MANTA精读:从小白到博士,彻底拆解面向微小物体的大规模多视图视觉-文本异常检测数据集的核心逻辑
MANTA: A Large-Scale Multi-View and Visual-Text Anomaly Detection Dataset for Tiny Objects 精读:从小白到博士,彻底拆解面向微小物体的大规模多视图视觉-文本异常检测数据集的核心逻辑
论文标题:MANTA: A Large-Scale Multi-View and Visual-Text Anomaly Detection Dataset for Tiny Objects
论文来源:MANTA: A Large-Scale Multi-View and Visual-Text Anomaly Detection Dataset for Tiny Objects
文章定位:论文精读 / 异常检测 / 微小物体感知 / 多视图视觉 / 视觉-文本融合 / 数据集构建
适合人群:零基础读者、计算机视觉/工业检测研究生、准备复现/基于该数据集做研究的博士生与工程研究人员


文章目录
一句提示词帮你速通论文
提示词
你现在是一位计算机视觉的博士,请你仔细阅读这篇论文,并将其拆解为小白阶段、硕士阶段、博士阶段。一定要引人入胜,客观具体,且极为详细。小白阶段你需要达到是个傻子都能懂的情况,在硕士阶段你需要达到正常使用一些专业数据,帮助小白从傻子到小专家的突破,在博士阶段你需要仔细拆解整篇论文,把各项细节全部记录,方便后期进行复现,同时促使小专家成为资深大拿
前言
最近几年,微小物体异常检测成了工业质检、安防监控、医疗影像、无人机巡检等领域的核心感知技术——从电路板焊点裂纹检测、精密轴承瑕疵识别,到航拍场景下的小目标异常监测、医疗切片中微小结节筛查,都需要能精准识别“不起眼却致命”的微小异常目标的能力。而微小物体异常检测有一个核心痛点:
传统异常检测数据集要么规模小、场景单一,要么只聚焦大物体异常,针对微小物体的标注数据极度稀缺;更关键的是,现有数据集要么只有单视图采集的信息,角度遮挡/光照变化下特征表征不足,要么缺乏视觉-文本关联标注,模型只能识别预定义的异常类型,面对新异常类型直接“失明”,根本适配不了真实场景的开放词汇检测需求。
同时,多视图感知、视觉-文本大模型(CLIP、BLIP)的兴起给 “补数据、破类别限制” 带来了希望 —— 多视图能补齐微小物体的特征信息,视觉-文本融合能实现开放词汇的异常识别,但新问题又来了:
现有多视图数据集大多针对常规尺寸物体,没有考虑微小物体“像素占比低、特征易被噪声淹没”的特点;视觉-文本异常检测数据集要么标注粒度粗,要么覆盖场景少,直接用这些数据集训练的模型,在微小物体异常检测任务上漏检率、误检率居高不下,根本没法落地。
于是,这篇论文提出了一套直击痛点的解决方案:
首次构建了面向微小物体异常检测的大规模基准数据集MANTA,通过“多视图标准化采集 + 视觉-文本细粒度标注 + 跨场景全覆盖”的设计,包含百万级多视图微小物体样本、千万级视觉-文本异常描述对,同时配套统一的评价指标、基线模型与开源工具链,填补了微小物体异常检测领域“大规模、多模态、开放词汇”数据集的空白,大幅提升了微小物体异常检测模型的泛化能力与开放词汇识别能力。
这篇文章我会把MANTA数据集拆成三个层次来讲:
- 小白阶段:用最直白的语言、最形象的类比,讲懂MANTA数据集到底在解决什么问题、包含什么核心内容、能用来做什么、效果有多好
- 硕士阶段:引入必要的专业术语、数据规格、标注体系、数学化评价指标、基线实验设计与结果对比,帮你完成从入门到专业的突破
