VAE模型
先来理解一下自编码器(Autoencoder, AE),它是一种无监督学习算法,主要用于数据降维和特征提取。它通过将输入数据编码成一个低维表示,然后再解码回原始数据,从而实现数据的压缩和重构。自编码器的结构通常包括一个编码器和一个解码器,编码器将输入数据转换为低维表示,解码器则将低维表示还原为原始数据,输入与输出的误差越小越好。
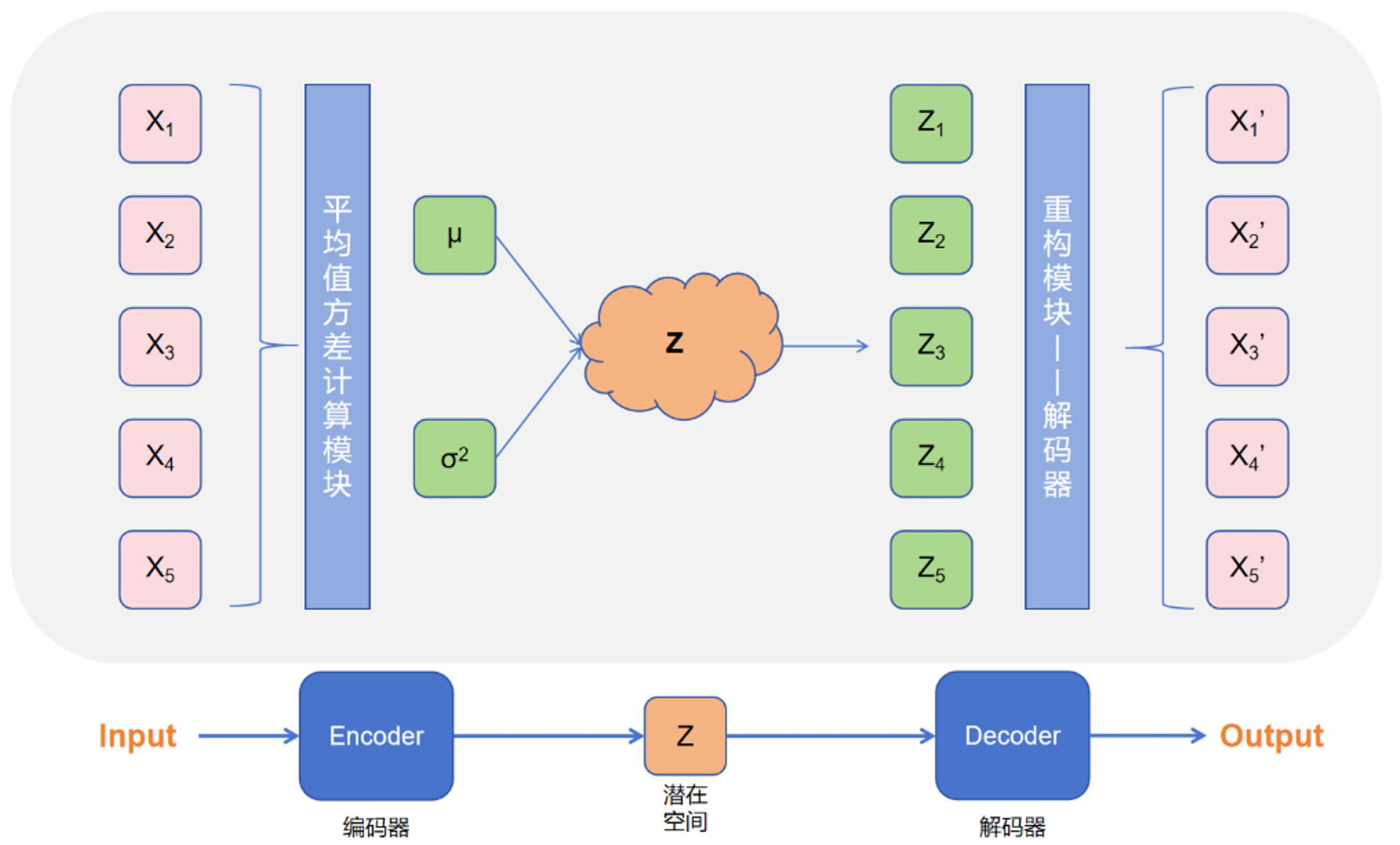
自编码器的结构如下:

其目标是最小化重构误差,损失函数如下:
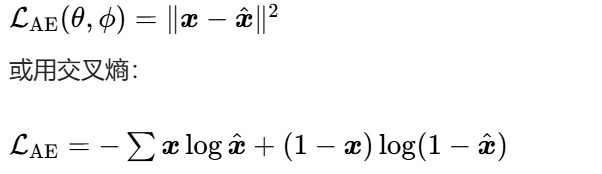
它能够学到数据的关键特征,但是隐空间不连续、不规则,不能生成新的合理数据。VAE就是一种使用了某种正则化方法的自编码器,它解决了自编码器的过拟合问题。
一.VAE设计思路
VAE作为一个生成模型,其基本思路是:把一堆真实样本通过编码器网络变换成一个理想的数据分布,然后这个数据分布再传递给一个解码器网络,得到一堆生成样本,生成样本与真实样本足够接近的话,就训练出了一个自编码器模型。所以,VAE就是在自编码器模型上做进一步变分处理,使得编码器的输出结果能对应到目标分布的均值和方差。
VAE最主要需要解决的就是编码器与解码器的构造,使图片能够编码成易于表示的形态,并且这一形态能够尽可能无损地解码回原真实图像。
自编码网络基本可以描述为,输入图像通过编码器(通常使用神经网络,使得编码的维度能够比原始图像的维度低非常多)得到图像的编码,然后再结合解码器生成图像,并尽可能接近原始图像。但这并不是一个生成模型,对于一个生成模型而言,解码器部分应该是单独能够提取出来的,并且对于在规定维度下任意采样的一个编码,都应该能通过解码器产生一张清晰且真实的图片。
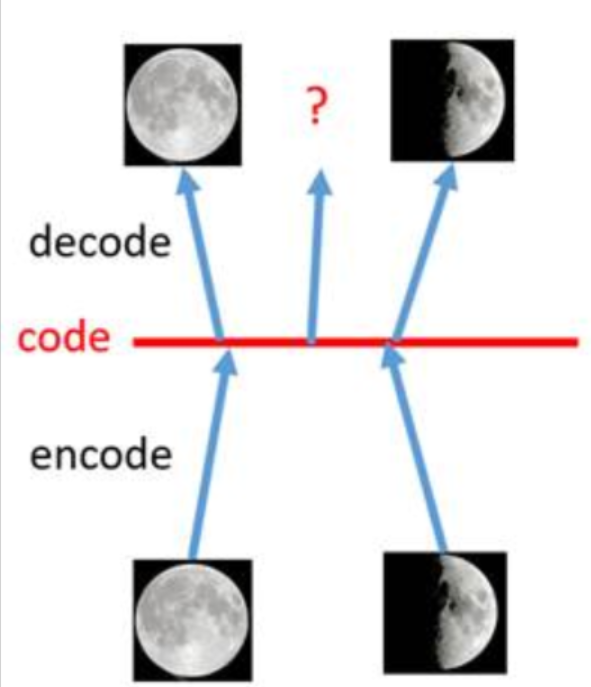
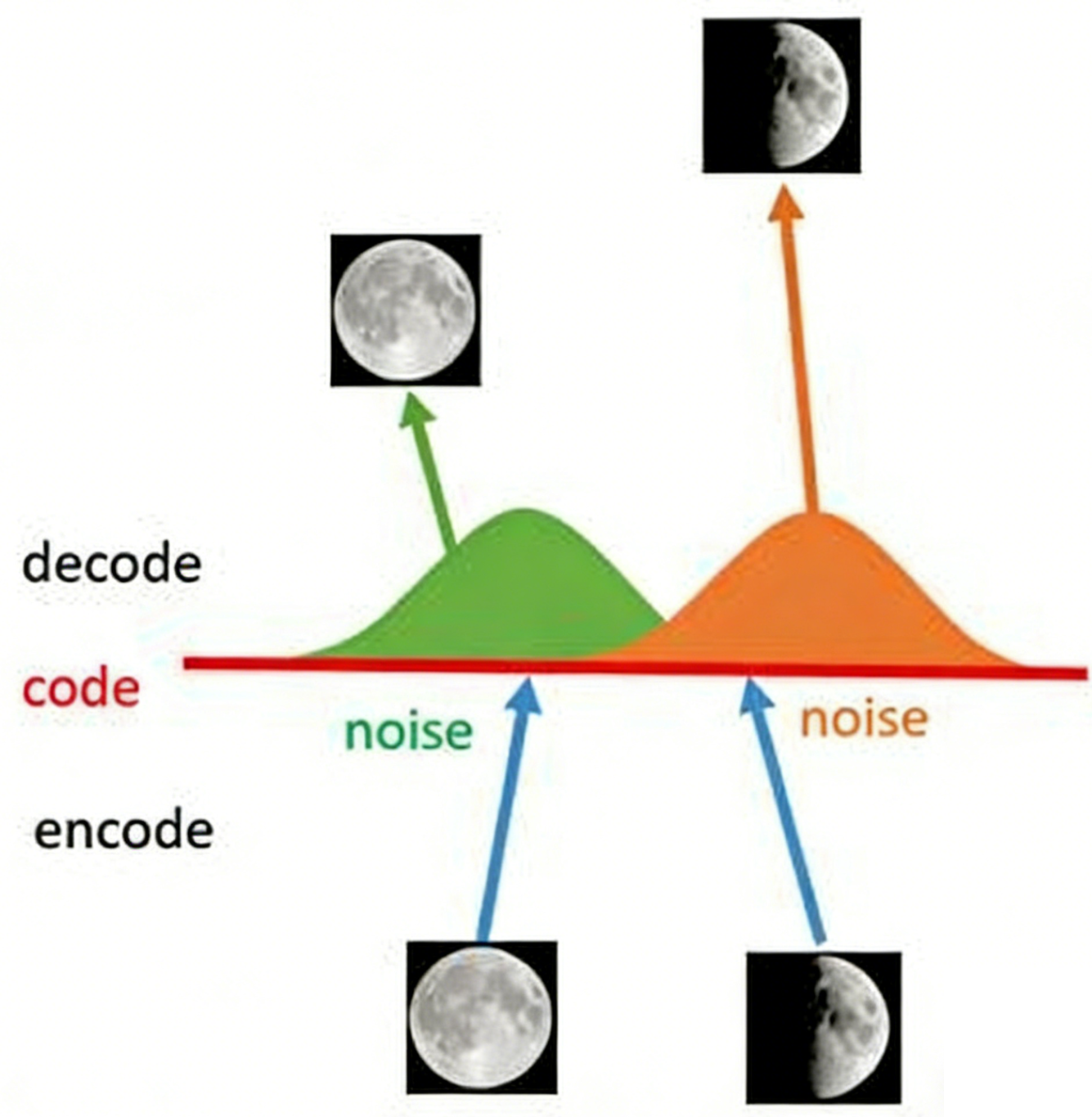
