深度学习实战-基于CNN卷积神经网络的肺癌和结直肠癌图像识别模型

🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
1.项目背景
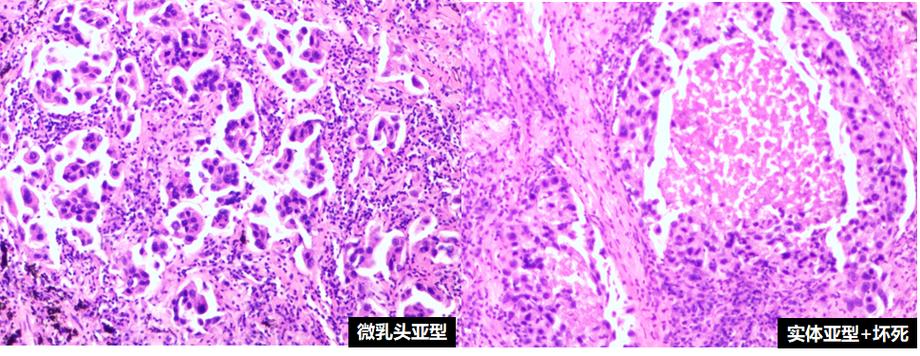
癌症的准确诊断是临床病理工作的核心环节,组织病理学检查作为诊断的金标准,依赖于病理医生通过显微镜观察组织切片中的细胞形态和结构特征。肺腺癌、肺鳞状细胞癌和结肠腺癌是临床上常见的恶性肿瘤类型,它们的治疗方案和预后存在差异,因此准确区分不同类型的癌症对临床决策具有重要意义。然而,病理诊断过程不仅耗时耗力,而且对医生的经验和专业水平要求较高,不同医生之间可能存在诊断差异。
随着数字病理技术的发展,越来越多的医院开始采用全切片扫描系统将传统玻璃切片转化为数字图像,这为计算机辅助诊断系统的开发提供了数据基础。病理图像包含丰富的形态学信息,但不同癌症类型之间的视觉差异有时十分细微,即使是经验丰富的病理医生也可能面临诊断挑战。特别是在基层医疗机构,病理医生资源相对匮乏,自动化的辅助诊断工具显得尤为重要。
本研究旨在探索卷积神经网络在病理图像分类中的应用潜力,构建一个能够自动识别肺癌和结直肠癌不同病理类型的深度学习模型。通过分析组织切片中的细胞排列、核形态、染色特征等微观结构,模型需要学习区分恶性与良性组织,并进一步鉴别不同癌症亚型。这项工作不仅关注技术指标的优化,更着眼于模型的临床应用价值,为病理诊断的智能化提供实践参考。
2.数据集介绍
本实验数据集来源于Kaggle,该数据集包含 25,000 张组织病理学图像,分为 5 个类别。所有图像均为 768 x 768 像素,格式为 JPEG。
数据集包含五个类别,每个类别 5,000 张图像,分别为:
Lung benign tissue 肺部良性组织
Lung adenocarcinoma 肺腺癌
Lung squamous cell carcinoma 肺鳞状细胞癌
Colon adenocarcinoma 结肠腺癌
Colon benign tissue 结肠良性组织
3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.实验过程
4.1导入数据
主要完成环境准备和基础配置工作,导入后续实验所需的各种工具库,并设置关键参数。我们会使用PyTorch框架来构建和训练深度学习模型,同时准备数据可视化和处理的相关工具。
# 导入基础数据处理和可视化库
import numpy as np # 数值计算库,用于数组和矩阵运算
import os # 操作系统接口,用于文件路径操作
import glob as gb # 文件路径匹配,用于批量查找图像文件
import matplotlib.pyplot as plt # 绘图库,用于数据可视化
import seaborn as sns # 统计图形库,用于更美观的可视化
from PIL import Image # 图像处理库,用于图像加载和转换
from tqdm.auto import tqdm # 进度条工具,用于显示循环进度
# 导入PyTorch深度学习框架相关模块
import torch # PyTorch主库
from torch import nn # 神经网络模块,包含各种网络层
from torch.utils.data import Dataset, DataLoader, random_split # 数据加载和处理工具
import torchvision as tv # 计算机视觉相关工具库
from torchinfo import summary # 模型结构可视化工具
import torchmetrics as tm # 模型评估指标库
# 设置seaborn绘图主题和调色板
sns.set_theme(style='darkgrid', palette='pastel') # 使用深色网格风格和柔和调色板
color = sns.color_palette(palette='pastel') # 获取调色板颜色
# 自动选择计算设备:优先使用CUDA(NVIDIA GPU),其次MPS(Apple Silicon),最后CPU
DEVICE = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
# 定义数据集路径和训练参数
DATASET_DIR = './lung-and-colon-cancer-histopathological-images/lung_colon_image_set' # 病理图像数据集目录
IMG_SIZE = 224 # 图像统一调整尺寸,标准输入尺寸
BATCH_SIZE = 64 # 每个训练批次包含的图像数量
EPOCHS = 10 # 训练的总轮数接着定义了专门处理病理图像数据的数据集类,能够自动读取文件夹结构中的图像并建立标签映射。针对医学图像数据集的特点,我们设计了相应的数据处理流程。
# 自定义异常类,用于处理数据集路径和标签数量不匹配的情况
class InvalidDatasetException(Exception):
def __init__(self, len_of_paths, len_of_labels):
# 显示具体的错误信息,帮助调试数据集问题
super().__init__(
f"Number of paths ({len_of_paths}) is not compatible with number of labels ({len_of_labels})"
)
# 自定义数据集类,继承自PyTorch的Dataset类
class CustomDataset(Dataset):
def __init__(self, data_dir):
# 初始化数据集对象
self.data_dir = data_dir # 数据集根目录
# 调用ReadDataset方法读取数据集信息
# imgs_paths: 所有图像文件的完整路径列表
# labels: 对应的标签列表(数字编码)
# label_map: 标签映射字典(数字到类别名称)
# n_classes: 总类别数量
self.imgs_paths, self.labels, self.label_map, self.n_classes = self.ReadDataset(self.data_dir)
# 定义数据转换流程:调整图像尺寸并转换为张量
self.transform = tv.transforms.Compose([
tv.transforms.Resize((IMG_SIZE, IMG_SIZE)), # 调整图像尺寸为224x224
tv.transforms.ToTensor() # 将PIL图像转换为PyTorch张量,同时将像素值归一化到[0,1]
])
# 检查图像路径和标签数量是否一致,如果不一致则抛出异常
if len(self.imgs_paths) != len(self.labels):
raise InvalidDatasetException(self.imgs_paths, self.labels)
def ReadDataset(self, data_dir):
"""
读取数据集目录结构,收集所有图像路径和对应标签
参数:
data_dir: 数据集根目录路径
返回:
imgs_paths: 所有图像文件的完整路径列表
labels: 对应的标签列表(数字编码)
label_map: 标签映射字典(数字到类别名称)
n_classes: 总类别数量
"""
