OpenAI 模型 API 基础
文章目录
OpenAI 模型 API 基础
1. 发送你对GPT模型的第一个请求
首先,确保已安装 OpenAI Python 库:
pip install openai
1.1 最简单的调用方式
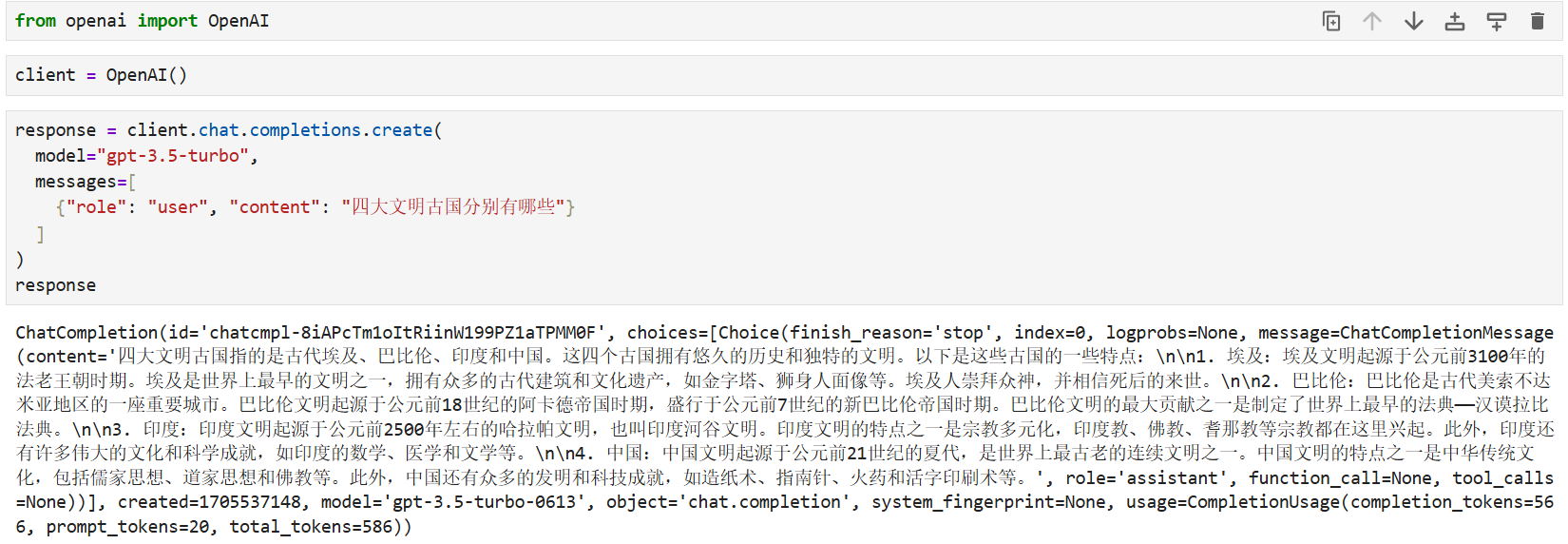
from openai import OpenAI
# 初始化客户端(会自动读取环境变量 OPENAI_API_KEY)
client = OpenAI()
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": "四大文明古国分别有哪些"}
]
)
print(response.choices[0].message.content)
运行结果示例
四大文明古国指的是古代埃及、巴比伦、印度和中国。这四个古国拥有悠久的历史和独特的文明。以下是这些古国的一些特点:
1. 埃及:埃及文明起源于公元前3100年的法老王朝时期。埃及是世界上最早的文明之一,拥有众多的古代建筑和文化遗产,如金字塔、狮身人面像等。
2. 巴比伦:巴比伦是古代美索不达米亚地区的一座重要城市。巴比伦文明的最大贡献之一是制定了世界上最早的法典——汉谟拉比法典。
3. 印度:印度文明起源于公元前2500年左右的哈拉帕文明,印度教、佛教、耆那教等宗教都在这里兴起。
4. 中国:中国文明起源于公元前21世纪的夏代,是世界上最古老的连续文明之一,拥有造纸术、指南针、火药等伟大发明。
1.2 多轮对话(带上下文)
如果需要维持对话历史,可以将之前的对话内容传入 messages 数组:
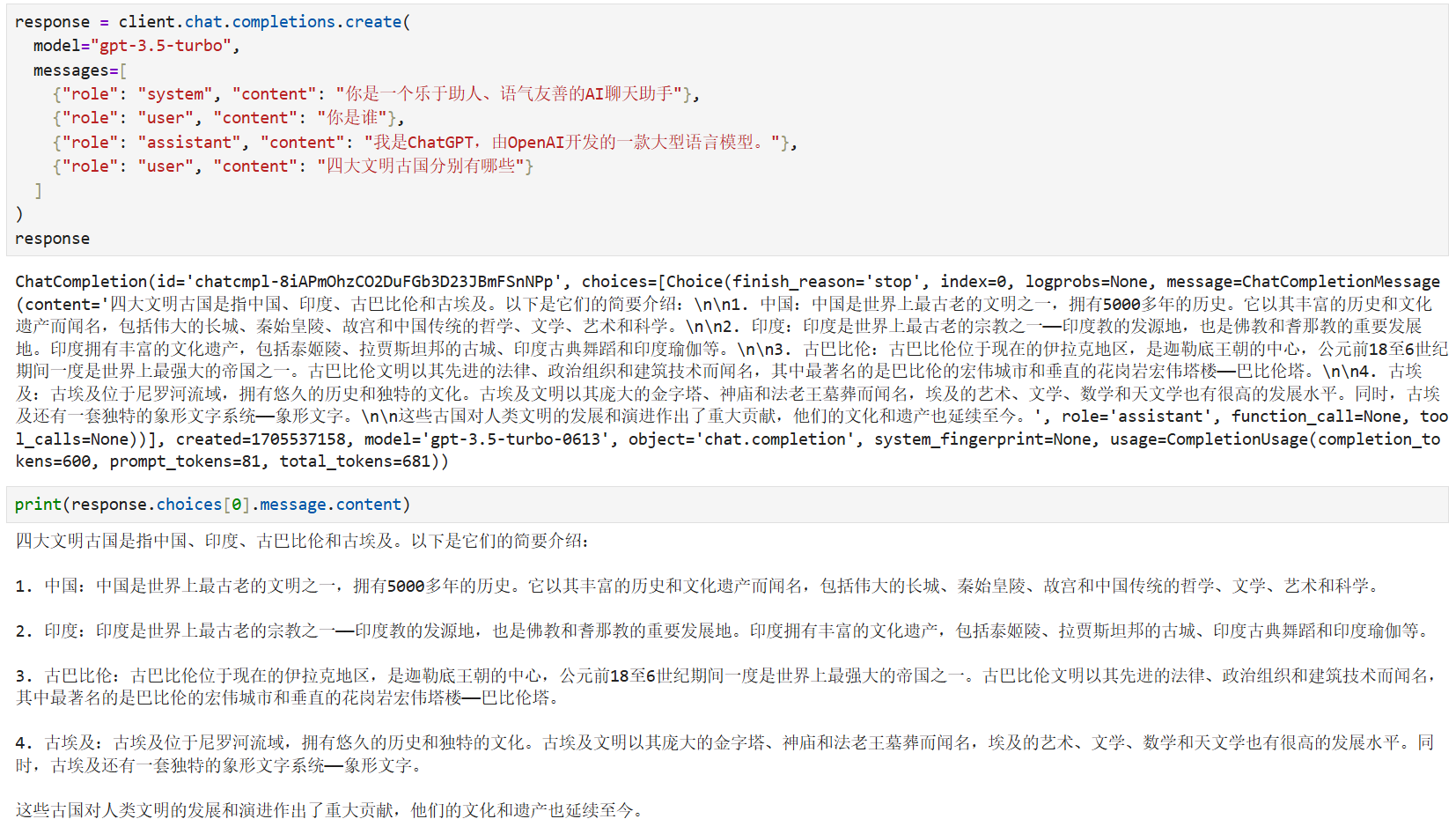
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "你是一个乐于助人、语气友善的AI聊天助手"}, # 设定AI的性格
{"role": "user", "content": "你是谁"}, # 用户之前问过的问题
{"role": "assistant", "content": "我是ChatGPT,由OpenAI开发..."}, # AI之前回答的内容
{"role": "user", "content": "四大文明古国分别有哪些"} # 用户现在问的问题
