万表级数据库如何喂给Agent?一项关于格式、架构与模型能力的系统实验
当agent需要操作包含上万张表的企业级数据库时,应该如何组织上下文信息?是把完整schema塞进提示词,还是让agent自己通过文件工具检索?用YAML、JSON还是Markdown格式?这些看似基础的问题,此前缺乏系统性的实证研究。
论文通过9,649次实验,横跨11个模型、4种格式、从10到10,000张表的不同规模,给出了一个出人意料的答案:架构选择的效果取决于模型能力,而非存在普适的最佳实践。
文件原生agent的兴起与核心问题
近年来,开发者为agent提供上下文的方式正在发生显著转变。越来越多的实践者采用"文件原生"(file-native)的语义层方案:让agent通过grep和read等原生文件操作来检索结构化文档,而非仅依赖RAG(Retrieval-Augmented Generation,检索增强生成)或直接在提示词中嵌入上下文。
这种模式已在行业中自然涌现:CLAUDE.md和AGENTS.md文件描述项目规范,llms.txt标准为LLM提供结构化网站描述,Cursor Rules为代码agent配置上下文,YAML/JSON/Markdown格式的schema文件描述数据库结构。
论文聚焦五个核心研究问题:(1)文件原生上下文工程是否比提示词工程更准确?(2)格式是否影响准确率?(3)模型层级如何影响效果?(4)schema规模如何影响文件原生agent?(5)格式是否影响效率?
实验设计:11个模型、4种格式、万表规模
论文以SQL生成作为程序化agent操作的代理任务,设计了系统性的对比实验。
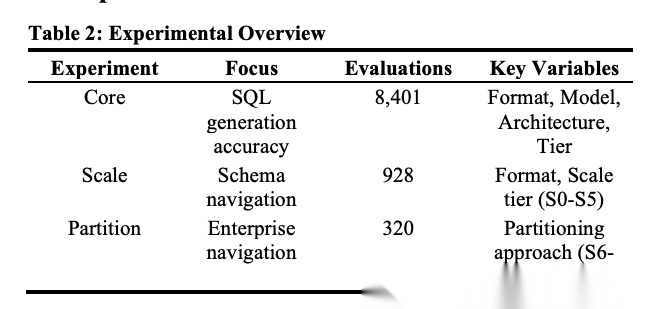
[Table 2: Experimental Overview 实验概览] 核心SQL生成实验8,401次,规模导航实验928次,分区导航实验320次,涵盖格式、模型、架构、层级等关键变量。
格式条件包括YAML(层级结构,grep友好)、Markdown(文档风格,自然语言)、JSON(机器可解析,冗长)和TOON(Token-Oriented Object Notation,面向Token的对象表示法,文件体积比YAML小约25%)。所有格式使用相同的系统提示词,不提供格式特定的搜索模式指导。
