空气质量 PM2.5 浓度高创新预测模型!基于VMD滚动分解+注意力机制的并行预测模型

往期精彩内容:
VMD + CEEMDAN 二次分解,BiLSTM-Attention预测模型-CSDN博客
基于麻雀优化算法SSA的预测模型——代码全家桶-CSDN博客
高创新 | CEEMDAN + SSA-TCN-BiLSTM-Attention预测模型-CSDN博客
独家原创 | 基于TCN-SENet +BiGRU-GlobalAttention并行预测模型-CSDN博客
独家原创 | BiTCN-BiGRU-CrossAttention融合时空特征的高创新预测模型-CSDN博客
CEEMDAN +组合预测模型(CNN-Transfromer + XGBoost)-CSDN博客
时空特征融合的BiTCN-Transformer并行预测模型-CSDN博客
独家首发 | 基于多级注意力机制的并行预测模型-CSDN博客
独家原创 | CEEMDAN-CNN-GRU-GlobalAttention + XGBoost组合预测-CSDN博客
暴力涨点! | 基于 Informer+BiGRU-GlobalAttention的并行预测模型-CSDN博客
重大更新!锂电池剩余寿命预测新增 CALCE 数据集_calce数据集-CSDN博客
基于 VMD滚动分解+Transformer-GRU并行的锂电池剩余寿命预测模型
快速傅里叶变换暴力涨点!基于时频特征融合的高创新时间序列分类模型-CSDN博客
基于CNN-BiLSTM-Attention的回归预测模型!-CSDN博客
独家原创 | CEEMDAN-Transformer-BiLSTM并行 + XGBoost组合预测-CSDN博客
涨点创新 | 基于 Informer-LSTM的并行预测模型-CSDN博客
一区直接写!CEEMDAN分解 + Informer-LSTM +XGBoost组合预测模型
基于Informer-SENet的光伏电站发电功率预测对比合集!6组对比预测模型,毕业论文、小论文直接写!
独家创新!基于ICEEMDAN+SHAP可解释性分析的锂电池剩余寿命预测高创新模型!
独家创新!基于Informer-BiGRUGATT-CrossAttention的预测模型
高创新!基于ICEEMDAN+MSCNN-BiGRU-Attention并行预测模型
独家首发!基于VMD滚动分解+Transformer-LSTM的并行预测模型
前言
随着城市工业化进程的加快,空气污染问题,尤其是PM2.5浓度的预测,成为环境科学和公共健康领域的研究重点。针对PM2.5序列的非平稳性和复杂性,本文提出了一种基于变分模态分解(Variational Mode Decomposition, VMD)滚动分解与Transformer和基于全局注意力机制优化的双向门控循环单元网络(BiGRU)的并行融合预测模型。该方法利用VMD对时间序列信号进行多模态分解,有效剥离信号内在的多个频段成分,再将不同成分的信息同步输入多模型架构,充分挖掘序列的复杂动态特征,从而显著提升预测性能。

● 数据集:上海市PM2.5数据集
● 环境框架:python 3.11 pytorch 2.1 及其以上版本均可运行
● 使用对象:论文需求、毕业设计需求者
● 代码保证:代码注释详细、即拿即可跑通。
注:数据集说明-中国五城市的PM2.5数据,沈阳、成都、北京、广州和上海的测量数据
数据集获取,后台回复”PM2.5“,可获取我们已经打包好的数据集!
