IGWO-SVM:基于Logistic、Tent混沌映射与DIH策略的灰狼优化算法改进支持向量机
IGWO-SVM:改良的灰狼优化算法改进支持向量机。 采用三种改进思路:两种Logistic和Tent混沌映射和采用DIH策略。 采用基于DIH维度学习的狩猎搜索策略为每只狼构建邻域,增强局部和全局搜索能力,收敛速度比GWO更快,适用于paper。
一、整体概述
本套代码基于改良的灰狼优化算法(DIH-GWO)对支持向量机(SVM)的关键参数(惩罚参数c和核函数参数g)进行优化,旨在提升SVM在分类任务中的性能。代码整体采用MATLAB开发,包含13个核心文件,涵盖数据预处理、种群初始化优化、算法迭代寻优、SVM模型训练与预测等完整流程,适用于葡萄酒数据集等分类场景,可通过调整参数适配其他类似结构化数据的分类任务。
二、核心模块与功能解析
(一)数据处理模块
该模块负责数据的加载、划分与预处理,为后续模型训练与优化提供高质量数据输入,核心逻辑集中在DIHGWOSVM.m文件中。
- 数据加载:加载葡萄酒(wine)数据集,该数据集包含178个样本,每个样本有13个特征,对应3个类别,同时加载样本标签(wine_labels)。
- 训练集与测试集划分:按照固定规则划分数据,将第一类样本的1-30号、第二类的60-95号、第三类的131-153号划分为训练集;第一类的31-59号、第二类的96-130号、第三类的154-178号划分为测试集,确保训练集与测试集样本分布合理,避免类别失衡。
- 数据归一化:使用
mapminmax函数将训练集与测试集数据统一归一化到[0,1]区间。归一化处理可消除不同特征量纲差异对SVM模型的影响,例如避免因某一特征数值范围过大而主导模型学习过程,提升模型收敛速度与分类精度。
(二)种群初始化优化模块
传统灰狼优化算法(GWO)种群初始化易出现分布不均匀问题,本代码提供两种混沌映射初始化方案,通过增强种群多样性提升算法寻优能力,相关实现位于DIHGWOSVM.m与initialization.m文件。
- Tent混沌映射初始化:通过Tent映射公式生成混沌序列,初始值随机设定,后续每个值根据前一个值与固定阈值(0.6)的大小关系计算。当数值小于0.6时,采用线性放大公式;大于等于0.6时,采用反向线性计算方式。生成的混沌序列结合参数上下界(ub/lb)转换为初始种群位置,该方式可使种群在解空间分布更均匀,覆盖更多潜在最优解区域。
- Logistic混沌映射初始化:基于Logistic映射公式(X(i+1,j)=4X(i,j)(1-X(i,j)))生成混沌序列,同样结合参数上下界得到初始种群。Logistic映射在特定参数下具有复杂的混沌特性,能有效避免初始种群陷入局部最优区域,与Tent映射形成互补,用户可根据实际场景选择其中一种初始化方式。
- 传统随机初始化:
initialization.m文件提供传统随机初始化方法,根据参数上下界随机生成种群位置,适用于对比实验,以验证混沌映射初始化对算法性能的提升效果。
(三)改良灰狼优化(DIH-GWO)算法模块
该模块是代码核心,通过引入DIH(Directional Learning and Heterogeneity)策略改进传统GWO,实现对SVM参数的高效寻优,核心逻辑分布在DIHGWOSVM.m与IGWO.m文件。
- 狼群层级划分与更新:算法将狼群分为Alpha(最优)、Beta(次优)、Delta(第三优)和Omega(普通)四级。每次迭代中,根据每个狼的适应度值(由SVM分类误差计算)更新Alpha、Beta、Delta的位置与适应度,确保算法始终向最优解方向搜索。
