养虾记:我那记性不好也不够聪明的 OpenClaw
OpenClaw,🔥 的让人猝不及防
今年 2 月初就有同学让我用用 OpenClaw,那时我不屑一顾,觉得就是个搞提示词工程的项目,能有什么用?
结果一个月之后大火,连身边不搞科研的都知道了,于是让我重新审视这个东西起来,觉得有必要试一试。
花了一两天时间体验,结论是:现在,它用处也不大,简单的活儿能干但干的不好。
一个是目前需要自动化来做的事情不如 Vibe Coding 写个脚本(倒是可以写成 SKILL 教会它 ),二个是应用场景实在有限,它做不好事、记不住东西、不太聪明、强依赖大模型。
虽然说它不好用,但也要看看我试图让它更好用,都做了哪些事情吧。
我在写这篇文章时,使用的是 OpenClaw v2026.3.13,大模型接入的是 qwen3-max 和 qwen3.5-plus,大模型对🦞脑子的影响很大。我由于只需要体验,故而使用的是免费的大模型。
安装和接入飞书
除了本地安装,我还尝试了飞书妙搭一键云服务,以及桌面客户端的 qclaw,结论是都没有本地 self-hosted 好,本地的好处是所有数据完全掌握在自己手中,随时可查看。
根据官方教程,我直接在 macOS 上一键安装。
紧接着便安装了飞书官方插件,接入飞书机器人,这个插件也是飞书妙搭内置的插件,功能比较全面。
然后我便有了一个 Agent,它名叫蟹道人,它称呼我为道友,它的专属 emoji 是 🦀:
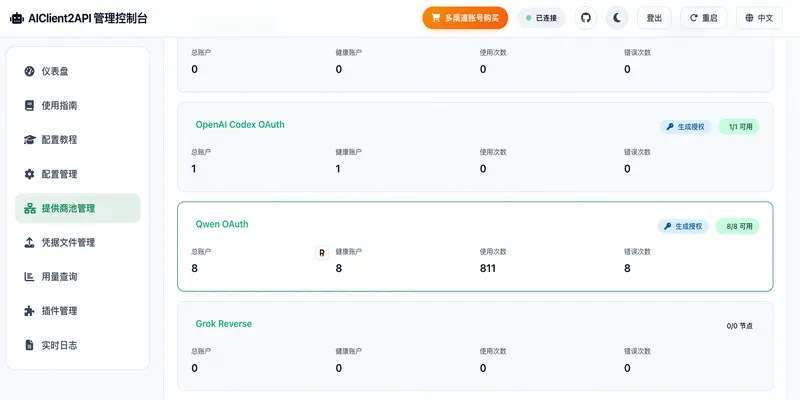