- 博士阶段:按照“可复现、可推敲、可扩展”的标准,完整拆解数据集的创新动机、采集标注的工程实现细节、基线模型设计逻辑、复现避坑指南、局限性与未来研究方向,帮你从专业玩家进阶为领域资深研究者
目标只有一个:
不只是让你“看过这个数据集”,而是让你真正“吃透这个数据集”,甚至能基于它做二次创新、模型训练与工程落地。
小白阶段:通俗易懂、引人入胜
1. 论文要解决的核心问题
我们生活里有很多超小的关键物件:比如治病的药片、种庄稼的麦种、手机里的小螺丝、Type-C充电口,这些东西但凡有针尖大的瑕疵(药片裂了、麦种发霉了、螺丝有划痕),就可能引发大问题——吃药没效果、庄稼长不好、手机充不上电。
但之前给AI做的“质检培训”,全是针对汽车外壳、手机屏幕这种大物件,面对这些小东西,有三个绕不开的麻烦:
- 看不见:瑕疵太小了,就像在一粒米上找一个针尖大的霉点,肉眼都费劲,AI更难捕捉;
- 看不全:只拍一张正面照(单视角),背面的裂痕根本拍不到,就像检查核桃有没有坏,只看一面肯定会漏检;
- 学不会:之前的AI只会死记硬背图片里的瑕疵长什么样,没有配套的“知识点”,不知道“发霉是什么、为什么会发霉”,换个没见过的小东西就彻底失灵了。
2. 论文的核心方法
作者们做了一个叫MANTA的超级AI学习库,相当于给AI打造了一套完整的「微小物体质检全能教材」,核心分为三部分:
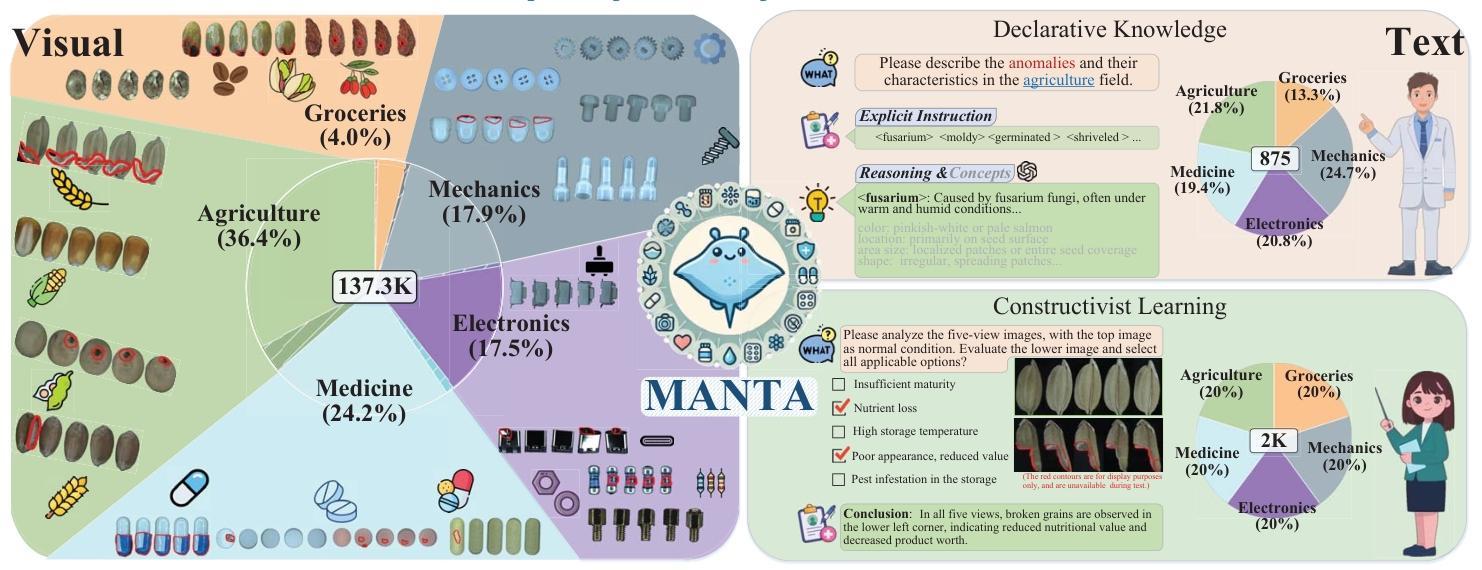
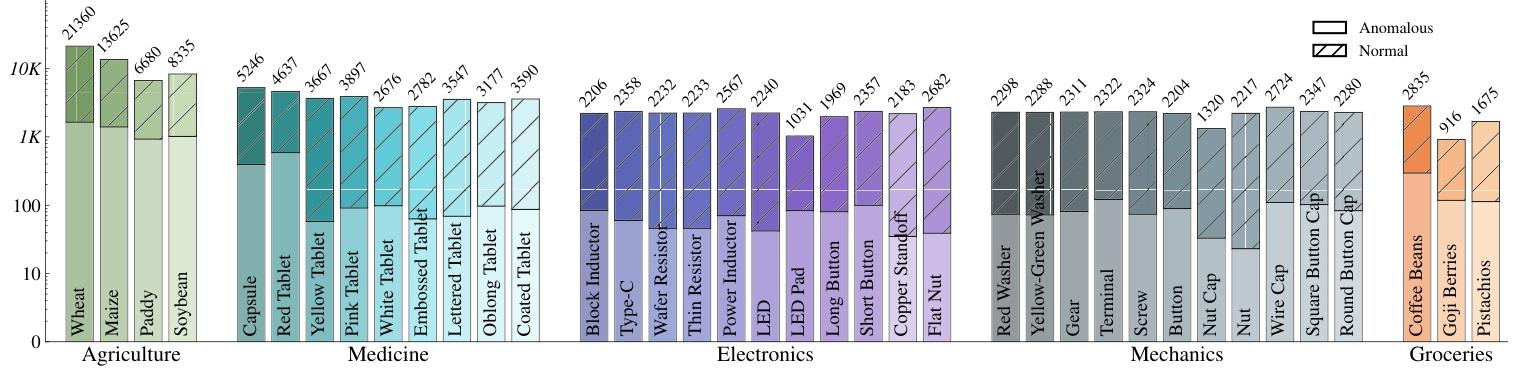
- 360°高清图片库:找了38种常见的小物件(麦粒、药片、Type-C接口、小螺丝、咖啡豆等),大小在4-20毫米之间,专门做了一个“5相机拍照神器”——4个相机斜着30度围一圈,1个相机从底下往上拍,就像给小东西做了全身CT,每个物件都拍5个角度的高清照片,连0.2毫米的瑕疵都能拍清楚。最终一共拍了13.7万张高清图,其中8600多张有瑕疵的图,还精准圈出了瑕疵的位置,就像老师给课本标了重点。
- 知识点手册:整理了875条关于瑕疵的专业知识,分领域讲清楚“这个瑕疵是什么、怎么产生的、长什么样”,比如农业里的“发霉”、医药里的“药片裂片”,让AI不仅能看到瑕疵,还能懂背后的原理。
- 练习题题库:出了2000道图文选择题,给AI看正常和有瑕疵的图片,让它判断有没有问题、问题是什么、有什么影响,就像考驾照的科目一,让AI从“死记硬背”变成“理解着做题”。
3. 方法的优缺点
核心优势
- 看得全:5个角度全覆盖,再也不怕瑕疵藏在背面,完美解决了单视角漏检的问题;
- 看得清:高清相机能捕捉0.2毫米的微小瑕疵,专门适配小物件的质检需求;
- 学得会:首创“图片+知识点+练习题”的模式,AI能真正理解瑕疵,而不是死记硬背,换个新物件也能尝试检测;
- 用得上:覆盖农业、医药、电子、机械、杂货五大刚需场景,能直接用到粮食选种、药品质检、手机零件检测等真实工作里。
局限性
- 仍有视觉死角:比如六边形的小螺母,5个相机也拍不到所有侧面,就像用5个手机拍骰子,总有几个面拍不到;
- 知识和题库规模有限:相比AI学过的海量知识,875个知识点和2000道题还是偏少,不足以支撑AI全量学习;
- 瑕疵场景不够全:现在的瑕疵很多是人工制作的,和工厂、农田里自然产生的真实瑕疵,还是有一定区别。
硕士阶段:深入分析、渐入佳境
1. 核心数学原理与基础概念铺垫
基础概念
- 异常检测(AD):核心任务是识别不符合「正常模式」的样本,工业质检是核心应用场景;主流无监督AD设定为:仅用正常样本训练模型,测试时区分正常/异常样本。
- 核心评价指标AUROC:受试者工作特征曲线下面积,取值0-100%,越接近100%模型性能越好,分为图像级AUROC(判断整张图是否存在异常)和像素级AUROC(精准定位异常的像素位置)。