]
)
print(response.choices[0].message.content)
1.2.1 参数说明
| 参数 | 说明 |
|---|---|
| model | 使用的模型名称,如 gpt-3.5-turbo、gpt-4 等 |
| messages | 对话消息列表,每条消息包含 role 和 content |
| role | 角色类型:system(系统设定)、user(用户)、assistant(助手) |
| content | 消息内容 |
1.2.2 返回对象结构
response 返回的是一个 ChatCompletion 对象,主要包含:
ChatCompletion(
id='chatcmpl-xxx', # 唯一请求ID
choices=[ # 回复选项列表
Choice(
finish_reason='stop', # 结束原因:stop/length/content_filter等
index=0,
message=ChatCompletionMessage(
content='回复内容...',
role='assistant'
)
)
]
)
1.2.3 提取回复内容
# 标准方式
reply = response.choices[0].message.content
print(reply)
1.3 常见问题
1.3.1 API Key 设置
推荐使用环境变量:
import os
from openai import OpenAI
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
在代码中直接设置(不推荐):你的api可以被别人使用
client = OpenAI(api_key="xxxxxxxxxxxxxxxxxxxxxxxx")
2. 大模型API GPT模型咋收费?必了解的token计数
2.1 什么是 Token?
在使用 OpenAI API 时,你需要了解一个核心概念:Token。
简单来说,Token 是 AI 处理文本的基本单位。它不完全是“字”,也不完全是“词”,而是一种介于两者之间的切分方式。
2.1.1 Token 的规则
- 英文:通常一个单词约等于 1-2 个 Token
- 中文:一个汉字通常等于 1-2 个 Token