imgs_paths, labels = [], [] # 初始化图像路径和标签列表
label_map = {} # 初始化标签映射字典
idx = 0 # 类别索引计数器
# 遍历数据集目录结构(假设结构为:data_dir/folder/category/image_files)
# 先按文件夹排序,确保每次运行结果一致
for folder in sorted(os.listdir(DATASET_DIR)):
for cat in sorted(os.listdir(os.path.join(DATASET_DIR, folder))):
# 建立当前类别到数字索引的映射
label_map[idx] = cat
# 获取当前类别下的所有图像路径
for path in os.listdir(data_dir + "/" + folder + '/' + cat):
# 使用glob模式匹配获取所有图像文件
files = gb.glob(pathname=str(data_dir + "/" + folder + '/' + cat + '/' + path))
# 将每个图像文件路径和对应标签添加到列表中
for file in files:
imgs_paths.append(file)
labels.append(idx) # 使用当前类别索引作为标签
idx += 1 # 处理完一个类别,索引加1
n_classes = len(label_map) # 计算总类别数
return np.array(imgs_paths), np.array(labels), label_map, n_classes
def __len__(self):
# 返回数据集大小(图像数量)
return len(self.labels)
def __getitem__(self, idx):
# 根据索引获取单个数据样本
img = Image.open(self.imgs_paths[idx]) # 打开图像文件
img = self.transform(img) # 应用预处理转换
label = torch.tensor(self.labels[idx]) # 将标签转换为张量
return img, label # 返回图像张量和标签
# 创建完整的数据集对象
ds = CustomDataset(DATASET_DIR)
# 从数据集对象中获取标签映射和类别数量
label_map = ds.label_map
N_CLASSES = ds.n_classes
# 显示标签映射和类别数量(实际运行时显示这两个变量)
label_map, N_CLASSES
# 划分训练集和验证集(80%训练,20%验证)
train_size = int(0.8 * ds.__len__()) # 训练集大小
val_size = int(0.2 * ds.__len__()) # 验证集大小
# 打印数据集统计信息
print(f"the size of the dataset is : {ds.__len__()}")
print(f"The size of the training set is : {train_size}")
print(f"The size of the validation set is : {val_size}")
将数据集包装成数据加载器,能够批量加载数据并提供数据打乱等功能,为模型训练做好数据准备。
# 使用random_split随机划分训练集和验证集
train_set, val_set = random_split(ds, [train_size, val_size])
# 设置随机种子,确保实验可重复
torch.manual_seed(42)
# 创建训练集数据加载器
train_ds = DataLoader(
train_set, # 训练数据集
batch_size=BATCH_SIZE, # 每批64张图像
shuffle=True, # 每个epoch打乱数据顺序,避免模型学习到数据顺序
pin_memory=True, # 使用固定内存加速数据加载到GPU
num_workers=4 # 使用4个子进程加载数据,提高IO效率
)
# 再次设置随机种子,确保验证集划分一致
torch.manual_seed(42)
# 创建验证集数据加载器
val_ds = DataLoader(
val_set, # 验证数据集
batch_size=BATCH_SIZE, # 每批64张图像
shuffle=False, # 验证集不需要打乱,便于跟踪每个样本的表现
pin_memory=True, # 使用固定内存
num_workers=4 # 使用4个子进程
)
# 打印数据加载器信息
print(f"the size of the train dataloader : {len(train_ds)} batches of {BATCH_SIZE}\n")
print(f"the size of the validation dataloader : {len(val_ds)} batches of {BATCH_SIZE}\n")
4.2数据可视化

从训练数据集中随机抽取一批样本进行可视化展示。对于病理图像识别任务来说,观察原始图像的质量、了解不同癌症类型的视觉特征非常重要。通过直观地查看这些组织切片图像,我们可以对数据集有一个初步的认识,也能检查数据预处理是否得当。
# 从训练数据加载器中获取一个批次的数据样本
# next()函数获取数据加载器的下一个批次
# iter(train_ds)将数据加载器转换为迭代器
img_sample, label_sample = next(iter(train_ds))
# 创建一个2行4列的子图网格,总共显示8个图像样本
# figsize=(15, 10)设置整个图形的大小为15x10英寸
fig, axis = plt.subplots(2, 4, figsize=(15, 10))
# 遍历所有子图(共8个),在每个子图中显示一张图像
for i, ax in enumerate(axis.flat):
# 调整图像张量的维度顺序
# PyTorch图像张量的默认格式是(C, H, W)即(通道数, 高度, 宽度)
# torch.permute将维度重新排列为(H, W, C)即(高度, 宽度, 通道数)
# 这是因为matplotlib的imshow函数需要(H, W, C)格式的图像
img = torch.permute(img_sample[i], (1, 2, 0))
# 将PyTorch张量转换为numpy数组
# matplotlib只能显示numpy数组格式的图像数据
img = img.numpy()
# 获取当前图像的标签值
# label_sample[i]是张量,.item()方法将其转换为Python标量
label = label_sample[i].item()
# 在当前子图中显示图像
# imshow函数显示numpy数组格式的图像
ax.imshow(img)
# 设置子图标题,显示对应的病理类型名称
# 通过label_map字典将数字标签转换为可读的类别名称
ax.set(title=f"{label_map[label]}")
# 关闭当前子图的坐标轴显示
# 病理图像通常不需要坐标轴,关闭后图像显示更清晰
ax.axis('off')
# 显示整个图形
plt.show()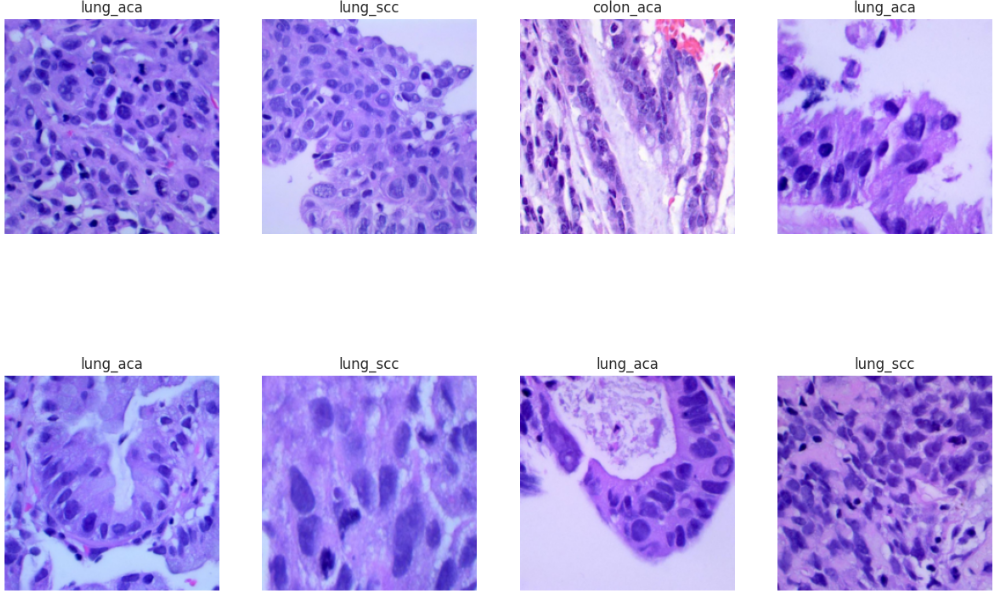
4.3特征工程
