Rational-Aware Tool Integrated via Reinforcement Learning
核心聚焦工具增强大语言模型(LLMs)的自适应推理优化。针对现有工具增强 LLMs 采用固定推理深度导致的 “简单任务过度思考、复杂任务思考不足” 问题,提出了基于强化学习的 RATIR(Rational-Aware Tool Integrated via Reinforcement Learning)框架,通过任务难度感知的动态推理深度调整与层级化奖励机制,实现了准确性、工具使用精度与推理效率的协同优化,为实用化工具增强 LLM 系统提供了关键解决方案。
一、研究背景与核心问题
1.1 研究动机
工具增强大语言模型(Tool-augmented LLMs)通过 “推理 - 工具调用 - 结果整合” 的闭环,显著扩展了 LLMs 的任务覆盖范围,但现有方法存在核心局限:
- 推理策略僵化:采用固定推理深度与工具调用预算,对所有任务 “一视同仁”—— 简单任务中过度推理导致 token 消耗冗余,复杂任务中思考不足导致性能瓶颈;
- 训练方法缺陷:监督微调(SFT)依赖静态数据,在混合难度场景中鲁棒性差;传统强化学习(如 RLHF)易出现奖励黑客(Reward Hacking),甚至放大冗长推理轨迹;
- 工具对齐不足:忽视工具调用的结构化约束(如函数 schema 格式),导致工具调用错误率高,且未协同优化推理深度与工具使用策略。
人类推理的核心优势在于 “情境自适应”—— 简单任务快速决策,复杂任务深度思考。受此启发,论文提出:工具增强 LLMs 需实现 “实例级自适应”,根据任务难度动态调整推理深度与工具使用行为,平衡性能与计算成本。
1.2 核心研究问题
- RQ1:RATIR 框架能否在提升任务成功率的同时,降低计算开销,实现准确性与效率的双赢?
- RQ2:层级化细粒度奖励结构如何影响强化学习的稳定性与收敛速度,尤其是优势估计方差的降低效果?
- RQ3:如何通过语义、过程与实证指标的混合量化任务复杂度,为自适应推理提供可靠依据?
- RQ4:随着任务难度提升,RATIR 相对基线模型的性能优势是否能持续保持?
1.3 研究贡献
- 提出 RATIR 框架:首个实现工具增强场景下 “推理深度 - 工具使用” 联合自适应的强化学习框架,适配任务难度动态调整策略;
- 创新奖励机制:设计层级化、schema 分解的奖励函数,精准优化工具调用各环节(名称、参数、类型等),降低优势估计方差;
- 构建复杂度评估体系:融合静态语义熵、过程必要性与实证成功率,实现任务难度的可靠量化;
- 实证验证优势:在 BFCL 与 ToolBench 基准上,以 Qwen2.5-7B 为骨干模型时,准确率比强基线提升 4.9%,token 消耗减少 28.6%,函数 schema 错误率降至 3.9%。
二、核心方法:RATIR 框架设计
RATIR 框架包含数据处理、SFT 热身、强化学习优化、增强推理四大阶段,核心逻辑是 “难度感知 - 自适应策略 - 精准奖励” 的闭环,架构如图所示。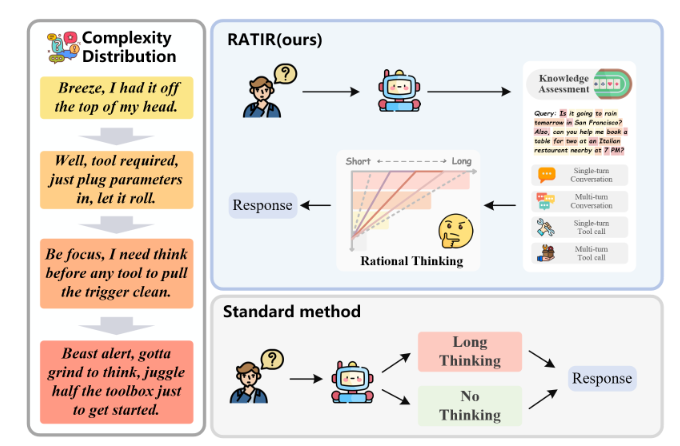
2.1 基础定义与任务形式化
(1)核心符号与动作空间
- 环境与输入:工具环境E(含函数 schemaS)、用户查询q;
- 动作空间:(推理)(工具调用,为工具名,z为参数), answer (y)(生成答案)});
- 轨迹与终止:轨迹τ=(q,{(st,at,ot)}t=1T),当生成答案或达到最大步数Tmax时终止。
(2)任务目标
在工具增强推理场景中,联合优化三大目标:
- 答案准确性:最终响应与真实结果的一致性;
- 工具使用精度:工具调用的 schema 合规性(格式、类型、约束等);
- 推理效率:最小化 token 消耗与推理步数。
2.2 任务复杂度量化
为实现自适应推理,论文提出多维度复杂度评分D(T),融合三类指标:
- 静态复杂度Cnorm(T):基于归一化香农熵,量化查询的语义模式多样性;
- 过程必要性CoT(T):二进制指标,标记是否需要链式思维(CoT)推理;
- 实证难度1−SR(T):基于模型执行成功率的反向指标,反映任务实际难度。
最终复杂度评分通过加权线性组合得到:D(T)=w1⋅Cnorm(T)+w2⋅CoT(T)+w3⋅(1−SR(T))其中w1,w2,w3通过实证确定,用于平衡三类指标的影响。
2.3 数据处理与课程学习
(1)数据集构建
