都能在它这有序管理。
去github下载安装即可:Release CC Switch v3.12.2 · farion1231/cc-switch
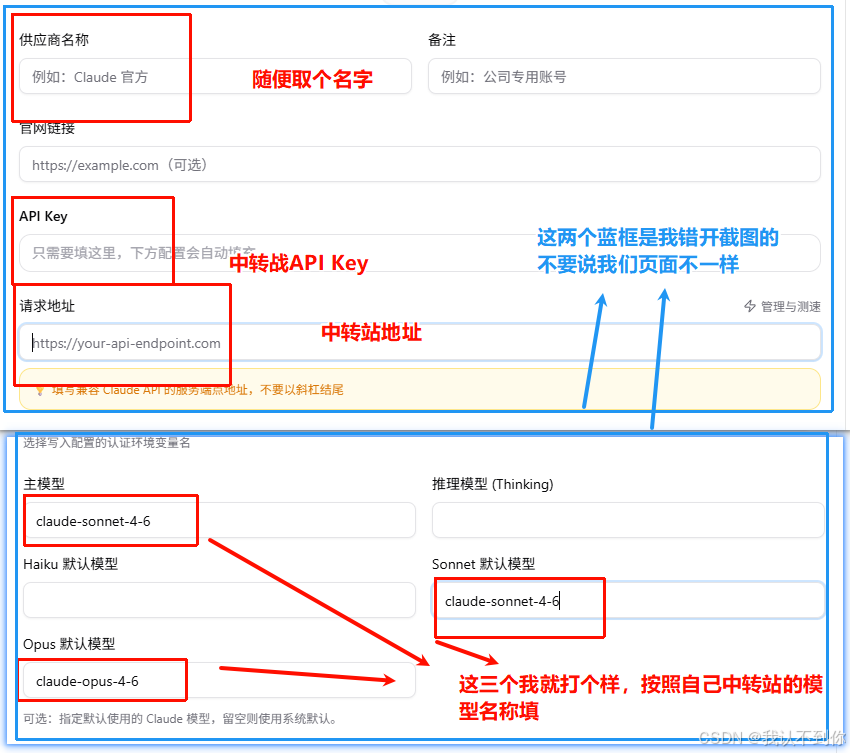
我们选择msi和zip都行,下载好后运行,添加供应商
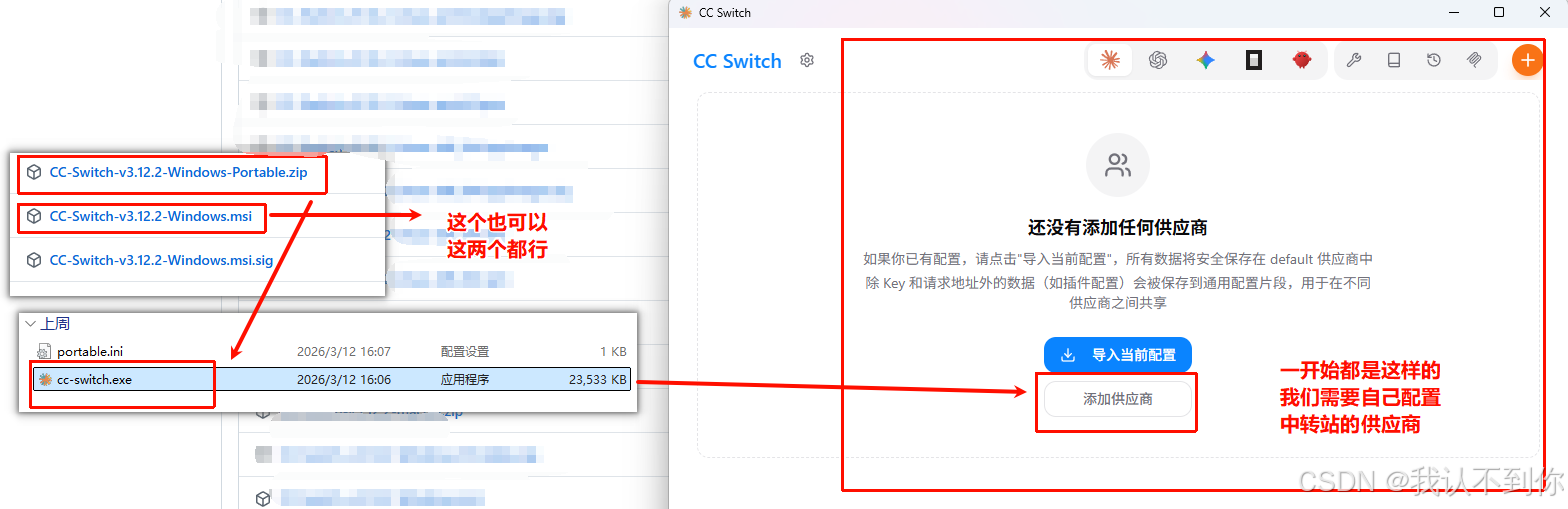
添加一下供应商
点击测试看看是否可以运行
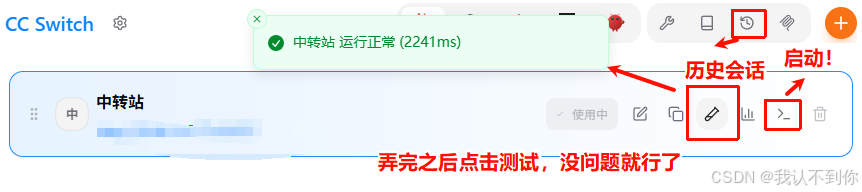
ps:还有一些其他的功能自己可以去玩玩(后续会出openclaw+飞书的教程,可以先关注一下主播,一直做开源教程也实属不易,写博客是没有收益的,但大家的关注和点赞可以给主播一点成就和动力,先感谢大家了(0^0))
三、Claude Code 使用
Claude Code 使用文档:交互模式 - Claude Code Docs
在cmd通过claude命令,或者CC switch 中运行即可打开 Claude Code 的 CLI 工作台
这里最重要的就是Alt+M切换切换权限模式,这里有三个权限模式我要重点讲一下
三个权限模式
正常模式(Ask):默认基础模式,随心聊随心操作 一只看不动,只读分析
你可以在这个模式里跟Claude Code随意聊需求、提问题,它会根据你的指令给出对应的回应,比如你让它写一段简单代码、改一个小bug,它都会直接执行;但它不会主动推进任务,也不会自动规划流程,完全跟着你的指令走,你说一步它做一步,适合简单、直接的小需求,比如临时写个小功能、排查个简单的代码问题。
自动接受模式(Edit):自动执行模式,敲定方案后高效干活 一直接执行,可写代码
自动接受代码编辑模式,其实就是说,默认允许Claude Code直接修改代码,不要每次修改什么代码的时候都要反问我们这样改动ok吗?我们允许吗?
这种方式理论上可以说是特别的不安全,相对于权限放开了,实际使用体验来说也挺安全的,因为重要的系统操作命令他还是要咨询我们的
Plan Mode (Plan):专属规划模式,只聊方案不写代码,项目前期超实用 一谋定而后动,先规划后执行
