误差状态卡尔曼滤波(ESKF)推导
目录
注:本篇笔记的主体内容来源于对深蓝学院《多传感器融合定位》课程的学习,推荐有一定基础的SLAM 初学者学习该课程。课程中提供了一个完整的滤波器代码框架,可供体会从理论到代码实现的过程。
符号约定:
、
:预测值(先验)
:更新值(后验)
:误差状态
1. 概率基础知识
1.1 独立
![]()
“ 独立 ” 描述两个随机变量互不影响。若 x 和 y 独立,说明 “ x 发生的概率,不会因 y 是否发生而改变 ” ,反之亦然。
- 联合概率p(x, y):独立时, “ x 且 y 发生 ” 的概率,等价于 “ x 发生概率 ” 乘以 “ y 发生概率” ( 比如抛两枚独立硬币,同时正面的概率 = 第一枚正面概率 × 第二枚正面概率 ) 。
- 条件概率p(x|y):“ 已知 y 发生时 x 发生的概率 ” ,因独立无影响,所以等于 p(x) 本身;同理p(y|x) = p(y)。
1.2 全概率公式
![]()
全概率公式用于“ 由局部推整体 ”:若 y 是一组 “ 互斥且穷尽所有可能的事件 ” ( 比如 y 代表 “ 天气:晴、雨、雪等 ” ,覆盖所有可能),那么 x 发生的总概率,等于 “ y 取每个可能值时, x 发生的条件概率 ” 乘以 “ y 本身的概率 ” ,再累加或积分(比如 “ 求出门概率 p(x) ” ,可拆成 “ 晴天时出门概率 × 晴天概率 + 雨天时出门概率 × 雨天概率 + …” ) 。
1.3 条件概率公式
![]()
该公式描述了x与y不独立时的联合概率,表达了联合概率与条件概率的转换: “ x 和 y 同时发生的概率 ” ,既可以理解为 “ 已知 y 发生时 x 发生的概率,乘以 y 发生的概率 ” ( 比如 “ 已知下雨( y )时打伞( x )的概率,乘以下雨的概率 ” ) ;也可以对称地理解为“ 已知 x 发生时 y 发生的概率,乘以 x 发生的概率 ” 。