假设有两张训练图片,一张是全月图,一张是半月图,经过训练的自编码器模型已经能无损地还原这两张图片。接下来,在code空间上,从两张图片的编码点中间处取一点,然后将这一点交给解码器,我们希望新的生成图片是一张清晰的图片(类似3/4全月)。但是,实际生成的图片是模糊且无法辨认的乱码图。由于编码和解码的过程使用了深度神经网络,这是一个非线性的变换过程,所以在code空间上点与点之间的迁移是非常没有规律的。
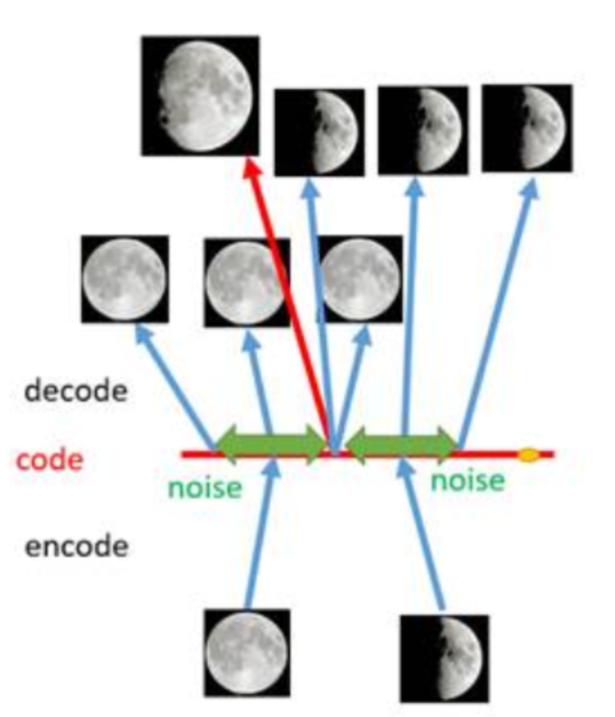
因此,我们可以引入噪声,使得图片的编码区域得到扩大,从而掩盖掉失真的空白编码点。在给两张图片编码的时候加上一点噪音,使得每张图片的编码点出现在绿色箭头所示范围内,于是在训练模型的时候,绿色箭头范围内的点都有可能被采样到,这样解码器在训练时会把绿色范围内的点都尽可能还原成和原图相似的图片。然后我们可以关注之前那个失真点,现在它处于全月图和半月图编码的交界上,于是解码器希望它既要尽量相似于全月图,又要尽量相似于半月图,于是它的还原结果就是两种图的折中(3/4全月图)。
那么,给编码器增添一些噪声,可以有效覆盖失真区域。但在上图的距离训练区域很远的黄色点处,它依然不会被覆盖到,仍是个失真点。所以,可以尝试把噪声无限拉长,使得对于每一个样本,它的编码会覆盖整个编码空间,但是我们需要做到在原编码附近编码的概率最高,离原编码点越远,编码概率越低。这样,图像的编码就由原先离散的编码点变成了一条连续的编码分布曲线。这种将图像编码由离散变为连续的方法,就是变分自编码器(Variational Autoencoder, VAE)的核心思想。
二.VAE模型原理
VAE是一种生成模型,结合了自编码器和概率图模型的特性。通过引入隐变量的概率分布,VAE能够生成新的数据样本,广泛应用于图像生成、数据降维和异常检测等领域。
VAE通过编码器(Encoder)将输入数据映射到隐变量的概率分布(通常是高斯分布),再通过解码器(Decoder)从隐变量重构数据。其目标是最小化重构误差并约束隐变量分布接近标准正态分布。
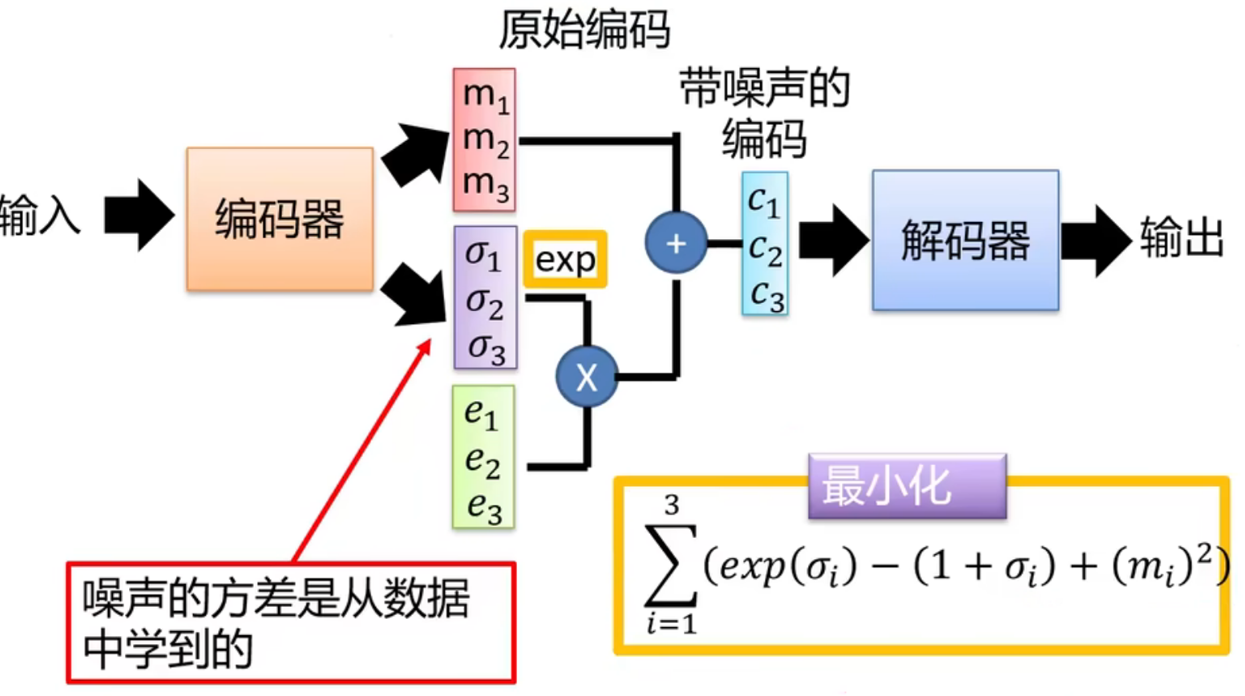