plan模式是专门的规划沟通模式,核心特点就是:只跟你讨论、沟通需求,不会主动执行写代码、改代码这些操作,特别适合项目前期的功能规划、方案设计阶段。
快捷键如下,大家可以使用起来了
| 快捷键 | 描述 | 上下文 |
|---|---|---|
Ctrl+C |
取消当前输入或生成 | 标准中断 |
Ctrl+F |
终止所有后台代理。在 3 秒内按两次以确认 | 后台代理控制 |
Ctrl+D |
退出 Claude Code 会话 | EOF 信号 |
Ctrl+G |
在默认文本编辑器中打开 | 在默认文本编辑器中编辑您的提示或自定义响应 |
Ctrl+L |
清除终端屏幕 | 保留对话历史 |
Ctrl+O |
切换详细输出 | 显示详细的工具使用和执行情况 |
Ctrl+R |
反向搜索命令历史 | 交互式搜索以前的命令 |
Ctrl+V 或 Cmd+V(iTerm2)或 Alt+V(Windows) |
从剪贴板粘贴图像 | 粘贴图像或图像文件的路径 |
Ctrl+B |
后台运行任务 | 后台运行 bash 命令和代理。Tmux 用户按两次 |
Ctrl+T |
切换任务列表 | 在终端状态区域中显示或隐藏任务列表 |
Left/Right arrows |
在对话框选项卡之间循环 | 在权限对话框和菜单中的选项卡之间导航 |
Up/Down arrows |
导航命令历史 | 回忆以前的输入 |
Esc + Esc |
回退或总结 | 将代码和/或对话恢复到上一个点,或从选定的消息进行总结 |
Shift+Tab 或 Alt+M(某些配置) |
切换权限模式 | 在自动接受模式、Plan Mode 和正常模式之间切换。 |
Option+P(macOS)或 Alt+P(Windows/Linux) |
切换模型 | 在不清除提示的情况下切换模型 |
Option+T(macOS)或 Alt+T(Windows/Linux) |
切换扩展思考 | 启用或禁用扩展思考模式。首先运行 /terminal-setup 以启用此快捷键 |
四、测试(这里随便测试一下,因为最好的测试就是我在gitee上开源的TTS项目了)