定义了模型训练和评估过程中需要用到的工具函数。对于医学图像分类任务,特别是癌症识别这样的重要应用,我们需要全面评估模型的性能,不仅要看整体准确率,还要关注精确率、召回率等更细致的指标。这些函数将帮助我们更好地监控训练过程、评估模型表现并进行错误分析。
# 定义准确率计算函数
def accuracy_fn(y_pred, y_true):
"""
计算模型预测的准确率
参数:
y_pred: 模型输出的预测概率分布,形状为(batch_size, n_classes)
y_true: 真实标签,形状为(batch_size,)
返回:
acc: 准确率百分比
"""
# 将预测概率分布转换为具体的类别标签
# torch.argmax(dim=1): 在类别维度上找到最大概率对应的索引
y_pred = torch.argmax(y_pred, dim=1)
# 统计预测正确的样本数量
# torch.eq(): 逐元素比较预测标签和真实标签是否相等
# .sum(): 统计相等的数量
# .item(): 将张量转换为Python标量
correct = torch.eq(y_true, y_pred).sum().item()
# 计算准确率百分比
acc = (correct / len(y_pred)) * 100
return acc
# 定义评估指标类,用于计算多种分类指标
class EvaluationMetrics:
def __init__(self, n_classes):
"""
初始化评估指标类
参数:
n_classes: 分类任务的类别数量
"""
# 使用torchmetrics库定义多种评估指标
self.metrics = {
'accuracy': tm.Accuracy(
task="multiclass", # 多分类任务
num_classes=N_CLASSES, # 类别数量
average="macro" # 宏平均:先计算每个类别的指标,然后取平均
),
'precision': tm.Precision(
task="multiclass",
num_classes=N_CLASSES,
average="macro" # 精确率:真正例 / (真正例 + 假正例)
),
'recall': tm.Recall(
task="multiclass",
num_classes=N_CLASSES,
average="macro" # 召回率:真正例 / (真正例 + 假负例)
),
'f1': tm.F1Score(
task="multiclass",
num_classes=N_CLASSES,
average="macro" # F1分数:精确率和召回率的调和平均
)
}
# 将所有指标移动到指定的计算设备(GPU/CPU)
for metric in self.metrics.values():
metric.to(DEVICE)
def update(self, y_preds, y_true):
"""
更新所有指标的统计量
参数:
y_preds: 模型预测的类别标签
y_true: 真实的类别标签
"""
for metric in self.metrics.values():
metric.update(y_preds, y_true)
def compute(self):
"""
计算所有指标的当前值
返回:
包含各指标数值的字典
"""
return {name: metric.compute().item() for name, metric in self.metrics.items()}
def reset(self):
"""
重置所有指标的统计量,用于新的评估轮次
"""
for metric in self.metrics.values():
metric.reset()
# 定义混淆矩阵可视化函数
def ConfMatPlot(cm, confmat):
"""
绘制混淆矩阵热力图
参数:
cm: torchmetrics的混淆矩阵对象
confmat: 计算好的混淆矩阵数值
"""
# 调用混淆矩阵对象的plot方法创建基础图形
fig, ax = cm.plot()
# 设置图表标题和坐标轴标签
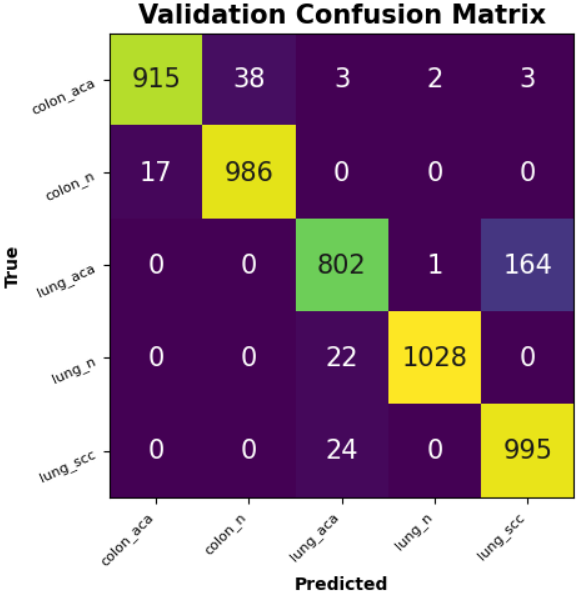
ax.set_title("Validation Confusion Matrix", fontsize=15, fontweight="bold")
ax.set_xlabel("Predicted", fontsize=10, fontweight="bold")
ax.set_ylabel("True", fontsize=10, fontweight="bold")
# 设置x轴刻度位置和标签
ax.set_xticks(np.arange(len(label_map))) # 在0到类别数量-1的位置设置刻度
# 设置刻度标签为类别名称,旋转45度,右对齐,字体大小8
ax.set_xticklabels(list(label_map.values()), rotation=45, ha='right', fontsize=8)
# 设置y轴刻度位置和标签
ax.set_yticks(np.arange(len(label_map)))
ax.set_yticklabels(list(label_map.values()), fontsize=8)
# 显示图形
plt.show()4.4构建模型
定义了用于肺癌和结直肠癌病理图像分类的卷积神经网络架构。我们采用相对简洁的CNN设计,通过多层卷积和池化操作逐步提取图像特征,最终实现五种病理类型的分类任务。这种结构适合处理组织切片图像中复杂的细胞形态和组织结构特征。
# 使用nn.Sequential构建顺序模型
# Sequential容器按顺序组合各网络层,适合简单的线性结构
model = nn.Sequential(
# ------------------- 第一个卷积块 -------------------
# 第一层卷积:输入通道3(RGB图像),输出通道32,3x3卷积核
# stride=2: 步长为2,每次卷积后特征图尺寸减半
# padding=1: 填充1像素,保持特征图边界信息
nn.Conv2d(3, 32, kernel_size=3, stride=2, padding=1),
# ReLU激活函数:引入非线性,使模型能够学习复杂模式
nn.ReLU(),
# 第二层卷积:输入通道32,输出通道64,3x3卷积核
# 继续提取更复杂的特征,增加特征图通道数
nn.Conv2d(32, 64, kernel_size=3, stride=2, padding=1),
nn.ReLU(),
# ------------------- 第一个池化层 -------------------
# 最大池化:2x2窗口,步长默认为2
# 进一步减小特征图尺寸,提取最显著的特征,增加平移不变性
nn.MaxPool2d((2, 2)),
# ------------------- 第二个卷积块 -------------------
# 第三层卷积:输入通道64,输出通道128,3x3卷积核
# 继续增加特征图通道数,提取更抽象的特征
nn.Conv2d(64, 128, kernel_size=3, stride=2, padding=1),
nn.ReLU(),
# 第四层卷积:输入通道128,输出通道256,3x3卷积核
# 最终的特征提取层,通道数增加到256
nn.Conv2d(128, 256, kernel_size=3, stride=2, padding=1),