架构条件对比两种上下文交付方式:File Agent让agent使用grep和read工具按需检索schema信息;Prompt Baseline将完整schema(TPC-DS约6,000 token)直接嵌入系统提示词。
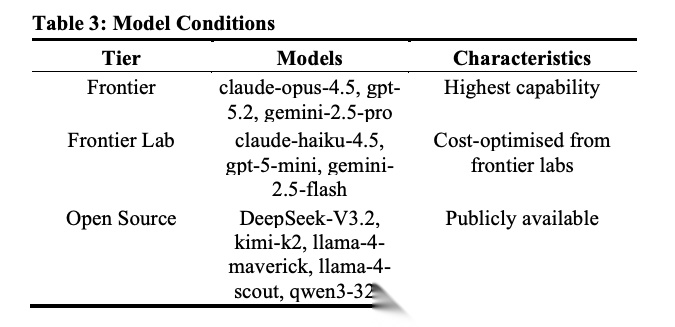
[Table 3: Model Conditions 模型条件] 11个模型分为三个层级:Frontier层(claude-opus-4.5、gpt-5.2、gemini-2.5-pro)、Frontier Lab层(claude-haiku-4.5、gpt-5-mini、gemini-2.5-flash)、Open Source层(DeepSeek-V3.2、kimi-k2、llama-4-maverick、llama-4-scout、qwen3-32b)。
复杂度分层从L1(单表直接查询)到L5(多步推理,5+表,子查询和嵌套逻辑)。规模分层从S0(10表)到S5(500表)为单文件schema,S6-S9通过领域分区扩展至10,000表。
发现一:架构效果取决于模型层级
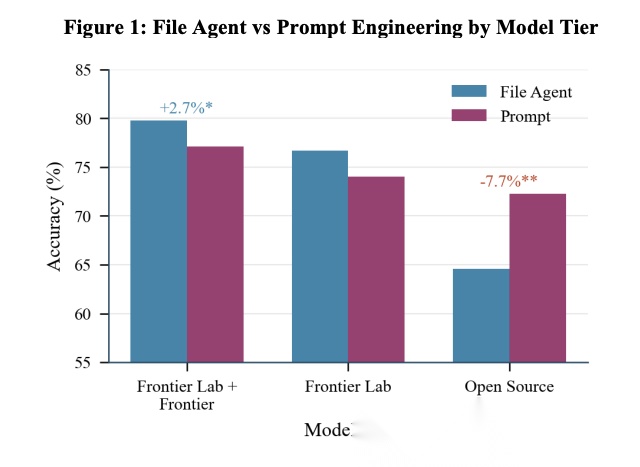
[Figure 1: File Agent vs Prompt Engineering by Model Tier 按模型层级对比文件Agent与提示词工程] 展示不同模型在两种架构下的准确率差异。
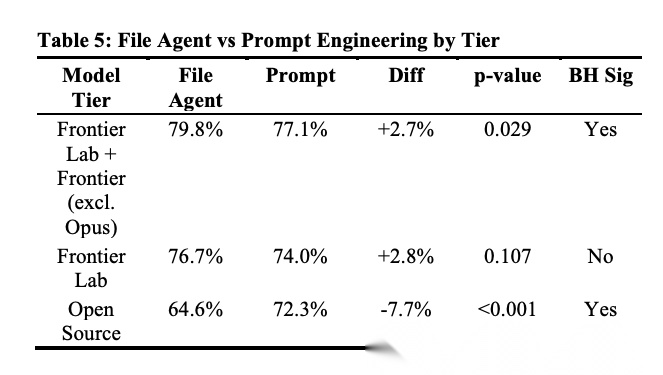
[Table 5: File Agent vs Prompt Engineering by Tier 按层级对比文件Agent与提示词工程] Frontier+Frontier Lab层使用文件agent准确率提升+2.7%(p=0.029),Open Source层则下降-7.7%(p<0.001)。
这是论文最重要的发现:文件原生检索并非普遍优于提示词工程。对于Frontier模型,文件原生检索带来可测量的收益;但对于开源模型,结果参差不齐。Qwen下降21.9%,Llama Maverick下降13.9%,而Kimi和Llama Scout几乎无差异。论文推测这反映了开源模型在工具使用训练上的差异。
发现二:格式对整体准确率无显著影响
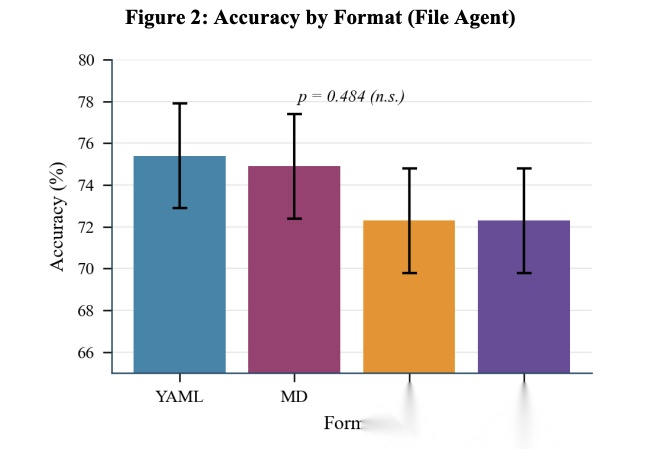
