PyTorch入门实战|LeNet5手写数字识别
PyTorch入门实战|LeNet5手写数字识别
前言
本篇是PyTorch深度学习纯入门实战,围绕经典LeNet5卷积网络,完成MNIST手写数字识别全流程。从卷积层、全连接层参数的拆开讲解,到一步步走完模型搭建、数据加载、训练、评估全套流程,从而彻底搞懂CNN入门核心逻辑。
一、项目基础信息
1.1 核心技术栈
-
开发环境:Python 3.8+、PyTorch 2.0+
-
核心工具:torchvision(数据集加载+预处理)、DataLoader(批次数据打包)
-
核心模型:LeNet5(经典轻量级CNN,卷积网络入门必学)
-
数据集:MNIST手写数字数据集(0-9黑白灰度图,28×28尺寸,入门首选)
1.2 实战目标
-
看懂Conv2d卷积层、Linear全连接层每一个参数的含义,不死记硬背
-
掌握PyTorch搭建模型的固定写法,分清构造函数和前向传播的作用
-
吃透深度学习训练+评估的完整逻辑,弄懂梯度、损失、优化器的核心作用
-
成功运行代码,得到模型准确率,能独立排查基础报错
二、核心层参数解析
LeNet5核心就是卷积层提特征 + 全连接层做分类,先把这两层参数讲透,后续代码一看就懂,只讲实战用到的关键参数,多余内容全部省略。
2.1 Conv2d 二维卷积层(特征提取)
卷积层就是用一个**小方块(卷积核)**在图片上滑动扫描,提取边缘、纹理这类基础特征,相当于给图片“找重点”。
nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0)
| 参数 | 白话含义 | LeNet5实际取值 |
|---|---|---|
| in_channels | 输入图片通道数,灰度图=1,彩色图=3 | 1(MNIST是黑白灰度图) |
| out_channels | 卷积核数量,想提取多少种特征就设多少 | 6、16、120(LeNet5经典设计) |
| kernel_size | 扫描小方块的大小,常用3×3或5×5 | 5(5×5卷积核) |
| stride | 小方块每次滑动的步数,默认1 | 1 |
| padding | 图片边缘补0的圈数,控制输出尺寸 | 2、0 |
2.2 Linear 全连接层(最终分类)
全连接层负责做最终判断,把卷积提取的特征,转换成0-9的分类结果。注意:全连接层只能接受一维数据,卷积输出的多维数据必须先展平。
nn.Linear(in_features, out_features)
| 参数 | 白话含义 | LeNet5实际取值 |
|---|---|---|
| in_features | 输入的特征总数,必须和前一层展平后数量一致 | 120、84 |
| out_features | 输出结果数量,分类数就是最终值 | 84、10(10对应0-9十个数字) |
关键衔接:卷积层输出是多维数据,必须用 x.view(-1, 120) 展平成一维,才能接入全连接层,-1代表自动计算批次数量,不用手动指定。 |
三、完整实战流程(代码+注释)
全程代码无冗余,注释直白,复制到编辑器就能运行,自动下载数据集,适配CPU和GPU。
3.1 模块导入 & 设备配置
导入依赖库,自动判断用GPU还是CPU,不用手动修改。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision.datasets import MNIST
from torchvision.transforms import Compose, ToTensor
from torch.utils.data import DataLoader
# 设备选择:有GPU用GPU,没GPU自动用CPU
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(f"当前运行设备:{device}")
3.2 LeNet5模型搭建
PyTorch模型固定写法:继承nn.Module → 构造函数定义层 → forward实现前向运算,这是固定模板,后续所有模型都这么写。
class Lenet5(nn.Module):
def __init__(self):
# 继承父类构造器,固定写法
super(Lenet5, self).__init__()