1 模型介绍
1.1 总体架构设计
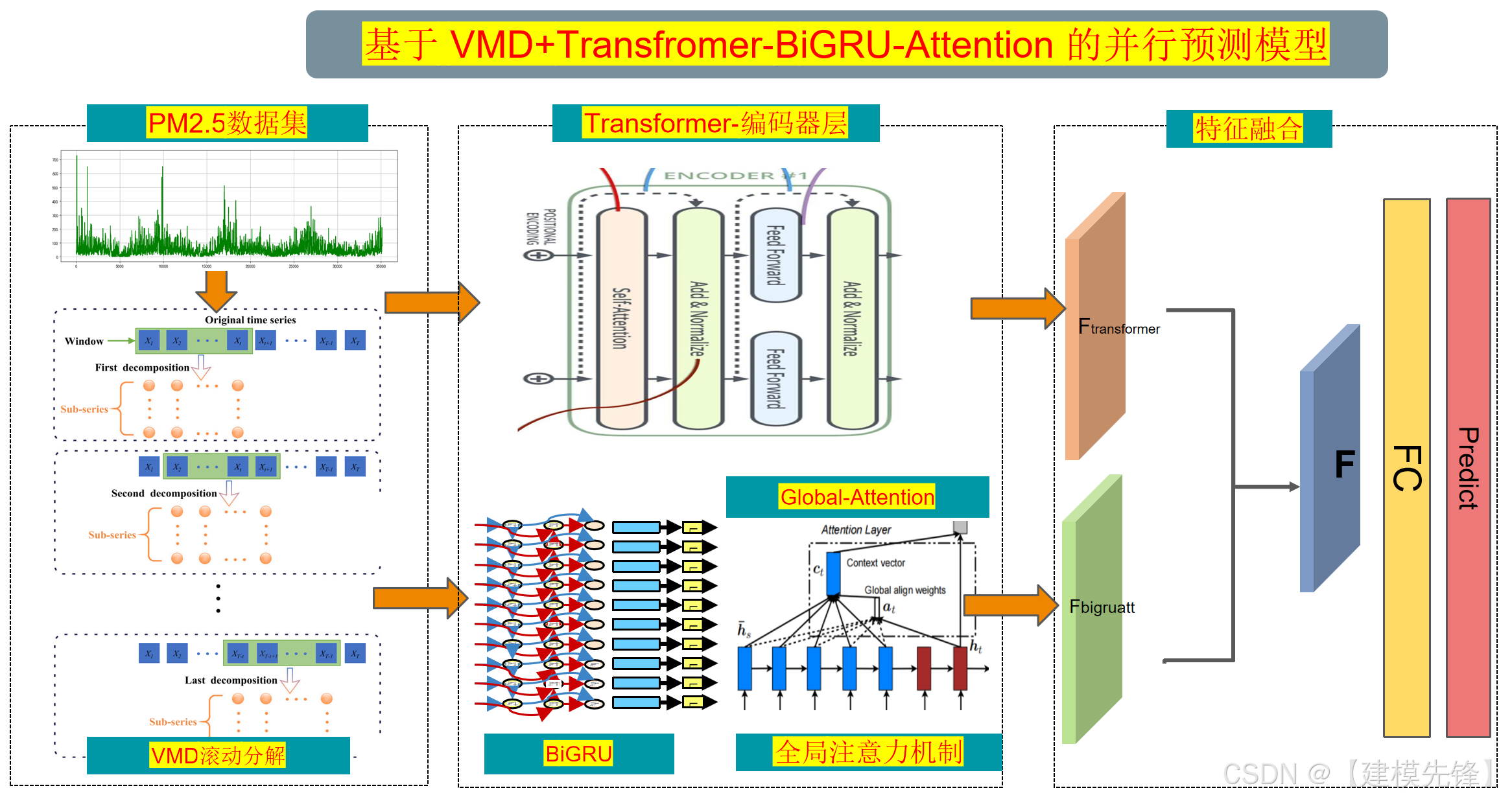
Transformer+BiGRU-Attention并行神经网络架构:
-
Transformer模块:Transformer通过自注意力机制(Self-Attention)充分挖掘序列全局依赖信息,具备并行计算优势,适合处理长序列。本文采用多头注意力机制捕获多模式相关特征,提升模型对空气质量复杂波动趋势的学习能力。
-
BiGRU-Attention模块:双向GRU为改进型RNN,具备学习正向和反向序列信息能力,适合捕捉上下文时序依赖。本文引入全局注意力(GlobalAttention)机制,优化传递的隐藏状态信息,使模型更关注对预测关键的时刻与特征,进一步提升表示质量和预测性能
1.2 整体流程
首先,利用VMD对原始PM2.5序列进行多尺度分解,提取不同频率成分,以提升序列的规律性和可预测性;其次,设计了Transformer和GlobalAttention优化的BiGRU的并行融合架构,有效捕捉序列的长短时依赖性与全局特征。实验结果表明,本文所提模型在预测精度和泛化能力上均优于传统模型,实现了对PM2.5浓度变化的高准确度预测,为空气质量预报提供了理论和方法支持。