我们让 Claude Code 给我们在桌面写一个 html 页面,当然测试就不要太简单,写一个模仿WeChat的聊天页面
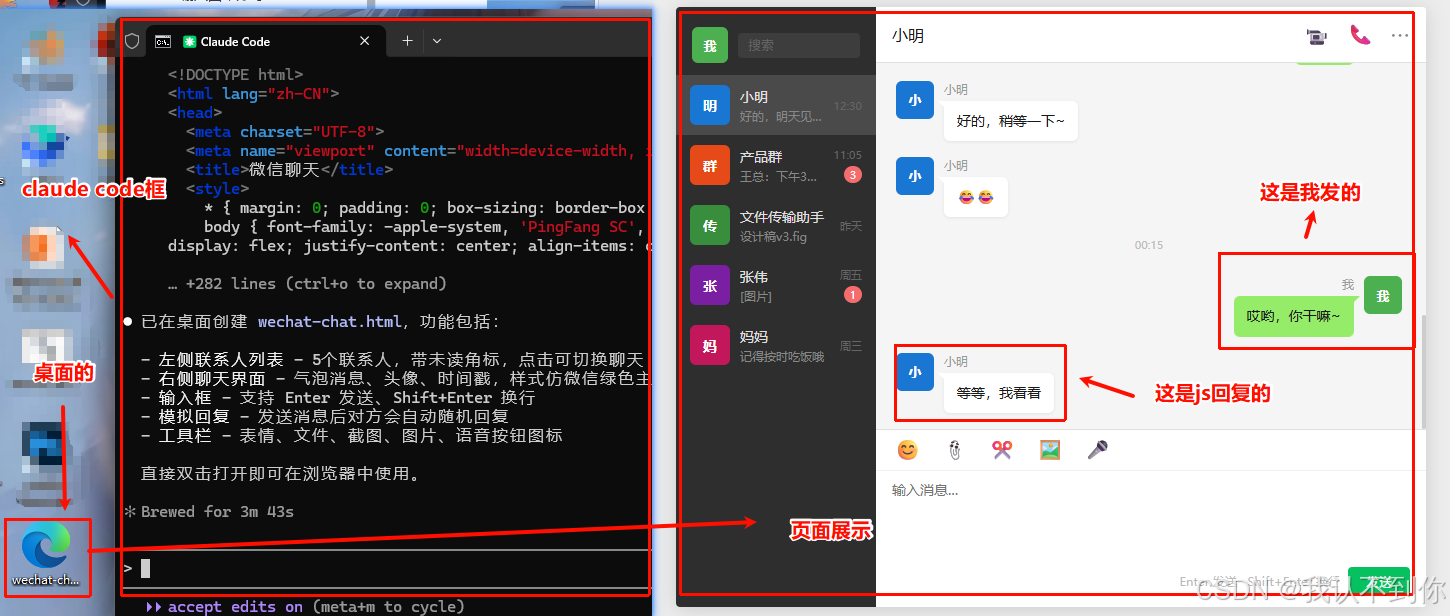
其实回复逻辑就是一个模拟回复的函数,其实真正要做的这样页面和功能不难(对我来说css很难),难的是你能在一分钟之内写完吗
// 模拟回复
setTimeout(() => {
const replies = ['哈哈,好的!', '明白了👍', '等等,我看看', '嗯嗯,收到!', '好的,稍等一下~', '😂😂', '这个问题我也不太清楚…'];
const reply = replies[Math.floor(Math.random() * replies.length)];
const rRow = document.createElement('div');
rRow.className = 'msg-row them';
const name = document.getElementById('chatName').textContent;
const initial = name.charAt(0);
rRow.innerHTML = `
<div class="msg-avatar" style="background:#1976d2">${escapeHtml(initial)}</div>
<div class="msg-content">
<div class="msg-name">${escapeHtml(name)}</div>
<div class="bubble them">${escapeHtml(reply)}</div>
</div>`;
list.appendChild(rRow);
list.scrollTop = list.scrollHeight;
}, 1000 + Math.random() * 1000);
MiMo-V2-TTS 模型
没有声音的 Agent 是不完整的。MiMo-V2-TTS 是小米自研的端到端文本转语音合成模型,基于自研 Audio Tokenizer 和**多码本联合建模(Multi-Codebook Joint Modeling)**架构。
