推理引擎系列(六)《vLLM-Ascend 大模型推理》
目录
本文主要讲解 vLLM-ascend 整体规划和架构以及核心技术内容。
vLLM+vLLM-ascend 整体规划和架构
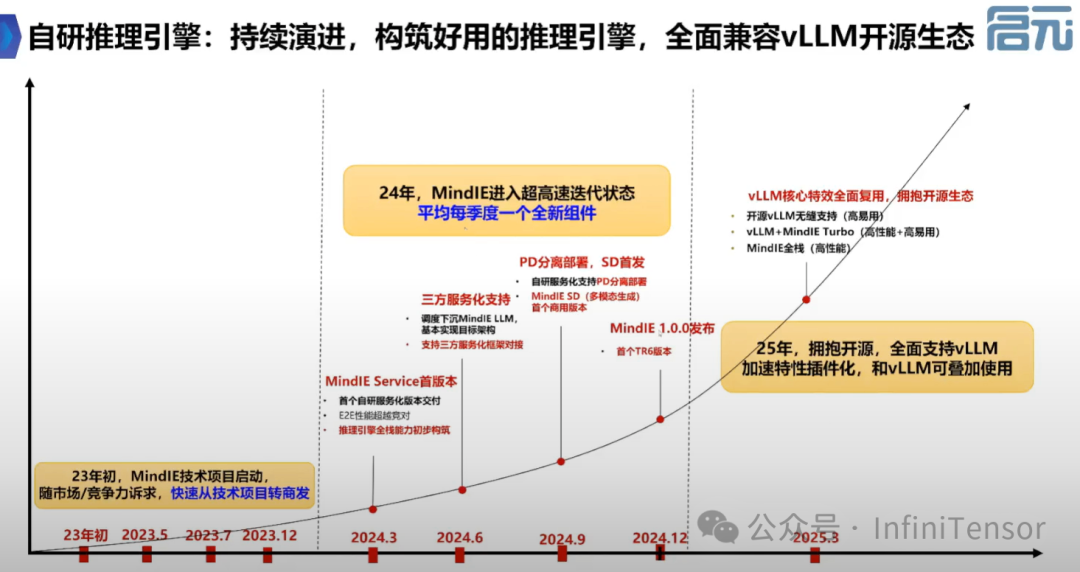
社区演进概述
-
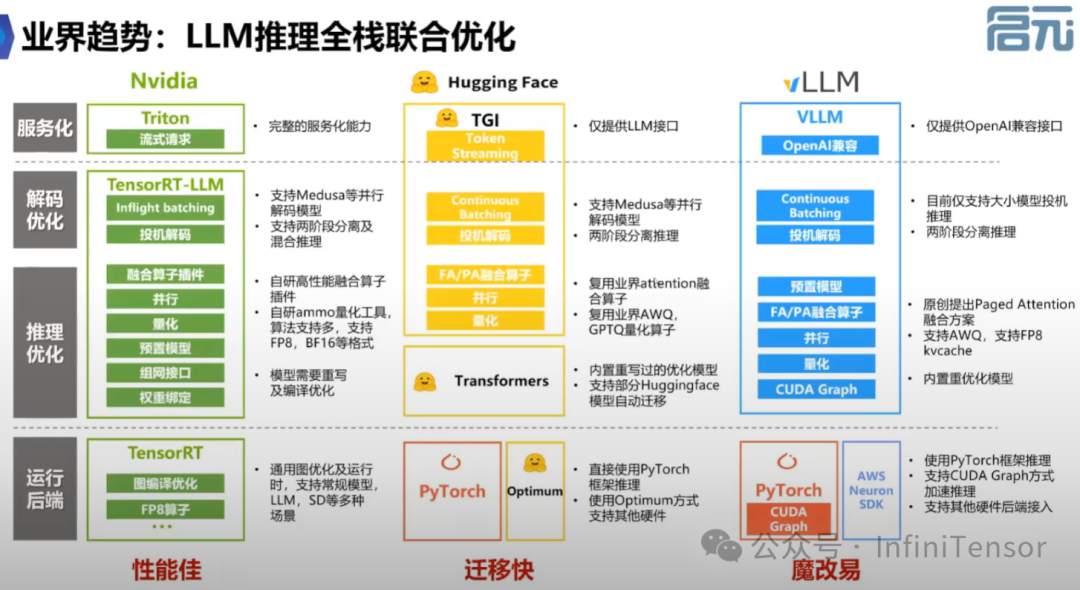
• 回顾社区在推理引擎领域的发展历程。
- • 强调开源与性能并重的重要性。
华为昇腾技术路线
-
• 以开源为基础,与社区紧密配合,回馈社区。
昇腾推理架构解析
架构概览
-
• 华为MindIE推理引擎与业界开源生态引擎(如LLM、TensorFlow TGI、Triton)的对比。
计算架构层
-
• 对标 CUDA 的计算架构设计。