- 训练数据:构建 4000 条工具增强推理语料,每条包含 “推理 - 工具调用 - 结果” 轨迹,涵盖正确响应与最小错误响应,覆盖不同难度级别;
- 数据过滤:剔除畸形 JSON、类型不匹配、占位符未解析等低质量样本;
- 课程采样:采用 “Easy to Hard” 渐进式采样策略,easy 样本的采样概率随训练步数线性降低(peasy(t)=1−t/T),逐步强化模型对复杂任务的处理能力。
2.4 分层训练流程
(1)SFT 热身训练
基于工具增强 CoT 数据集初始化模型,目标是掌握基础推理链生成与工具调用格式,损失函数为标准对数似然损失:LSFT(θ)=E(x,y)∼Ds[∑t=1Tlogpθ(yt∣y1:t−1,x)]其中x为输入提示,y为目标轨迹(推理 + 工具调用 + 答案)。
(2)强化学习优化(核心创新)
基于 GRPO 算法扩展,设计 Tool Verifiable Reward(TVR)优化目标,核心是层级化奖励机制与 KL 正则化:LTVR_GRPO(θ)=G1∑i=1Gmin[πθold(at∣st)πθ(at∣st)A^t(w),clip(⋅)A^t(w)]−βDKL[πθ∥πref]其中β=2×10−2(平衡探索与格式稳定性),A^t(w)为加权优势估计。
层级化奖励设计(RC=RThink+RFormat+RTool)
-
推理奖励RThink:难度敏感型奖励,惩罚简单任务的冗长推理,优先保证复杂任务的正确性:(简单任务)(复杂任务)其中α(ra,L)为长度惩罚系数,ra为答案得分,L为响应长度。
-
格式奖励RFormat:二进制奖励,工具调用格式(标签顺序、JSON 结构)正确得 1 分,否则得 0 分。
-
工具奖励RTool:细粒度分解奖励,覆盖工具调用全环节:
- 工具名匹配rname:基于 Ochiai 系数,衡量预测与真实工具名的重叠度;
- 参数结构奖励rparam:需同时满足参数键、类型、约束匹配,否则得 0.5 分;
- 参数值匹配rvalue:精准匹配参数值的比例;
- 完美匹配奖励rperfect:全环节无错误时额外加 1 分。
最终工具奖励经归一化后缩放至[−2,2]区间,确保与其他奖励分量的平衡。
2.5 增强推理阶段
推理时,模型基于输入复杂度评分D(T)动态调整策略:
- 简单任务(Scomp<θcomp):压缩推理步骤,减少不必要的工具调用;
- 复杂任务(Scomp≥θcomp):延长推理链,充分调用工具补充信息;
- 复杂度阈值:默认采用 80 分位数阈值,在保证准确性的同时,最大化降低 token 消耗。
三、实验设计与结果
3.1 实验设置
(1)数据集
- 评估基准:BFCL(Berkeley Function Calling Leaderboard,5551 个测试样本,覆盖单轮 / 多步 / 并行工具调用)、ToolBench(16000 + 真实 API,49 个类别);
- 训练数据:4000 条工具增强推理语料,含不同难度与错误类型样本。
(2)基线模型与对比方法
- 基础模型:Qwen2.5-7B-instruct、Qwen2.5-Coder-7B、Llama-3.2-8B-instruct;
- 训练范式基线:SFT(监督微调)、GRPO(基础强化学习);
- 工具增强基线:Toolformer、ReAct、Gorilla、Granite、ToolAlign、OTC 等。
(3)评估指标
- 准确性指标:BFCL 的 Non-Live AST Accuracy(非交互场景准确率)、Live Accuracy(交互场景准确率);ToolBench 的 Pass Rate(执行成功率)、Win Rate(相对质量得分);
- 效率指标:平均推理 token 长度;
- 可靠性指标:函数 schema 错误率(格式、类型、约束等错误占比)。
3.2 核心实验结果
(1)主任务性能对比
RATIR 在三类基础模型上均实现一致提升,核心结果如下(以 Qwen2.5-7B-instruct 为例):
表格
| 方法 | BFCL Overall(%) | BFCL Non-Live(%) | BFCL Live(%) | ToolBench Pass(%) | ToolBench Win(%) | token 消耗降低率 |
|---|---|---|---|---|---|---|
| SFT | 82.58 | 86.23 | 78.90 | 64.13 | 63.03 | - |
| GRPO | 83.67 | 87.05 | 80.29 | 71.43 | 67.13 | - |