1.4 贝叶斯公式
![]()
该公式的核心是“ 由结果推原因 ” (逆概率) :已知 “ 结果 y 发生 ” ,求 “ 原因 x 导致 y ” 的概率。
- 分子p(y|x)p(x):先验部分,p(x)是 “ 原因 x 本身的概率(先验概率) ” ,p(y|x)是 “ x 导致 y 的可能性(似然) ” 。
- 分母p(y):通过全概率公式计算的 “ 结果 y 发生的总概率(证据) ” ,用于归一化,保证p(x|y)是合法概率(和为 1 ) 。
比如 “ 已知检测阳性(y),求真正患病(x)的概率 ” ,就需要用贝叶斯公式,结合 “ 患病概率 p(x)、患病时检测阳性概率 p(y|x) 、全体检测阳性概率 p(y) ” 推导 。
1.5 高斯概率密度函数
1)一维情况下,高斯概率密度函数表示为:
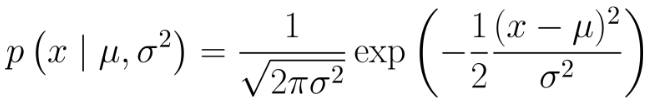
其中,为均值,
为方差。
2)多维情况下,高斯概率密度函数表示为:
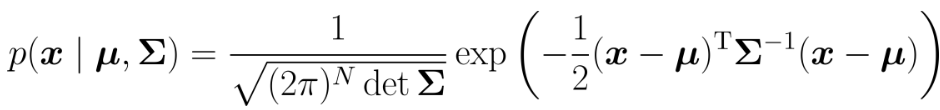
其中,为均值,
为方差。一般把高斯分布写成
。


1.6 联合高斯概率密度函数
在SLAM过程中,我们是根据内感传感器(如IMU、轮速计)的运动感知和外感传感器对当前环境的观测来进行自身定位的。使用概率来描述的话,假设当前机器人位姿为x,当前对环境的观测为y,有高斯分布:
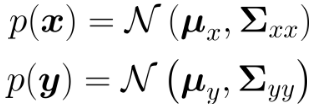
我们需要求解,在已知当前观测y的条件下,机器人位姿x是怎样的,从概率的角度来看即p(x|y)。求解的过程可以从二者的联合概率密度出手,因为x与y并不独立,所以:
![]()
而二者的联合概率密度函数可以表示为:
![]()
由于高斯分布中指数项中包含方差的求逆,而此处联合概率的方差是一个高维矩阵,对它求逆的简洁办法是运用舒尔补。
舒尔补的主要目的是把矩阵分解成上三角矩阵、对角阵、下三角矩阵乘积的形式,方便运算,即:
其中
称为矩阵D关于原矩阵的舒尔补。此时有:
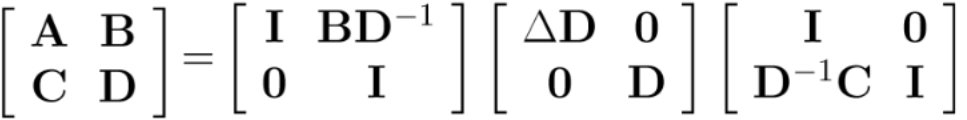
利用舒尔补,联合分布的方差矩阵可以写为:
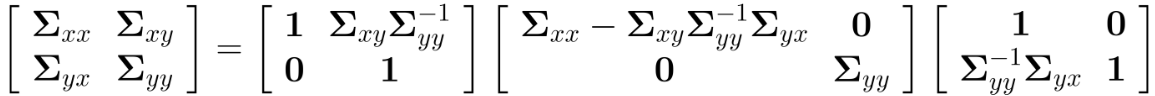
其逆矩阵为:
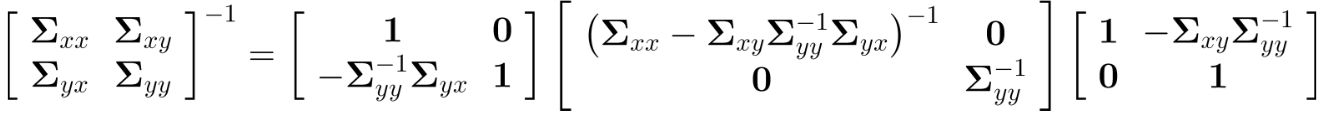
则高斯分布指数部分
可以表示为:

又因为:
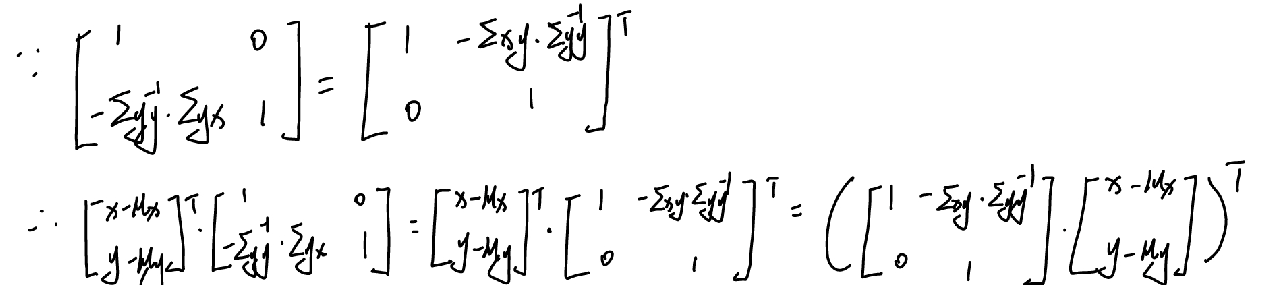
所以高斯分布指数部分可以表示为:
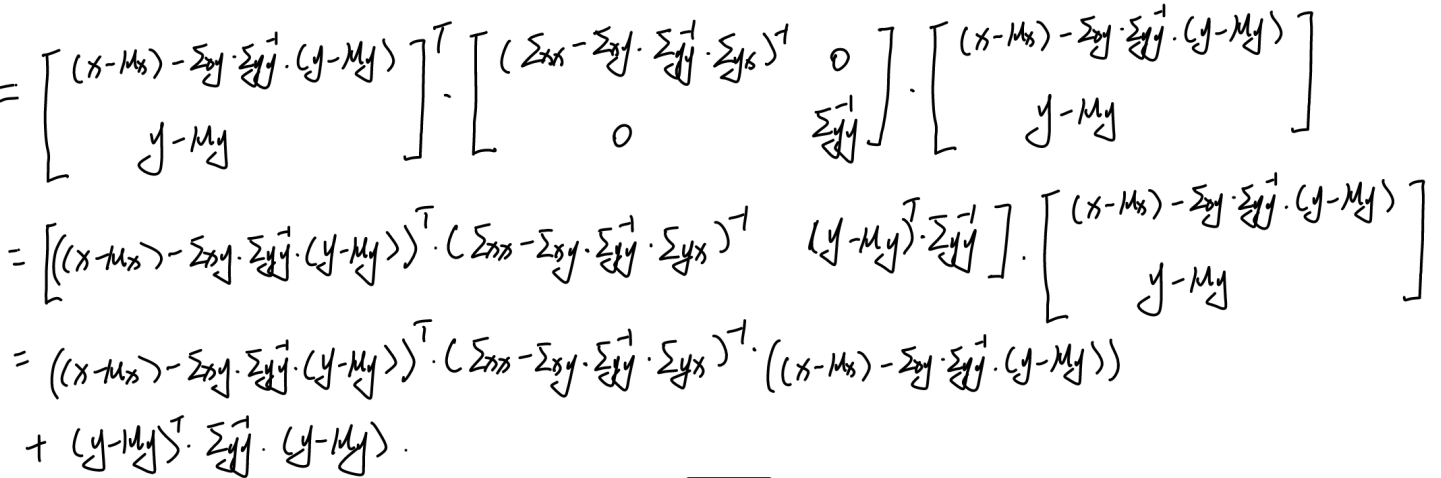
经过化简,原本复杂的联合分布二次项被拆分成了两个独立的部分 。第二项对应的是边缘分布的指数项 :
![]()
第一项对应的是条件分布的指数项:
![]()
从中可以直接读出后验均值和方差 ,所以:
这一步推导在数学上证明了:两个变量的联合高斯分布,其关于其中一个变量的条件分布仍然是高斯分布 。
1.7 高斯随机变量的线性分布
在上面的例子中,若已知𝒙和𝒚之间有如下关系:
其中,G和C可以看作是两个系数矩阵,为零均值白噪音,在实际中指的是观测噪音。下面推导y与x的均值和方差之间的关系:
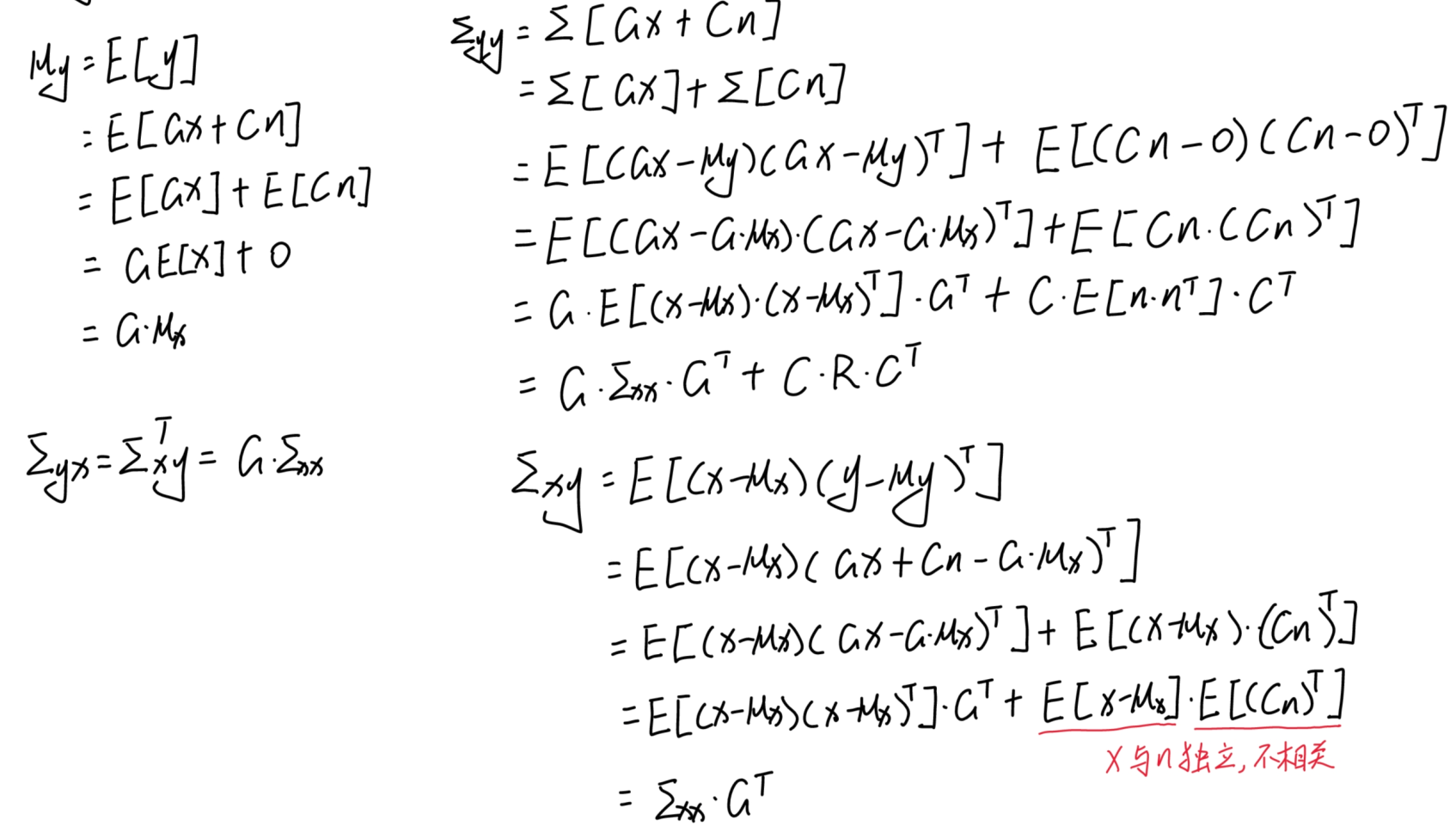
2.滤波器基本原理
2.1 状态估计模型
状态估计任务中,待估计的状态的后验概率密度可以表示为:
![]()
其中,代表状态初始值,
代表从1到k时刻的内感传感器输入(如imu、轮速计),
代表从0到k时刻的外感传感器对环境的观测(如激光雷达)。
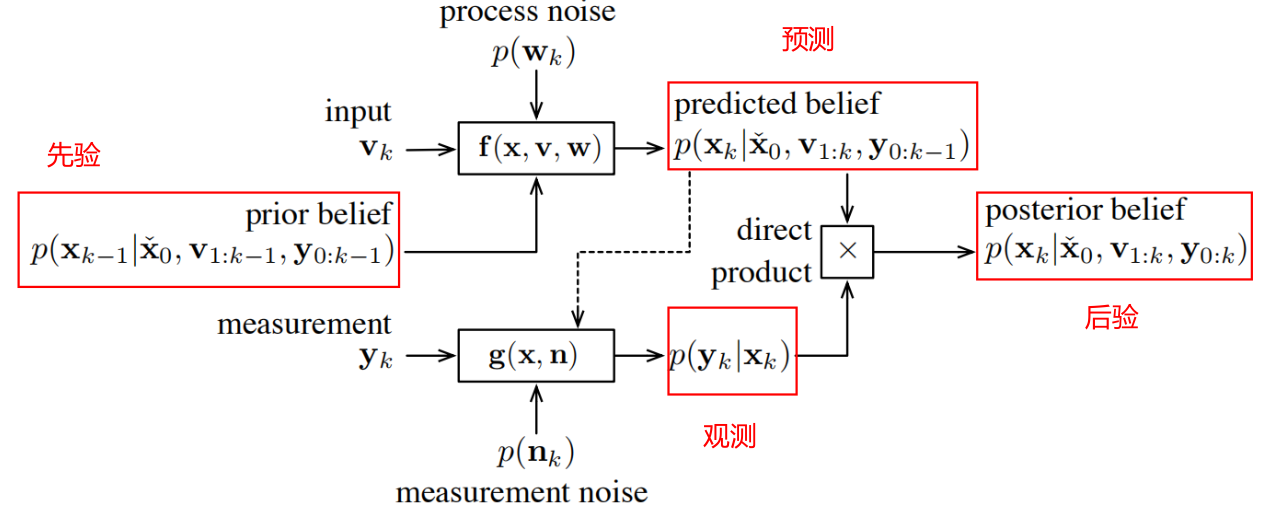
因此,滤波问题可以直观表示为,根据所有历史数据(初始状态、输入、观测)得出最终的融合结果。历史数据之间的关系,可以用下面的图模型表示:
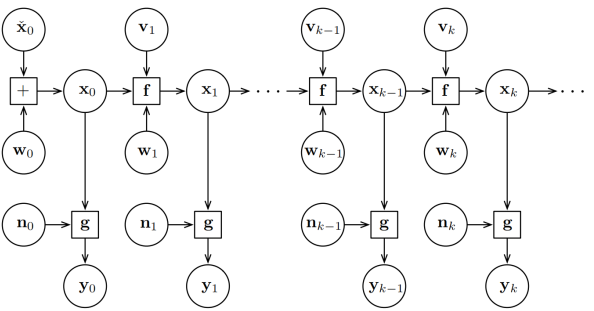
其中,w代表imu积分的过程噪音(imu测量的随机游走和bias随机游走),f代表状态转移函数,通常对应imu的积分过程,x代表惯性解算递推出的状态估计值;n代表观测噪音,y代表该时刻的观测(如激光雷达的扫描点云,或者更直接的是scan to map得到的机器人位姿T),g代表观测函数,表示根据当前状态x推导出理论的观测值。
图模型中体现了马尔可夫性,即当前状态只跟前一时刻状态相关,和其他历史时刻状态无关。该性质的数学表达:
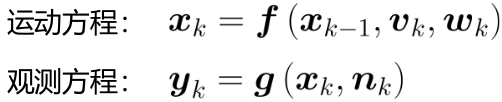
(这个图中没有表示如何根据已知观测y去更新估计值x)
2.2 贝叶斯滤波
根据贝叶斯公式,𝑘时刻后验概率密度可以表示为:
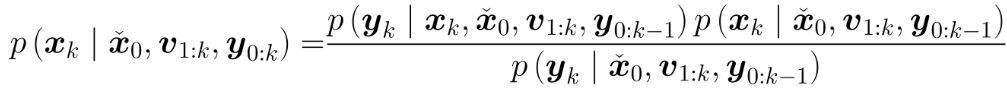
其中:
代表先验概率。表示在获取当前观测数据 y 之前,根据机器人上
一时刻的位姿以及运动信息(imu测量的角速度和加速度等 ),通过运动模型预测当前时刻机器人可能的位姿。这是对机器人状态的一个初步估计。代表似然函数。表示在已知机器人状态