[Figure 2: Accuracy by Format (File Agent) 按格式划分的准确率] 卡方检验显示格式效果不显著(p=0.484)。YAML达75.4%,MD 74.9%,JSON 72.3%,TOON 72.3%。
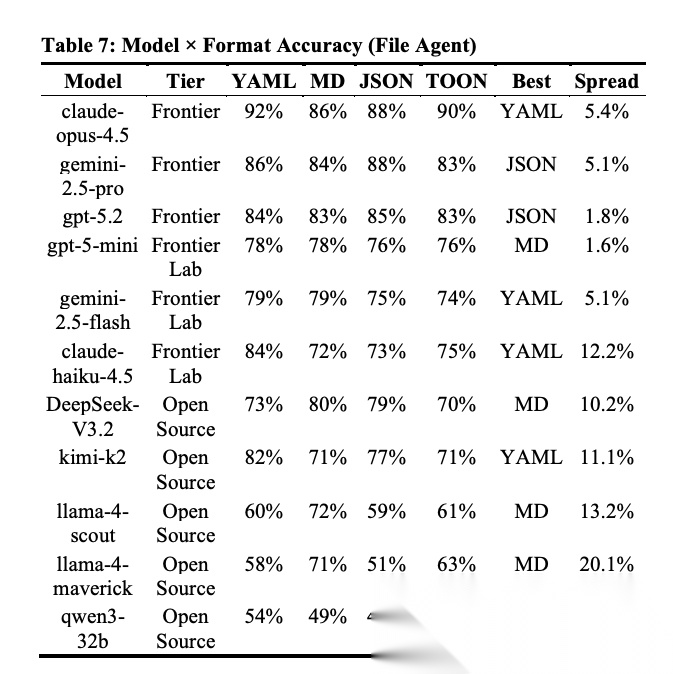
[Table 7: Model × Format Accuracy (File Agent) 模型与格式交叉准确率] 虽然整体无显著差异,但个别模型表现出格式敏感性。开源模型的格式敏感度(spread 9.8-20.1%)远高于Frontier模型(spread 1.6-5.4%)。
格式偏好总结:YAML对5个模型最优,MD对4个模型最优,JSON对2个模型最优,TOON对0个模型最优。
发现三:模型能力是主导因素
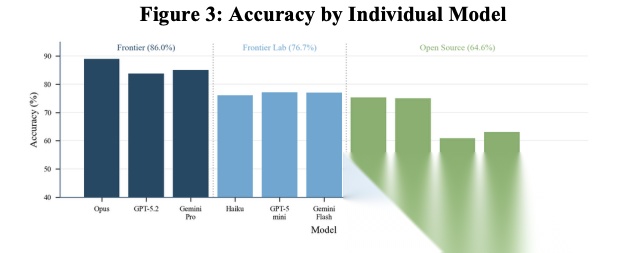
[Figure 3: Accuracy by Individual Model 各模型准确率] 单因素方差分析:F(10, 8390)=30.55,p<0.001。
Frontier层准确率86.0%,Frontier Lab层76.7%,Open Source层64.6%。层级间21个百分点的差距远超任何格式或架构效应。
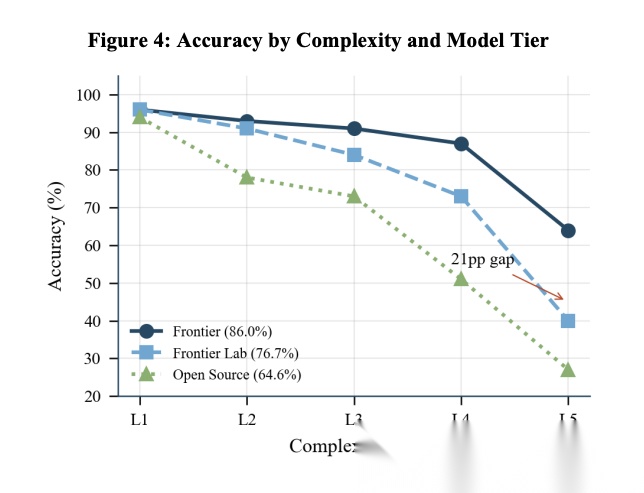
[Figure 4: Accuracy by Complexity and Model Tier 按复杂度和模型层级划分的准确率] 所有层级在L1达到相似准确率(94-96%),但在更高复杂度上急剧分化。Frontier模型在L5维持64%,而开源模型降至27%。
发现四:分区策略支撑万表规模
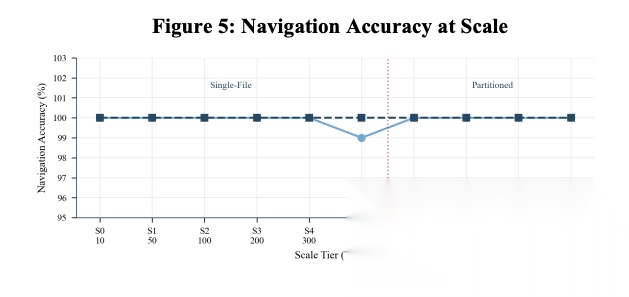
[Figure 5: Navigation Accuracy at Scale 规模化导航准确率] 单文件schema在500表以内保持近乎完美的准确率。领域分区使10,000表时仍保持高导航准确率。
分区架构使每次查询的上下文保持有界,不受总schema规模影响。
发现五:"Grep税"现象——紧凑格式未必高效
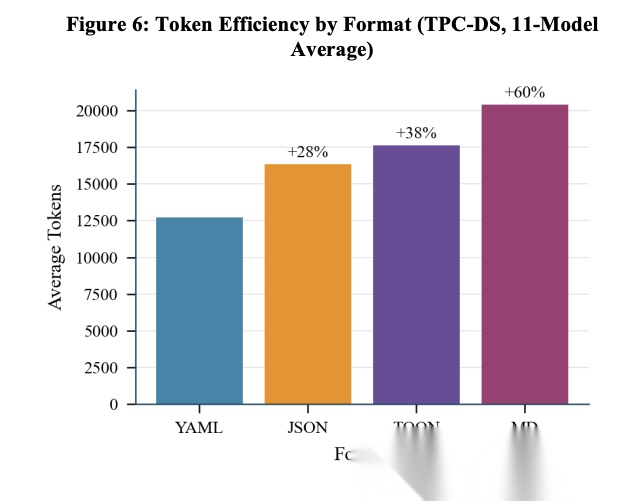