nn.ReLU(),
# ------------------- 第二个池化层 -------------------
# 再次进行最大池化,进一步压缩特征图
nn.MaxPool2d((2, 2)),
# ------------------- 展平层 -------------------
# 将三维特征图展平为一维向量,供全连接层处理
# 特征图当前形状为:(256, 3, 3) -> 展平为2304维向量
nn.Flatten(),
# ------------------- 输出层 -------------------
# 全连接层:输入维度256*3*3=2304,输出维度为类别数
# 直接输出每个类别的得分,没有激活函数(后续会配合交叉熵损失使用)
nn.Linear(256 * 3 * 3, N_CLASSES)
)
# 将模型移动到指定的计算设备(GPU/CPU)
# 这会将模型的所有参数和缓冲区复制到对应设备
model = model.to(DEVICE)
# 打印模型结构摘要
# 显示每层的输出形状、参数数量和总参数量
# input_size=(BATCH_SIZE, 3, IMG_SIZE, IMG_SIZE): 输入张量的形状
summary(model, input_size=(BATCH_SIZE, 3, IMG_SIZE, IMG_SIZE))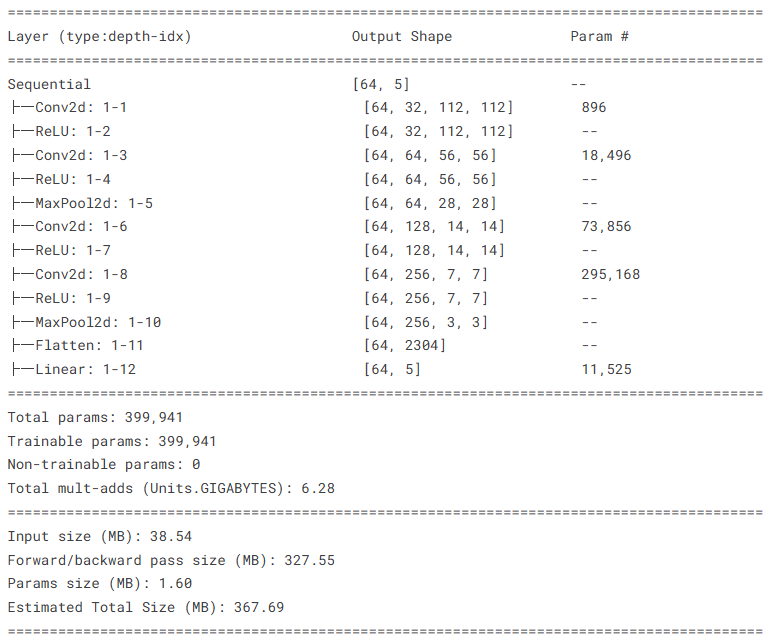
4.5训练模型
实现了模型的完整训练流程,包括训练循环和验证循环的定义,以及整个训练过程的执行。针对病理图像分类任务,我们设计了包含学习率调整的训练策略,确保模型能够在合适的训练节奏下学习到有效的特征表示。
# 定义损失函数、优化器和学习率调度器
loss_fn = nn.CrossEntropyLoss() # 交叉熵损失函数,适用于多分类任务
optim = torch.optim.Adam(model.parameters(), lr=0.003) # Adam优化器,初始学习率0.003
# 定义学习率调度器:基于验证损失自动调整学习率
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(
optim, # 要调度的优化器
mode='min', # 监控指标的模式:'min'表示希望损失值越小越好
factor=0.2, # 学习率衰减因子:当触发条件时,学习率乘以0.2(降低80%)
patience=3 # 耐心值:容忍验证损失连续3个epoch没有改善
)
def train_loop():
"""
单个epoch的训练循环
返回:
epoch_loss: 当前epoch的平均训练损失
epoch_acc: 当前epoch的平均训练准确率
"""
epoch_loss, epoch_acc = 0, 0 # 初始化损失和准确率累加器
model.train() # 设置模型为训练模式,启用Dropout和BatchNorm的随机性
# 遍历训练数据加载器中的所有批次
for X, y in train_ds:
# 将数据和标签移动到指定设备(GPU/CPU)
X, y = X.to(DEVICE), y.to(DEVICE)
# 前向传播:计算模型预测
y_preds = model(X)
# 计算损失
loss = loss_fn(y_preds, y)
# 累加损失和准确率
epoch_loss += loss.item() # .item()将标量张量转换为Python浮点数
epoch_acc += accuracy_fn(y_preds, y) # 使用之前定义的准确率函数
# 反向传播和参数更新
optim.zero_grad() # 清空之前的梯度缓存
loss.backward() # 反向传播,计算梯度
optim.step() # 根据梯度更新模型参数
# 计算整个epoch的平均损失和准确率
epoch_loss /= len(train_ds) # 除以批次数量
epoch_acc /= len(train_ds)
return epoch_loss, epoch_acc
def val_loop():
"""
单个epoch的验证循环
返回:
epoch_loss: 当前epoch的平均验证损失
epoch_acc: 当前epoch的平均验证准确率
epoch_lr: 当前的学习率
"""
epoch_loss, epoch_acc = 0, 0 # 初始化损失和准确率累加器
model.eval() # 设置模型为评估模式,禁用Dropout和BatchNorm的随机性
# 使用推理模式,禁用梯度计算以节省内存和加速计算
with torch.inference_mode():
# 遍历验证数据加载器中的所有批次
for X, y in val_ds:
X, y = X.to(DEVICE), y.to(DEVICE)
y_preds = model(X) # 前向传播(不计算梯度)
loss = loss_fn(y_preds, y)
epoch_loss += loss.item()
epoch_acc += accuracy_fn(y_preds, y)
# 计算整个验证集的平均损失和准确率
epoch_loss /= len(val_ds)
epoch_acc /= len(val_ds)
# 根据验证损失更新学习率
scheduler.step(epoch_loss)
# 获取当前的学习率
epoch_lr = optim.param_groups[0]["lr"]
return epoch_loss, epoch_acc, epoch_lr
# 设置随机种子,确保实验可重复
torch.manual_seed(42)
# 初始化记录训练过程的列表
train_losses, train_accuracies = [], [] # 训练损失和准确率历史
val_losses, val_accuracies = [], [] # 验证损失和准确率历史
lr_over_epochs = [] # 学习率变化历史
# 开始训练循环
for epoch in tqdm(range(EPOCHS)):
# 执行一个完整的训练epoch
train_loss, train_acc = train_loop()
# 执行验证,评估模型在验证集上的表现
val_loss, val_acc, current_lr = val_loop()
# 记录当前epoch的结果
train_losses.append(train_loss)
train_accuracies.append(train_acc)
val_losses.append(val_loss)
val_accuracies.append(val_acc)
lr_over_epochs.append(current_lr)
# 打印当前epoch的训练结果
print(
f"""
[Epoch {epoch+1}/{EPOCHS}] [LR : {current_lr:0.5f}]
[Train Loss: {train_loss:0.5f}] [Train Accuracy: {train_acc:0.2f}%]
[Validation Loss: {val_loss:0.5f}] [Validation Accuracy: {val_acc:0.2f}%]
"""
)
4.6模型评估
对于病理图像分类这样的医疗应用,准确的性能评估至关重要,我们需要清楚地了解模型在验证集上的实际表现。
