从 QPS 到 TT/FT,当 RAG 成为标配,AI 性能测试到底卡在哪?
关注 霍格沃兹测试学院公众号,回复「资料」, 领取人工智能测试开发技术合集
最近做 AI 应用的团队都有遇到一个困惑:
接口压测数据很好看, 但用户体验却“卡”。
QPS 上去了, 可回答迟迟不出来。
问题出在哪?
不是模型不行, 而是测试视角还停留在传统时代。
-
首字延迟为什么突然重要
-
GPU 为什么成了性能主战场
-
RAG 上线后,测试难度为什么陡增
目录
-
QPS 还在涨,用户却觉得慢?
-
TT / FT:首字延迟为什么变成核心指标
-
GPU 资源:性能瓶颈已经不在 CPU
-
RAG 为什么成为测试重点
-
RAG 专项测试的三个高频翻车点
-
多模态解析:最容易被忽略的风险
-
参数不是调大小:TOPK 背后的逻辑
一、QPS 很高,用户却说慢?
在传统性能测试里,我们盯着:
-
QPS
-
CPU
-
内存
-
平均响应时间
但 AI 应用里,用户体验并不完全由“总响应时间”决定。
流式输出场景下,用户感知的是:
多久开始出现第一个字。
这就引出了两个指标:
-
TT(Time To First Token)
-
FT(First Token Time)
它测的不是“答完多久”, 而是“开始多久”。
当 TT 从 600ms 变成 1.8s, 用户会明显感觉“卡”。
即使总耗时差别不大。
这在传统系统里几乎不被关注。
二、首字延迟到底发生在哪?
可以用一个简单流程看清楚:
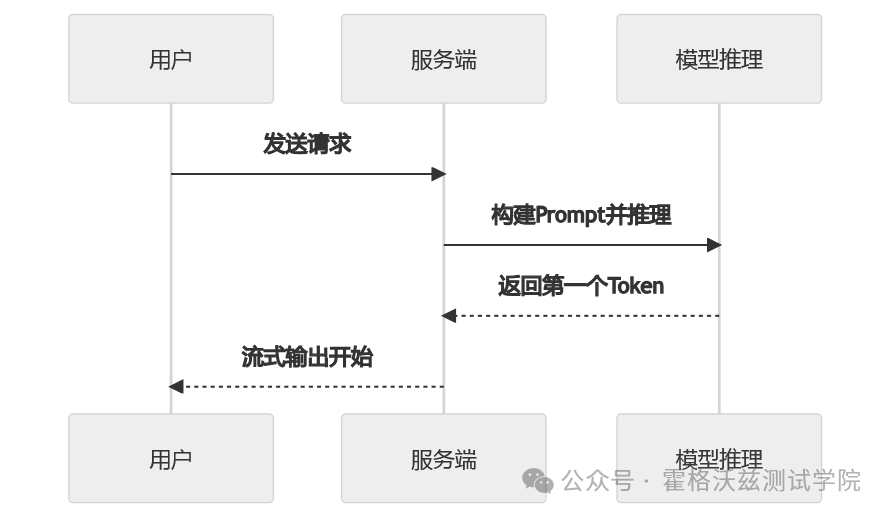
TT 本质上测的是:
从“发送请求”到“收到第一个 Token”。
这段时间包含:
-
Prompt 构建
-
检索拼接
-
模型首次推理
-
GPU 调度
其中任一环节变慢,首字延迟都会上升。
这也是为什么接口层压测正常,但用户体感变差。
三、GPU:性能瓶颈已经换了地方
AI 性能测试绕不开 GPU。
你要关注的不再只是:
“CPU 有没有打满”
而是:
-
显存是否溢出
-
推理是否触发 OOM
-
KV Cache 是否暴涨
-
显卡温度是否持续高位
举个典型场景:
服务器有 4 张 22GB 显卡(共 88GB 显存)。
当并发提升时,问题可能不是接口崩溃,而是:
显存碎片化严重,推理时间拉长。
AI 性能曲线和传统 Web 服务完全不同。
它更像持续计算过程,而不是一次短事务调用。
四、RAG 上线后,测试复杂度翻倍
以“生源地助学贷款 AI 助手”为例。
如果模型是本地部署的,它可能无法回答:
“助学贷款客服电话是多少?”
因为训练数据不是实时更新的。
于是引入 RAG(检索增强生成)。
流程变成:

模型不再只靠“记忆”。
它开始“查资料”。
但测试难度也随之增加。
五、RAG 测试的三个常见翻车点
1. 只测标准提问
真实用户不会问:
“生源地助学贷款客服电话是多少?”
他们可能问:
-
“助学贷款电话多少?”
-
“怎么联系官方?”
-
“有没有客服电话?”
测试如果只覆盖标准问法,召回质量根本无法验证。
2. 参数不理解,只会调数值
常见参数:
-
TOPK
-
相似度阈值
-
Chunk 大小
例如:
TOPK=1 → 精准但容易漏召回 TOPK=5 → 召回更多但噪声增加
如果回答出现“答非所问”, 问题可能不是模型,而是检索策略。
3. 多模态盲区
知识库里有一份注册协议。
关键条款是图片格式。
如果系统没有图像解析能力:
它根本读不到那部分内容。
测试需要关注:
-
是否支持图文解析
-
OCR 是否正确
-
图片是否被向量化
否则系统表面完整,实际存在盲区。
六、AI 测试的结构性变化
从这次内容可以看到一个清晰趋势:
-
性能指标从“总耗时”转向“首字延迟”
-
性能瓶颈从 CPU 转向 GPU
-
测试类型增加 RAG、提示词、工具链专项
-
检索质量成为系统稳定性的关键变量
-
多模态能力成为新的风险来源
测试对象已经变了。
如果测试方法不变, 问题会反复出现。
写在最后
当一个系统开始:
-
流式输出
-
使用 GPU 推理
-
检索知识库
-
解析图片
测试就不能只盯着 QPS。
AI 性能测试不是“传统压测+模型”。
它是一次工程结构的变化。
而真正的难点,从来不在模型本身。
往往在:
-
首字延迟
-
召回质量
-
参数策略
-
多模态盲区
当这些点被看清,很多“神秘问题”其实都能解释。
关于我们
霍格沃兹测试开发学社,隶属于 测吧(北京)科技有限公司,是一个面向软件测试爱好者的技术交流社区。
学社围绕现代软件测试工程体系展开,内容涵盖软件测试入门、自动化测试、性能测试、接口测试、测试开发、全栈测试,以及人工智能测试与 AI 在测试工程中的应用实践。
我们关注测试工程能力的系统化建设,包括 Python 自动化测试、Java 自动化测试、Web 与 App 自动化、持续集成与质量体系建设,同时探索 AI 驱动的测试设计、用例生成、自动化执行与质量分析方法,沉淀可复用、可落地的测试开发工程经验。
在技术社区与工程实践之外,学社还参与测试工程人才培养体系建设,面向高校提供测试实训平台与实践支持,组织开展 “火焰杯” 软件测试相关技术赛事,并探索以能力为导向的人才培养模式,包括高校学员先学习、就业后付款的实践路径。
同时,学社结合真实行业需求,为在职测试工程师与高潜学员提供名企大厂 1v1 私教服务,用于个性化能力提升与工程实践指导。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 15
15 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)