- LoRA(低秩适配):大模型高效微调技术,冻结预训练模型的主干权重,仅用两个低秩矩阵拟合权重更新量,大幅降低训练显存占用,同时缓解灾难性遗忘。
核心公式与原理
-
交叉熵损失(分类任务核心损失)
[L_{ce}=-\sum_{i=1}^{B} c_{i} log \left(\hat{c}_{i}\right)]
公式解释:(B)为批次大小,(c_i)为真实类别标签(正常/异常、物体类别),(\hat{c}_i)为模型预测的类别概率。该损失衡量模型预测分布与真实分布的差异,值越小,分类精度越高。论文中用该损失优化模型的物体分类与异常判断能力。 -
自回归损失(文本生成任务核心损失)
L a r = − 1 B ∑ i = 1 B ∑ t = 1 T log p θ ( x i , t ∣ x i , < t , I ) L_{ar} = -\frac{1}{B} \sum_{i=1}^{B} \sum_{t=1}^{T} \log p_{\theta}(x_{i,t} | x_{i,<t}, I) Lar=−B1i=1∑Bt=1∑Tlogpθ(xi,t∣xi,<t,I)
公式解释:(x_{i,t})为文本序列的第(t)个token,(I)为输入图像,(p_{\theta})为模型的条件概率分布。该损失优化模型基于图像和前文生成正确答案的能力,是论文中问答任务的核心优化目标。
2. 论文核心方法与技术细节
(1)视觉数据集构建技术
- 样本采集:筛选300K+微小物体,尺寸范围(43-203 mm^3),最终覆盖农业、医药、电子、机械、杂货5大领域38个类别,人工引入可控缺陷保证异常样本均衡性。
- 采集原型设计:5台高分辨率相机(4台四边形排布、向下倾斜30°,1台垂直底部向上拍摄),双侧无影光源保证均匀无阴影光照;相机DPI分别为1170(侧视)、1250(底视),可检测最小(0.2^3 mm^3)的缺陷。
- 预处理与标注:原始图像分辨率1272×1016,经形态学操作定位物体中心、裁剪、背景去除、颜色校准,将5个视角图像对齐合并为单张五视角复合图像;4名专业标注人员完成正常/异常分类,通过CVAT工具完成像素级异常掩码标注,经分类/分割模型过滤低质量标注后人工复核,最终得到137338张多视角图像,其中8617张异常图像带像素级标注。
(2)双文本子集设计
-
Declarative Knowledge(DeclK,陈述性知识)
基于认知负荷理论,构建<what, why, how>三级知识体系:- Explicit Instruction:异常类型的标准化术语(如发霉、划痕),共875条,含391条类别专属术语;
- Reasoning:异常的成因与发生机理;
- Concepts:异常的视觉特征(颜色、形状、纹理、位置)。
所有知识以JSON格式存储,实现图文知识的标准化对齐。
-
Constructivist Learning(ConsL,建构主义学习)
基于双编码理论,构建2000道图文多选题,分易、难两个难度,每个题目包含正常-正常/正常-异常图像对、5个领域专属选项、标准答案与解析。任务要求模型完成异常存在性判断、异常描述、推理决策,模拟人类的对比学习过程。
(3)基线模型架构
基于BLIP-2多模态框架,采用LoRA进行高效微调:
- 主干结构:冻结预训练的ViT图像编码器、OPT大语言模型,仅在视觉分支、Q-Former(查询Transformer,桥接视觉与语言模态)、语言分支添加LoRA模块,秩r=8;
- 输入流程:垂直拼接的图像对+固定文本prompt,经图像编码器提取视觉特征,与token化的文本特征拼接后输入Q-Former,最终输入LLM生成答案;