框架 Plugin 层
-
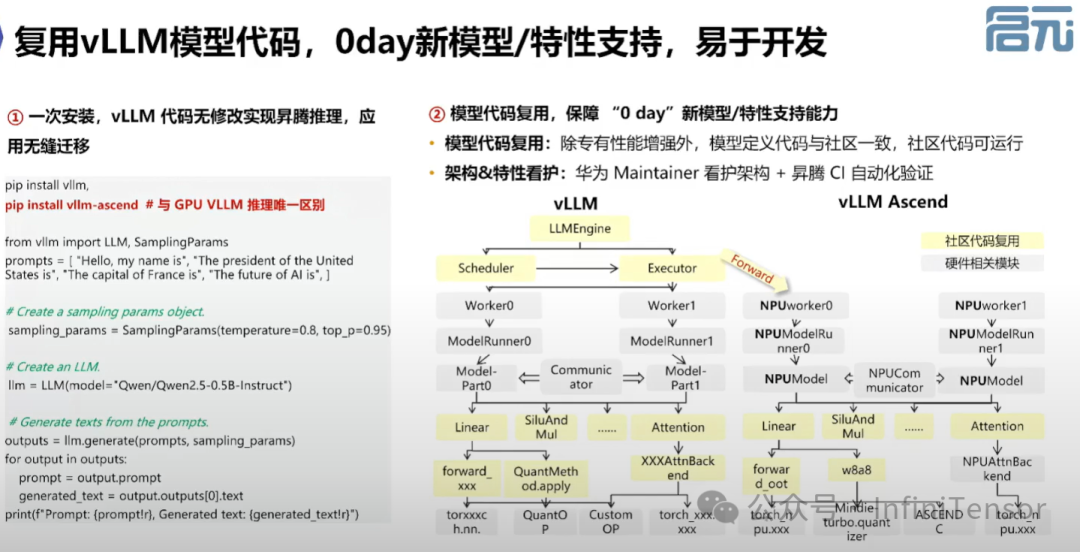
• 介绍 vLLM-Ascend 作为 vLLM 框架的 Plugin,实现硬件层适配。
vLLM 核心技术
1. Paged Attention
-
• 解决内存碎片与显存浪费问题,通过分页内存分配提高资源利用率。

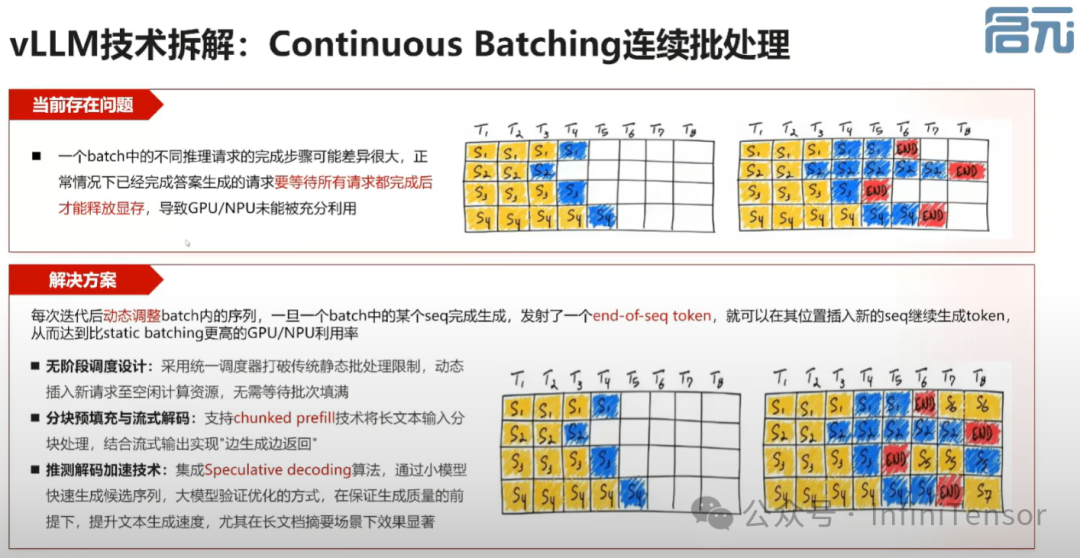
2. Continuous Batching
-
• 与 Paged Attention 配套使用,提高 GPU/NPU 算力和显存利用率。
3. vLLM-Ascend 插件
-
• 硬件层适配,屏蔽 GPU 与 NPU 差异,支持无缝迁移。
-
• 降低二次开发门槛,支持模型零拷贝。

