start-MLLM TASK01
https://github.com/datawhalechina/start-mllm/blob/main/docs/%E5%89%8D%E8%A8%80.md
一、为什么要系统学习多模态大模型
多态大模型(MLLM,Multimodal Large Language Model)尝试进一步处理图片、文档、截图、表格、视频帧、语音等多种输入形式。它的真正价值,不是“接了一个图片入口”,而是让模型逐步具备接近真实世界任务的感知能力。
在现实应用中,用户很少只提供纯文本。更常见的输入是:
- 一张报错截图,外加一句“这是什么意思”
- 一份发票或合同,外加一句“帮助我提取关键信息”
- 一张商品图,外加一句“帮我写标题和卖点”
- 一段视频封面、多张图片、语音说明、构成表格的组合输入
- 如果你限制文本模型,你只能做的事情会被输入形式;如果你理解了多模态模型,你就可以开始做真正贴近业务的AI系统。
如果你刚开始学多模态,先把这条路线记在脑子里:概念地图 → 架构原理 → 数据与训练 → 评测与部署 → 推理实操 → Demo → Agent
后面遇到新术语时,你能立刻知道它属于哪一段,很容易越读越乱。
建立认识与训练侧概念:任务版图、视觉令牌与瞄准、生成式架构(Connector + LLM)、数据配方与敏感性策略。第4章的JSONL与加密脚本重在「格式与质量意识」,不等于必须立即训练大模型。
建立了验收与落地能力:场景剧情、配置与部署、推理脚本与Gradio Demo、多模态代理、以及将全书收成的重建路线。
命令行与环境变量
- 实战篇里部分示例在Windows(cmd / PowerShell)下使用set VAR=value;在Linux / macOS(Bash / Zsh)下请改为export VAR=value。相同指标名与取值不变,仅语法不同。
- 文档中的相对路径默认以仓库根目录(start-mllm/)为当前工作目录,除非你看到明确写到cd了子目录。
- 第八章等处的.env文件为KEY=value行格式,各系统写法一致;与「在 shell 里临时导出」不是同一个入口,别混用语法即可。
首读术语速查
- MLLM / VLM:能够同时处理与语言输入的模型(VLM通常特指图文方向)。
- 视觉编码器:把像素变成支持特征的模块,相当于“眼睛”。
- Patch Token:图像切块后形成的视觉令牌,粒度影响细节保留能力。
- Connector / Projector:把视觉特征映射到LLM可消费表示的桥接层。
- SFT:指令指令,让模型提供“会执行任务的助手”,而不仅仅是会理解图文关系。
- Grounding:让模型的文字描述能够定位到图像中的具体区域(如坐标框、边界框),而不仅仅是笼统地描述整张图。
第一遍看时先记“这个词是Q的”就够了,细节可以边做边补。
如何使用这份教程
如果你对Transformer、Embedding、自回归生成等还不太熟悉,先花30分钟读完LLM基础速通,再进入正文。已有LLM基础的读者可跳过。
误区 1:把“能收图片”当成“理解图像”
很多多模态模型的能力边界并不来自“有没有图片输入”,而来自:
- 视觉编码器是否足够强
- 对齐是否足够好
- 数据分布里是否包含你关心的任务
- 推理链路里是否保留了必要的细粒度信息
不追求一次全做满,但这是本书默认的「能力终点」画像:
能用自己的话讲清 视觉编码 → 对齐 → LLM 在系统里各干什么(第 1~3 章)。
能写一小份 多模态 SFT 风格 JSONL 并做基础校验(第 4 章 + docs/chapter4/code)。
能搭 几十条量级 的场景评测集,并跑通 eval_vlm_dataset.py(第 5 章)。
能说清 推理链路 上哪里会丢图、哪里会慢,以及该记哪些日志(第 6 章)。
能 本地或 API 跑通图文对话,并做一个 Gradio 级 Demo(第 7~8 章)。
能画出 感知 → 规划 → 工具 → 记忆 的多模态 Agent 草图,并整理出一份自己的实践优先级清单(第 9~10 章)。
更偏场景的排版、多图、长图,可穿插 扩展阅读 与 Extra-Chapter。
LLM基础速通
如果你只有 Python 基础,对 Transformer、Embedding、自回归生成这些概念还不熟悉,花 30 分钟读完本章就够了。我们只讲后续章节会直接用到的概念,不展开数学推导。
训练过程的基本单位:
总训练数据(10000 条)
└── 拆成多个 Batch(每批 32 条)
└── 每个 Batch 跑一次前向 + 反向传播 → 更新一次参数(1 Step)
└── 所有数据跑完一遍 = 1 Epoch