1.3 滑动窗口与VMD滚动分解
(1)数据集导入
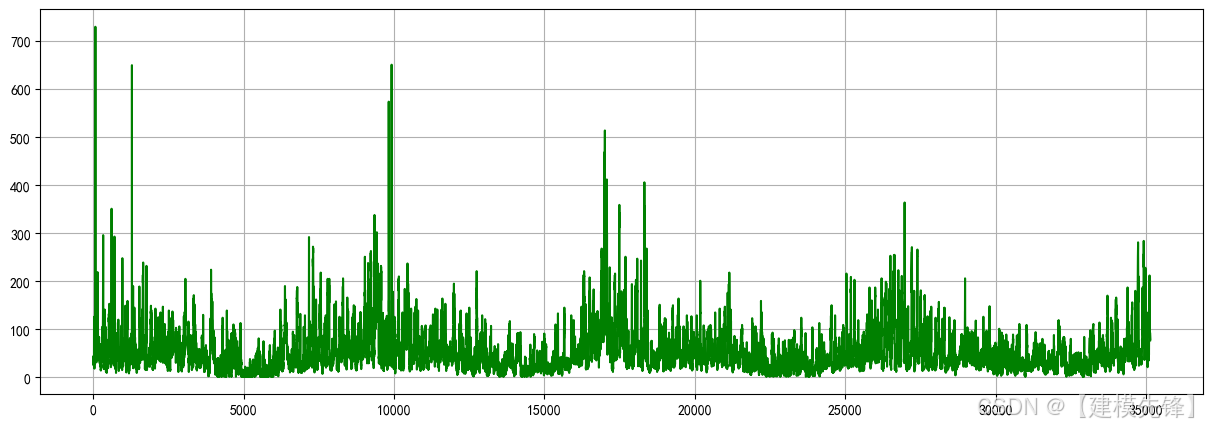
本实验采用上海市PM2.5数据集,一共35142个样本,17个特征,取目标变量数据进行可视化

(2)VMD滚动分解
多变量时间序列数据,归一化处理后采用滑动窗口技术,将序列切分成固定长度的样本窗口,为VMD分解提供基础。
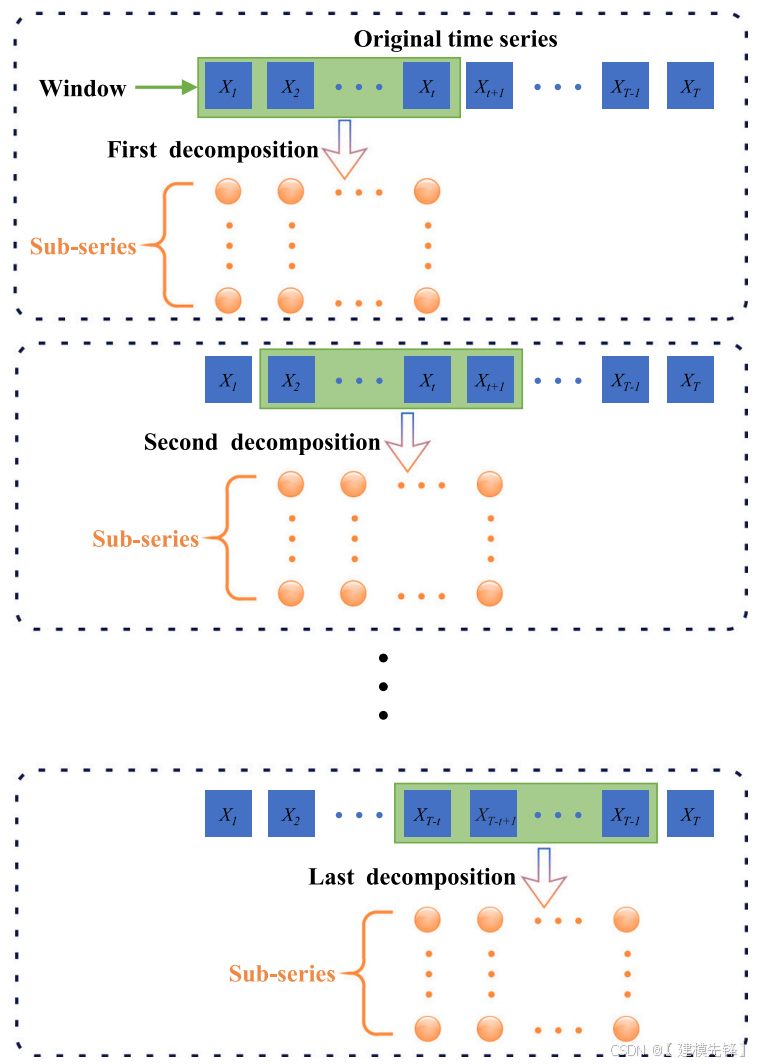
通过在原始系列上滑动固定大小的窗口来解决只分解窗口中的数据。也就是说,每次都有新的数据添加后,窗口中最旧的数据将被删除。通过这种方式分解后生成的子序列数量保持不变,没有数据信息泄露。此外,选择合适的滑动窗口尺寸至关重要。一个小窗口导致数据不足,重要信息丢失,预测减少精度。相反,大窗口会增加计算量复杂性和运行时间,减少可用的训练数据,减少模型有效性。
2 基于VMD+Transformer-BiGRU-Attention的并行预测模型
2.1 设置参数,训练模型