- 优化策略:两阶段训练,先通过交叉熵损失优化物体分类任务,再通过自回归损失优化问答任务,缓解小数据集过拟合。
3. 实验设计与结果分析
(1)实验设置
论文设计了5种全覆盖的评估设定,对应传统AD到多模态AD的全场景:
| 实验设定 | 输入形式 | 任务目标 |
|---|---|---|
| 单视角设定 | 单张视角图像,单类别训练 | 传统单视角异常检测 |
| 多视角设定 | 单个物体的5张视角图像,单类别训练 | 多视角融合异常检测 |
| 多类别设定 | 单视角图像,同领域全类别混合训练 | 单模型多类别异常检测 |
| 文本prompt设定 | 单视角图像+DeclK文本prompt | 少样本/零样本异常检测 |
| 视觉语言设定 | 图像对+ConsL题目prompt | 多模态异常推理问答 |
(2)核心实验结果
-
纯视觉任务结果
- 单视角设定:测试了RD、DMAD、PatchCore等主流AD算法,所有模型平均I-AUROC均低于97%,农业/杂货领域平均低于90%,远低于MVTec AD上接近100%的性能,凸显数据集的挑战性;其中PatchCore性能最优,平均I-AUROC/P-AUROC为93.7%/95.7%;重建类算法(RD、DMAD)性能最差,核心原因是微小物体的异常区域占比大,重建模型无法有效区分正常与异常特征。
- 多视角设定:所有模型平均I-AUROC达91%、P-AUROC达94%,相比单视角有显著提升,证明多视角信息的互补性;PatchCore仍保持最优,平均I-AUROC/P-AUROC为95.0%/95.7%。
- 多类别设定:测试了UniAD、CRAD等主流多类别AD算法,平均I-AUROC低于90%、P-AUROC低于91%,相比单/多视角显著下降,核心原因是同领域内不同类别的外观差异极大,模型难以同时学习所有类别的正常模式。
-
视觉语言任务结果
- 文本prompt设定:基于DeclK测试了WinCLIP、PromptAD等算法,one-shot设定下WinCLIP性能最优,平均I-AUROC超75%、P-AUROC超90%,证明DeclK的文本知识可有效提升视觉语言模型的AD性能。
- 视觉语言设定:基于ConsL测试了Llava1.5、InternVL2等主流多模态大模型,以及论文提出的BLIP-2+LoRA基线;few-shot设定下,基线模型平均选项准确率仅52.7%,问题准确率仅3.0%,证明该任务对模型的跨模态推理能力提出了极高挑战,现有模型仍有巨大提升空间。
(3)与现有数据集的对比
相比MVTec AD、VisA、Real-IAD等主流AD数据集,MANTA在样本规模、类别数量、标注密度上均领先,是首个同时提供完备多视角数据和双文本子集的微小物体AD数据集,也是唯一同时支持5种任务设定的AD基准数据集。
博士阶段:深入拆解、实现复现
1. 研究动机与创新点深度剖析
(1)研究背景与动机的底层逻辑
论文精准击中了异常检测领域三大未被解决的核心痛点:
- 数据集的尺寸偏见与领域空白:主流AD数据集均聚焦大尺寸工业物体,而4-20mm微小物体的AD任务在农业选种、医药质检、精密电子/机械制造等场景有极强刚需,却长期处于研究空白。微小物体AD存在三大固有挑战:
- 类内异质性:自然物体(麦粒、咖啡豆)的正常样本本身存在形状、颜色、纹理的天然差异,模型难以区分「正常波动」与「异常缺陷」;
- 姿态无关性:微小物体的姿态难以精准控制,同一物体不同视角的外观差异极大,传统单视角模型极易漏检;
- 尺寸敏感性:微小物体的尺寸偏差直接影响功能(药片剂量、螺丝装配),模型需要对微米级尺寸变化有极高敏感度,这是现有数据集从未覆盖的。
