论文精读:Building Effective Agents
论文精读:Building Effective Agents
文章目录
- 论文精读:Building Effective Agents
-
- 核心观点摘要
- 一、Agent 的定义与分类
- 二、何时使用(以及何时不使用)Agents
- 三、框架使用策略
- 四、构建模块体系(由简到繁)
- 五、Agent 设计模式
- 六、最佳实践总结
- 七、实际应用案例(附录精华)
- 八、常见陷阱与避免方法
- 九、核心要点回顾
- 十、未来展望
- 十一、我的思考与启示
- 参考资源
- 总结
来源: Anthropic Engineering Blog
原文链接: Building Effective Agents
发布时间: 2024年
核心观点摘要
Anthropic 基于与数十个团队的合作经验,提出了一个重要观点:最成功的 Agent 实现并非使用复杂的框架或专用库,而是采用简单、可组合的模式。本文系统性地总结了构建高效 AI Agent 的架构设计原则和最佳实践。
一、Agent 的定义与分类
1.1 什么是 Agent?
Agent 可以有多种定义方式:
- 全自主系统:在较长时间内独立运行,使用各种工具完成复杂任务
- 预定义工作流实现:遵循预定的工作流程
- 混合型系统:结合上述两种特征
1.2 关键架构区分:Workflows vs Agents
| 特征 | Workflows(工作流) | Agents(智能体) |
|---|---|---|
| 控制方式 | LLM 和工具通过预定义的代码路径进行编排 | LLM 动态指导自己的流程和工具使用 |