# 打印验证集的最终损失和准确率
# val_losses[-1]: 验证损失列表中的最后一个元素(最后一个epoch的损失)
# val_accuracies[-1]: 验证准确率列表中的最后一个元素
print(f"The loss of the Validation set is : {val_losses[-1]:0.3f}")
print(f"The accuracy of the Validation set is : {val_accuracies[-1]:0.3f}%")
接着通过绘制损失曲线和准确率曲线,可视化展示模型在整个训练过程中的学习动态。这些曲线能帮助我们诊断模型训练的健康状况,识别过拟合或欠拟合等问题。
# 创建包含两个子图的图形窗口
figure, axis = plt.subplots(1, 2, figsize=(15, 8))
# ------------------- 第一个子图:损失曲线 -------------------
# 绘制训练损失曲线
axis[0].plot(train_losses, label='train')
# 绘制验证损失曲线
axis[0].plot(val_losses, label='val')
# 设置子图标题和坐标轴标签
axis[0].set_title('Training/validation loss over Epochs')
axis[0].set_xlabel('Epochs')
axis[0].set_ylabel('loss')
# 显示图例,区分训练和验证曲线
axis[0].legend()
# ------------------- 第二个子图:准确率曲线 -------------------
# 绘制训练准确率曲线
axis[1].plot(train_accuracies, label='train')
# 绘制验证准确率曲线
axis[1].plot(val_accuracies, label='val')
# 设置子图标题和坐标轴标签
axis[1].set_title('Training/validation accuracy over Epochs')
axis[1].set_xlabel('epoch')
axis[1].set_ylabel('Accuracy')
# 显示图例
axis[1].legend()
# 显示完整图形
plt.show()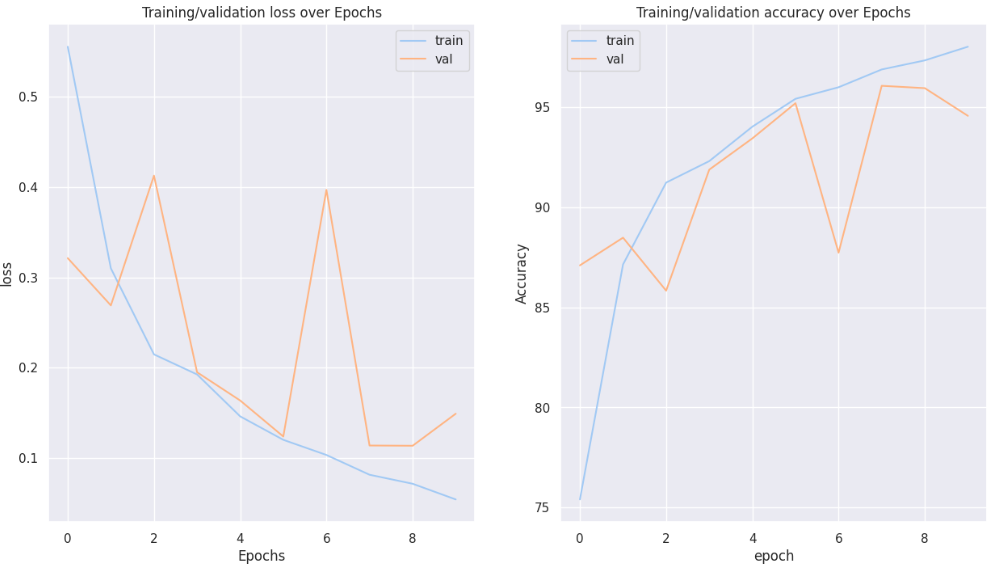
接着对模型进行全面的性能评估,不仅计算整体准确率,还计算精确率、召回率、F1分数等更细致的指标,并生成混淆矩阵来了解各类别间的混淆情况。
def evaluate(ds, metrics, cm):
"""
在指定数据集上全面评估模型性能
参数:
ds: 数据加载器(验证集或测试集)
metrics: 评估指标对象
cm: 混淆矩阵对象
"""
# 设置模型为评估模式
model.eval()
# 重置所有评估指标的统计量,确保评估从干净状态开始
metrics.reset()
# 使用推理模式,禁用梯度计算以节省内存和加速
with torch.inference_mode():
# 遍历数据集中的所有批次,显示进度条
for X, y in tqdm(ds):
# 将数据和标签移动到指定设备
X, y = X.to(DEVICE), y.to(DEVICE)
# 前向传播,获取模型预测
y_preds = model(X)
# 将预测概率分布转换为具体类别标签
y_preds = y_preds.argmax(dim=1)
# 更新评估指标统计量
metrics.update(y_preds, y)
# 更新混淆矩阵统计量
cm.update(y_preds, y)
# 计算所有评估指标的最终值
val_metrics = metrics.compute()
# 计算混淆矩阵并转换为numpy数组
confmat = cm.compute().cpu().numpy()
# 打印详细的评估结果
print(
"\t\t\t\t--- Validation Metrics ---\n"
f"Validation Accuracy: {val_metrics['accuracy']:.2f}%\n"
f"Validation Precision: {val_metrics['precision']:.3f}\n"
f"Validation Recall: {val_metrics['recall']:.3f}\n"
f"Validation F1-score: {val_metrics['f1']:.3f}\n\n"
f"Validation Confusion Matrix :\n{confmat}\n"
)
# 调用之前定义的混淆矩阵可视化函数
ConfMatPlot(cm, confmat)
# 重置混淆矩阵统计量,为下次评估做准备
cm.reset()
# 初始化评估指标对象和混淆矩阵对象
metrics = EvaluationMetrics(n_classes=N_CLASSES)
confusion_matrix = tm.classification.MulticlassConfusionMatrix(num_classes=N_CLASSES).to(DEVICE)
# 在验证集上执行全面评估
evaluate(val_ds, metrics, confusion_matrix)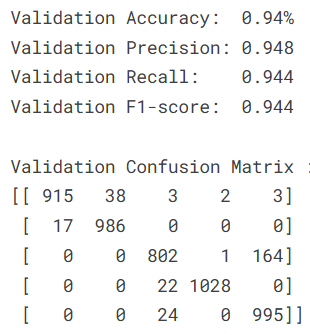
最后通过随机抽样展示模型在具体样本上的预测结果,将模型的预测与真实标签进行直观对比,帮助我们理解模型的判断依据和常见错误类型。
def predict(model, ds):
"""
随机抽样展示模型在具体样本上的预测结果
参数:
model: 训练好的模型
ds: 数据集(验证集)
"""
# 从数据集中随机选择10个不同的样本索引
# np.random.choice随机抽样,replace=False确保不重复抽样
idxs = np.random.choice(ds.__len__(), 10, replace=False)
# 创建2行5列的子图网格,用于展示10个样本
fig, axes = plt.subplots(2, 5, figsize=(25, 15))
# 遍历每个子图和对应的样本索引
for ax, idx in zip(axes.flat, idxs):
# 根据索引从数据集中获取图像和标签
sample_img, sample_label = ds[idx]
# 将数据和标签移动到指定设备
sample_img, sample_label = sample_img.to(DEVICE), sample_label.to(DEVICE)
# 使用推理模式进行预测
with torch.inference_mode():
# 增加批次维度:unsqueeze(0)将形状从[C,H,W]变为[1,C,H,W]
y_pred = model(sample_img.unsqueeze(0))
# 调整图像维度顺序,准备显示
sample_img = torch.permute(sample_img, (1, 2, 0))
sample_img = sample_img.cpu().numpy()
# 获取真实标签的数值
sample_label = sample_label.item()
# 获取模型预测的类别
y_pred = torch.argmax(y_pred, dim=1).cpu().item()