和先验条件的情况下,得到观测数据 y 的概率。例如,当机器人处于某个确定的位姿 x ,且已知部分地图信息时,激光雷达获取到特定距离数据 y 的概率。如果机器人的实际位姿与当前估计的位姿 x 越匹配,那么得到观测数据 y 的可能性就越大。
:后验概率。这是我们最终想要得到的结果,即在已知观测数据 y 和条件信息 v,y 的情况下,机器人状态 x 的概率分布。它结合了先验信息和观测信息,对机器人的状态进行了更准确的估计。
其中,可被看作归一化因子并省略,得到:
![]()
可被忽略的原因之一可能为:
是k时刻的已知条件z(系统已经运行到了k时刻,那么k时刻之前的机器人状态x、内传感器输入、外传感器的观测都已知)。
- 在 SLAM 等实际应用场景中,我们通常更关心的是在给定观测 y 和已知条件 z 下,机器人状态 x 的概率分布情况。
- 在条件贝叶斯公式中, p(y∣z) 表示在已知条件 z 下观测数据 y 出现的概率。从数学角度看,对于特定的观测 y 和已知条件 z , p(y∣z) 是一个固定的值,它不依赖于机器人状态 x 。也就是说,无论 x 取何值,只要 y 和 z 确定, p(y∣z) 都是恒定的。p(y∣z) 作为分母,只影响后验概率的相对大小。
再回到后验概率公式。根据观测方程,只与
相关,则上式可以简写为:
![]()
再利用全概率公式与马尔可夫性可得:
![]()
全概率公式的应用:我们要推断现在的状态
,并根据运动模型
把它们“推演”到现在k时刻。
经过以上化简,最终后验概率可以写为:
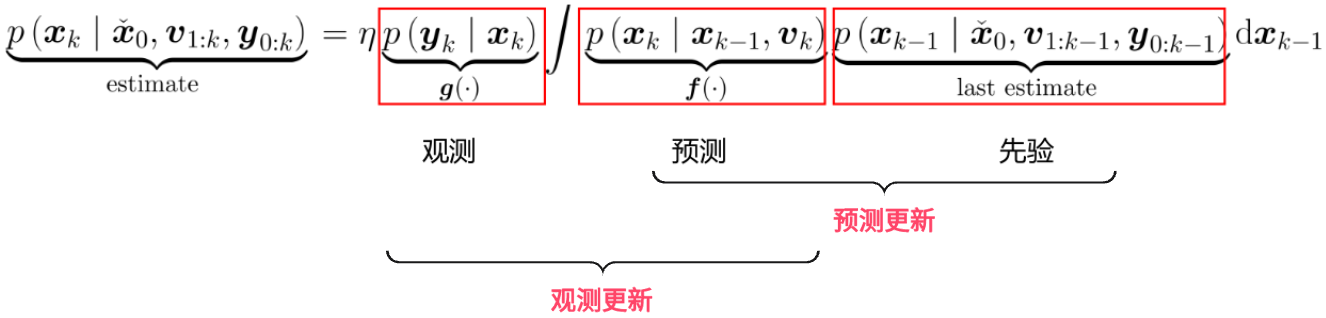
上式完美地体现出滤波的过程:
预测更新:根据当前的先验(即上一时刻的后验)与内传感器的输入,通过运动学解算,递推出当前时刻的状态预测值。
观测更新:根据当前的观测,修正状态量的预测值(纠正imu积分产生的漂移)。
2.3 卡尔曼滤波(KF)推导