官方地址:MiMo-V2-TTS | Xiaomi
功能使用文档:MiMo-V2-TTS 功能 使用文档
API使用文档:MiMo-V2-TTS API 使用文档
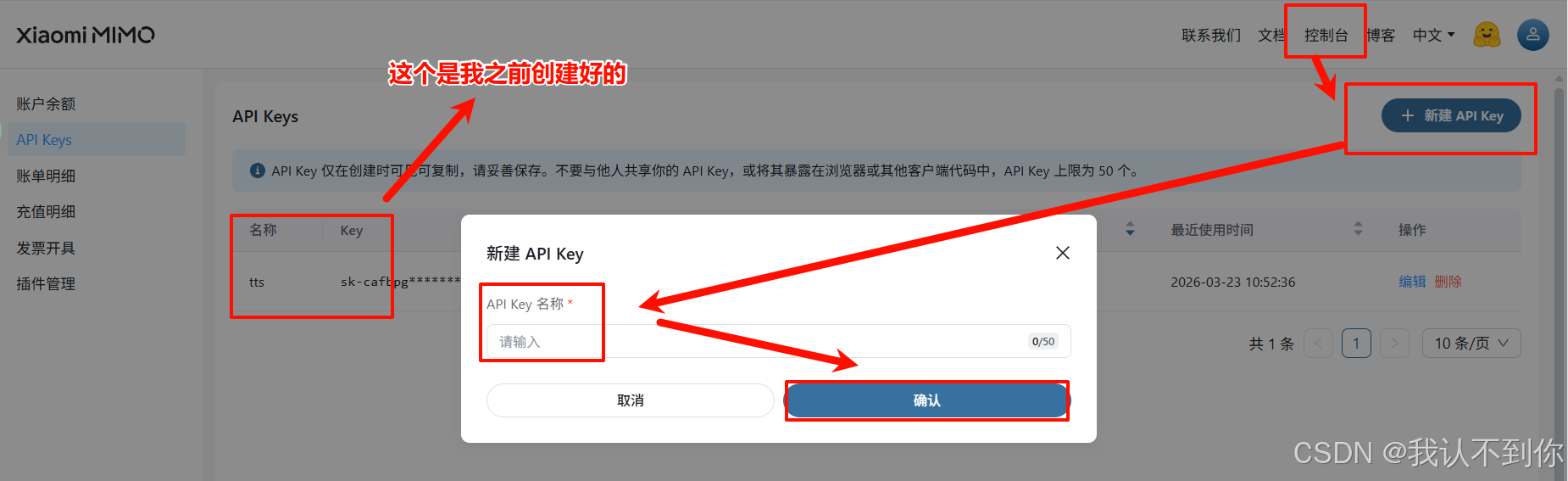
申请API Key
这个就很简单了,点击这个地址Xiaomi MiMo 开放平台,先注册一个小米账号,然后再点击这个地址(或者点击控制台–>API Keys),然后新建一个API Key就好了
API的使用(参数说明)
非流式输出
http 输入(在cmd窗口输入回车即可)
curl --location --request POST "https://api.xiaomimimo.com/v1/chat/completions" ^
--header "api-key: %MIMO_API_KEY%" ^
--header "Content-Type: application/json" ^
--data-raw "{\"model\": \"mimo-v2-tts\", \"messages\": [{\"role\": \"user\", \"content\": \"Hello, MiMo, have you had lunch?\"}, {\"role\": \"assistant\", \"content\": \"Yes, I had a sandwich.\"}], \"audio\": {\"format\": \"wav\", \"voice\": \"mimo_default\"}}"
输入json讲解:
关于输出内容风格,如:东北话、生气、夹子声
这个后面讲,这里只讲json的内容分析
{
// 模型名称
"model": "mimo-v2-tts",
// 消息
"messages": [
{
// user 角色的消息为可选参数,但建议用户携带,可在部分场景下调整语音合成的语气与风格。
"role": "user",
// 内容
"content": "Hello, MiMo, have you had lunch?"