| RATIR | 87.82 | 88.24 | 87.40 | 82.03 | 81.33 | 28.6% |
关键发现:
- RATIR 比 GRPO 基线准确率提升 4.9%,ToolBench Pass/Win 率分别突破 82% 和 81%;
- 非交互与交互场景性能差距仅 0.83%,证明模型在真实工具执行场景中的鲁棒性;
- 函数 schema 错误率从 6.3% 降至 3.9%,工具调用可靠性显著提升。
(2)消融实验:核心组件有效性
通过移除关键组件验证其贡献(基于 Qwen2.5-7B-instruct):
表格
| 方法 | BFCL Overall(%) | 优势估计方差 | 核心结论 |
|---|---|---|---|
| RATIR(完整) | 87.82 | 0.10 | 基准性能 |
| 移除完美匹配奖励 | 85.31 | 0.15 | 缺乏强优化信号,收敛变慢 |
| 移除细粒度奖励 | 84.76 | 0.18 | dense 反馈缺失,工具调用方差增大 |
| 移除格式奖励 | 83.29 | 0.16 | 格式约束不足,JSON 错误增多 |
| 移除推理奖励 | 82.64 | 0.20 | 无难度适配,过度 / 不足思考问题复发 |
关键结论:层级化奖励各组件互补,细粒度反馈使优势估计方差降低 50%(相较于 GRPO 的 0.21),显著提升训练稳定性。
(3)课程学习与复杂度阈值影响
- 课程策略对比:“Easy to Hard” 策略最优(准确率 30.6%,平均长度 175.2token),优于 “Hard to Easy”(准确率 24.3%,长度 426.3token)与两阶段策略;
- 复杂度阈值:80 分位数阈值平衡效果最佳,BFCL 准确率 87.6%,token 长度 175.5,比无阈值场景减少 64%。
(4)不同难度任务的性能表现
- 简单任务(Level 1-3):RATIR 与基线差距较小(<1%),但 token 消耗降低更显著(32%);
- 复杂任务(Level 4-6):差距持续扩大,Level 6 时 RATIR 比 GRPO 提升 6.1%,证明难度感知自适应的核心价值。
四、理论与实践意义
4.1 理论意义
- 构建了工具增强推理的 “难度 - 策略” 自适应范式,为解决 “过度思考 / 思考不足” 提供理论框架;
- 提出层级化细粒度奖励机制,验证了 “精准信用分配” 对降低强化学习方差的关键作用;
- 建立多维度复杂度量化体系,为自适应推理提供可解释的难度判断依据。
4.2 实践意义
- 降低部署成本:28.6% 的 token 消耗减少直接降低 latency 与计算开销,适配多步工作流;
- 提升可靠性:schema 错误率降至 3.9%,减少下游系统因工具调用格式错误导致的故障;
- 强泛化性:在三类基础模型上均实现一致提升,支持开源模型部署,适配日历管理、企业自动化、旅行规划等真实场景。
五、局限性与未来方向
5.1 局限性
- 长 horizon 规划缺失:未建模长期任务的步骤规划,依赖单步自适应;
- 模型规模局限:主要评估 7B 级模型,未验证更大参数模型的适配性;
- 工具类型局限:聚焦静态 API,未支持多模态工具与有状态工具。
5.2 未来方向
- 整合规划机制:引入交互式修正与长期规划模块,适配更复杂任务;
- 扩展模型与工具:支持更大参数模型、领域专用模型及多模态工具;
- 优化奖励设计:融入预算感知效用函数,进一步平衡决策质量与效率;
- 多语言与低资源适配:扩展至多语言场景,优化低资源环境下的训练效率。
六、相关工作对比
表格
| 研究方向 | 代表工作 | 核心差异 |
|---|---|---|
| 长度可控推理 | CoT-Valve、ASRR | 仅优化推理长度,未结合工具使用与难度适配 |
| 工具对齐 | ToolAlign、Gorilla | 聚焦工具选择与参数准确性,缺乏推理深度自适应 |
| 高效工具使用 | OTC、ToolMem | 优化工具调用次数,未涉及推理链长度的动态调整 |
| 本研究(RATIR) | - | 首次联合优化推理深度与工具使用,基于难度感知实现自适应,层级化奖励提升稳定性 |
论文通过系统化的方法设计与实证验证,为工具增强 LLMs 的实用化提供了关键技术支撑,其核心创新点(难度感知、层级化奖励、课程学习)对后续自适应推理研究具有重要参考价值。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)