| 决策机制 | 程序化逻辑决定执行路径 | 模型驱动决策 |
| 适用场景 | 任务明确、流程固定 | 需要灵活性、大规模决策的场景 |
| 可预测性 | 高 | 较低但更灵活 |
核心洞察: Workflows 提供可预测性和一致性;Agents 提供灵活性和模型驱动的决策能力。
二、何时使用(以及何时不使用)Agents
2.1 使用原则:从简到繁
核心建议:始终寻找最简单的解决方案,仅在必要时增加复杂性。
不需要构建 Agentic 系统的情况:
- 单次优化的 LLM 调用 + 检索增强(RAG)+ 上下文示例通常足够
- 许多应用场景不需要 Agent 架构
需要增加复杂性的权衡:
- 代价:增加延迟和成本
- 收益:更好的任务性能
- 判断标准:这种权衡是否合理?
2.2 选择指南
简单任务 → 优化单次 LLM 调用(RAG + 示例)
↓ 需要更多准确性?
明确任务 → Workflows(可预测、一致)
↓ 需要灵活性?
复杂/不确定任务 → Agents(动态决策、自适应)
三、框架使用策略
3.1 可用的框架工具
- Claude Agent SDK (Anthropic)
- Strands Agents SDK (AWS)
- Rivet - 拖拽式 GUI LLM 工作流构建器
- Vellum - GUI 复杂工作流构建和测试工具
3.2 框架的优缺点
优势:
- 简化标准底层任务(调用 LLM、定义解析工具、链式调用)
- 快速入门和原型开发
劣势:
- 创建额外抽象层,可能掩盖底层的 prompts 和 responses
- 使调试更加困难
- 容易在简单设置就足够时引入不必要的复杂性
