【通义千问】蓝耘原生代 | Qwen3-235B-A22B 架构创新赋能AI生态

【作者主页】Francek Chen
【专栏介绍】 ⌈ ⌈ ⌈人工智能与大模型应用 ⌋ ⌋ ⌋ 人工智能(AI)通过算法模拟人类智能,利用机器学习、深度学习等技术驱动医疗、金融等领域的智能化。大模型是千亿参数的深度神经网络(如ChatGPT),经海量数据训练后能完成文本生成、图像创作等复杂任务,显著提升效率,但面临算力消耗、数据偏见等挑战。当前正加速与教育、科研融合,未来需平衡技术创新与伦理风险,推动可持续发展。
文章目录

前言
数字化时代,大模型迅速崛起并重塑生活、工作和社会运行逻辑,为各行业带来变革与机遇。通义千问以出色自然语言理解能力,推动人机交互迈向新高度。本文探讨蓝耘 MaaS(Model as a Service)平台与深度学习的关系,阐述与阿里通义千问 Qwen3-235B-A22B 模型融合亮点,应用 Chatbox 拓展实例。
一、Chatbox 概述
Chatbox 作为一款跨平台 AI 客户端,凭借其硬核的功能、清爽的 UI 设计以及对用户隐私的极致尊重,已快速成为办公学习领域的现象级工具。它超越了传统聊天机器人的范畴,是一款能应对从日常琐事到专业开发的多元化智能助手。
Chatbox 的核心亮点包括:
- 多端无缝协同:全面支持 Windows、MacOS、Linux、移动端及网页版,让您在任何设备上都能延续工作流。
- 文档图片对话:支持上传 PDF、Word、Excel、TXT 及图片,AI 能深度解读内容并给出精准的分析响应。
- 代码智能伴侣:集代码生成预览、审查优化、Bug 调试与安全检查于一体,覆盖多种编程语言。
- 联网实时感知:AI 可主动搜索全网信息,提供 URL 解析、摘要提炼及事实验证,告别知识滞后。
- 图表自动生成:将复杂概念与数据转化为清晰可调的可视化图表,让信息展示更专业。
- 创意图像渲染:只需简单描述,即可生成高品质图片,激发灵感,满足设计与创作需求。
- 公式排版专家:完美支持 LaTeX 与 Markdown 渲染,让复杂公式和技术文档的书写得心应手。
- 数据隐私守护:高度重视信息安全,所有数据默认本地存储,彻底杜绝隐私泄露风险。
Chatbox 官网主页:https://chatboxai.app/zh

二、Qwen3-235B-A22B 模型简介
Qwen3-235B-A22B 以创新架构实现了性能的显著跃升。该模型采用稀疏激活机制,虽拥有庞大的总参数量,但在推理过程中仅激活少量关键参数,有效降低了计算成本,同时其精度可与顶级闭源模型相媲美。在数学推理方面,它在解答 AIME 竞赛题时展现出高准确率;代码生成能力更是出众,超越了 OpenAI 的 Grok-3,能够迅速生成复杂且高质量的代码。
此外,Qwen3-235B-A22B 独创了双模式切换功能,既能高效进行严谨的逻辑推演,又能自然流畅地处理日常交互任务。它支持超过百种语言,翻译质量实现了显著提升。在创意写作等场景中,该模型展现出卓越的拟人性,多轮对话的连贯性增强,指令解析的准确率大幅提高,面对工程化任务时更可实现秒级响应。