[Figure 6: Token Efficiency by Format Token效率按格式划分] 在TPC-DS schema(24表)上,YAML最省token(12,729),其次是JSON(16,320,+28%)、TOON(17,625,+38%)、MD(20,382,+60%)。
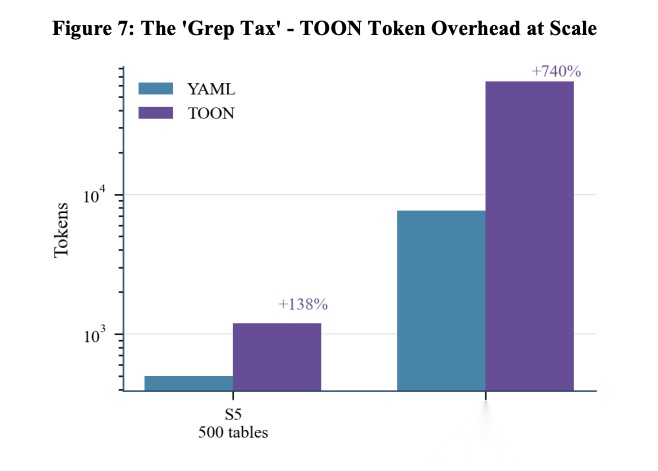
[Figure 7: The ‘Grep Tax’ - TOON Token Overhead at Scale “Grep税”——TOON在规模化时的Token开销] 在S5(500表)时,TOON比YAML多消耗138%的token;在S9(10,000表)时,这一差距扩大到740%。
根本原因:模型对TOON语法不熟悉,无法构建有效的细化搜索模式。当初始搜索返回过多匹配时,agent会循环尝试已知格式(DDL、JSON、YAML)的模式,每次失败尝试都增加对话上下文。
实践建议与局限

[Table 9: Architecture Selection Guide 架构选择指南] Frontier模型推荐File Agent,Frontier Lab模型推荐File Agent(需先验证),Open Source模型推荐Prompt Engineering。

[Table 10: Format Selection Guide 格式选择指南] 追求token效率选YAML,追求可读性选Markdown,程序化生成选YAML或JSON,自定义格式需确保grep友好的模式。
论文指出若干局限:核心实验使用100条查询(每层级20条);规模实验仅使用Claude模型且测试的是schema导航而非SQL推理;所有实验基于TPC-DS零售数据仓库基准;TOON作为新格式在LLM训练数据中几乎不存在,观察到的grep税可能部分反映格式陌生度。
核心启示
针对模型能力匹配架构,而非假设存在普适最佳实践。在优化格式之前,先投资于模型能力。使用YAML获得token效率和grep友好模式。对企业级规模采用领域分区。随着LLM agent日益操作关键业务系统,基于证据的上下文工程指导变得至关重要。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献204条内容
已为社区贡献204条内容

所有评论(0)