# 第一层:卷积 + 激活 + 池化
self.conv1 = nn.Conv2d(1, 6, 5, 1, 2)
self.relu1 = nn.ReLU()
self.pool1 = nn.MaxPool2d(2) # 池化核2×2,图片尺寸直接减半
# 第二层:卷积 + 激活 + 池化
self.conv2 = nn.Conv2d(6, 16, 5)
self.relu2 = nn.ReLU()
self.pool2 = nn.MaxPool2d(2)
# 第三层:卷积 + 激活
self.conv3 = nn.Conv2d(16, 120, 5)
self.relu3 = nn.ReLU()
# 第四层:全连接 + 激活
self.fc4 = nn.Linear(120, 84)
self.relu4 = nn.ReLU()
# 第五层:全连接(输出层,不加激活)
self.fc5 = nn.Linear(84, 10)
def forward(self, x):
# 前向传播:数据按顺序过每一层
x = self.conv1(x)
x = self.relu1(x)
x = self.pool1(x)
x = self.conv2(x)
x = self.relu2(x)
x = self.pool2(x)
x = self.conv3(x)
x = self.relu3(x)
# 展平数据,对接全连接层
x = x.view(-1, 120)
x = self.fc4(x)
x = self.relu4(x)
x = self.fc5(x)
return x
# 实例化模型,放到对应设备
model = Lenet5().to(device)
3.3 数据集加载(训练集+测试集)
MNIST数据集自动下载,分成训练集(模型学习)和测试集(模型考试),打包成批次方便训练。
def load_mnist(root='./minist', batch_size=100):
# 数据预处理:只转成张量,模型能识别
transform = Compose([ToTensor()])
# 加载训练集:train=True,6万张图片
train_ds = MNIST(root=root, train=True, download=True, transform=transform)
# 加载测试集:train=False,1万张图片
valid_ds = MNIST(root=root, train=False, download=True, transform=transform)
# 打包批次:训练集打乱顺序,测试集不打乱
train_loader = DataLoader(train_ds, shuffle=True, batch_size=batch_size)
valid_loader = DataLoader(valid_ds, shuffle=False, batch_size=batch_size)
return train_loader, valid_loader
# 加载数据,批次大小100
train_loader, valid_loader = load_mnist()
数据集区分:train=True是训练集(教模型),train=False是测试集(考模型),测试集shuffle必须设为False,保证评估公平。
3.4 模型训练模块
训练核心四步:梯度清零 → 模型推理 → 算损失 → 更新参数,这是深度学习训练的固定逻辑。
# 定义损失函数:分类任务首选交叉熵损失,衡量预测对错差距
loss_fun = nn.CrossEntropyLoss()
# 定义优化器:Adam优化器,入门首选,学习率设0.0005
optimizer = optim.Adam(model.parameters(), lr=0.0005)
# 单轮训练函数
def train_one_epoch(model, loader, loss_fun, optimizer, device):
model.train() # 切换训练模式,固定写法
for x, y in loader:
# 数据和模型放同一设备
x, y = x.to(device), y.to(device)
# 梯度清零:防止上一批数据梯度残留,必须写
optimizer.zero_grad()