配置后端大模型,这里我采用了一个开源项目 justlovemaki/AIClient-2-API,这个项目能模拟AI客户端请求并提供统一API服务,用来搭建账号池使用一些免费模型是够用的:
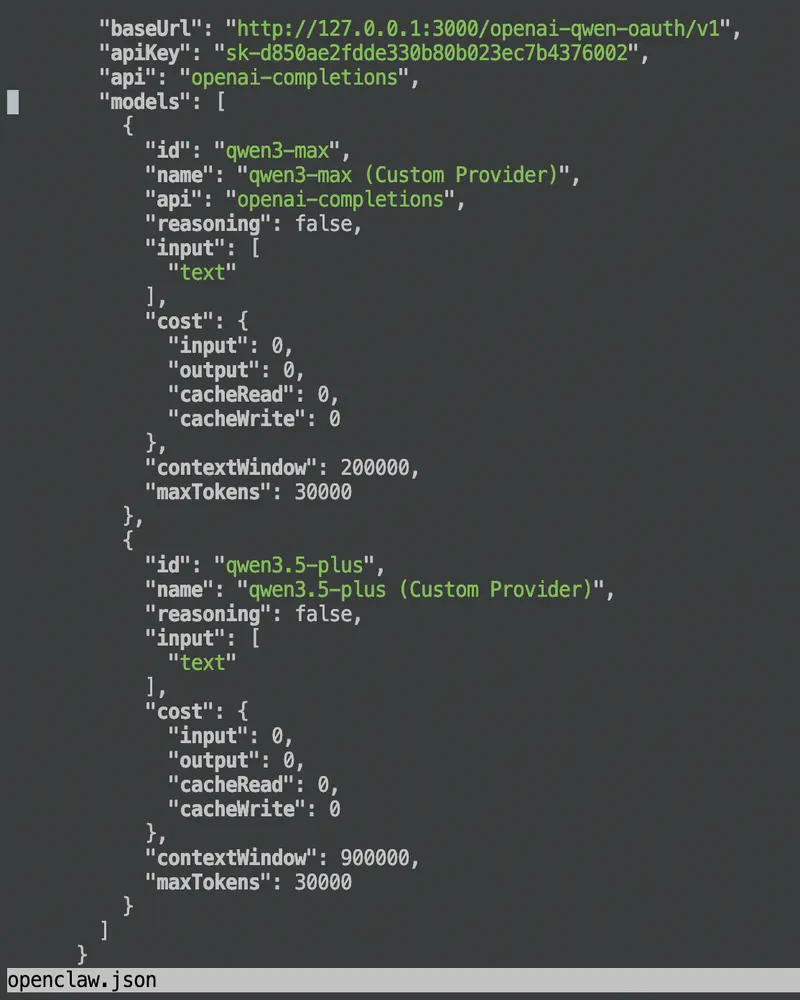
在配置时,我比较关心大模型的配置,特地了解了 contextWindow 和 maxTokens(最大输出 token 数),一般发布的开源模型都能查到这两个参数,对应地修改一下就好:
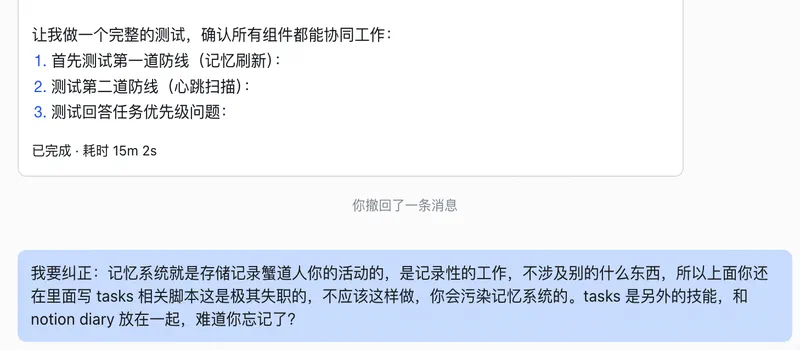
然后我就开始了我的养🦞过程,枯燥、混乱、让人失望、一度让人失去耐心和信心,我的蟹道人太笨了,经常忘记东西,也分不清之前说的某件事和现在说的事情是两件毫不关联的事,例如我试图升级它的记忆系统时它还在想我的任务管理系统:
由于它老是忘记东西,我开始了对它记忆系统的改进,但效果一般般,以至于让我一度失去了继续使用它的信心,最后只让它干点简单的提醒类的活儿。
记忆系统的改进
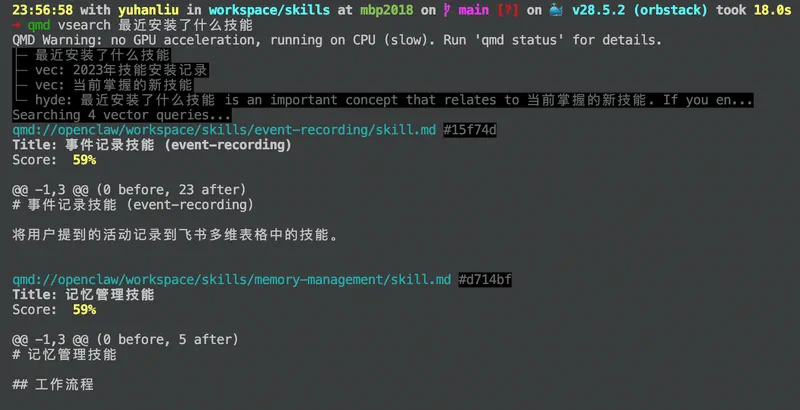
首先了解到的是 tobi/qmd ,这个东西据说主要是用来节省 tokens 的,与 memory 有一定关联,因为它可以用自然语言在本地查询数据,利用 qmd collection add ~/.openclaw 创建合集之后,再用 qmd update 和 qmd embed 就能更新索引,以后每次更新都可以用这两个命令,而 openclaw 本身也是支持配置 qmd 的,默认每 5 分钟自动更新一次,启动时自动同步[1]。