相当于对输入图像进行编码时,这里不会像自编码器中一样直接生成编码。而是为了给编码添加合适的噪音,生成一个编码和方差
的概率分布,
是分布的均值,
是分布的方差。接下来从这个分布中进行采集编码得到
,
= exp(
) *
+
, exp(
) 是标准差,
是原始样本,
是方差范围内采样的一个值,exp(
) *
是噪声。
损失函数方面,除了必要的重构损失外,VAE还增添了一个损失函数。为了保证生成图片的质量越高,编码器肯定希望噪音对自身生成图片的干扰越小,于是分配给噪音的权重越小,这样只需要将(σ1,σ2,σ3)赋为接近负无穷大的值就好了。所以,第二个损失函数就有限制编码器走这样极端路径的作用,这也从直观上就能看出来,exp(σi)-(1+σi)在σi=0处取得最小值,于是(σ1,σ2,σ3)就会避免被赋值为负无穷大。
二.VAE训练目标
数学上,VAE依然使用了编码器-解码器的架构,它是概率生成模型,核心在于隐变量 z 服从分布,从分布中采样生成 x。VAE的理论基础就是高斯混合模型,高斯混合模型就是说任何一个数据的分布,都可以看作是若干高斯分布的叠加。
编码器的输出是一个可学习的正态分布。对分布是不能做求导和梯度下降的,但是可以去分布里采样,对采样出来的编码进行解码并求导。VAE的损失函数除了要最小化重建图像与原图像之间的均方误差外,还要最大化每个分布和标准正态分布之间的相似度。常见的描述分布之间相似度的指标叫做KL散度。只要把KL散度的公式套进损失函数里,整个训练框架就算搭好了。所以,VAE的训练目标就是最大化所有样本的证据下界(ELBO),给定一个训练数据集![]() ,其中
,其中![]() 是干净的图像,ELBO 的最终形式为:
是干净的图像,ELBO 的最终形式为:
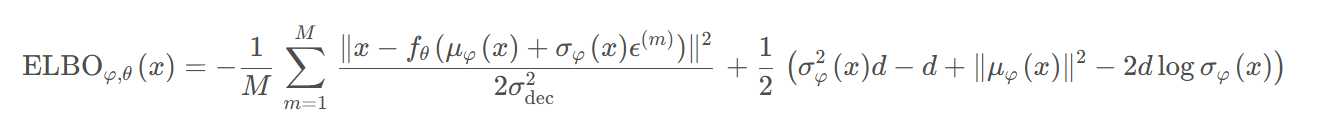
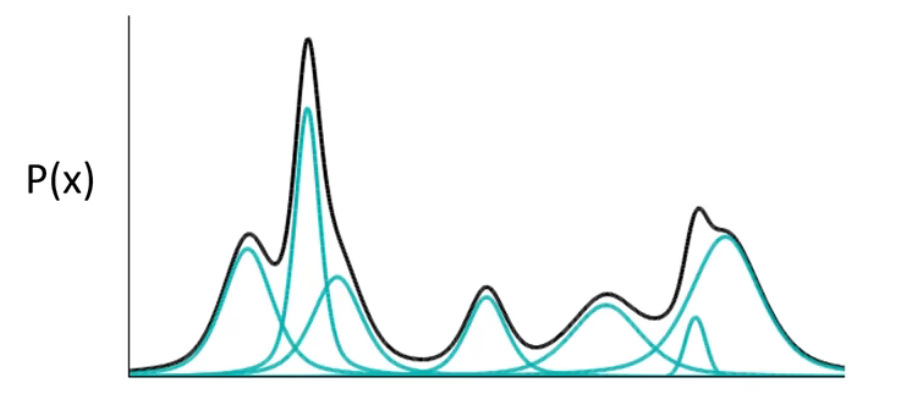
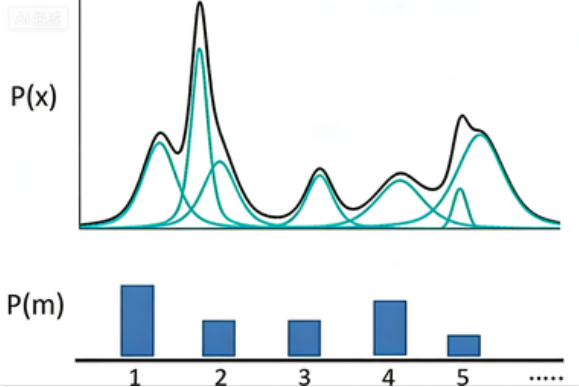