└── 通常训练 1~5 个 Epoch
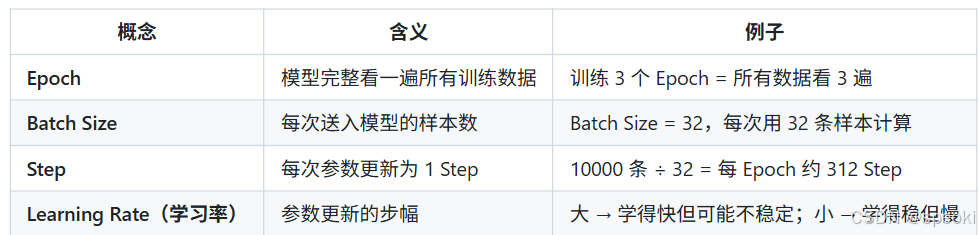
训练日志里的 lr 1e-4 就是当前的学习率。常见策略是预训练阶段用较大 lr(如 1e-4),微调阶段用较小 lr(如 2e-5)。
预训练与微调
大模型的训练通常分两大阶段:
预训练(Pre-training):从零开始,在海量文本上学习语言能力
训练数据: 互联网文本、书籍、代码...(TB 级)
训练目标: 预测下一个 token
训练成本: 需要大量 GPU 和时间(通常数周到数月)
产出: 基座模型(Base Model)
指令微调(SFT, Supervised Fine-Tuning):在基座模型上,用任务数据进一步训练
训练数据: "指令-回答"格式的标注数据(千~万条)
训练目标: 让模型学会执行具体任务
训练成本: 远低于预训练(单卡几小时到几天)
产出: 指令模型(Chat Model / Instruct Model)
这个范式叫 “预训练 → 微调”,是当前 LLM 和 MLLM 的标准流程:
预训练 → 基座模型(会续写文本,但不会听指令)
↓ 指令微调
指令模型(会听指令、会对话、会完成任务)
基座模型
基座模型(Base Model) 就是只经过预训练、还没经过指令微调的模型。
- 它会续写文本,但不会"回答问题"
- 你给它"法国的首都是",它会续写"法国的首都是巴黎,巴黎是…“,而不是干净地回答"巴黎”
- 常见基座模型:Qwen2.5-7B、Llama3-8B、DeepSeek-V2-Lite
后续章节里提到"冻结基座模型",就是指保持预训练参数不变,只训练新加的模块(如 Connector、LoRA 适配器)。
五、PyTorch 五分钟速查
如果你走 API 路线(第七章 OpenAI 兼容接口、第八章 Gradio Demo、第九章 Agent),完全不需要 PyTorch,可以跳过本节。
如果你想走 本地推理路线(第七章 Transformers 方式)或动手做 LoRA 微调(第四章),下面 5 个模式够你用了:
检查 GPU 是否可用
import torch
print(torch.cuda.is_available()) # True = 有可用 GPU
print(torch.cuda.get_device_name(0)) # 显卡型号
加载预训练模型
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2.5-7B-Instruct")
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-7B-Instruct")
from_pretrained 是你最常用的方法——给一个模型名或本地路径,它自动下载/加载模型权重。
把模型放到 GPU 上
model = model.to("cuda") # 整个模型搬到 GPU
# 或者加载时直接指定:
# model = AutoModelForCausalLM.from_pretrained("...", device_map="auto")
device_map=“auto” 会自动把模型分配到可用的 GPU 上,大模型推荐用这种方式。
推理模式
with torch.no_grad(): # 推理时关闭梯度计算,省显存
outputs = model.generate(**inputs, max_new_tokens=512)
torch.no_grad() 告诉 PyTorch 不需要记录计算图(那是训练用的),推理时务必加上。
Tensor 基础
import torch
x = torch.tensor([1.0, 2.0, 3.0]) # 创建张量(类似 numpy array)
print(x.shape) # torch.Size([3])
print(x.device) # cpu 或 cuda:0
x = x.to("cuda") # 搬到 GPU
Tensor 就是 PyTorch 版的多维数组。你在后续章节里看到的 input_ids、pixel_values、attention_mask 都是 tensor。
一句话总结:PyTorch 在本教程里主要就做两件事——加载模型(
from_pretrained)和生成输出(model.generate)。更深入的训练用法(Dataset、DataLoader、Trainer)在第四章 LoRA 微调时会结合具体代码讲解。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)