- 多视角AD数据集的不完备性:现有多视角数据集(Real-IAD)需要人工干预才能实现全表面检测,无法适配工业产线的自动化质检;而MANTA的5相机固定布局,可实现微小物体的自动化全表面成像,无需人工调整姿态。
- 大模型时代的模态缺失:现有AD数据集均为纯视觉数据,无法适配CLIP、BLIP-2等视觉语言大模型的预训练范式,而工业质检场景中存在大量领域专家文本知识,现有数据集无法实现图文知识对齐,限制了大模型在AD任务中的应用。
(2)核心创新点的学术贡献拆解
- 数据集范式创新:首次提出「视觉+双文本子集」的AD数据集范式,突破了传统纯视觉AD数据集的模态限制,将AD任务从「纯视觉模式匹配」升级为「视觉-语言联合推理」,为大模型时代的AD研究提供了全新基准。
- 认知科学与AD的交叉创新:DeclK子集基于认知负荷理论,ConsL子集基于建构主义学习理论与双编码理论,首次将认知科学理论引入AD数据集设计,让AI的异常检测学习过程贴近人类认知逻辑,为可解释AD研究提供了新思路。
- 任务设定的全面性创新:首次同时支持单视角、多视角、多类别、文本prompt、视觉语言5种AD任务设定,覆盖了从传统无监督AD到少样本/零样本AD、再到多模态推理AD的全场景,为AD算法的全面评估提供了统一平台。
- 领域标准化创新:首次针对微小物体的三大固有挑战构建了标准化数据集,填补了该领域的基准空白,为农业、医药、精密制造等场景的AD算法研发提供了数据支撑。
2. 数学推导与核心技术深度剖析
(1)LoRA低秩适配的数学原理与实现细节
对于预训练模型的线性层权重(W \in \mathbb{R}^{d \times k}),常规微调会更新整个W,导致计算量巨大且易出现灾难性遗忘。LoRA的核心是冻结W,仅学习更新量(\Delta W),并将(\Delta W)分解为两个低秩矩阵的乘积:
Δ W = B A , B ∈ R d × r , A ∈ R r × k \Delta W = BA, \quad B \in \mathbb{R}^{d \times r}, \quad A \in \mathbb{R}^{r \times k} ΔW=BA,B∈Rd×r,A∈Rr×k
其中秩(r \ll min(d,k)),训练时A用高斯分布初始化,B初始化为0,保证训练初始阶段(\Delta W=0),不影响预训练权重。前向传播时,输出为:
h = W x + Δ W x = W x + B A x h = Wx + \Delta W x = Wx + BAx h=Wx+ΔWx=Wx+BAx
论文中,在BLIP-2的ViT图像编码器、Q-Former、OPT语言模型的注意力层均添加了LoRA模块,秩r=8,将可训练参数降低了2个数量级,解决了大模型微调的显存与过拟合问题。
(2)损失函数的联合优化逻辑
论文采用两阶段训练策略,实现分类与生成任务的联合优化:
-
第一阶段:分类任务预训练
用多分类交叉熵损失优化模型的视觉特征提取能力,让模型学习不同类别的细粒度特征:
L c e = − 1 B ∑ i = 1 B ∑ c = 1 C y i , c log ( y ^ i , c ) L_{ce} = -\frac{1}{B} \sum_{i=1}^{B} \sum_{c=1}^{C} y_{i,c} \log(\hat{y}_{i,c}) Lce=−B1i=1∑Bc=1∑Cyi,clog(y^i,c)
其中(C)为类别总数,(y_{i,c})为one-hot真实标签,(\hat{y}_{i,c})为模型预测的类别概率。该阶段预训练的分类头,为后续问答任务提供了稳定的视觉特征基础。 -