此前,Qwen 系列所采用的“混合思考模式”,凭借其“Think + Instruct 二合一”的独特设计,乍一听颇具高端科技感。然而,在实际应用落地过程中,却状况百出、麻烦不断。有用户忍不住吐槽,该模式各类标签堆砌得极为繁杂,简直堪比 HTML 里的垃圾代码,光是看着就让人倍感头疼、心烦意乱。
而这一次,Qwen 大刀阔斧地进行了改进,直接砍掉了“思考”分支,将全部精力都投入到 Instruct 指令模型的训练当中。如此一来,用户无需再手动配置 enable_thinking = False 这类繁琐参数,也不用时刻提心吊胆,担心模型会在运行过程中突然“走神”、偏离预期。用一句话来概括此次改变,那就是:简洁清爽、干脆利落,执行效率直接飙升至满格状态。
三、蓝耘 MaaS 平台使用 Qwen3-235B-A22B 模型
(一)注册蓝耘智算平台账号
点击注册链接:https://console.lanyun.net/#/register?promoterCode=0180
输入手机号获取验证码,输入邮箱(这里邮箱会收到信息,要激活邮箱),设置密码,点击注册。如图3所示。

新用户福利:注册后可领取免费试用时长(20元代金券,可直接当余额来使用)。
若已经注册过帐号,点击下方“已有账号,立即登录”即可。
(二)进入蓝耘 MaaS 模型广场
登录后进入首页,点击“MaaS平台”。接着进入 MaaS 平台的模型广场。在这里,用户可以看到多种来自不同供应商的模型,如 DeepSeek、通义等。页面详细列出了模型名称、类型(如文本生成)、上下文长度等信息,还提供了 API 示例、查看详情和立即体验等操作选项。
然后,找到 Qwen3-235B-A22B 大模型,点击“立即体验”。如图4所示。

图5中展示的是蓝耘元生代 MaaS 平台的对话界面。左侧是功能导航栏,包含模型广场、文本模型等选项。对话框上方是模型选择区域,点击可展开选择如 DeepSeek-V3.2、Qwen3-235B-A22B 等多种模型。下方是对话输入区,用户可输入问题,有“深度思考”“联网搜索”“知识库”等功能按钮,输入框显示 token 限制。这里选择的是“Qwen3-235B-A22B”模型。

(三)使用 Qwen3-235B-A22B 模型生成代码
生成有关机器学习回归预测的代码,提示词如下:
帮我生成一段关于机器学习回归预测的代码,要求使用scikit-learn库。
输出结果如图6所示。

此次对话输出652tokens,总耗时8.6s,共消耗677tokens。该对话token消耗的数量=输入token数+输出token数。
输出代码如下:
# 导入必要的库
import numpy as np
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# 1. 加载数据集(这里使用糖尿病数据集作为示例)
data = load_diabetes()
X, y = data.data, data.target
# 2. 将数据集分为训练集和测试集(80%训练,20%测试)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 3. 创建线性回归模型
model = LinearRegression()
# 4. 训练模型
model.fit(X_train, y_train)
# 5. 在测试集上进行预测
y_pred = model.predict(X_test)
# 6. 评估模型性能
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
# 7. 输出结果
print("模型系数:", model.coef_)
print("模型截距:", model.intercept_)
print("均方误差 (MSE):", mse)
print("决定系数 (R^2):", r2)
# 8. 预测单个样本
sample = X_test[0].reshape(1, -1)
predicted_value = model.predict(sample)
print("\n预测单个样本的目标值:", predicted_value[0])
print("真实值:", y_test[0])
四、使用 Chatbox 接入蓝耘 Qwen3-235B-A22B API
(一)添加配置 Qwen3-235B-A22B 模型
- API 域名:
https://maas-api.lanyun.net/v1 - API 路径:
/chat/completions