3.3 Anthropic 的建议
推荐做法:
- 直接使用 LLM API:许多模式只需几行代码即可实现
- 如果使用框架,确保理解底层代码
- 对底层实现的不正确假设是客户错误的常见来源
四、构建模块体系(由简到繁)
4.1 基础模块:Augmented LLM(增强型大语言模型)-给LLM加上手和脚
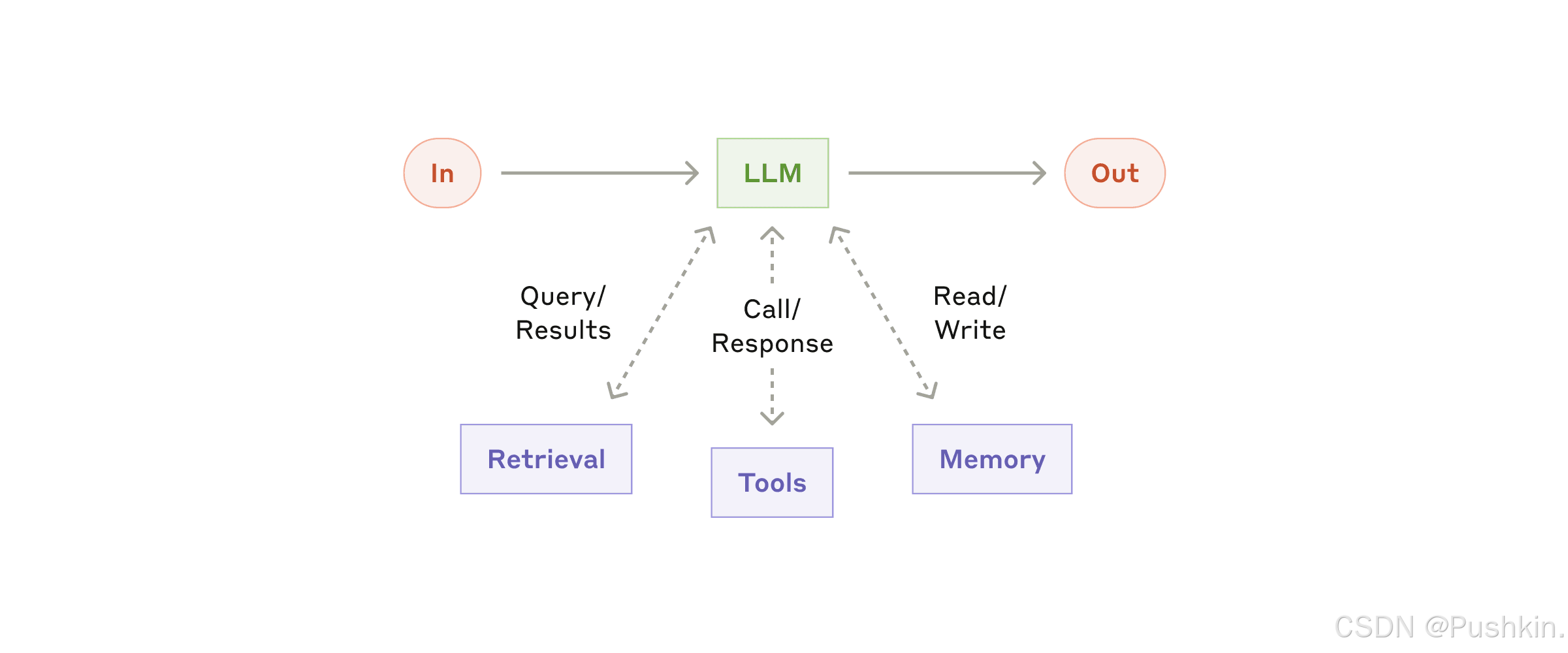
定义:通过检索、工具和记忆等能力增强的 LLM。
关键特性:
- 当前模型可以主动使用这些能力
- 自动生成搜索查询
- 选择合适的工具
- 决定保留哪些信息
实施要点:
- 针对特定用例定制能力
- 提供易于理解、文档完善的接口
- 可考虑使用 Model Context Protocol (MCP) 与第三方工具集成
4.2 Workflow 模式 1:Prompt Chaining(提示链)
原理:将任务分解为一系列步骤,每个 LLM 调用处理前一个的输出。
架构图示:
输入 → LLM(步骤1) → Gate检查 → LLM(步骤2) → ... → 最终输出
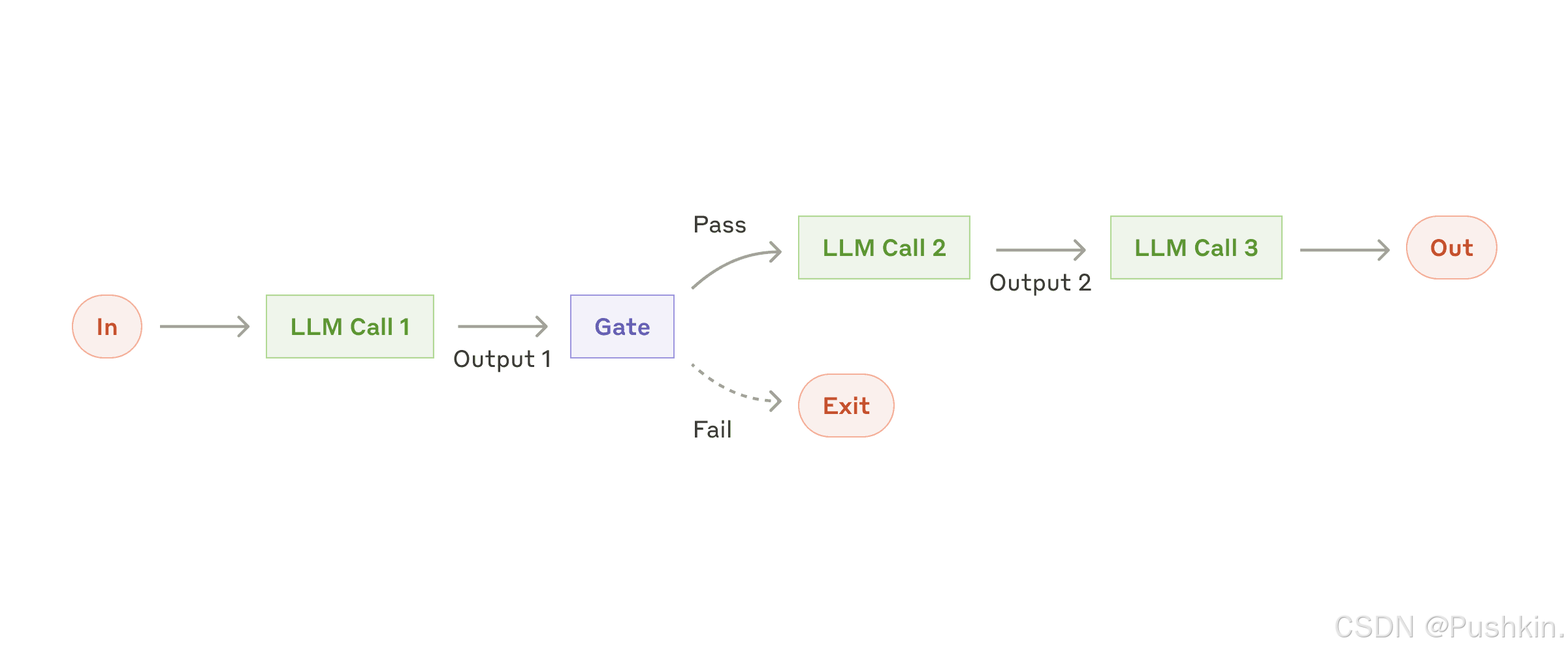
适用场景:
- ✅ 任务可以清晰分解为固定的子任务
- ✅ 目标是用延迟换取更高的准确性
- ✅ 每个 LLM 调用都是更简单的任务
实际案例:
- 先生成营销文案,再翻译成不同语言
- 先写文档大纲,检查是否符合标准,再基于大纲写完整文档
Gate 检查机制:可以在中间步骤添加程序化检查,确保过程仍在正轨。
4.3 Workflow 模式 2:Routing(路由)
原理:对输入进行分类,并引导至专门的后续处理分支。