第二阶段:问答任务微调
用自回归损失优化模型的跨模态推理能力,对于长度为T的文本序列,损失函数为:
L a r = − 1 B ∑ i = 1 B ∑ t = 1 T log p θ ( x i , t ∣ x i , < t , I ) L_{ar} = -\frac{1}{B} \sum_{i=1}^{B} \sum_{t=1}^{T} \log p_{\theta}(x_{i,t} | x_{i,<t}, I) Lar=−B1i=1∑Bt=1∑Tlogpθ(xi,t∣xi,<t,I)
其中(x_{i,t})为第t个token,(I)为输入图像,(p_{\theta})为模型的条件概率分布。该损失优化模型基于图像和前文生成正确答案的能力,实现视觉特征与语言知识的对齐。
(3)多视角特征融合的底层逻辑
多视角设定下,模型输入为5个视角的拼接图像,传统AD算法的感受野无法有效捕捉不同视角的互补信息。论文中通过特征金字塔多尺度融合,将不同视角的特征映射到同一特征空间,再通过全局平均池化聚合多视角特征,实现对单个物体的全局异常判断。核心逻辑是:同一物体的不同视角共享类别级的正常特征,而异常特征仅在部分视角出现,多视角融合可放大异常特征与正常特征的距离,提升检测精度。
3. 复现步骤与工程实现细节
(1)复现环境准备
- 硬件:NVIDIA A100/V100 GPU(显存≥40G,多视角训练建议≥80G),CPU核心≥16,内存≥64G;
- 软件:Ubuntu 20.04,Python 3.8+,PyTorch 2.0+,CUDA 11.7+;核心依赖库:timm、transformers、peft、opencv-python、scikit-learn、mmcv;
- 数据获取:从官方网站https://grainnet.github.io/MANTA下载数据集,包括视觉图像、像素级标注、DeclK JSON文件、ConsL问答对,按官方格式组织目录。
(2)数据预处理复现
- 图像预处理:读取原始五视角图像,用OpenCV完成形态学开运算去除背景,通过轮廓检测定位物体中心,裁剪为固定尺寸,基于标准色板完成白平衡与颜色校准,将5个视角的图像按固定顺序垂直拼接,生成模型输入的复合图像;
- 标注处理:读取CVAT生成的掩码标注,转换为COCO格式,生成训练/测试集标注文件;按论文规则划分数据集:每个类别若有N张异常图像,测试集包含2N张正常图像+全部N张异常图像,剩余正常图像作为训练集,保证类别均衡。
(3)纯视觉任务复现
- 单视角设定:将复合图像拆分为单张视角图像,分别作为训练/测试样本;基于timm库实现PatchCore、RD、CDO等算法,输入尺寸224×224,backbone采用ImageNet预训练的WideResNet-50,按论文超参设置训练,计算图像级和像素级AUROC;
- 多视角设定:输入为完整的五视角复合图像,调整输入尺寸为224×1120,修改backbone为多尺度特征提取器,在特征层完成5个视角的特征融合,其余超参与单视角一致;
- 多类别设定:将同一领域所有类别的单视角图像混合,训练统一模型,backbone采用UniAD官方实现,超参按论文设置。
(4)视觉语言任务复现
- 文本prompt设定:基于Hugging Face的CLIP模型实现WinCLIP,从DeclK中提取异常术语,构建正样本prompt「a photo of a normal {category}」,负样本prompt「a photo of a {category} with {anomaly}」;按one-shot设定,每个类别选取1张正常样本作为支撑集,计算测试集AUROC;