如果P(X)代表一种分布的话,存在一种拆分方法能让它表示成图中若干浅蓝色曲线对应的高斯分布的叠加。如果直接用每一组高斯分布的参数作为一个编码值实现编码,如图所示,m代表着编码维度上的编号,例如实现一个512维的编码,m的取值范围就是1,2,3……512。m会服从于一个概率分布P(m)(多项式分布)。现在编码的对应关系是,每采样一个m,其对应到一个小的高斯分布N(μm,∑m),P(X)就可以等价为所有的这些高斯分布的叠加,即![]() ,其中
,其中![]() 。这种方式对应的是之前提到的离散的、有大量失真区域的编码方式。
。这种方式对应的是之前提到的离散的、有大量失真区域的编码方式。
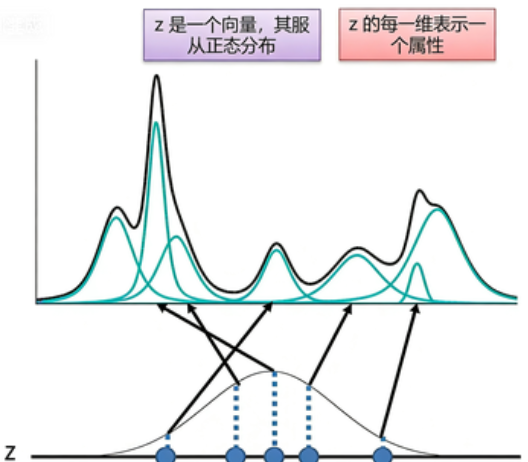
对目前的编码方式进行改进,使得它成为连续有效的编码。如果将编码换成一个连续变量z,规定z服从正态分布N(0,1)(实际上并不一定要选N(0,1)用,其他的连续分布都是可行的)。每对于一个采样z,会有两个函数μ和σ,分别决定z对应到的高斯分布的均值和方差,然后在积分域上所有的高斯分布的累加就成为了原始分布P(X),即![]() ,其中
,其中![]() 。
。
训练过程通过随机梯度下降,优化θ和φ,梯度利用自动微分自动计算。核心公式如下:
概率假设:

编码器输出分布:
![]()
重参数化:

三.VAE的实现步骤
-
编码器输出均值 μ 和方差 σ(而非单一隐向量)
-
重参数化技巧实现可微分的采样
-
损失函数 = 重构损失 + KL 散度
代码示例
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
# 超参数
latent_dim = 20 # 隐向量维度(压缩后的特征维度)
hidden_dim = 400 # 编码器/解码器隐藏层维度
num_epochs = 10 # 训练轮数
batch_size = 128 # 批次大小
learning_rate = 1e-3 # 学习率
sigma_dec = 0.1 # 解码器方差超参数(用于重构损失的缩放)
