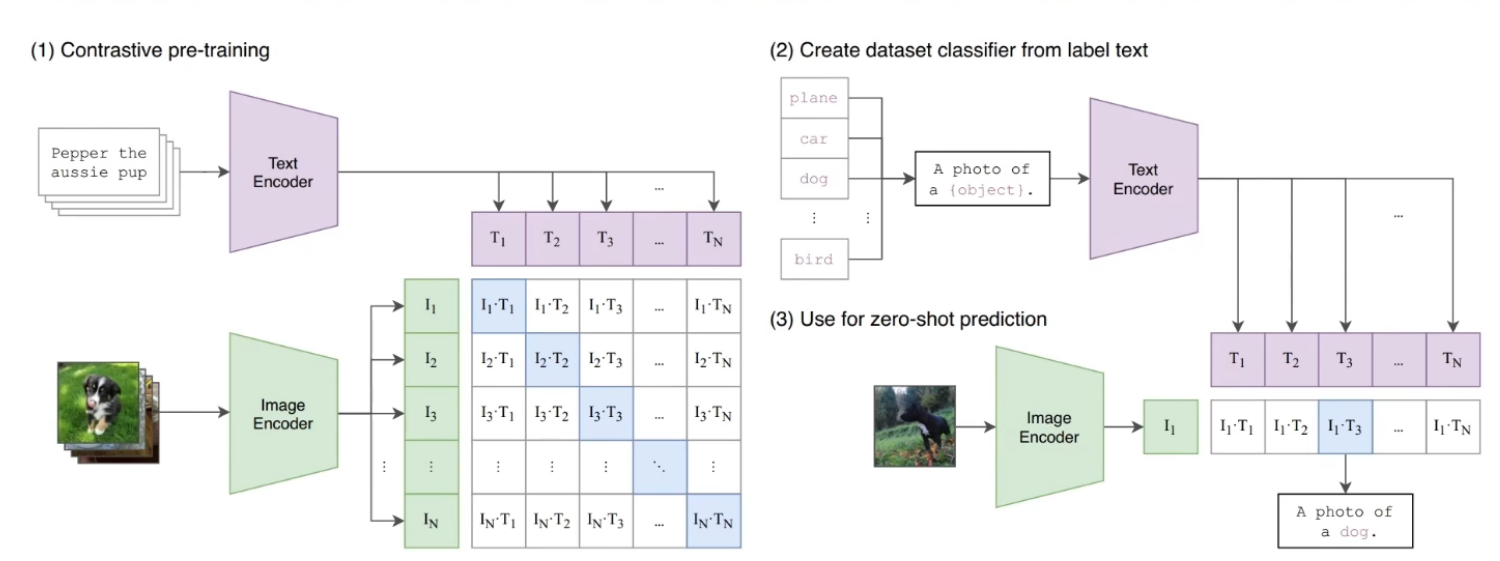
CLIP (Contrastive Language-Image Pre-training) 学习
1. 核心思想与研究动机
传统的计算机视觉模型(如基于 ImageNet 预训练的模型)依赖于预先定义好的固定类别(Closed-set)和密集的人工标注。一旦遇到训练集以外的类别,模型便无法识别。 CLIP 的核心贡献在于打破了固定标签的限制,通过引入自然语言作为监督信号,在海量(4亿)的“图像-文本对”上进行跨模态对比学习(Contrastive Learning)。这使得 CLIP 将图像和文本映射到了同一个共享的特征空间中,从而具备了极其强大的 Zero-Shot(零样本) 泛化能力。
2. 模型架构设计
CLIP 的结构非常简洁对称,由双流(Two-Stream)编码器组成:
-
Image Encoder (图像编码器): 负责提取图像的全局特征表示。CLIP 论文中探索了两种架构:
-
修改版的 ResNet(如 ResNet-50, ResNet-101 以及引入 Attention Pooling 的 ResNet-50x4 等)。
-
Vision Transformer (ViT),将图像切分为 Patch 序列进行处理。
-
-
Text Encoder (文本编码器): 负责提取文本的特征表示。
-
采用基于 Transformer 的架构(类似于 GPT-2),使用 Byte Pair Encoding (BPE) 对文本进行 Tokenize。
-
文本序列的最大长度限制为 76,序列末尾
[EOS]Token 对应的特征向量被用来表示整个句子的全局特征。
-
(注:两个编码器输出的特征会通过一个线性投影层 Projector 映射到相同的维度,并进行 L2 归一化。)
3. 核心机制:对比学习与损失函数
CLIP 不使用传统的交叉熵分类损失(即不预测具体是哪个词),而是预测图像和文本是否配对。
在训练阶段,给定一个大小为 N的 Batch,包含 N 对图文数据。模型通过以下步骤计算损失:
-
特征提取: 分别得到 N 个图像特征向量和 N 个文本特征向量。
-
相似度矩阵: 计算这 N个图像特征和 N 个文本特征两两之间的余弦相似度(Cosine Similarity),构成一个
的矩阵。
-
正负样本定义: 矩阵对角线上的 N个元素是匹配的图文对(正样本),需要最大化其相似度;其余
个元素是不匹配的(负样本),需要最小化其相似度。
-
损失函数计算: 使用带有温度参数的对称交叉熵损失(Symmetric Cross-Entropy Loss)。设
为第
个图像的归一化特征,
为第
个文本的归一化特征:
图像到文本 (Image-to-Text) 的对比损失:
文本到图像 (Text-to-Image) 的对比损失:
总损失为两个方向损失的平均值:
(其中
为可学习的温度参数 Temperature,用于缩放 logits,避免模型在训练初期过于自信)
4. Zero-Shot 推理范式
在预训练完成后,CLIP 可以直接用于任意图像的分类,而无需微调(Fine-tuning)。
-
Prompt Engineering (提示工程): 将需要分类的类别名称(如 "dog", "cat", "car")填入一个预设的文本模板中,例如
"A photo of a {label}."。这样可以弥合预训练数据(多为完整的句子描述)和推理数据(单个单词)之间的分布差异。 -
特征匹配: 1. 使用 Text Encoder 计算所有模板句子的文本特征。
2. 使用 Image Encoder 计算待测图像的图像特征。
3. 计算该图像特征与所有文本特征的余弦相似度,并经过 Softmax 转化为概率分布。
4. 相似度得分最高对应的 Label 即为分类结果。
5. 对下游任务的启发(以目标检测为例)
CLIP 的出现催生了 Open-Vocabulary Object Detection (OVD,开放词汇目标检测) 领域的爆发。
-
传统检测器(如 DETR 系列)受限于固定类别的 Bounding Box 标注。
-
利用 CLIP 的多模态对齐能力,研究者现在通过特征蒸馏(Feature Distillation)或区域-文本对齐(Region-Text Alignment),将 CLIP 强大的全局语义知识转移到检测器的局部区域特征(Region Proposals/Queries)上。这使得检测器能够识别并定位出在训练集中从未见过的新类别。
6. 局限性与改进空间
-
细粒度理解不足: 虽然全局语义匹配强大,但在涉及复杂的关系理解、计数问题(如“有几只鸟”)、绝对距离评估以及极小目标的细微差别区分上,表现仍然较弱。
-
数据效率: CLIP 属于数据驱动的暴力美学,极度依赖海量的数据规模(400M 对)和超大的 Batch Size(32768),训练成本极其昂贵。
-
领域泛化: 对于一些完全脱离自然图像分布的抽象任务(如专业的医疗影像、特定光谱的遥感图像),如果预训练集中未曾覆盖,Zero-Shot 性能会大幅衰减。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)