再回头看运动方程和观测方程。常规的运动方程和观测方程如下所示:
运动方程:
观测方程:
其中:
:k时刻状态的先验预测值。
:k-1时刻状态的后验值(经过k-1时刻观测修正后的)。
:k时刻imu的测量值,角速度、加速度。
:状态转移函数,描述系统状态如何随时间演变,对应imu积分的过程。
:过程噪音,由imu的测量白噪音(随机游走)和bias随机游走组成,服从高斯分布
。
:过程噪音系数矩阵,描述了过程噪音如何影响当前状态。
:k时刻的观测,如激光雷达的scan to map得到的位姿T。
:观测函数,描述观测的过程。
:观测噪音,描述观测的误差,服从高斯分布
。
:观测噪音系数矩阵,描述了观测噪音如何影响当前观测。
在线性高斯假设下,对于线性系统,运动方程和观测方程可以改写为:
运动方程:
观测方程:
把上一时刻的后验状态写为:
![]()
(1)当前时刻状态的预测值(先验均值)为:
(这个预测值在数学本质上是运动方程的期望均值。由于我们假设过程噪声为零均值白噪声,对其求期望后该项为零。因此,在推算先验状态时噪声项自然消退,而非被忽略;噪声的真实影响将在随后的协方差预测方程中予以体现。)
(2)根据高斯分布的线性变化,此时的先验方差为(仿照1.7节中的推导):
![]()
(3)观测y的期望均值为:
(4)观测y的方差为:
再根据1.6中推导的后验概率分布:
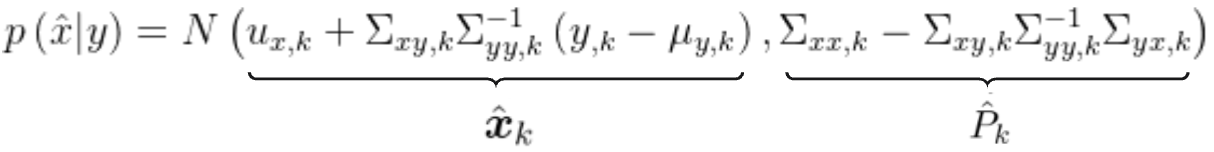
以及1.7中的推导:
令:
![]()
这个K即为卡尔曼增益,则后验均值为:
后验方差为:
![]()
如此,便得到了卡尔曼经典的五个方程:
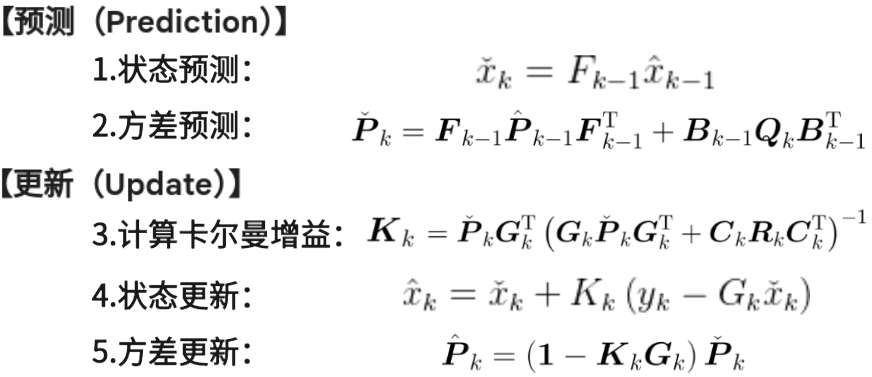
从贝叶斯滤波到卡尔曼滤波:如何让概率落地?