# 编码器
# 编码器的作用是把输入的 784 维图片向量,映射成隐空间的概率分布参数(μ 和 log_var)
class Encoder(nn.Module):
def __init__(self, input_dim=784, hidden_dim=400, latent_dim=20):
super(Encoder, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc21 = nn.Linear(hidden_dim, latent_dim) # 均值
self.fc22 = nn.Linear(hidden_dim, latent_dim) # 对数方差
self.relu = nn.ReLU()
def forward(self, x):
h = self.relu(self.fc1(x))
mu = self.fc21(h)
log_var = self.fc22(h)
return mu, log_var
# 解码器
class Decoder(nn.Module):
def __init__(self, latent_dim=20, hidden_dim=400, output_dim=784):
super(Decoder, self).__init__()
self.fc1 = nn.Linear(latent_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, output_dim)
self.relu = nn.ReLU()
self.sigmoid = nn.Sigmoid()
def forward(self, z):
h = self.relu(self.fc1(z))
return self.sigmoid(self.fc2(h)) #400→784,Sigmoid压缩到[0,1](匹配MNIST像素值范围)
# VAE 模型
"""
如果直接从 N(μ, σ²) 采样 z,采样操作是不可微分的,梯度无法回传到编码器
重参数化把采样拆成「固定分布采样 ε」+「确定变换 z=μ+ε×σ」,让梯度可以正常回传
"""
class VAE(nn.Module):
def __init__(self, encoder, decoder):
super(VAE, self).__init__()
self.encoder = encoder
self.decoder = decoder
def reparameterize(self, mu, log_var):
std = torch.exp(0.5 * log_var)#标准差
eps = torch.randn_like(std)# 采样ε ~ N(0, I),形状和std一致
return mu + eps * std#重参数化:z = μ + ε×σ
def forward(self, x):
mu, log_var = self.encoder(x)
z = self.reparameterize(mu, log_var)#采样z
return self.decoder(z), mu, log_var
# 损失函数
def loss_function(recon_x, x, mu, log_var, sigma_dec=sigma_dec):
recon_loss = torch.mean(torch.sum((x - recon_x) ** 2, dim=1)) / (2 * sigma_dec ** 2)
kl_div = -0.5 * torch.sum(1 + log_var - mu.pow(2) - log_var.exp())
return recon_loss + kl_div
# 数据加载
transform = transforms.ToTensor()
train_dataset = datasets.MNIST('./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# 模型初始化
encoder = Encoder()