- ConsL基线模型复现:基于transformers库的BLIP-2模型,用peft库添加LoRA模块,冻结ViT和OPT主干权重,仅训练LoRA参数;输入为垂直拼接的正常/异常图像对+论文固定prompt,批次大小8,学习率1e-4,优化器AdamW,训练轮数10;用50%的ConsL数据训练,50%测试,计算选项准确率与问题准确率。
(5)复现难点与解决方案
| 复现难点 | 核心解决方案 |
|---|---|
| 多视角图像显存占用过高 | 梯度累积、混合精度训练、模型并行,降低LoRA秩至4,减少可训练参数 |
| 微小异常的像素级定位精度不足 | 多尺度特征融合,放大低层级细节特征,添加Dice损失辅助优化分割任务 |
| ConsL任务模型过拟合 | prompt增强、随机翻转/亮度调整等数据增强、早停策略,仅验证集损失下降时保存模型 |
| 不同视角图像对齐误差 | 预处理阶段采用SIFT特征点匹配,完成5个视角图像的亚像素级对齐,保证特征空间一致性 |
4. 实验结果深度分析
- 领域性能差异的底层原因:农业和杂货领域性能显著低于医药、电子、机械领域,核心原因是农业/杂货样本以自然物体为主,类内异质性极强,正常样本的天然波动远大于工业化生产的标准化物体,模型决策边界极难确定;而医药、电子、机械样本为标准化生产,正常样本一致性极高,模型更容易学习正常模式。
- 算法性能差异的本质逻辑:PatchCore等基于特征匹配的算法性能显著优于重建类算法,核心原因是重建类算法的核心假设是「异常区域无法被正常重建」,但微小物体的异常区域占比往往很大,重建模型会学习到异常的通用特征,导致异常区域也能被很好地重建,无法形成有效重建误差;而PatchCore基于正常样本的特征库进行匹配,异常样本特征与特征库的距离更大,更适配微小物体AD任务。
- 多视角性能提升的边界:多视角设定的性能提升幅度仅1-2个百分点,并非线性提升,核心原因是:部分异常在多个视角中均可见,多视角融合无法带来额外增益;极端视角的异常仅在单个视角可见,多视角融合只能缓解视角缺失问题,无法解决微小异常的特征提取难题;同时多视角图像尺寸更大,模型感受野无法有效覆盖所有细节,导致部分定位误差。
- 视觉语言任务的性能瓶颈:现有多模态大模型在ConsL任务上性能极差,核心瓶颈有三点:① 预训练数据域gap,大模型预训练图像以自然场景、日常物体为主,几乎没有微小物体的高清特写图像,视觉特征适配性极差;② 任务复合性,ConsL任务需要模型完成「正常/异常对比→异常识别→异常属性推理→多选项判断」的多步推理,现有大模型多步推理能力不足;③ 视觉粒度不匹配,ViT的patch size为14×14,无法捕捉0.2mm级的微小异常特征。
5. 局限性与未来研究方向
(1)论文方法的局限性
- 数据集本身的局限性:① 视角覆盖不足,5相机布局无法实现360°全表面覆盖,棱柱形、六边形物体仍存在视觉死角;② 异常分布偏差,人工引入的异常与真实工业场景的自然异常在形态、分布上存在差异,模型真实场景泛化能力有待验证;③ 文本子集规模有限,875条术语和2000道问答对,无法支撑大模型全参数微调;④ 模态单一,仅提供RGB图像,缺乏高光谱、3D点云、红外等多模态数据,无法覆盖更多工业检测场景。
- 基线模型的局限性:① 仅基于BLIP-2构建基线,未充分探索其他多模态架构的适配性,基线上限不足;② 未针对微小物体特征提取优化视觉编码器,采用通用ViT,无法有效捕捉微小异常的细粒度特征;③ 未利用DeclK的领域知识做prompt优化,仅用通用prompt,未充分发挥图文知识的协同作用。
(2)未来研究方向