在上一节中,我们看到了贝叶斯滤波的终极公式。它在理论上非常完美(融合了全概率公式与贝叶斯推断),但它是一个包含了无穷积分的连续函数表达。在实际工程和计算机中,我们不可能遍历连续空间去硬算积分(维度灾难)。
为了让这个完美的理论框架能够真正在工程中落地,卡尔曼(Kalman)引入了两个极其伟大的假设:系统是线性的,且噪声服从高斯分布。
高斯分布有一个极其迷人的数学特权:它的线性组合依然是高斯分布。 这直接为贝叶斯滤波的两个步骤带来了“降维打击”般的捷径:
1.化解“积分”噩梦(预测阶段): 贝叶斯滤波中预测阶段那庞大复杂的积分,因为高斯分布的线性映射性质,现在根本不需要积分了!只需要利用我们在 1.7 节 提到的高斯随机变量的线性变换,做简单的矩阵乘法和加法(均值和方差的递推)就能搞定。
2.化解“相乘配方”噩梦(更新阶段): 贝叶斯滤波的更新阶段本质是“似然乘以先验”(即两个高斯分布的概率密度函数相乘)。如果硬算这两个包含指数项的式子并强行凑成一个新的高斯分布,代数过程极其痛苦。此时,我们在 1.6 节 中辛苦推导的联合高斯概率密度函数和舒尔补终于派上了用场!因为状态和观测必定构成联合高斯分布,我们只需利用舒尔补对联合协方差矩阵进行降维分解,就能直接得出相乘后的条件分布
。
核心总结:
卡尔曼滤波推导中使用“联合分布求条件概率”,在数学本质上与贝叶斯公式的“似然乘以先验”是完全等价的。它只是借用了联合高斯的数学特权,巧妙地避开了微积分和繁琐的指数配方。
2.4 扩展卡尔曼滤波(EKF)推导
在标准 KF 中,假设系统是严格线性的(矩阵乘法)。但在真实的 SLAM 或机器人世界里,运动和观测(比如scan to map)几乎全是非线性的。如果把高斯分布强行塞进非线性函数,输出的就不再是高斯分布了,KF 的理论基础就会崩塌。
EKF 的核心思想就是:“既然世界是非线性的,那我就在当前工作点附近把它切成一小段一小段的直线(局部线性化),然后强行套用 KF 的公式。”
(1)定义非线性的真实世界。用非线性函数和
来替换掉 KF 中的常数矩阵F和G:
非线性运动方程:![]()
非线性观测方程:![]()
(2)由于 f 和 g 没法直接算方差,需要使用一阶泰勒展开将它们线性化:
1)对运动方程展开。选择在上一时刻的最佳后验估计值处进行展开,并假设噪声
服从高斯分布
:
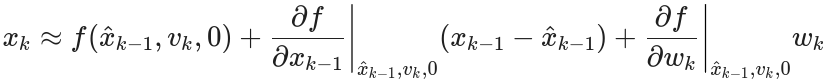
- 为了书写方便,我们定义:
- 无噪声下的名义预测值:
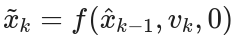
- 状态雅可比矩阵 (Jacobian):
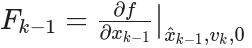
- 噪声雅可比矩阵 (Jacobian):
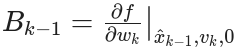
- 无噪声下的名义预测值:
代入后,非线性运动方程被成功“拍扁”成了线性方程:
![]()
2)对观测方程展开。同理,我们在当前时刻的先验预测值处对观测方程进行展开,并假设观测噪声
服从高斯分布
:
- 定义:
- 无噪声下的理论观测值:
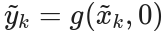
- 观测雅可比矩阵:
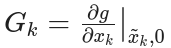
- 观测噪声雅可比矩阵:
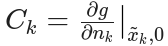
- 无噪声下的理论观测值:
展开后的线性化观测方程为:
![]()
(3)推导均值与方差。
1)预测阶段(先验):
因为,且
的最佳估计就是
,此时
,所以先验均值就是非线性函数的结果:
![]()
方差:
![]()
2)观测阶段(后验):
期望:
![]()
方差:此时的偏差项为:
![]()
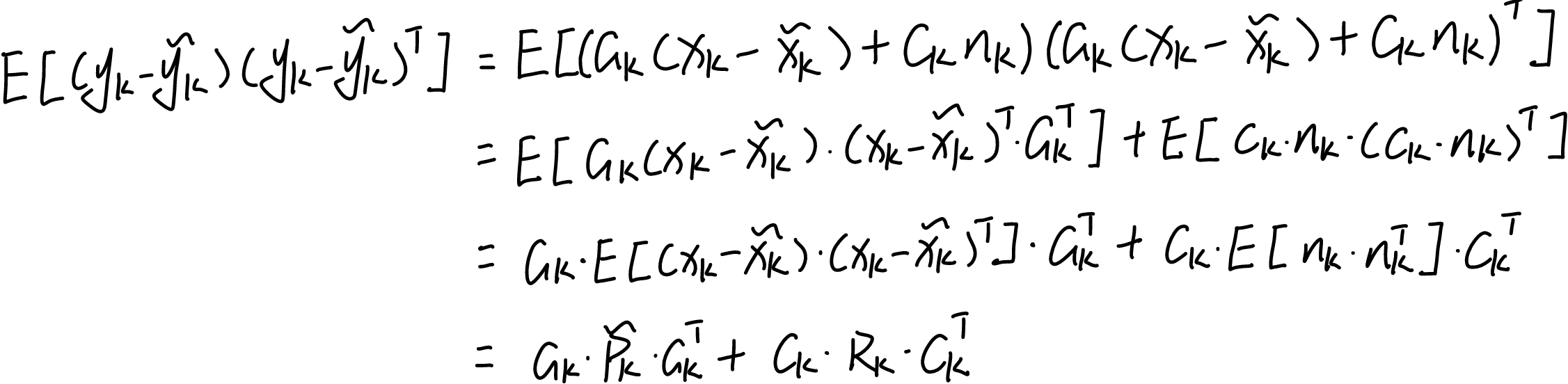
![]()
观测的不确定性
由两部分组成:
1.