- 传统GWO位置更新:基于Alpha、Beta、Delta的位置,通过随机系数(A1、A2、A3与C1、C2、C3)计算每个Omega狼的候选位置(X_GWO)。其中系数A随迭代次数从2线性递减至0,实现算法从全局探索到局部开发的平滑过渡;系数C为[0,2]区间随机值,增强搜索随机性。
- DIH策略改进:
- 邻居半径计算:通过欧氏距离计算每个狼与传统GWO生成候选位置的距离(radius),作为邻居判断依据。
- 邻居选择:筛选出与当前狼距离小于等于radius的邻居个体,形成邻居集合,确保学习对象的相关性。
- 定向学习位置生成:基于邻居集合与随机选择的其他个体,通过定向学习公式生成新的候选位置(X_DLH),该位置融合了邻居的优质信息与种群多样性,有效提升算法跳出局部最优的能力。 - 选择与更新机制:对比XGWO与XDLH对应的适应度值,选择更优的候选位置与适应度;再与个体历史最优(pBest)比较,更新个体最优位置与适应度,最终实现种群整体进化,逐步逼近SVM最优参数组合。
(四)适应度函数与约束处理模块
该模块确保算法寻优方向与SVM性能目标一致,并保证参数在合理范围内,相关文件包括objfun.m、fobj.m与boundConstraint.m。
- 适应度函数(objfun.m):以SVM分类错误率作为适应度值,输入待优化参数(c、g),通过
svmtrain函数训练SVM模型,再用svmpredict函数计算测试集分类准确率,适应度值为“1 - 准确率/100”。适应度值越小,代表SVM分类性能越好,算法通过最小化适应度值实现参数优化。 - 辅助适应度计算(fobj.m):提供另一种适应度计算方式,以SVM预测的平均均方误差(MSE)作为优化目标,适用于回归任务或需关注预测误差的场景,增强代码通用性。
- 边界约束处理(boundConstraint.m):在种群位置更新过程中,若新位置超出参数上下界(ub/lb),采用“当前位置与边界值平均”的方式调整,避免参数取值不合理导致SVM模型失效(如惩罚参数c过小导致模型欠拟合,过大导致过拟合)。
(五)SVM模型训练与预测模块
该模块基于优化后的参数构建SVM模型,完成分类任务并输出结果,主要实现于DIHGWOSVM.m文件。
- 最优参数获取:DIH-GWO算法迭代结束后,选取适应度值最小的个体对应的参数作为SVM最优参数(bestc、bestg)。
- SVM模型训练:使用
svmtrain函数,传入训练集数据、标签与最优参数(通过命令行参数cmd指定),构建SVM分类模型。其中核函数默认采用RBF(径向基函数),适用于非线性分类场景,可通过调整命令行参数切换核函数类型。 - 分类预测与结果输出:调用
svmpredict函数,用训练好的SVM模型对测试集进行分类预测,输出预测标签、分类准确率、决策值等信息。同时计算测试集总样本数、正确分类样本数,以“准确率=正确数/总数”的格式打印结果,直观展示模型性能。
(六)结果可视化与分析模块
该模块通过图表展示算法寻优过程与SVM分类效果,帮助用户直观评估系统性能,位于DIHGWOSVM.m与func_plot.m文件。
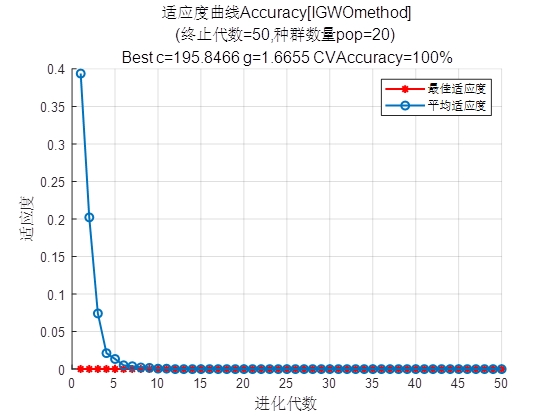
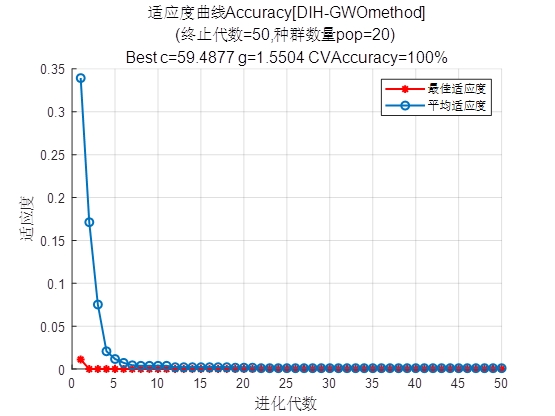
- 适应度曲线绘制:在