架构图示:
输入 → 分类器(LLM) → 分支A: 专业处理A
→ 分支B: 专业处理B
→ 分支C: 默认处理
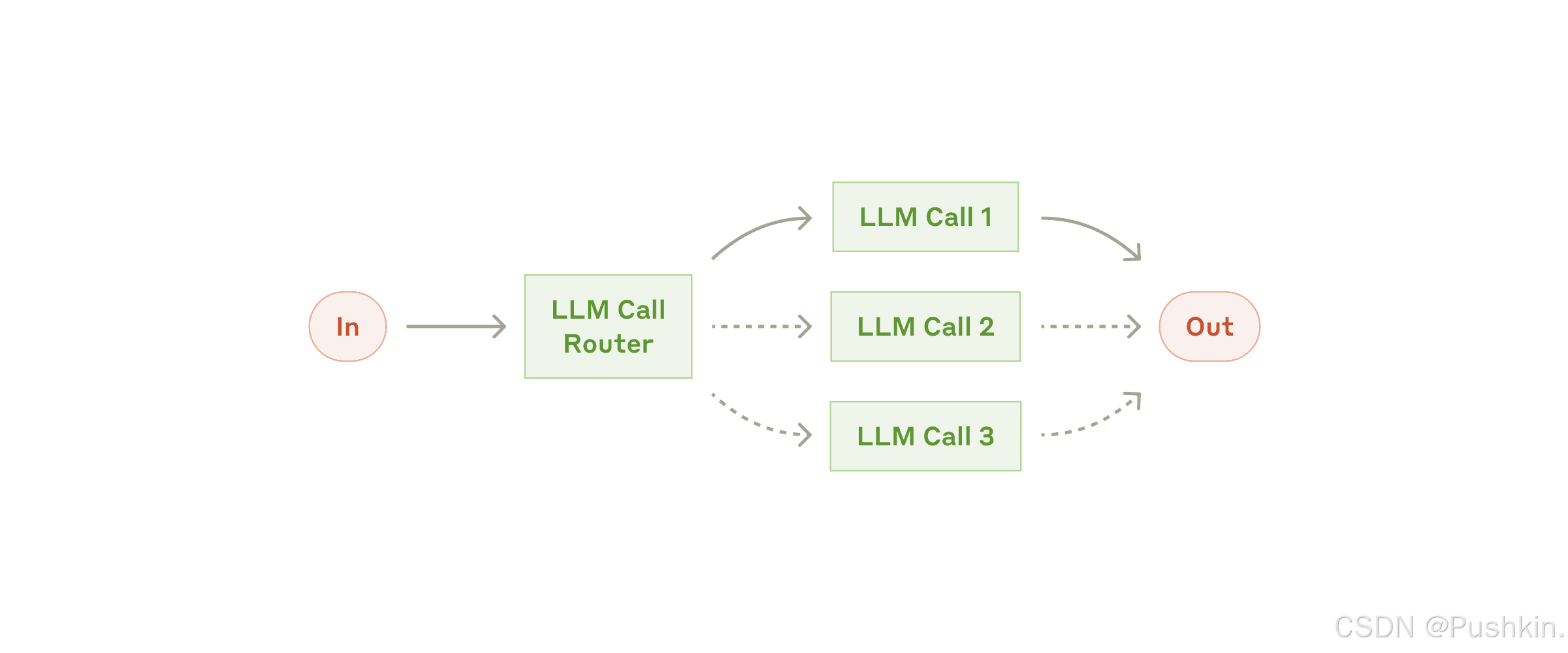
适用场景:
- ✅ 不同类型的输入需要不同的处理策略
- ✅ 分类相对简单,但每个类别的处理很复杂
- ✅ 并行化可以提高效率
实际案例:
- 客服系统:将客户查询分类为技术问题、账单问题、一般咨询等
- 内容处理:根据文档类型选择不同的处理管道
优势:
- 解耦关注点
- 允许优化和独立维护每个分支
- 提高整体系统的可扩展性
4.4 Workflow 模式 3:Parallelization(并行化)
原理:将任务分解为独立的子任务,并行执行以提高效率或提供不同视角。
两种主要形式:
形式 1: Section Parallelization(分段并行)
输入 → ┬→ LLM(部分1) ─┐
├→ LLM(部分2) ─┤→ 合并 → 最终输出
└→ LLM(部分3) ─┘
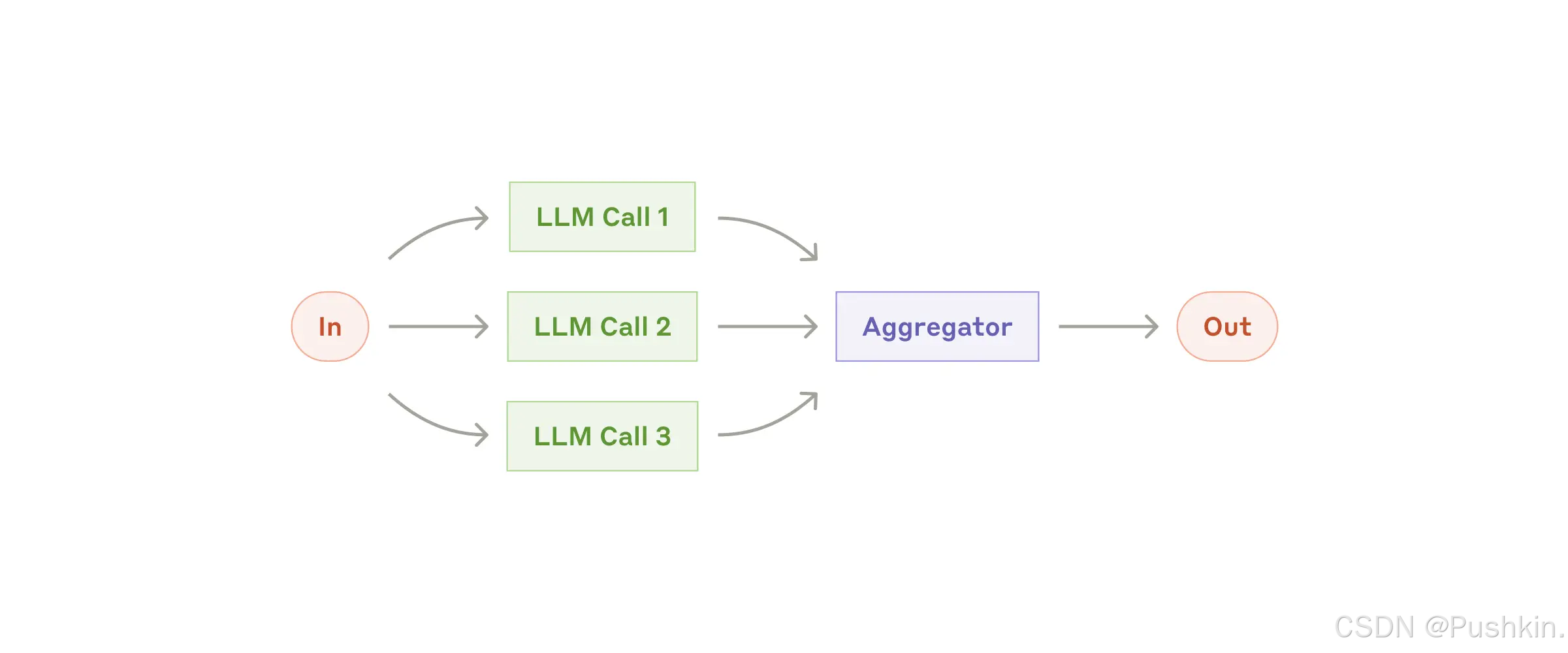
适用场景:
- 大型文档的不同部分可以独立处理
- 各部分之间依赖性较低
形式 2: Multiple Perspectives(多视角)
问题 → ┬→ LLM(视角A: 乐观分析)
├→ LLM(视角B: 悲观分析)
└→ LLM(视角C: 中立评估) → 综合报告
适用场景:
- 需要从多个角度评估同一个问题
- 决策制定需要全面考虑
实际案例:
- 代码审查:同时运行多个静态分析工具
- 投资分析:同时生成看涨、看跌和中立的报告