# 模型推理
y_pred = model(x)
# 计算损失
loss = loss_fun(y_pred, y)
# 反向传播,算梯度
loss.backward()
# 更新模型参数,模型学习的核心步骤
optimizer.step()
3.5 模型评估模块
评估时不更新模型,关闭梯度计算,只统计损失和准确率,直观看模型效果。
# 关闭梯度追踪,评估专用,提速省内存
@torch.no_grad()
def evaluate(model, loader, loss_fun, device):
model.eval() # 切换评估模式
total_num = 0
correct_num = 0
total_loss = 0.0
for x, y in loader:
x, y = x.to(device), y.to(device)
y_pred = model(x)
# 累加损失
loss = loss_fun(y_pred, y)
total_loss += loss.item()
# 取概率最大的结果作为预测值
_, pred_result = torch.max(y_pred, dim=1)
# 统计正确数量
correct_num += (pred_result == y).sum().item()
total_num += y.size(0)
# 打印评估结果
acc = correct_num / total_num * 100
print(f"\t评估损失:{total_loss:.6f}")
print(f"\t识别准确率:{acc:.6f}%\n")
3.6 主训练入口
循环训练多轮,每轮训练完立刻评估,保存模型权重。
def train_model(epochs=10):
for epoch in range(epochs):
print(f"===== 第{epoch+1:02d}轮训练 =====")
train_one_epoch(model, train_loader, loss_fun, optimizer, device)
# 每轮训练后做评估
evaluate(model, valid_loader, loss_fun, device)
# 保存模型权重
torch.save(model.state_dict(), 'lenet5.pth')
# 运行训练,默认训练100轮
if __name__ == '__main__':
train_model(epochs=100)
四、运行结果说明
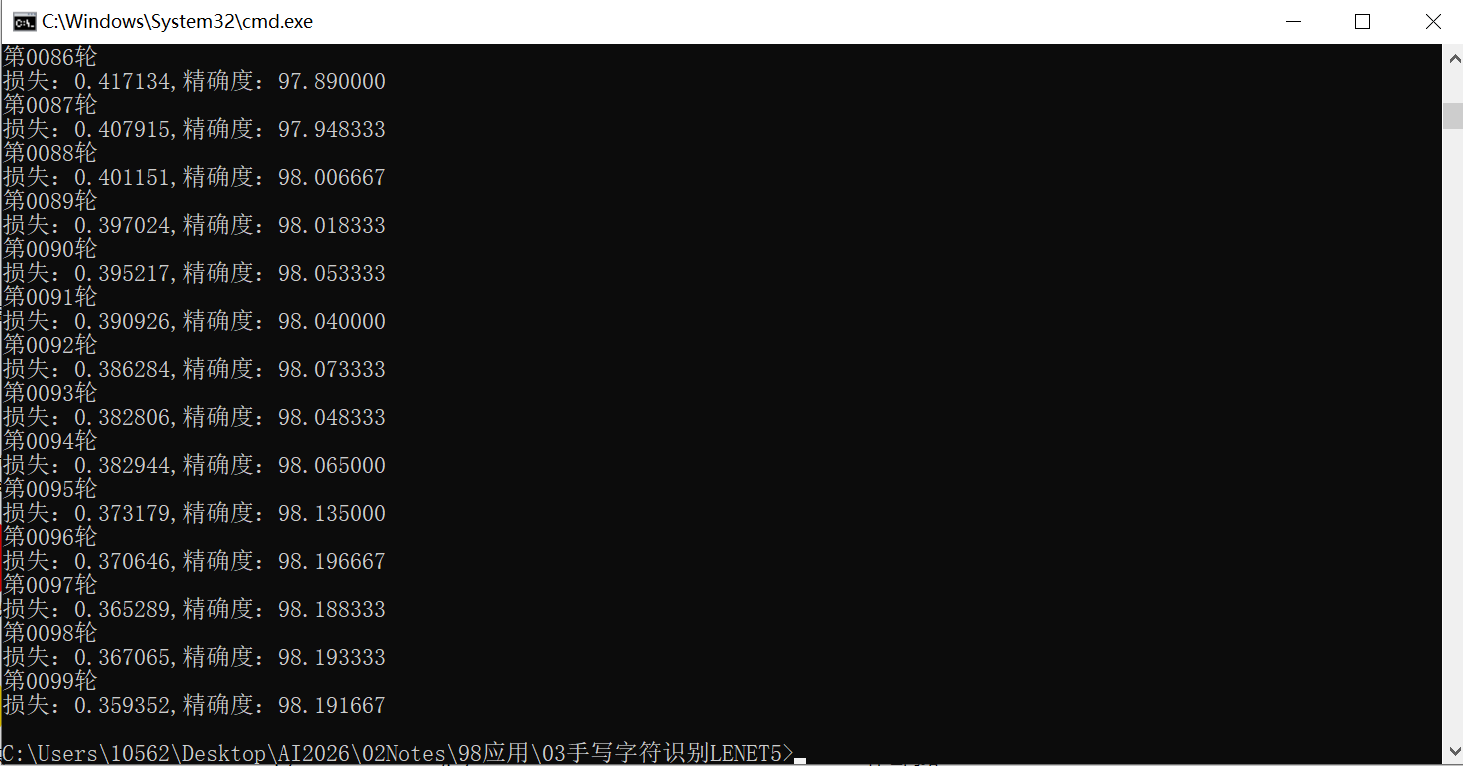
运行后控制台会逐轮打印结果,正常情况下:
-
第一轮训练后准确率就能达到90%以上
-
100轮训练结束,准确率稳定在98%左右
-
根目录会生成lenet5.pth文件,这是训练好的模型权重
五、新手注意事项(避坑)
-
维度不匹配报错:大概率是view展平的特征数和Linear输入对不上,严格按照代码里的120修改即可
-
梯度清零必须写:每批训练前都要清零,否则梯度累加,模型训练效果极差
-
设备统一:模型和数据必须放在同一设备(都GPU或都CPU),否则报错
-
数据集下载慢:网络不好时多等一会,或者手动下载MNIST数据集放到minist文件夹
-
batch_size调整:GPU显存小就改小batch_size(比如50),不影响最终效果
六、核心知识点总结
-
PyTorch模型必须继承nn.Module,__init__定义层,forward做运算
-
卷积层提特征,全连接层做分类,中间必须展平数据
-
训练模式train()、评估模式eval(),评估必须加@torch.no_grad()
-
训练核心:梯度清零→推理→损失→反向传播→更新参数
-
dim=1代表按行取最大值,对应分类任务选概率最高的结果
七、后续扩展方向
-
添加Dropout层,防止模型过拟合,提升泛化能力
-
调整学习率、batch_size,优化训练速度和准确率
-
编写单张图片推理代码,用自己手写的数字测试模型
-
可视化训练损失和准确率曲线,更直观观察训练过程

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 29
29 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)