- 空格和标点:也会占用 Token
2.2 为什么需要计算 Token?
使用 OpenAI API 时,费用是按照 Token 数量 来计算的:
- 输入 Token:你发送给 AI 的消息
- 输出 Token:AI 返回给你的回答
了解 Token 数量可以帮助你:
- 控制 API 使用成本
- 避免超出模型的最大 Token 限制
- 优化提示词长度
2.3 如何计算 Token?
OpenAI 提供了一个名为 tiktoken 的工具库,可以精确计算 Token 数量。
2.3.1 安装 tiktoken
pip install tiktoken
2.4 基础用法
import tiktoken
# 获取指定模型的编码器
encoding = tiktoken.encoding_for_model("gpt-3.5-turbo")
# 查看编码器名称
print(encoding)
# 输出:<Encoding 'c1100k_base'>
2.5 将文本转换为 Token
# 将文本编码为 Token 数组
text = "黄河之水天上来"
tokens = encoding.encode(text)
print(tokens)
# 输出:[30868, 226, 31106, 111, 55030, 53610, 36827, 17905, 37507]
- 这些数字代表Token ID,包含 9 个 Token
2.6 计算 Token 数量
# 方法一:获取编码后的长度
token_count = len(encoding.encode(text))
print(token_count) # 输出:9
# 方法二:直接使用 encode 方法后取长度
tokens = encoding.encode(text)
token_count = len(tokens)
print(f"'{text}' 包含 {token_count} 个 Token")
# 输出:'黄河之水天上来' 包含 9 个 Token
2.7 费用计算
OpenAI 按 总Token 收费:
- 费用 = (输入Token数 × 输入价格) + (输出Token数 × 输出价格)
每个模型有总Token上限:
- 注意:所有消息的Token总和不能超过这个上限