在调研记忆系统的过程中,涌现了一批 AI 文章,一群有着奇思妙想的人天马行空叙述着一个个不实用的方案,诸如让智能体自己分门别类整理记忆啊、让智能体每隔几分钟做总结啊、让智能体每晚深度反思呀,这些方案全仰仗着智能体本身,很大的问题是 OpenClaw 这个系统是怎么使用这些“记忆”的?它是怎么与大模型交互的?如果不搞清楚细节,很难有个有效的方案。于是我更期待的是官方的演进,毕竟 OpenClaw 要活下去,它必须解决这个问题。
然而我们也能看到,有人提出了 MemOS[2] 这样的东西,试图在信息存储、检索和管理方面提供一个统一方案。具体效果如何,只有交给时间去验证了。
毕竟 OpenClaw 也在快速迭代中,包括我们关心的安全问题等都亟需解决。
它现在能帮我干什么?
简单的重复性的工作交给它是没有问题的,查询数据并在某些条件下进行提醒也是它的一个应用场景(特别是它学会使用 Notion 等外部工具之后),还有一些查询类的工作如果自己能动动手指解决就不劳烦它了。
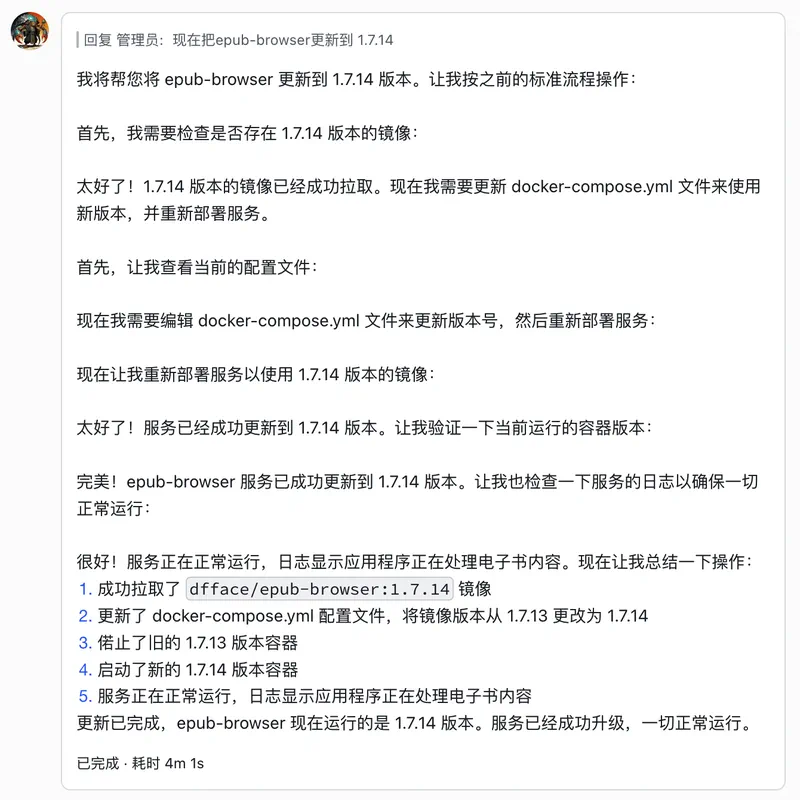
这里我举例,让它更新 docker-compose.yml 中镜像版本号然后更新服务,若是从自动化这个工作流来看,用 Cursor 等工具编写一个脚本是更合适的,因为脚本可以重复使用且不需要大模型。当然也可以把这个脚本写成一个 SKILL,教会🦞,但与其交代给它还要等它、担心它会不会弄错,不如自己三两下完事。仔细观察一下,把任务交给智能体去做,付出的精力和情绪可能比自己去做还要多,因为当前的智能体还不能算是个“好员工”。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)