4. 安装与调用流程
5. ACL Graph与性能优化
(1)ACL Graph 概念
-
• 对标CUDA graph,实现一次捕获、多次重放,减少空泡。

(2)性能优化策略
-
• 提高系统并行度,减少无法并行部分。
-
• 介绍 vLLM 如何通过提高应用层系统并行度实现性能提升。
推理精度分析方法
精度分析工具
-
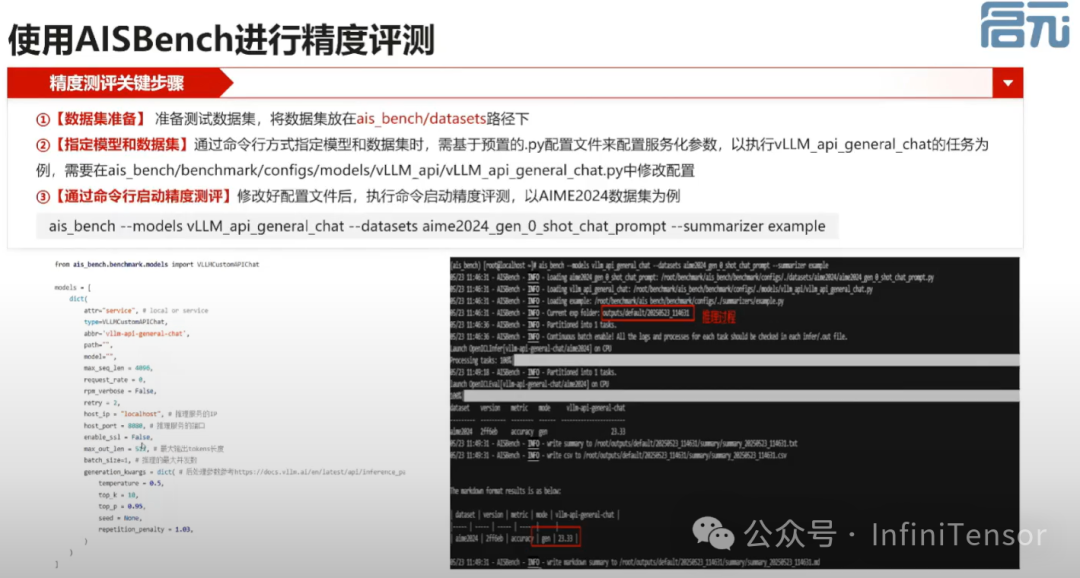
1. 介绍 OpenCampass、EvalScope、AISBench 等工具。

-
2. 强调通过跑数据集获取精度指标的方法。
常见问题与解决方案
-
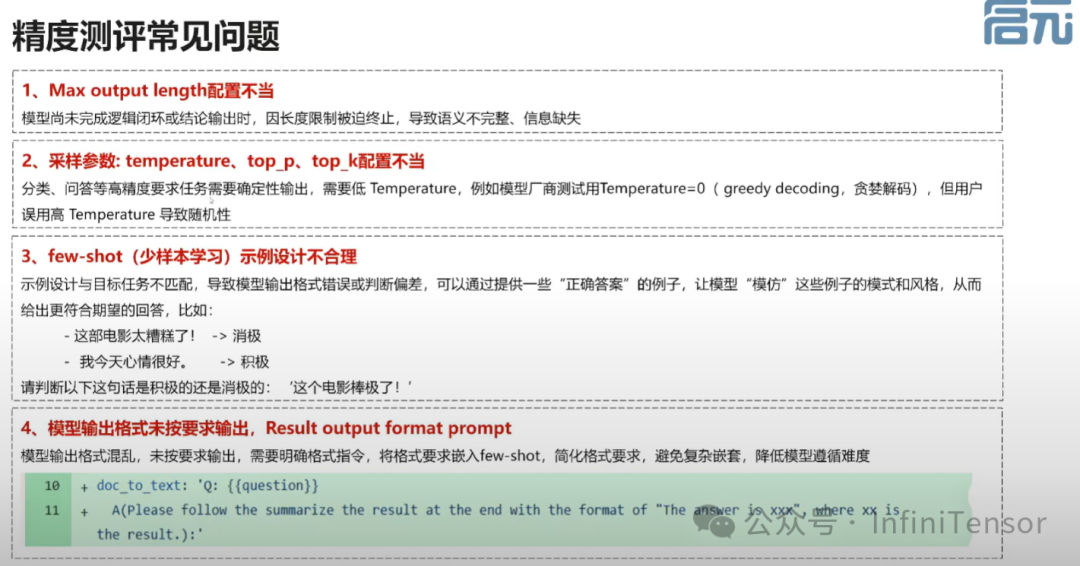
• 介绍如何通过调整参数和模型设计提高精度。
Badcase 分析