4.5 Workflow 模式 4: Orchestrator-Workers(编排者-工作者)
原理:中央"编排者" LLM 将任务分解并分配给"工作者" LLM,然后综合结果。
架构图示:
用户请求 → Orchestrator(LLM) → ┬→ Worker1(LLM): 子任务1
├→ Worker2(LLM): 子任务2
└→ WorkerN(LLM): 子任务N
↓
Orchestrator 综合所有结果 → 最终响应
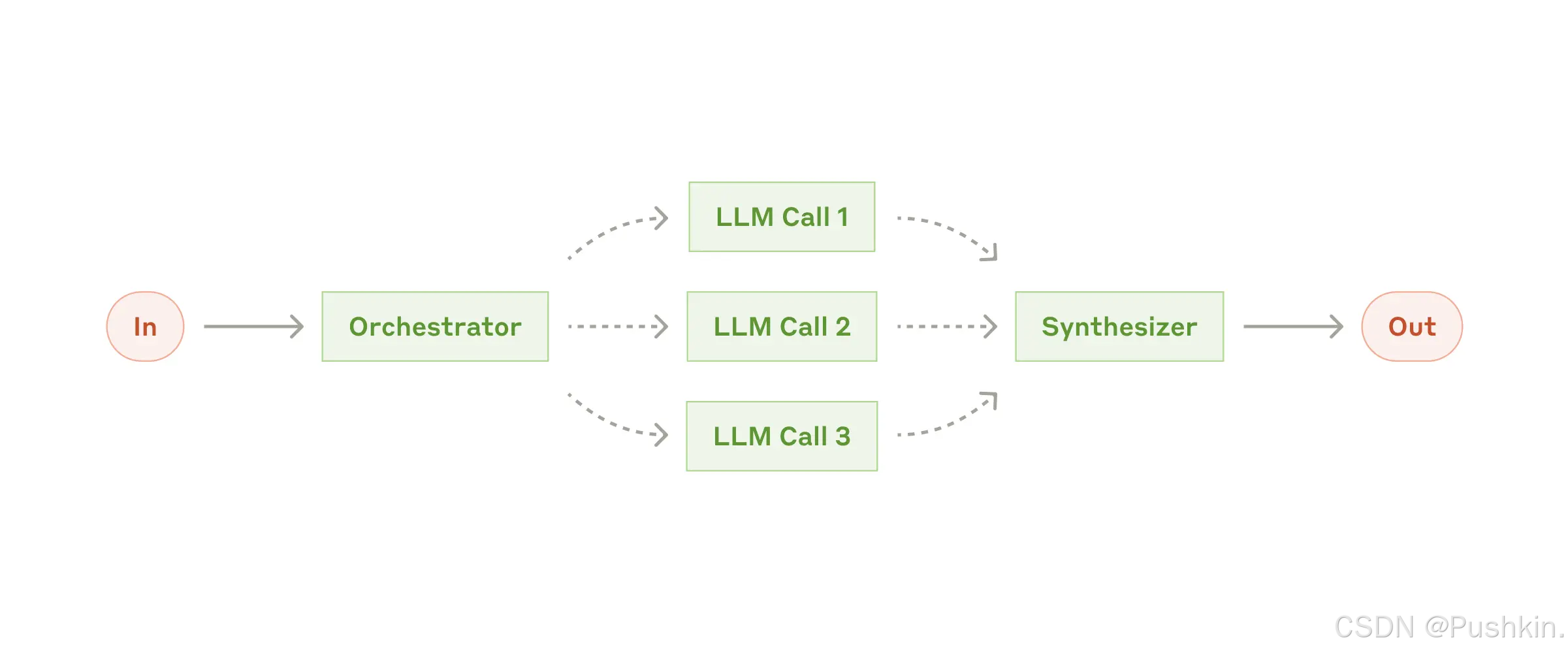
关键特点:
- 动态任务分解:编排者决定如何拆分任务
- 灵活的工作者数量:可以根据任务复杂度调整
- 质量保证:编排者负责最终输出的质量和一致性
适用场景:
- ✅ 任务复杂且无法预先确定最佳分解方式
- ✅ 子任务之间的相互依赖性低
- ✅ 各部分的并行处理能显著提高速度
实际案例:
- 研究报告生成:编排者将研究主题分解为多个子课题,每个工作者研究一个方面
- 代码生成:编排者设计架构,工作者实现具体功能模块
优化建议:
- 为工作者提供详细的上下文和指令
- 实施中间检查点以确保质量
- 考虑使用不同的模型配置给不同的工作者(例如,简单任务用更快/更便宜的模型)
4.6 Workflow 模式 5: Evaluator-Optimizer(评估器-优化器)
原理:一个 LLM 生成初始输出,另一个 LLM 评估并提供反馈,循环迭代直到达到质量阈值。
架构图示:
初始请求 → Generator(LLM) → 初始输出
↓
Evaluator(LLM) ← 反馈
↓
达到质量标准?──否──→ Generator(LLM) → 改进版本
│ ↓
是 再次评估...