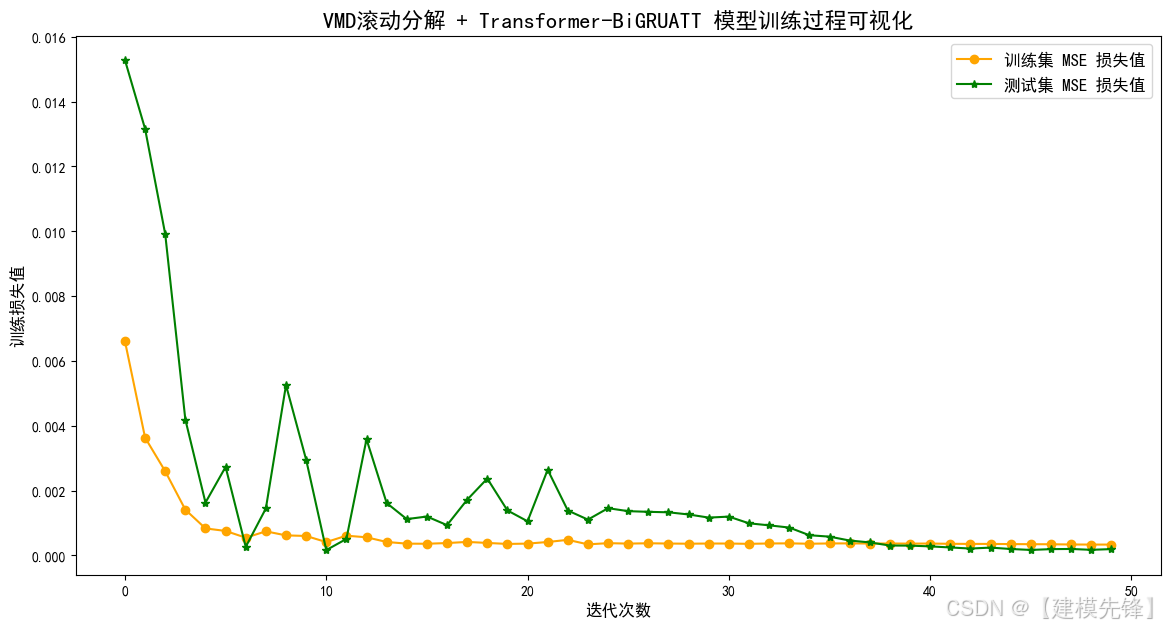
VMD+Transformer-BiGRU-Attention预测效果显著,VMD滚动分解增强了对复杂时间序列多尺度特征抽取的能力,结合Transformer和BiGRU-Attention的并行架构,实现了全局长短期依赖的补充。模型将VMD分解的多个分量分别输入Transformer和GlobalAttention-BiGRU两个子网络,经过特征提取再融合,兼顾两者优势:Transformer捕获全局多尺度依赖;BiGRU更注重序列局部动态与时序关系。最后通过融合层整合特征输出最终预测结果,增强模型稳定性与泛化能力。
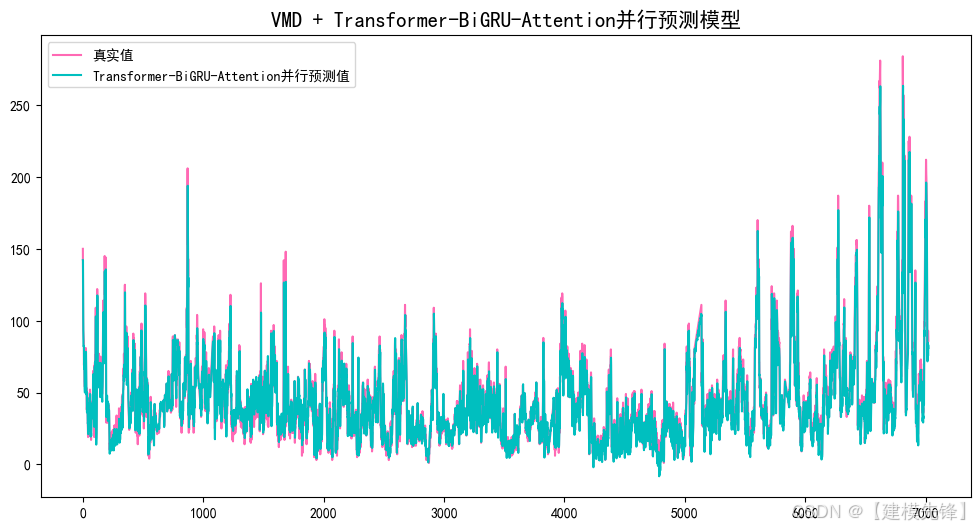
2.2 预测结果可视化
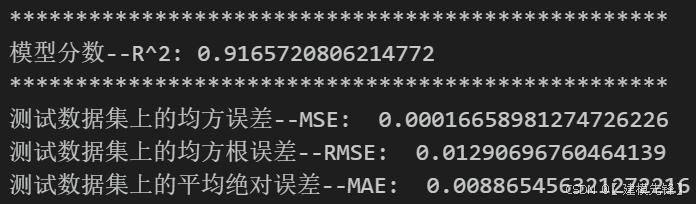
2.3 模型评估
有建模需求或论文指导的朋友请关注公众号,联系博主
3 代码、数据整理如下:

点击下方卡片获取代码!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)