},
{
// 语音合成的目标文本需填写在 role 为 assistant 的消息中,不可放在 user 角色的消息内。
"role": "assistant",
// 内容 这里可以有风格设置后面会讲,这里只讲json的内容分析
"content": "Yes, I had a sandwich."
}
],
// 音频输出参数
"audio": {
// 指定输出音频格式。默认值:wav,如果设置 stream: true 则为 pcm。
// 可选值:wav,mp3,pcm,pcm16
"format": "wav",
// 模型用于响应的内置音色。
// 可选值:mimo_default,default_en,default_zh
"voice": "mimo_default"
},
// 是否流式输出
"stream": false
}
http 输出(json讲解)
通过choices.message.audio.data的Base64编码可以输出为对应的音频文件
{
// 唯一ID
"id": "dd4b41d152e84d97bf828a06583d68c6",
// 包含生成的回复选项列表。
"choices": [
{
// 模型停止生成 token 的原因。如果模型到达自然停止点或提供的停止序列,则为 stop;
// 如果达到请求中指定的最大 token 数,则为 length;
// 如果模型调用了工具,则为 tool_calls。
// 如果内容因触发过滤策略而被拦截,则为 content_filter。
"finish_reason": "stop",
// 选项列表中对应选项的索引。
"index": 0,
// 模型生成的对话补全消息。
"message": {
// 消息的内容。
"content": "",
// 消息作者的角色。
"role": "assistant",
// 模型音频响应的数据。
"audio": {
// 此音频响应的唯一标识符。
"id": "dc4acca3976643d88c4e6904f74afd5e",
// 模型生成的 Base64 编码音频,格式为请求中指定的格式。
"data": "base64编码(这里太长了,我给删掉了)",
// 此音频响应过期的 Unix 时间戳(以秒为单位)。当前仅为 null。
"expires_at": null,
// 模型生成的音频的文字记录。当前仅为 null。
"transcript": null
},
// 函数调用启动后,模型会返回待调用的工具以及该调用所需的参数。
// 此参数可包含一个或多个工具响应对象。
"tool_calls": null
}
}
],
// 对话补全对象创建时的 Unix 时间戳(以秒为单位)。每个数据块均使用相同的时间戳。
"created": 1774233257,
// 用于生成结果的模型。
"model": "mimo-v2-tts",
// 对象类型,仅为 chat.completion.chunk。
"object": "chat.completion",
// 该对话补全请求的用量信息。
"usage": {
// 模型输出内容花费的 token。
"completion_tokens": 22,
// 提示词使用的 token 数量。
"prompt_tokens": 139,
// 请求中使用的 token 总数(提示词 + 补全结果)。
"total_tokens": 161,
// 补全中使用的 token 数量明细。
"completion_tokens_details": {
// 模型为推理生成的 token 数量。
"reasoning_tokens": 0
},
// 提示中使用的 token 数量明细。
"prompt_tokens_details": {
// 缓存中提供的 token 数量。
"cached_tokens": 138
}
}
}
python输入(OpenAI API 兼容)
这个和上面的内容是一样的,所以就不过多讲解了
import os
from openai import OpenAI
import base64
client = OpenAI(
api_key=os.environ.get("MIMO_API_KEY"),
base_url="https://api.xiaomimimo.com/v1"
)
completion = client.chat.completions.create(
model="mimo-v2-tts",
messages=[
{
"role": "user",
"content": "Hello, MiMo, have you had lunch?"
},
{
"role": "assistant",
"content": "Yes, I had a sandwich."