↓
最终高质量输出
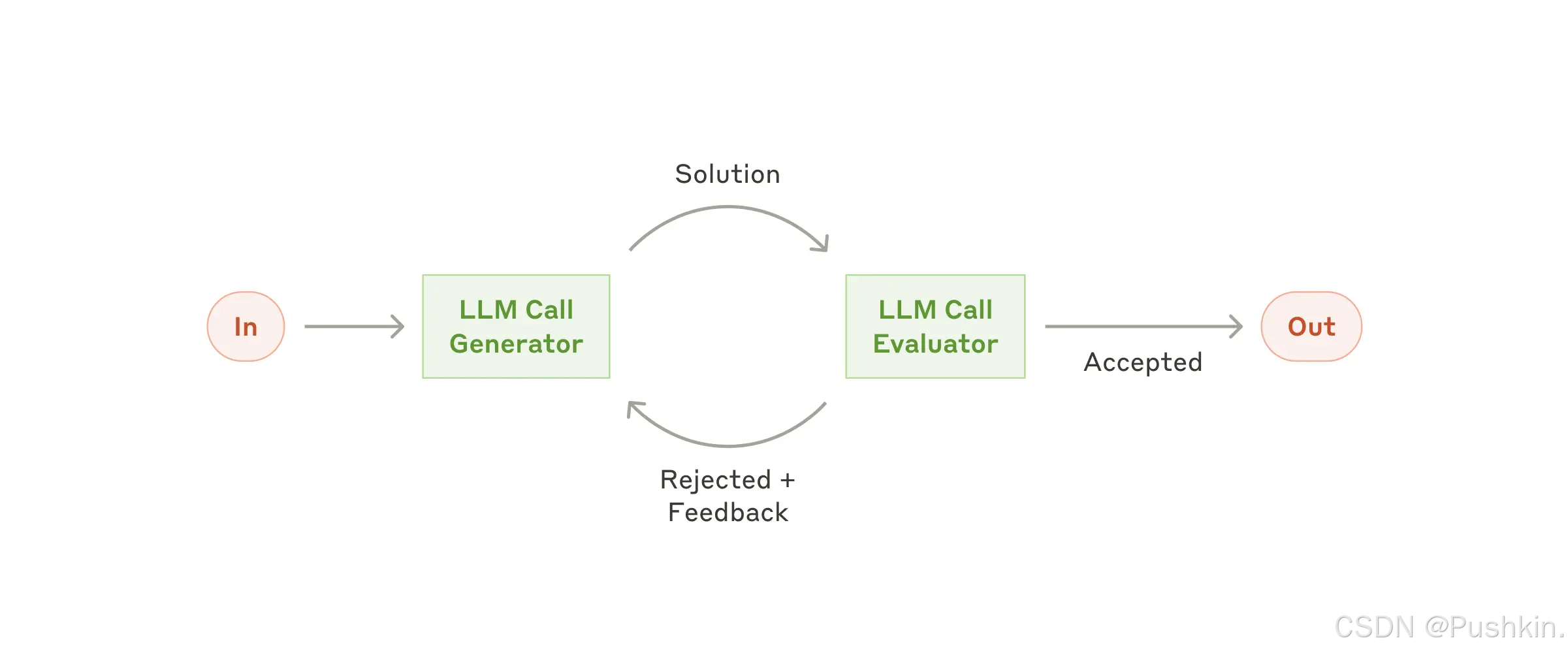
关键组件:
-
Generator(生成器):
- 产生初始输出
- 根据反馈进行改进
-
Evaluator(评估器):
- 提供结构化的批评和建议
- 检查是否满足预设的质量标准
适用场景:
- ✅ 输出质量要求极高
- ✅ 明确的评估标准存在
- ✅ 迭代改进的成本低于一次性完美的成本
实际案例:
- 文章写作:先生成初稿,再反复修改直到满足出版标准
- 代码生成:编写代码,然后进行多次审查和重构
实施注意事项:
- 设置最大迭代次数以避免无限循环
- 定义明确的停止条件
- 平衡质量提升与计算成本
五、Agent 设计模式
5.1 何时从 Workflow 升级到 Agent?
升级条件:
- 高度不确定性:无法预定义所有可能的执行路径
- 需要自主决策:系统需要在运行时做出复杂的选择
- 长期运行:任务跨越多个会话或长时间周期
- 工具使用复杂:需要动态选择和组合多种工具
- 外部交互频繁:与多个外部系统/API 进行复杂交互
5.2 核心 Agent 架构
┌─────────────────────────────────────────┐
│ Agent Core │
│ │
│ ┌─────────┐ ┌──────────────────┐ │
│ │ Planner │───→│ Task Decomposer │ │
│ └────┬─────┘ └────────┬─────────┘ │
│ │ │ │
│ ▼ ▼ │
│ ┌─────────┐ ┌──────────────────┐ │
│ │ Memory │ │ Tool Selector │ │
│ └────┬─────┘ └────────┬─────────┘ │
│ │ │ │
│ ▼ ▼ │
│ ┌──────────────────────────────────┐ │
│ │ Execution & Monitoring │ │
│ └──────────────────────────────────┘ │
└─────────────────────────────────────────┘
核心组件:
-
Planner(规划器):
- 制定高层行动计划
- 设定目标和里程碑
-
Task Decomposer(任务分解器):
- 将复杂任务分解为可执行的子任务
- 确定任务优先级和依赖关系
-
Memory(记忆系统):
- 短期记忆:当前上下文和正在进行的工作
- 长期记忆:历史经验和学到的知识
-
Tool Selector(工具选择器):
- 分析可用工具的能力
- 为每个子任务选择最合适的工具
-
Execution & Monitoring(执行与监控):
- 执行计划中的步骤
- 监控进度并根据情况调整
5.3 Agent 的关键设计原则
原则 1: 明确的边界和约束
# 好的实践:定义清晰的权限范围
class AgentConstraints:
max_actions_per_task = 10
allowed_tools = ["search", "read", "write"]
forbidden_domains = ["personal_data", "financial_transactions"]
requires_human_approval_for = ["delete", "send_email", "make_purchases"]
为什么重要:
- 防止 Agent 越权操作
- 降低安全风险
- 使行为可预测和可审计
原则 2: 优雅的错误处理
必须考虑的失败场景:
- API 调用失败
- 工具不可用
- 数据格式错误
- 权限不足
- 网络中断
应对策略:
- 重试机制:对于临时性故障
- 降级方案:当主要工具不可用时使用替代方案
- 人工介入:当自动恢复不可能时请求帮助
- 状态保存:定期保存进度以便从中断处恢复
原则 3: 可观测性和调试能力
必需的实现:
- 详细的日志记录(包括决策过程)
- 中间结果的快照
- 性能指标收集
- 用户友好的状态展示
推荐的监控维度:
- 任务完成时间
- 工具使用频率和成功率
- 错误率和类型分布
- 资源消耗(token 使用量、API 调用次数)
六、最佳实践总结
6.1 设计阶段
- 从简单开始:先用最基本的方案验证可行性
- 明确需求:清楚知道什么情况下需要 Agent,什么时候 Workflow 就够了
- 设计接口:为每个组件定义清晰的输入输出规范
- 规划测试:从一开始就考虑如何测试和验证
6.2 开发阶段
- 模块化实现:每个组件应该可以独立开发和测试
- 渐进式集成:先让各部分单独工作,再逐步连接
- 持续验证:每一步都要验证是否符合预期
- 保持透明:记录所有的设计和决策理由
6.3 部署阶段
- 灰度发布:先在小范围内测试
- 监控一切:建立全面的监控系统