decoder = Decoder()
vae = VAE(encoder, decoder)
optimizer = optim.Adam(vae.parameters(), lr=learning_rate)
# 训练循环
for epoch in range(num_epochs):
for batch_idx, (data, _) in enumerate(train_loader):
data = data.view(-1, 784) # 展平图像
optimizer.zero_grad()
recon_batch, mu, log_var = vae(data)
loss = loss_function(recon_batch, data, mu, log_var)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print(f'Epoch {epoch}, Batch {batch_idx}, Loss: {loss.item():.4f}')
# 推理:生成新图像
with torch.no_grad():
z = torch.randn(1, latent_dim)# 从标准正态分布采样1个隐向量z
generated_image = decoder(z).view(28, 28)# 解码→展平为28×28图片
# 可视化 generated_image(需添加 matplotlib 代码)
plt.imshow(generated_image.numpy(), cmap='gray')
plt.axis('off')
plt.show()
print("Training finished!")
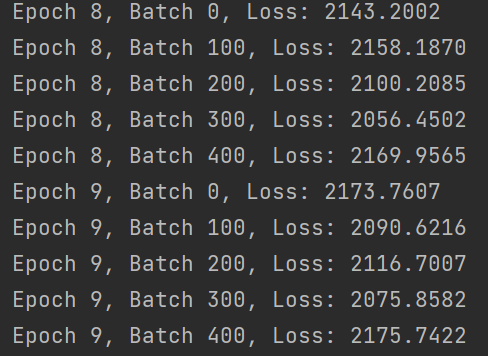
运行9个epoch后,输出结果,这就是一张没有在训练集中出现过的新图片:


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)