- 面向微小物体的专用AD模型设计:针对异质性、姿态无关性、尺寸敏感性三大挑战,设计专用特征提取器、多视角融合模块、异常评分函数,提升微小异常检测能力;
- 多模态AD模型研发:基于MANTA的图文数据,设计融合DeclK领域知识的视觉语言AD模型,提升零样本/少样本场景性能,实现「文本描述异常,模型即可检测」的开箱即用能力;
- 高效多视角AD算法:设计轻量化多视角特征融合算法,在保证性能的同时降低计算成本,实现工业产线实时检测;
- 数据集拓展:增加更多类别、真实场景自然异常样本、多模态数据,完善DeclK和ConsL规模,构建更全面的微小物体AD基准;
- 可解释AD研究:基于ConsL问答任务,研发可解释AD模型,让模型不仅能检测异常,还能输出异常的类型、成因、影响,实现「检测+诊断」全流程。
6. 隐藏难点与研究挑战
(1)论文未明确提及的核心难点
- 数据采集的高精度控制:微小物体成像需要极高的对焦精度、光照均匀性和相机标定精度,0.1mm的对焦误差就会导致图像模糊,无法捕捉微小异常,这是数据集构建最核心的工程难点,论文未提及标定、对焦、光照控制的具体实现细节;
- 标注一致性控制:微小异常的标注需要极高专业度,不同标注人员对「正常波动」和「异常」的判断标准存在差异,尤其是自然物体样本,标注一致性极难保证,论文未提及标注一致性的量化指标(如IoU、Kappa系数);
- 多视角特征的空间对齐:不同视角图像中,同一物体的特征在空间位置上存在差异,传统卷积网络无法实现跨视角特征对齐,导致多视角融合效果无法达到最优,这是多视角AD任务的核心研究挑战;
- 视觉粒度与patch size的本质矛盾:现有大模型ViT编码器的patch size通常为14×14,对于224×224的图像,单个patch对应实际物体尺寸约为0.4mm,无法捕捉0.2mm级的微小异常,这是视觉语言模型在微小物体AD任务中的核心瓶颈。
(2)潜在研究空白
- 神经符号推理的微小物体AD:将DeclK的符号化领域知识与神经网络的视觉特征提取结合,实现神经符号推理的AD模型,同时提升检测性能与可解释性;
- 主动学习的微小物体AD:基于MANTA设计主动学习策略,用最少的标注样本实现最优AD性能,降低工业场景标注成本;
- 联邦学习的微小物体AD:针对不同工厂、不同领域的数据隐私问题,设计联邦学习AD模型,在不共享原始数据的前提下实现多领域模型联合优化;
- 端侧轻量化微小物体AD:设计适配MCU、FPGA等端侧设备的轻量化AD模型,实现工业产线的边缘实时检测。
分阶段一句话核心总结
- 小白一句话总结:这篇论文打造了一套专门教AI给米粒、药片、小螺丝这些超小物件找瑕疵的「学习大全」,不仅有各个角度的高清照片,还有配套的知识点和练习题,让AI能看得更全、学得更明白,大大提升了小物件质检的能力。
- 硕士一句话总结:论文提出了首个面向4-20mm微小物体的大规模多视角图文异常检测数据集MANTA,构建了包含137.3K五视角图像的视觉分支与陈述性知识、建构主义问答双文本子集,设计了基于BLIP-2+LoRA的多模态基线模型,通过5种任务设定的系统基准测试,验证了数据集的有效性与领域挑战性,为微小物体异常检测的算法研发提供了标准化基准。
- 博士一句话总结:MANTA填补了微小物体异常检测领域多视角、多模态基准数据集的空白,其基于认知科学理论设计的双文本子集,突破了传统纯视觉异常检测数据集的模态限制,为视觉语言大模型在异常检测任务的应用开辟了全新范式,不仅为农业、医药、精密制造等刚需场景提供了标准化数据支撑,也为可解释异常检测、零样本/少样本异常检测的交叉研究提供了核心基准与创新方向。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)