- 准备回滚:确保可以快速回到之前的稳定版本
- 收集反馈:主动向用户收集使用体验
6.4 维护阶段
- 定期评估:持续评估性能和效果
- 更新知识:随着时间推移更新工具和模型的知识
- 优化效率:寻找减少延迟和成本的机会
- 安全审计:定期检查安全性
七、实际应用案例(附录精华)
案例 1: 编码助手
挑战:帮助开发者完成复杂的编码任务
解决方案:
- 使用 Orchestrator-Workers 模式
- Orchestrator 理解需求并分解任务
- Workers 分别负责:设计、编码、测试、文档
成果:
- 显著提高开发效率
- 代码质量更一致
- 减少了重复劳动
案例 2: 客户服务自动化
挑战:处理多样化的客户咨询
解决方案:
- 结合 Routing 和 Agent 模式
- Router 将查询分类到正确的处理队列
- 每个 Agent 专门处理一类问题,具有深度领域知识
成果:
- 响应时间大幅缩短
- 解决率提高
- 客户满意度上升
案例 3: 研究与分析
挑战:快速生成全面的研究报告
解决方案:
- 采用 Evaluator-Optimizer 循环
- 多个研究 Agent 并行收集信息
- 主 Agent 整合并优化最终报告
成果:
- 研究时间从数天缩短到数小时
- 覆盖面更广,遗漏更少
- 质量经过多轮验证
八、常见陷阱与避免方法
陷阱 1: 过度工程化
症状:
- 在简单问题上使用复杂的 Agent 系统
- 引入不必要的抽象层
- 过度依赖框架而忽略基础理解
避免方法:
- 始终问自己:“这是否真的需要?”
- 从最简单的解决方案开始
- 确保理解每一层抽象的作用
陷阱 2: 忽视成本
症状:
- 没有监控 token 使用量
- 使用过于强大的模型处理简单任务
- 缺乏缓存和重用机制
避免方法:
- 建立成本追踪系统
- 根据任务复杂度选择合适的模型
- 实施智能缓存策略
陷阱 3: 缺乏人机协作
症状:
- Agent 完全自主运行无监督
- 没有紧急停止机制
- 用户无法干预或纠正
避免方法:
- 设计明确的人机交互点
- 实施审批流程(特别是高风险操作)
- 提供直观的状态展示和控制界面
陷阱 4: 测试不足
症状:
- 只在理想条件下测试
- 缺乏边缘情况的覆盖
- 没有自动化测试套件
避免方法:
- 设计全面的测试场景(正常、异常、极端)
- 实施自动化回归测试
- 定期进行红队测试和安全审计
九、核心要点回顾
要记住的关键教训
- 简洁胜于复杂:大多数成功的实现都使用简单的模式
- Workflows vs Agents:根据任务特性选择合适的架构
- 直接使用 API:除非必要,否则不要引入框架层
- 渐进式发展:从基本构建块开始,按需增加复杂性
- 重视可观测性:良好的监控和日志至关重要
- 设计安全边界:始终考虑安全和权限控制
- 以人为本:即使是最自主的系统也需要人类监督
决策流程图
开始
↓
任务是否明确且固定? ──是──→ 使用 Prompt Chaining 或 Routing
↓否
是否需要并行处理? ──是──→ 使用 Parallelization
↓否
是否能预定义子任务? ──是──→ 使用 Orchestrator-Workers
↓否
是否有明确的质量标准? ──是──→ 使用 Evaluator-Optimizer
↓否
需要高度自主性和适应性? ──是──→ 使用完整 Agent 架构
↓否
重新审视:是否真的需要 LLM?也许传统编程就够了
十、未来展望
发展趋势
- 更强的工具整合:Model Context Protocol (MCP) 等标准的普及
- 更好的记忆系统:长期记忆和知识管理能力的提升
- 多模态扩展:文本之外的图像、音频、视频处理能力
- 协作式 Agent:多个 Agent 协同工作的标准化协议
- 个性化适应:根据用户习惯和偏好自动调整行为
待解决的问题
- 可靠性保证:如何在关键应用中确保 Agent 的可靠性和一致性
- 可解释性:让 Agent 的决策过程对人类来说更透明
- 安全性强化:防止恶意使用和意外伤害
- 效率优化:降低延迟和成本的同时保持或提高质量
- 伦理框架:建立负责任的 AI Agent 开发和使用准则
十一、我的思考与启示
1. 关于"简洁性"哲学的深刻认同
这篇论文最打动我的核心理念是:“最成功的实现并非使用复杂的框架,而是采用简单、可组合的模式”。这完全符合软件工程中的 KISS 原则(Keep It Simple, Stupid),但在 AI 领域往往被忽视。
个人反思:
在实际项目中,我们经常看到一种倾向——为了展示技术实力或追求"先进性",过早地引入复杂的 Agent 框架和多智能体系统。然而,Anthropic 的经验表明,许多场景下,几个精心设计的 LLM API 调用加上合理的 RAG 策略就足够了。
实践建议:
在开始任何新项目前,我应该先问自己三个问题:
- 这个问题能否用一次优化的 LLM 调用解决?