| 概念 | 含义 | 例子 |
|---|---|---|
| Token个数 | 单条消息的Token数量 | “黄河之水天上来” = 9个Token |
| 总Token | 一次调用中所有Token之和 | 问题9个 + 回答50个 = 59个Token |
调用总tokens示例: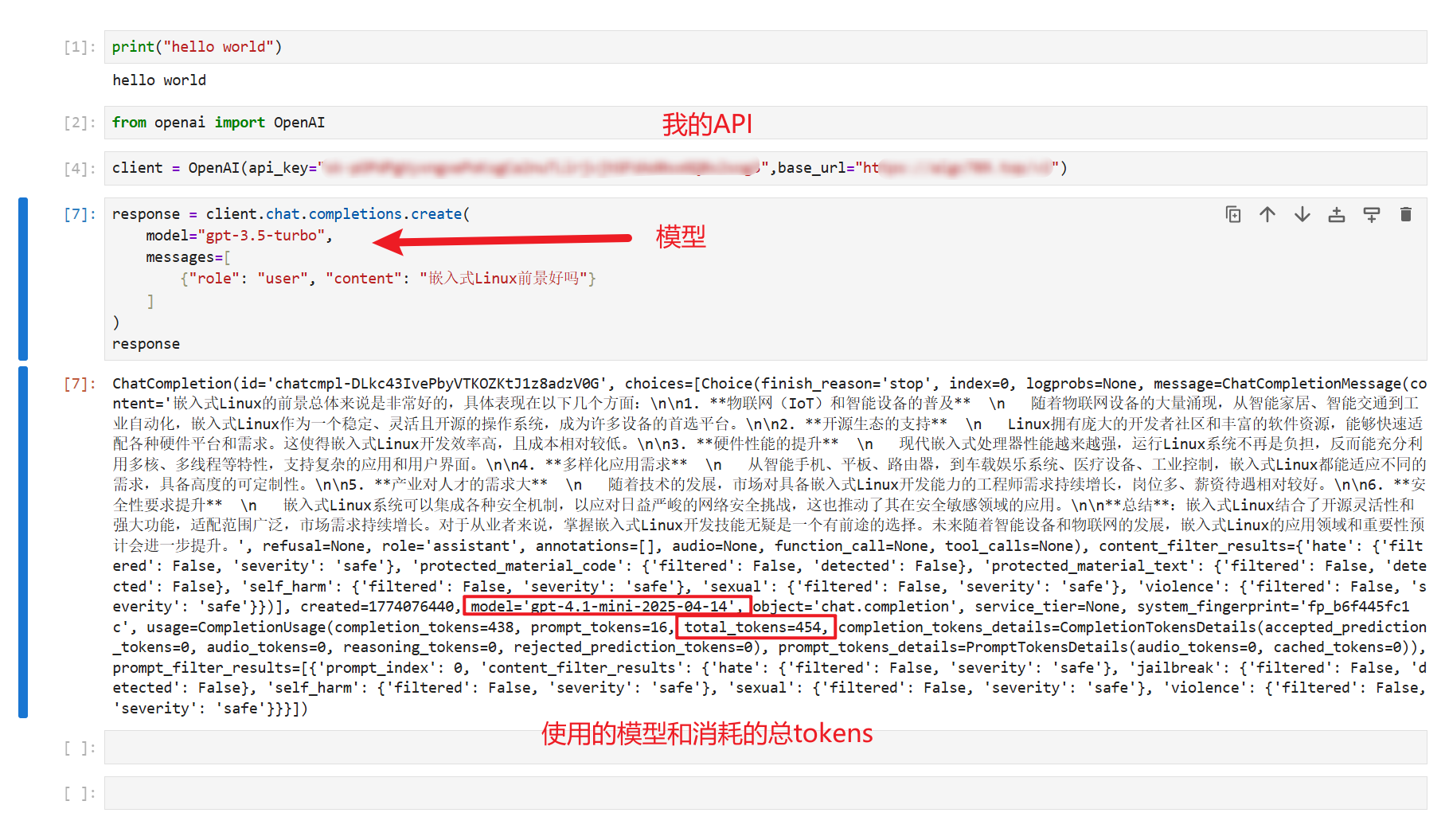
3. 大模型API定制和调整GPT回复的常用参数
在使用 OpenAI API 时,除了 model 和 messages 这两个必填参数外,还有四个重要的可选参数可以控制 AI 的回复行为,分别是max_tokens、temperature、top_p 和 frequency_penalty。
3.1 max_tokens:控制回复长度
3.1.1 作用
max_tokens 用于限制 AI 回复的最大 Token 数量。就像给 AI 规定了一个“字数上限”,超过这个长度就会被截断。
3.1.2 代码示例
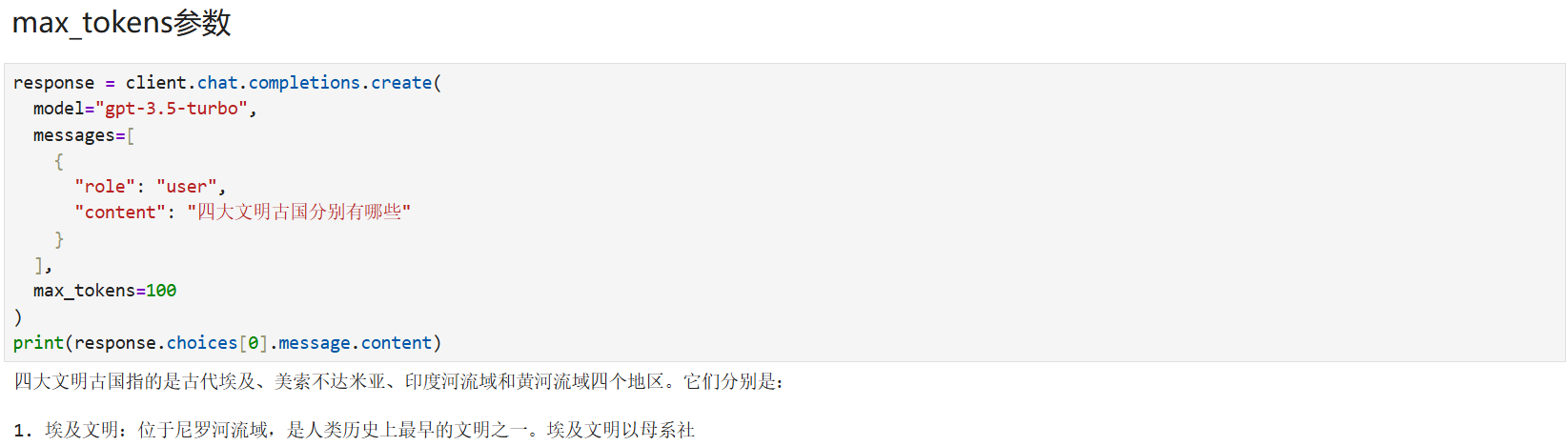
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{
"role": "user",
"content": "四大文明古国分别有哪些"
}
],
max_tokens=100 # 限制回复最多100个Token
)
print(response.choices[0].message.content)
运行结果:超过长度被截断
四大文明古国指的是古代埃及、美索不达米亚、印度河流域和黄河流域四个地区。它们分别是:
1. 埃及文明:位于尼罗河流域,是人类历史上最早的文明之一。埃及文明以母系社
3.1.3 参数详解
| 参数值 | 效果 | 说明 |
|---|---|---|
| 不设置 | AI 可以回复任意长度 | 受模型上限限制 |
| 设置较小值(如 50) | 回复可能被截断 | 信息可能不完整 |
| 设置较大值(如 1000) | AI 可以回复较长内容 | 适合详细回答 |
3.1.4 注意事项
- max_tokens 限制的是 AI 回复的 Token 数,不包括你的输入
- 不同模型的最大 Token 限制不同
3.2 temperature:控制创造性