# 在子图中显示图像
ax.imshow(sample_img)
# 设置子图标题:同时显示预测结果和真实标签
# 可以添加颜色判断:预测正确为绿色,错误为红色
title_color = 'green' if y_pred == sample_label else 'red'
ax.set_title(
f"Predicted : {label_map[y_pred]}\nTrue : {label_map[sample_label]}",
fontsize=20,
color=title_color
)
# 关闭坐标轴
ax.axis('off')
# 调整子图布局,避免重叠
plt.tight_layout()
# 显示图形
plt.show()
# 在验证集上执行预测可视化
predict(model, val_set)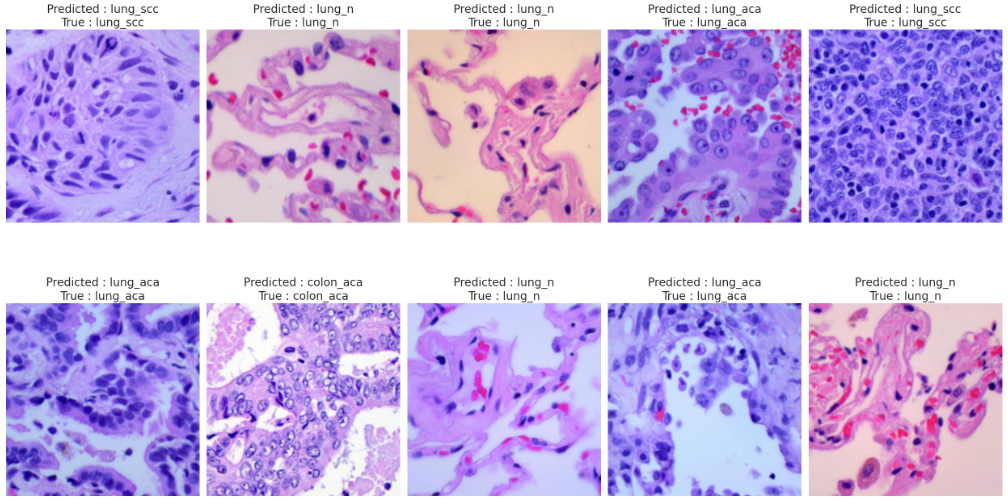
5.总结
本文基于卷积神经网络构建了一个肺癌和结直肠癌病理图像的分类识别模型,在包含五类组织病理学图像的数据集上取得了较好的识别效果。实验结果表明,模型在验证集上达到了94.4%的准确率,F1分数为0.944,显示出模型能够有效区分不同癌症类型与正常组织。通过混淆矩阵分析可以发现,模型对结肠良性组织和肺腺癌的识别准确率较高,但在肺鳞状细胞癌与结肠腺癌之间存在一定的混淆现象,这可能与两类组织在病理形态上的相似性有关。训练过程中采用了自适应学习率调整策略,验证损失曲线和准确率曲线均呈现良好的收敛趋势,表明模型学习过程稳定。可视化结果显示模型能够较准确地对大多数病理样本进行分类,为基于深度学习的病理图像辅助诊断提供了可行的技术方案。后续研究可进一步优化网络结构,引入注意力机制以提升对细微病理特征的识别能力,并结合临床诊断需求对模型进行针对性改进。
源代码
import numpy as np
import os
import glob as gb
import matplotlib.pyplot as plt
import seaborn as sns
from PIL import Image
from tqdm.auto import tqdm
import torch
from torch import nn
from torch.utils.data import Dataset , DataLoader , random_split
import torchvision as tv
from torchinfo import summary
import torchmetrics as tm
sns.set_theme(style='darkgrid', palette='pastel')
color = sns.color_palette(palette='pastel')
DEVICE = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
DATASET_DIR = './lung-and-colon-cancer-histopathological-images/lung_colon_image_set'
IMG_SIZE = 224
BATCH_SIZE = 64
EPOCHS = 10
class InvalidDatasetException(Exception):
def __init__(self,len_of_paths,len_of_labels):
super().__init__(
f"Number of paths ({len_of_paths}) is not compatible with number of labels ({len_of_labels})"
)
class CustomDataset(Dataset) :
def __init__(self , data_dir) :
self.data_dir = data_dir
self.imgs_paths , self.labels , self.label_map , self.n_classes = self.ReadDataset(self.data_dir)
self.transform = tv.transforms.Compose([
tv.transforms.Resize((IMG_SIZE , IMG_SIZE)) ,
tv.transforms.ToTensor()
])
if len(self.imgs_paths) != len(self.labels) :
raise InvalidDatasetException(self.imgs_paths , self.labels)
def ReadDataset(self , data_dir) :
imgs_paths , labels = [] , []
label_map = {}
idx = 0
for folder in sorted(os.listdir(DATASET_DIR)):
for cat in sorted(os.listdir(os.path.join(DATASET_DIR, folder))):
label_map[idx] = cat
for path in os.listdir(data_dir + "/" + folder + '/' + cat) :
files = gb.glob(pathname = str(data_dir + "/" + folder + '/' + cat + '/' + path))
for file in files :
imgs_paths.append(file)
labels.append(idx)
idx += 1
n_classes = len(label_map)
return np.array(imgs_paths) , np.array(labels) , label_map , n_classes
def __len__(self) :
return len(self.labels)
def __getitem__(self , idx) :
img = Image.open(self.imgs_paths[idx])
img = self.transform(img)
label = torch.tensor(self.labels[idx])
return img , label
ds = CustomDataset(DATASET_DIR)
label_map = ds.label_map
N_CLASSES = ds.n_classes
label_map , N_CLASSES
train_size = int(0.8 * ds.__len__())
val_size = int(0.2 * ds.__len__())
print(f"the size of the dataset is : {ds.__len__()}")
print(f"The size of the training set is : {train_size}")
print(f"The size of the validation set is : {val_size}")
train_set , val_set = random_split(ds , [train_size , val_size])
torch.manual_seed(42)
train_ds = DataLoader(
train_set ,
batch_size = BATCH_SIZE ,
shuffle = True ,
pin_memory = True ,