}
],
audio={
"format": "wav",
"voice": "mimo_default"
}
)
message = completion.choices[0].message
audio_bytes = base64.b64decode(message.audio.data)
with open("audio_file.wav", "wb") as f:
f.write(audio_bytes)
流式输出
因为这是文件的IO流操作,所以用流式和非流式,都要最终合成文件然后再给用户
所以流式的效果不能直观的展示给用户,在我看来非常的鸡肋,所以这里只做展示
注意事项
- 采用流式调用时,输出音频的格式请指定为
pcm16,以便拼接成完整音频。拼接示例可参考 Python 调用方式。
http 输入(在cmd窗口输入回车即可)
就是在data里面多一个参数 “stream”: true,其他都是一样的
curl --location --request POST "https://api.xiaomimimo.com/v1/chat/completions" ^
--header "api-key: sk-cafbpgu5o8171zbwacw3klmh3zpv5em87igqomit31wq00lf" ^
--header "Content-Type: application/json" ^
--data-raw "{\"model\": \"mimo-v2-tts\", \"messages\": [{\"role\": \"user\", \"content\": \"Hello, MiMo, have you had lunch?\"}, {\"role\": \"assistant\", \"content\": \"Yes, I had a sandwich.\"}], \"audio\": {\"format\": \"wav\", \"voice\": \"mimo_default\"},\"stream\": true}"
python输入(OpenAI API 兼容)
import base64
import os
import numpy as np
import soundfile as sf
from openai import OpenAI
client = OpenAI(
api_key=os.environ.get("MIMO_API_KEY"),
base_url="https://api.xiaomimimo.com/v1"
)
completion = client.chat.completions.create(
model="mimo-v2-tts",
messages=[
{
"role": "assistant",
"content": "You are UN-BE-LIEVABLE! I am sooooo done with your constant lies. GET. OUT!"
}
],
audio={
"format": "pcm16",
"voice": "default_en"
},
stream=True
)
# 24kHz PCM16LE mono audio
collected_chunks: np.ndarray = np.array([], dtype=np.float32)
for chunk in completion:
if not chunk.choices:
continue
delta = chunk.choices[0].delta
audio = getattr(delta, "audio", None)
if audio is not None:
assert isinstance(audio, dict), f"Expected audio to be a dict, got {type(audio)}"
pcm_bytes = base64.b64decode(audio["data"])
np_pcm = np.frombuffer(pcm_bytes, dtype=np.int16).astype(np.float32) / 32768.0
collected_chunks = np.concatenate((collected_chunks, np_pcm))
print(f"Received audio chunk of size {len(pcm_bytes)} bytes")
# Save the collected audio to a file
os.makedirs("tmp", exist_ok=True)
sf.write("tmp/output.wav", collected_chunks, samplerate=24000)
print("Audio saved to tmp/output.wav")
模型输出风格设置
语音整体风格控制
将 <style>style</style> 置于转换目标文本开头,其中 style 为需要生成的音频风格。如需设置多种风格,请将多个风格名称置于同一个 <style> 标签内,分隔符不限。
格式示例:<style>风格1 风格2</style>待合成内容。
以下是一些推荐使用的风格,支持使用不在列表中的风格。
| 风格类型 | 风格示例 |
|---|---|
| 语速控制 | 变快/变慢 |
| 情绪变化 | 开心/悲伤/生气 |
| 角色扮演 | 孙悟空/林黛玉 |
| 风格变化 | 悄悄话/夹子音/台湾腔 |
| 方言 | 东北话/四川话/河南话/粤语 |
样例:
<style>开心</style>明天就是周五了,真开心!<style>东北话</style>哎呀妈呀,这天儿也忒冷了吧!你说这风,嗖嗖的,跟刀子似的,割脸啊!<style>粤语</style>呢个真係好正啊!食过一次就唔会忘记!<style>唱歌</style>原谅我这一生不羁放纵爱自由,也会怕有一天会跌倒,Oh no。背弃了理想,谁人都可以,哪会怕有一天只你共我。
音频标签细粒度控制
通过 [音频标签] ,你可以对声音进行细粒度控制,精准调节语气、情绪和表达风格——无论是低声耳语、放声大笑,还是带点小情绪的小吐槽,也可以灵活插入呼吸声,停顿,咳嗽等,都能轻松实现。语速同样可以灵活调整,让每句话都有它该有的节奏。
样例:
- (紧张,深呼吸)呼……冷静,冷静。不就是一个面试吗……(语速加快,碎碎念)自我介绍已经背了五十遍了,应该没问题的。加油,你可以的……(小声)哎呀,领带歪没歪?
- (极其疲惫,有气无力)师傅……到地方了叫我一声……(长叹一口气)我先眯一会儿,这班加得我魂儿都要散了。
- 如果我当时……(沉默片刻)哪怕再坚持一秒钟,结果是不是就不一样了?(苦笑)呵,没如果了。
- (寒冷导致的急促呼吸)呼——呼——这、这大兴安岭的雪……(咳嗽)简直能把人骨头冻透了……别、别停下,走,快走。
- (提高音量喊话)大姐!这鱼新鲜着呢!早上刚捞上来的!哎!那个谁,别乱翻,压坏了你赔啊?!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)