3.2.1 作用
temperature 控制 AI 回答的 创造性程度。值越高,回答越多样化、越有创意;值越低,回答越保守、越确定。
3.2.2 取值范围
- 0 到 2 之间的浮点数
- 默认值:1
3.2.3 代码示例:temperature = 2(高创造性)
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{
"role": "user",
"content": "四大文明古国分别有哪些"
}
],
max_tokens=100,
temperature=2 # 高创造性
)
print(response.choices[0].message.content)
运行结果:
四大文明古国分别是:古代埃及文明、幼发拉底河流域文明古印度同时票角utenberg SouthEurope MarystreamsJapan modeling forecast TclwaDavis sidl Kenn nobern
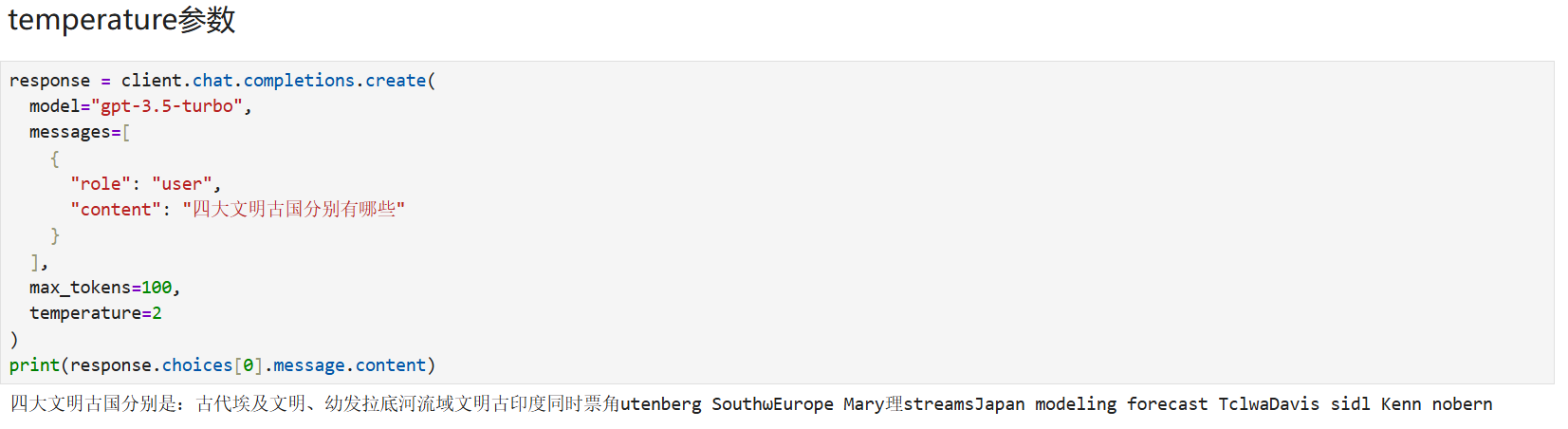
现象:
- 当 temperature 过高时,AI 的回答可能变得混乱,甚至出现乱码或无意义的词语。
3.2.4 temperature 值对比
| temperature 值 | 效果 | 适用场景 |
|---|---|---|
| 0 - 0.3 | 回答稳定、保守,每次基本一样 | 事实问答、代码生成、客服回复 |
| 0.5 - 0.8 | 回答有一定变化,但总体合理 | 日常对话、一般写作 |
| 1.0 | 默认值,平衡创造性和准确性 | 大多数场景 |
| 1.5 - 2.0 | 回答非常多样,可能出错或混乱 | 创意写作、头脑风暴 |
3.3 top_p:控制词汇选择范围
3.3.1 作用
top_p 是一种核采样(Nucleus Sampling) 技术,控制 AI 选择下一个词时的候选范围。
简单理解:AI 在生成每个词时,会先预测所有可能的词及其概率。top_p 决定了只从概率之和达到 p 的最有可能的词中选择。
3.3.2 取值范围
- 0 到 1 之间的浮点数
- 默认值:1
3.3.3 代码示例:top_p = 0.4(较小范围)