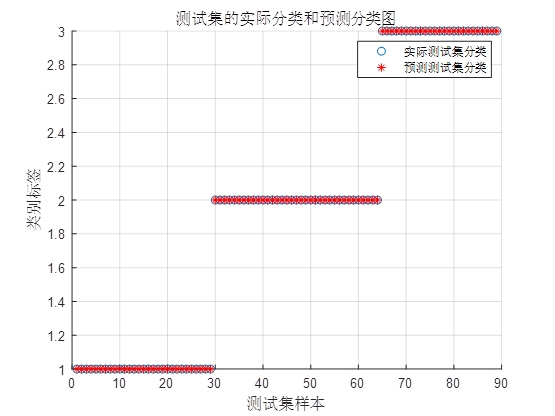
DIHGWOSVM.m中,绘制迭代过程中“最佳适应度”与“平均适应度”曲线,横轴为进化代数,纵轴为适应度值。曲线趋势可反映算法收敛速度(如快速下降代表收敛快)与稳定性(如后期波动小代表稳定),标题中包含终止代数、种群数量、最优参数与交叉验证准确率等关键信息。 - 分类结果对比图:绘制测试集“实际类别标签”与“预测类别标签”的对比图,横轴为测试集样本序号,纵轴为类别标签。通过两种标签的重合程度,可直观判断SVM模型对不同样本的分类准确性,便于定位分类错误的样本。
- 基准函数可视化(func_plot.m):提供23种基准函数(如F1为Sphere函数、F9为Rastrigin函数)的三维可视化功能,可用于测试DIH-GWO算法在不同复杂函数上的寻优能力,辅助算法改进与性能验证。
(七)辅助计算模块
该模块提供常用统计指标计算函数,用于评估模型预测精度,包含mymae.m、mymape.m与mymse.m文件。
- 平均绝对误差(MAE)计算(mymae.m):通过“实际值与预测值绝对差的平均值”计算MAE,反映预测值与真实值的平均偏差程度,值越小精度越高。
- 平均绝对百分比误差(MAPE)计算(mymape.m):以“实际值与预测值绝对差占实际值的百分比的平均值”计算MAPE,适用于需要关注相对误差的场景,避免因数据量级差异导致误差评估不准确。
- 均方误差(MSE)计算(mymse.m):通过“实际值与预测值差值的平方的平均值”计算MSE,对较大误差惩罚更严厉,可突出异常值对预测精度的影响,与适应度函数中的MSE计算形成呼应。
三、关键参数配置与调优建议
(一)核心参数说明
| 参数名称 | 含义 | 默认值 | 影响 |
|---|---|---|---|
| N | 狼群规模 | 20 | 规模过小时种群多样性不足,易陷入局部最优;过大则增加计算量,降低迭代速度 |
| Max_iter | 最大迭代次数 | 50 | 次数过少可能导致算法未收敛,无法找到最优参数;过多则增加冗余计算 |
| ub | 参数上界([c的上界, g的上界]) | [500, 100] | 上界过高可能导致参数搜索范围过大,增加寻优难度;过低可能错过最优解 |
| lb | 参数下界([c的下界, g的下界]) | [0.001, 0.001] | 下界过低可能导致参数过小,SVM模型性能下降;过高则限制搜索范围 |
| dim | 待优化参数个数 | 2 | 固定为2(对应c和g),无需修改 |
(二)调优建议
- 狼群规模(N):对于简单数据集(如样本数少、特征维度低),可将N设为15-25;复杂数据集(如高维、多类别)建议设为25-40,平衡多样性与计算效率。
- 最大迭代次数(Max_iter):若适应度曲线在50次迭代后仍未收敛(如后期持续下降),可增加至80-100次;若50次内已收敛,可减少至30-40次以节省时间。
- 参数上下界(ub/lb):惩罚参数c的上界可根据数据复杂度调整,简单数据设为300-500,复杂数据设为500-1000;核函数参数g的上界一般设为50-100,下界保持0.001即可,避免g过小导致核函数过于平滑,模型欠拟合。
四、代码运行流程与结果解读
(一)运行流程
- 启动MATLAB,将所有代码文件放入同一目录,并将该目录设为当前工作目录。
- 打开
DIHGWOSVM.m文件,根据需求选择种群初始化方式(注释或取消注释Tent/Logistic混沌映射相关代码)。 - 点击“运行”按钮,代码自动执行数据预处理、DIH-GWO算法寻优、SVM模型训练与预测、结果可视化等步骤。