- API 密钥:回到蓝耘 MaaS 平台获取专属 API KEY,如图8所示。
- 模型:
/maas/qwen/Qwen3-235B-A22B(图4中所示的模型名称)
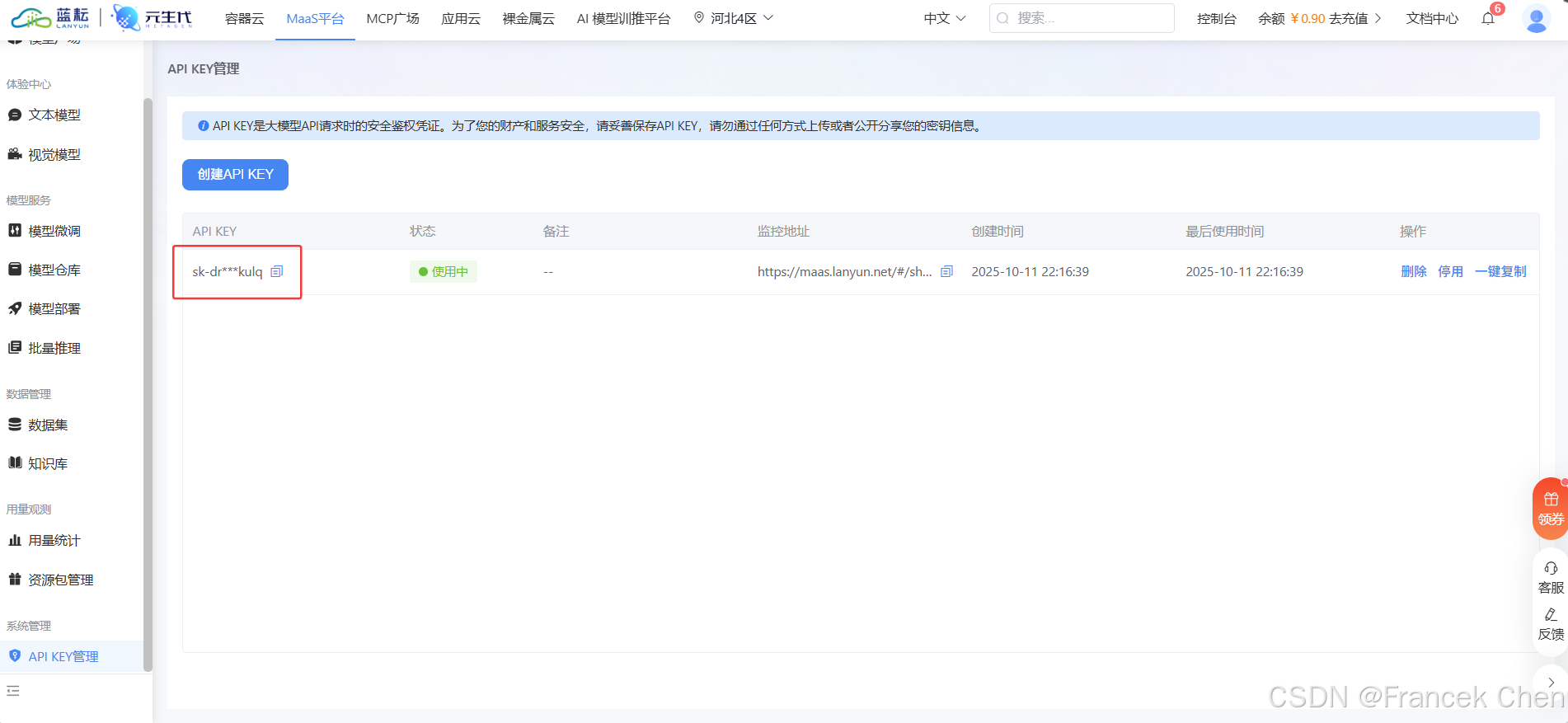
配置完成,点击保存。
(二)新建对话测试验证
新建对话,验证蓝耘 Qwen3-235B-A22B 模型对话。提示词如下:
200字简单概述一下Qwen3-235B-A22B大模型的升级点

小结
Qwen3-235B-A22B 是通义千问系列的超大规模语言模型的迭代版本,升级点主要体现在:基于更高效的混合专家(MoE)架构设计,在保持 235B 超大参数量的基础上,通过动态计算资源分配提升推理效率;融合超 5 万亿多语言文本及代码数据,强化了对专业领域的深度理解能力;支持长文本,并通过量化压缩技术降低部署成本;集成视觉-语音协同机制框架,支持图文生成、跨模态检索等复合任务;优化了内容过滤机制,增强对话场景中的逻辑一致性与价值观对齐。
欢迎 点赞👍 | 收藏⭐ | 评论✍ | 关注🤗


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 74
74 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)