num_workers=4
)
torch.manual_seed(42)
val_ds = DataLoader(
val_set ,
batch_size = BATCH_SIZE ,
shuffle = False ,
pin_memory = True ,
num_workers=4
)
print(f"the size of the train dataloader : {len(train_ds)} batches of {BATCH_SIZE}\n")
print(f"the size of the validation dataloader : {len(val_ds)} batches of {BATCH_SIZE}\n")
img_sample , label_sample = next(iter(train_ds))
fig , axis = plt.subplots(2 , 4 , figsize = (15 , 10))
for i , ax in enumerate(axis.flat) :
img = torch.permute(img_sample[i] , (1,2,0))
img = img.numpy()
label = label_sample[i].item()
ax.imshow(img)
ax.set(title = f"{label_map[label]}")
ax.axis('off')
plt.show()
def accuracy_fn(y_pred , y_true) :
y_pred = torch.argmax(y_pred , dim = 1)
correct = torch.eq(y_true , y_pred).sum().item()
acc = (correct / len(y_pred)) * 100
return acc
class EvaluationMetrics :
def __init__(self , n_classes) :
self.metrics = {
'accuracy' : tm.Accuracy(
task = "multiclass" ,
num_classes = N_CLASSES ,
average = "macro"
) ,
'precision' : tm.Precision(
task = "multiclass" ,
num_classes = N_CLASSES ,
average = "macro"
) ,
'recall' : tm.Recall(
task = "multiclass" ,
num_classes = N_CLASSES ,
average = "macro"
) ,
'f1' : tm.F1Score(
task = "multiclass" ,
num_classes = N_CLASSES ,
average = "macro"
)
}
for metric in self.metrics.values() :
metric.to(DEVICE)
def update(self , y_preds , y_true) :
for metric in self.metrics.values() :
metric.update(y_preds , y_true)
def compute(self) :
return {name : metric.compute().item() for name , metric in self.metrics.items()}
def reset(self) :
for metric in self.metrics.values() :
metric.reset()
def ConfMatPlot(cm , confmat) :
fig, ax = cm.plot()
ax.set_title("Validation Confusion Matrix" , fontsize = 15 , fontweight = "bold")
ax.set_xlabel("Predicted", fontsize=10, fontweight="bold")
ax.set_ylabel("True", fontsize=10, fontweight="bold")
ax.set_xticks(np.arange(len(label_map)))
ax.set_xticklabels(list(label_map.values()), rotation=45, ha='right', fontsize=8)
ax.set_yticks(np.arange(len(label_map)))
ax.set_yticklabels(list(label_map.values()), fontsize=8)
plt.show()
model = nn.Sequential(
nn.Conv2d(3 , 32 , kernel_size = 3 , stride = 2 , padding = 1) ,
nn.ReLU() ,
nn.Conv2d(32 , 64 , kernel_size = 3 , stride = 2 , padding = 1) ,
nn.ReLU() ,
nn.MaxPool2d((2,2)) ,
nn.Conv2d(64 , 128 , kernel_size = 3 , stride = 2 , padding = 1) ,
nn.ReLU() ,
nn.Conv2d(128 , 256 , kernel_size = 3 , stride = 2 , padding = 1) ,
nn.ReLU() ,
nn.MaxPool2d((2,2)) ,
nn.Flatten() ,
nn.Linear(256*3*3 , N_CLASSES)
)
model = model.to(DEVICE)
summary(model , input_size=(BATCH_SIZE , 3 , IMG_SIZE , IMG_SIZE))
loss_fn = nn.CrossEntropyLoss()
optim = torch.optim.Adam(model.parameters(), lr=0.003)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(
optim ,
mode = 'min' ,
factor = 0.2 ,
patience = 3
)
def train_loop() :
epoch_loss , epoch_acc = 0 , 0
model.train()
for X , y in train_ds :
X , y = X.to(DEVICE) , y.to(DEVICE)
y_preds = model(X)
loss = loss_fn(y_preds , y)
epoch_loss += loss.item()
epoch_acc += accuracy_fn(y_preds , y)
optim.zero_grad()
loss.backward()
optim.step()
epoch_loss /= len(train_ds)
epoch_acc /= len(train_ds)
return epoch_loss , epoch_acc
def val_loop() :
epoch_loss , epoch_acc = 0 , 0
model.eval()
with torch.inference_mode() :
for X , y in val_ds :