- 如果不能,能否用简单的 Workflow(如 Prompt Chaining)解决?
- 只有在前两个答案都是"否"时,才考虑完整的 Agent 架构。
2. Workflows vs Agents 的二元分类非常有价值
这个分类框架为我提供了一个清晰的决策工具。以前我在设计系统时经常模糊不清,不知道该用哪种架构。现在有了明确的判断标准:
Workflows 适合的场景:
- 流程相对固定(如数据处理管道)
- 需要高可预测性和一致性(如财务报表生成)
- 性能和延迟敏感(如实时客服)
Agents 适合的场景:
- 探索性研究(如市场调研)
- 创意性任务(如内容创作)
- 需要适应不断变化的环境(如个人助理)
启发:我应该建立一个内部的决策树,帮助团队在选择架构时有据可依。
3. 对框架使用的审慎态度值得学习
Anthropic 对框架的建议非常务实:“直接使用 LLM API…如果使用框架,确保理解底层代码”。这与我的实践经验高度吻合。
观察到的现象:
很多开发者(包括我自己有时)会陷入"框架崇拜",认为使用了最新的框架就能获得最好的结果。但实际上:
- 框架增加了抽象层,使调试困难
- 框架的设计假设可能与你的具体场景不匹配
- 学习框架本身的成本往往被低估
新的工作方式:
我打算在未来项目中采用以下策略:
- 先用原生 API 实现最小可行产品(MVP)
- 当且仅当出现明显的重复模式时,才考虑引入轻量级的抽象
- 即使使用框架,也要保持对底层机制的清晰理解
4. Evaluator-Optimizer 模式的创新价值
这个模式给我带来了新的启发。传统的软件开发中,我们通常采用"写完-测试-修复"的线性流程。但 Evaluator-Optimizer 模式将其变成了持续的迭代改进循环。
潜在应用场景:
- 代码生成:生成代码 → 静态分析 → 改进 → 再分析…
- 文案创作:初稿 → A/B 测试数据反馈 → 优化版本…
- 翻译工作:机器翻译 → 人工评分微调 → 再翻译…
深入思考:
这个模式实际上模拟了人类专家的工作方式——我们也是通过不断的自我评估和改进来提升产出质量的。将这种元认知能力赋予 AI 系统,是一个很有前景的方向。
5. 安全性和可控性是不可妥协的底线
论文强调的安全边界设计让我意识到:随着 Agent 能力的增强,对其约束的需求也在同步增长。
关键认识:
- 自主性越强,需要的护栏越多
- 透明的日志和监控不是可选的,而是必需的
- 人工审批机制应该在设计阶段就内置,而不是事后补充
行动项:
在我未来的 Agent 项目中,我会确保:
- 每个都有明确的权限清单(白名单比黑名单更好)
- 所有关键操作都有审计轨迹
- 有明确的"紧急停止"按钮
- 定期进行安全审查和压力测试
6. 对未来发展的期待与担忧
期待的方面:
- MCP (Model Context Protocol) 这样的标准化努力可能会极大地促进生态繁荣
- 更好的记忆系统将使 Agent 能够真正地从经验中学习
- 多 Agent 协作的标准协议将开启全新的应用可能性
担忧的方面:
- 过度自主的 Agent 可能被恶意利用
- 成本和环境影响可能会限制大规模部署
- 人类可能会过度依赖 Agent 而丧失关键技能
平衡的观点:
我认为关键是找到辅助而非替代的平衡点。Agent 应该是人类能力的放大器,而不是替代品。好的 Agent 设计应该让人类做更有价值的创造性工作,而不是完全接管。
参考资源
- Anthropic Cookbook - 实现示例
- Model Context Protocol - 第三方工具集成标准
- Claude Documentation - 官方 API 文档
总结
《Building Effective Agents》是一篇兼具理论深度和实践指导价值的优秀文章。它没有推销复杂的概念或专有技术,而是回归本质,强调简洁性、实用性和渐进式发展的原则。
对我而言,最大的收获是建立了一个清晰的思维框架来评估和选择 AI 系统架构。在这个框架的指导下,我可以更有信心地做出技术决策,避免过度工程化,专注于真正创造用户价值。
正如文中所言:“When building applications with LLMs, we recommend finding the simplest solution possible, and only increasing complexity when needed.” 这句话应该成为每一个 AI 应用开发者的座右铭。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)