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{
"role": "user",
"content": "四大文明古国分别有哪些"
}
],
max_tokens=300,
top_p=0.4 # 只考虑概率最高的40%的词
)
print(response.choices[0].message.content)
运行结果:
四大文明古国是指古埃及、古巴比伦、古印度和古中国。

现象:
- 当 top_p 较小(如 0.4)时,AI 只从最有可能的几个词中选择,回答非常保守、简洁。
3.3.4 top_p 值对比
| top_p 值 | 效果 | 说明 |
|---|---|---|
| 0.1 | 非常保守,只选最高概率的词 | 回答稳定,可能重复 |
| 0.5 | 中等保守 | 平衡稳定性和多样性 |
| 1.0 | 考虑所有可能的词 | 最大创造性 |
3.3.5 temperature 和 top_p 的关系
这两个参数都控制随机性,但机制不同:
- temperature:调整概率分布的“形状”(拉平或尖锐化)
- top_p:裁剪概率分布,只保留概率最高的部分
建议:一次只调整其中一个参数,不要同时调整两者。
3.4 frequency_penalty:控制词语重复
3.4.1 作用
frequency_penalty 控制 AI 回答中词语的重复程度。正数会惩罚重复出现的词语,鼓励使用新词;负数则会鼓励重复。
3.4.2 取值范围
- -2 到 2 之间的浮点数
- 默认值:0
3.4.3 代码示例 1:frequency_penalty = -2(鼓励重复)
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{
"role": "user",
"content": "生成一个购物清单,包含至少20个物品,每个物品之间用逗号进行分隔,例如:苹果、香蕉、牛奶"
}
],
max_tokens=300,
frequency_penalty=-2 # 鼓励重复
)
print(response.choices[0].message.content)
运行结果(鼓励重复)
苹果、香蕉、牛奶、面包、鸡蛋、洗发水、牛肉、蛋糕、薯片、咖啡、
牛、
......

现象:
- 回答很短,出现了重复的"牛"(“牛肉"和"牛”),没有达到20个物品。
3.4.4 代码示例 2:frequency_penalty = 2(惩罚重复)
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{
"role": "user",
"content": "生成一个购物清单,包含至少20个物品,每个物品之间用逗号进行分隔,例如:苹果、香蕉、牛奶"
}
],
max_tokens=300,
frequency_penalty=2 # 惩罚重复
)
print(response.choices[0].message.content)
运行结果(惩罚重复):
苹果、香蕉、牛奶、面包、鸡蛋、咖啡豆、洗发水、
肥皂、面巾纸、茶叶、巧克力、红酒、
玉米片、米饭、电视机、
手表、手机、笔记本电脑、
运动裤、T恤衫
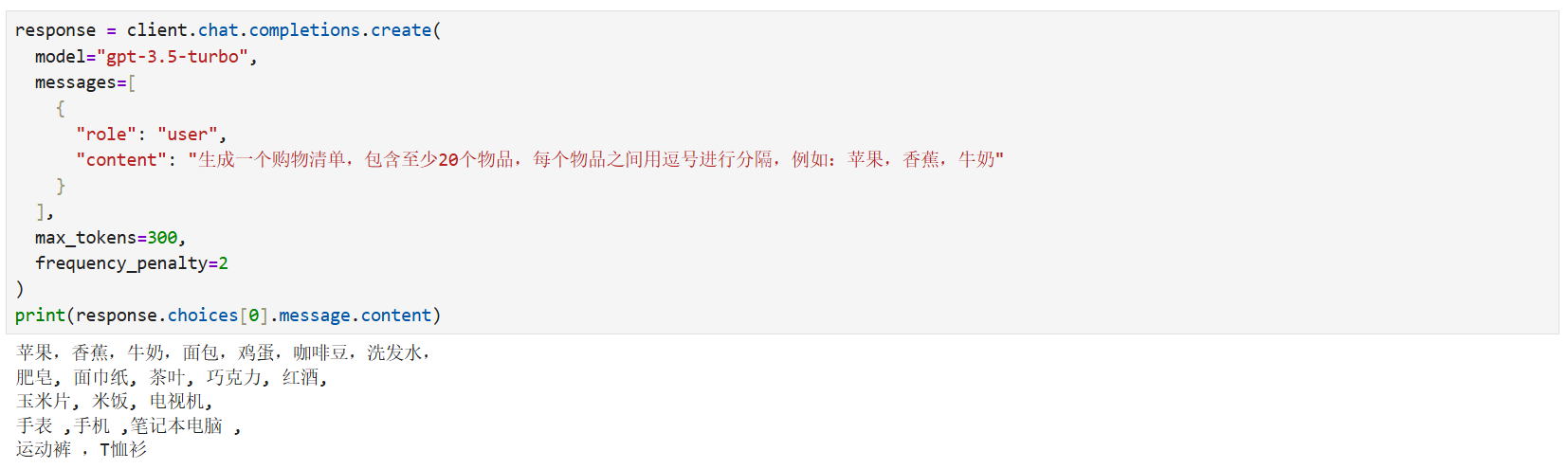
现象:
- 成功生成了20个以上物品,且物品多样,没有重复。
3.4.5 frequency_penalty 值对比
| frequency_penalty | 效果 | 适用场景 |
|---|---|---|
| 负数(-2 到 0) | 鼓励重复 | 想要强调某些概念,或生成重复性内容 |
| 0 | 默认行为 | 大多数情况 |
| 正数(0 到 2) | 惩罚重复,鼓励多样性 | 列表生成、创意写作、避免啰嗦 |
3.5 四个参数对比总结
| 参数 | 作用 | 取值范围 | 默认值 | 值越小效果 | 值越大效果 |
|---|---|---|---|---|---|
| max_tokens | 限制回复长度 | 1 ~ 模型上限 | 无限制 | 回复短 | 回复长 |
| temperature | 控制创造性 | 0 ~ 2 | 1 | 稳定、保守 | 多样、创意(可能混乱) |
| top_p | 控制选择范围 | 0 ~ 1 | 1 | 保守、稳定 | 多样、随机 |
| frequency_penalty | 控制重复 | -2 ~ 2 | 0 | 鼓励重复 | 避免重复 |
3.6 实际应用场景参数推荐
场景一:事实问答(如百科查询)
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": "中国的首都是哪里?"}],