X , y = X.to(DEVICE) , y.to(DEVICE)
y_preds = model(X)
loss = loss_fn(y_preds , y)
epoch_loss += loss.item()
epoch_acc += accuracy_fn(y_preds , y)
epoch_loss /= len(val_ds)
epoch_acc /= len(val_ds)
scheduler.step(epoch_loss)
epoch_lr = optim.param_groups[0]["lr"]
return epoch_loss , epoch_acc , epoch_lr
torch.manual_seed(42)
train_losses , train_accuracies = [] , []
val_losses , val_accuracies = [] , []
lr_over_epochs = []
for epoch in tqdm(range(EPOCHS)) :
train_loss , train_acc = train_loop()
val_loss , val_acc , current_lr = val_loop()
train_losses.append(train_loss)
train_accuracies.append(train_acc)
val_losses.append(val_loss)
val_accuracies.append(val_acc)
lr_over_epochs.append(current_lr)
print(
f"""
[Epoch {epoch+1}/{EPOCHS}] [LR : {current_lr:0.5f}]
[Train Loss: {train_loss:0.5f}] [Train Accuracy: {train_acc:0.2f}%]
[Validation Loss: {val_loss:0.5f}] [Validation Accuracy: {val_acc:0.2f}%]
"""
)
print(f"The loss of the Validation set is : {val_losses[-1]:0.3f}")
print(f"The accuracy of the Validation set is : {val_accuracies[-1]:0.3f}%")
figure , axis = plt.subplots(1,2,figsize=(15,8))
axis[0].plot(train_losses , label='train')
axis[0].plot(val_losses , label='val')
axis[0].set_title('Training/validation loss over Epochs')
axis[0].set_xlabel('Epochs')
axis[0].set_ylabel('loss')
axis[0].legend()
axis[1].plot(train_accuracies, label='train')
axis[1].plot(val_accuracies, label='val')
axis[1].set_title('Training/validation accuracy over Epochs')
axis[1].set_xlabel('epoch')
axis[1].set_ylabel('Accuracy')
axis[1].legend()
plt.show()
def evaluate(ds , metrics , cm) :
model.eval()
metrics.reset()
with torch.inference_mode() :
for X , y in tqdm(ds) :
X , y = X.to(DEVICE) , y.to(DEVICE)
y_preds = model(X)
y_preds = y_preds.argmax(dim = 1)
metrics.update(y_preds , y)
cm.update(y_preds , y)
val_metrics = metrics.compute()
confmat = cm.compute().cpu().numpy()
print(
"\t\t\t\t--- Validation Metrics ---\n"
f"Validation Accuracy: {val_metrics['accuracy']:.2f}%\n"
f"Validation Precision: {val_metrics['precision']:.3f}\n"
f"Validation Recall: {val_metrics['recall']:.3f}\n"
f"Validation F1-score: {val_metrics['f1']:.3f}\n\n"
f"Validation Confusion Matrix :\n{confmat}\n"
)
ConfMatPlot(cm , confmat)
cm.reset()
metrics = EvaluationMetrics(n_classes=N_CLASSES)
confusion_matrix = tm.classification.MulticlassConfusionMatrix(num_classes=N_CLASSES).to(DEVICE)
evaluate(val_ds, metrics , confusion_matrix)
def predict(model , ds) :
idxs = np.random.choice(ds.__len__(), 10, replace=False)
fig, axes = plt.subplots(2, 5, figsize=(25, 15))
for ax, idx in zip(axes.flat, idxs):
sample_img , sample_label = ds[idx]
sample_img , sample_label = sample_img.to(DEVICE) , sample_label.to(DEVICE)
with torch.inference_mode() :
y_pred = model(sample_img.unsqueeze(0))
sample_img = torch.permute(sample_img , (1,2,0))
sample_img = sample_img.cpu().numpy()
sample_label = sample_label.item()
y_pred= torch.argmax(y_pred, dim=1).cpu().item()
ax.imshow(sample_img)
ax.set_title(f"Predicted : {label_map[y_pred]}\nTrue : {label_map[sample_label]}" , fontsize = 20)
ax.axis('off')
plt.tight_layout()
plt.show()
predict(model , val_set)资料获取,更多粉丝福利,关注下方公众号获取


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 31
31 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)