-
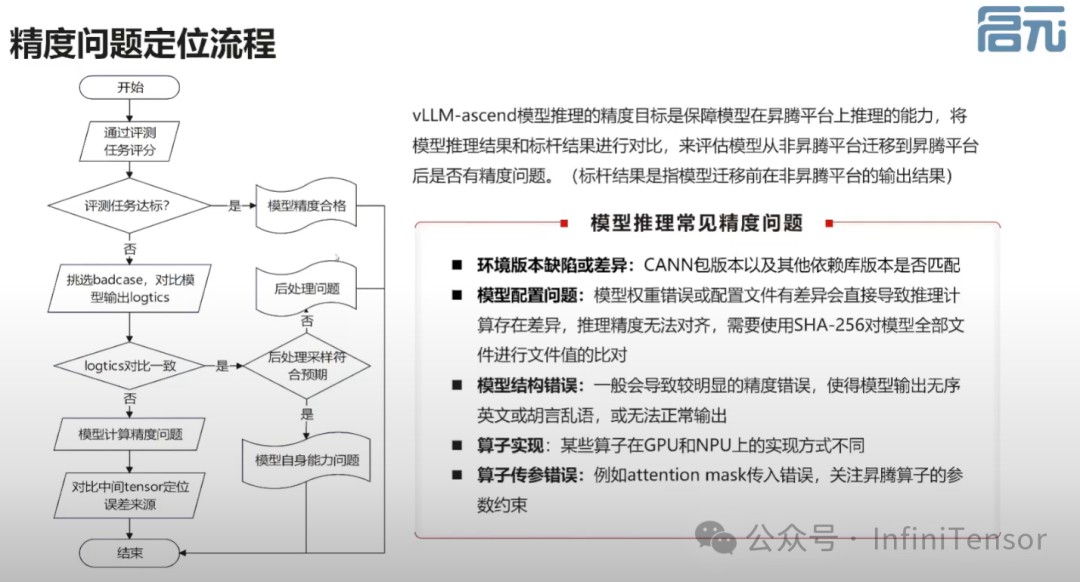
1. 如何定位和分析 Badcase,找出精度不达标的原因。
-
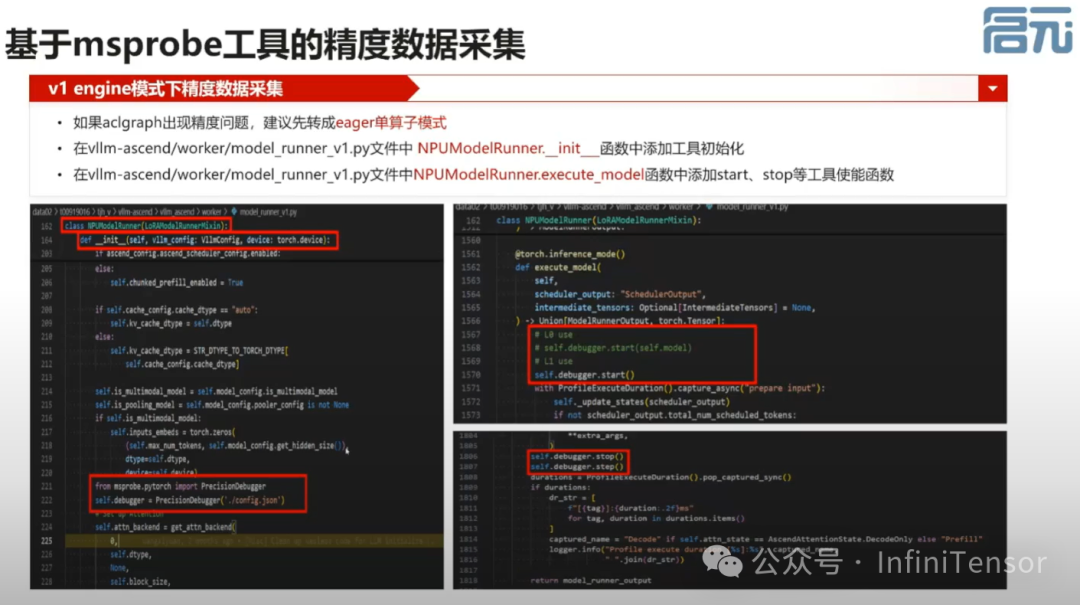
2. 基于MSProbe工具的精度数据采集
推理性能分析方法
性能分析工具
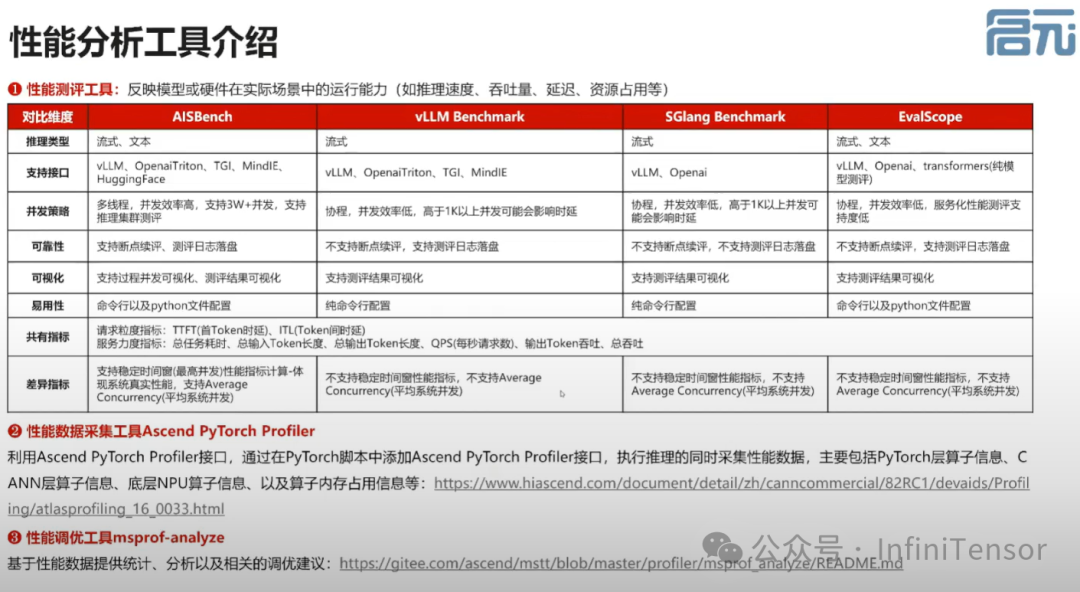
使用 AISBench 进行性能测评:
-
• 配置随机数据集
-
• 指定模型和数据集
-
• 通过命令行启动性能测评
性能问题定位

性能数据分析
-
•
op_statistic.csv -
•
trac_view.json
PD 分离场景调优
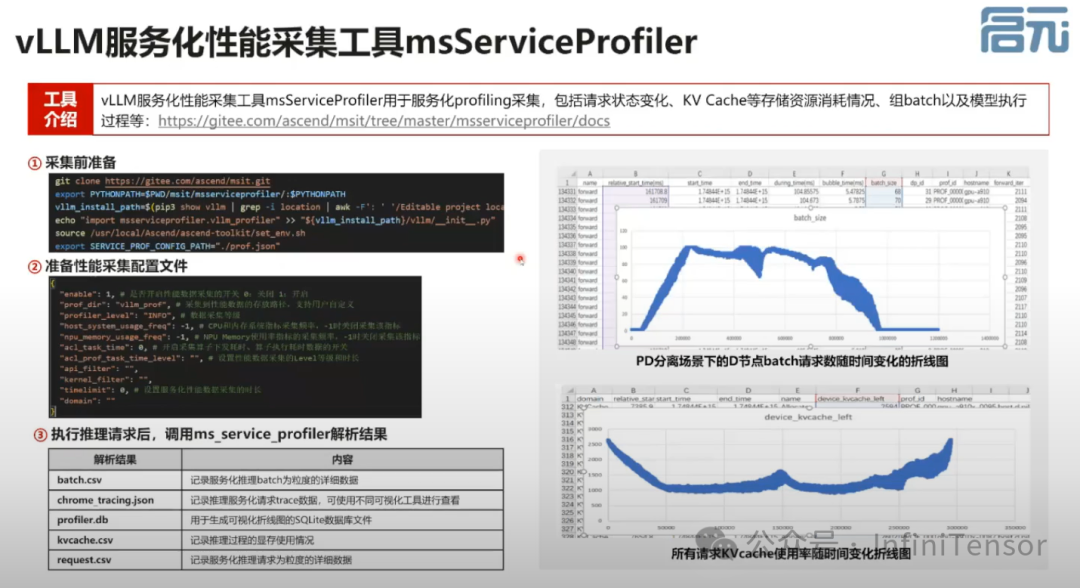