- 运行结束后,MATLAB命令行窗口输出最优参数(bestc、bestg)与测试集分类准确率;同时弹出两个图表:适应度曲线图与分类结果对比图。
(二)结果解读
- 命令行输出:例如“Best c = 120.5,Best g = 8.2”“Accuracy = 96.7% (58/60)”,表示最优参数为c=120.5、g=8.2,测试集60个样本中58个分类正确,准确率96.7%。
- 适应度曲线图:若“最佳适应度”曲线快速下降并在后期趋于平稳,说明算法收敛良好;若曲线波动较大或后期仍下降,可能需调整种群规模或迭代次数。
- 分类结果对比图:若“实际标签”与“预测标签”曲线基本重合,仅少数样本存在差异,代表SVM模型分类效果优秀;若差异较多,需检查数据预处理步骤或调整算法参数。
五、适用场景与扩展方向
(一)适用场景
- 结构化数据分类:如葡萄酒数据集、鸢尾花数据集、手写数字识别数据集等,特征为数值型且样本量适中(100-1000个)的场景。
- SVM参数优化:适用于需提升SVM分类精度的任务,尤其当手动调参(如网格搜索)效率低、效果差时,可通过本算法实现自动化最优参数搜索。
- 算法对比实验:可与传统GWO-SVM、粒子群优化(PSO)-SVM等算法对比,验证DIH-GWO算法在寻优精度、收敛速度上的优势。
(二)扩展方向
- 数据集扩展:修改
DIHGWOSVM.m中的数据加载与划分代码,适配其他数据集(如CSV格式数据),只需将数据读取为矩阵形式,并对应调整训练集与测试集的索引范围。 - 算法改进:可引入其他混沌映射(如Chebyshev映射)或混合优化策略(如结合遗传算法的交叉变异操作),进一步提升算法寻优能力。
- 任务扩展:将适应度函数改为回归任务的误差指标(如MSE),并调整SVM模型类型(将分类SVM改为回归SVM),可用于房价预测、股票走势预测等回归场景。
- 并行计算优化:对于大规模数据集,可利用MATLAB的并行计算工具箱,将种群适应度计算改为并行执行,减少迭代时间。
六、注意事项
- 环境依赖:代码基于MATLAB R2011b及以上版本开发,需确保安装“Statistics and Machine Learning Toolbox”(包含
svmtrain与svmpredict函数),低版本MATLAB可能存在函数兼容性问题。 - 混沌映射选择:同一实验中仅能选择一种种群初始化方式(Tent或Logistic),不可同时启用,否则会导致种群初始化错误。
- 参数合理性检查:运行前需确认参数上下界(ub/lb)设置合理,避免出现上界小于下界的情况,否则边界约束处理函数会失效。
- 结果可重复性:由于算法包含随机过程(如初始种群、随机系数),每次运行结果可能存在微小差异,若需重复实验,可在代码开头添加“rng(seed)”(seed为固定整数)设置随机种子。
IGWO-SVM:改良的灰狼优化算法改进支持向量机。 采用三种改进思路:两种Logistic和Tent混沌映射和采用DIH策略。 采用基于DIH维度学习的狩猎搜索策略为每只狼构建邻域,增强局部和全局搜索能力,收敛速度比GWO更快,适用于paper。


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 13
13 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)