temperature=0, # 稳定准确
top_p=0.5, # 保守选择
max_tokens=100 # 简短回答
)
场景二:创意写作(如写故事)
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": "写一个关于太空冒险的短故事"}],
temperature=1.2, # 高创造性
top_p=0.9, # 多样化选择
max_tokens=500, # 较长内容
frequency_penalty=0.5 # 避免重复用词
)
场景三:列表生成(如购物清单)
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": "列出10种健康食物"}],
temperature=0.5, # 适中创造性
top_p=0.8, # 适当多样
max_tokens=200, # 足够列出10项
frequency_penalty=0.8 # 避免重复
)
场景四:代码生成
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": "用Python写一个冒泡排序"}],
temperature=0, # 精确稳定
max_tokens=500 # 足够生成代码
)
3.7 常见问题与注意事项
-
temperature 和 top_p 同时使用会怎样?
- 同时使用会使随机性控制变得复杂。建议一次只调整其中一个参数。
-
为什么我的回答被截断了?
- 可能是 max_tokens 设置太小,或者模型的 Token 上限已达到。
-
frequency_penalty 和 presence_penalty 有什么区别?
- frequency_penalty:根据词的出现频率惩罚
- presence_penalty:只要词出现过就惩罚,与频率无关
-
参数设置会影响费用吗?
- 会的!max_tokens 直接影响输出长度,从而影响费用。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 12
12 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)