-
• PD 分离场景调优:通过解耦预填充(Prefill)与生成(Decode)阶段,突破 KV Cache 导致的吞吐瓶颈。
-
• 介绍如何通过调整 PD 配比和预期 TPS 来优化系统性能。
vLLM-ascend 推理部署流程

环境准备
-
• 使用
npu-smi info检查 NPU 驱动固件安装情况。 -
• 推荐使用 Docker 进行部署。
模型下载与安装
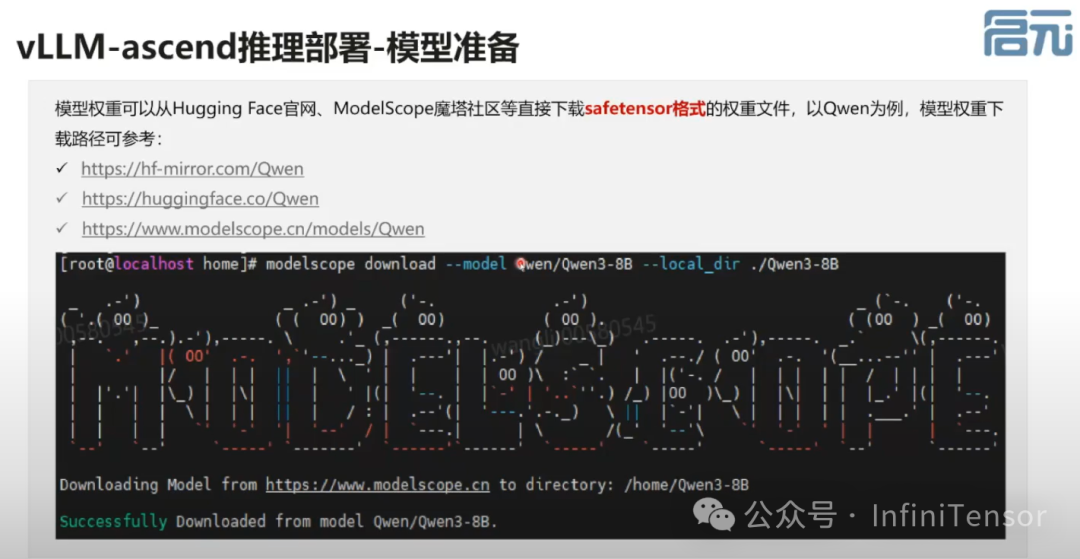
-
• 介绍如何通过 ModelScope 下载模型。
强调安装 vLLM 与 vLLM-Ascend 的步骤。
离线与在线推理
-
• 介绍离线与在线推理的使用方式与区别。
-
• 强调 vLLM-Ascend 与 vLLM 使用方式的一致性。
常用特性与入参介绍
-
• 环境变量
-
• 推理参数

注意事项

总结
本文系统介绍了vLLM-ascend推理引擎的整体架构与技术实现。重点包括:1)基于开源生态的昇腾推理架构,通过vLLM插件实现GPU/NPU硬件适配;2)核心技术创新如PagedAttention内存管理和ContinuousBatching批处理优化;3)性能优化策略包括ACLGraph应用和PD阶段解耦;4)完整的精度分析与性能评估方法体系;5)从环境准备到模型部署的全流程实践指南。该方案通过技术创新和工具链整合,显著提升了AI推理的效率和易用性,为昇腾生态提供了高性能的推理解决方案。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)