(条件方差):由于传感器本身不准带来的误差。
2.
(状态预测误差)
此时,得到了EKF经典的五个方程:
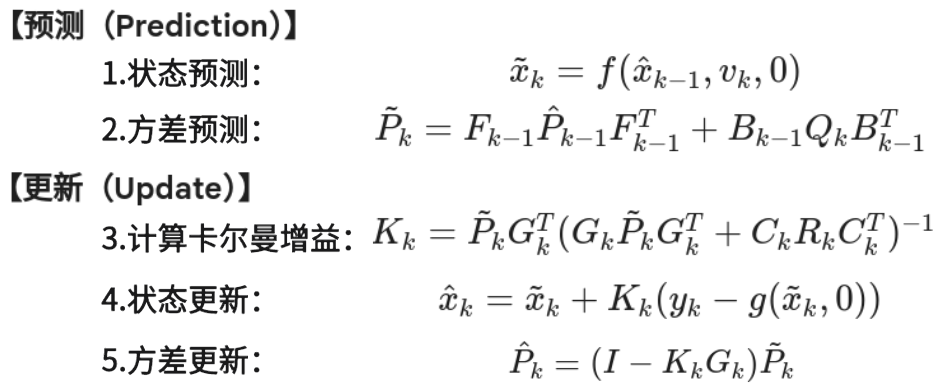
注:状态预测和状态更新时的计算,直接代入非线性方程计算更准。
KF中的矩阵F和G是常数矩阵;而EKF中的F和G是雅可比矩阵。
3.误差状态卡尔曼滤波(ESKF)
3.1 ESKF的引出
EKF 的精度极大地依赖于线性化点的准确性。EKF中会进行两次线性化展开,一是对运动方程展开在上一时刻的最佳后验估计值处进行展开,二是对观测方程在当前时刻的先验预测值
处对观测方程进行展开。如果初始误差太大,或者运动太过剧烈导致非线性极强,被一阶展开无情抛弃的高阶项就会引入巨大的截断误差,导致滤波器发散。
并且当系统引入3D姿态(如四元数q或旋转矩阵R)时,直接使用基于名义状态的滤波模型会遇到致命问题:
- 卡尔曼滤波的假设是状态变量可以进行线性叠加,即状态变量可以加上高斯噪声。
- 但是,四元数必须满足模长为 1(
),旋转矩阵必须是正交的。
- 如果给四元数直接加上一个高斯噪声(
),相加后的结果不再是一个合法的四元数!这就好比你让一个只能在球面上移动的点,加上了一个直线向量,它直接飞出了球面。
为了解决这两大痛点,误差状态卡尔曼滤波(ESKF)应运而生。它放弃了直接估计高度非线性的系统“名义状态”,转而采用“分而治之”的思想:把非线性的大范围运动交给名义状态去积分,而滤波器只负责估计帧间微小的、线性的不确定性噪声(误差状态)。
对于非线性系统,虽然系统的大范围运动(名义状态)是非线性的,但只要传感器的更新频率足够高,帧间累积的误差往往非常微小。只要及时进行状态清零与补偿,误差状态就会始终被限制在极小的范围内。这使得我们可以在工作点附近进行局部线性化,认为误差状态的传播是一个高精度的线性马尔可夫过程。
此时,对于旋转,不直接估计四元数,而是估计一个三维的误差角。这个三维向量是在切空间(李代数空间)中的,它没有任何长度或正交性约束,完美符合高斯分布的假设。在更新时,利用指数映射或一阶近似
将误差“乘”回名义姿态中,天然保证了旋转的合法性。
每次观测更新后,ESKF都会把误差注入名义状态,并将误差状态清零。这意味着我们的误差状态永远是一个围绕着 0 的无穷小量。在 0 附近对误差模型进行线性化,截断误差微乎其微,使得滤波器的表现更接近理论最优。
3.2 ESKF的具体形式
ESKF属于KF,所以运动方程和观测方程沿用线性表示:
运动方程:
观测方程:
此时,来看两个方程中每个量的具体形式:
3.2.1 运动方程
运动方程:
设当前待估计的状态为,分别为位置误差、姿态误差(用旋转向量表示)、速度误差、加速度计零偏的误差、陀螺仪零偏的误差。
过程噪音为,分别加速度计的测量白噪音(随机游走)、陀螺仪的测量白噪音、加速度计bias随机游走、陀螺仪bias随机游走。
根据上一篇笔记《惯性导航解算及误差分析》中推导得到连续时间下的误差微分方程:
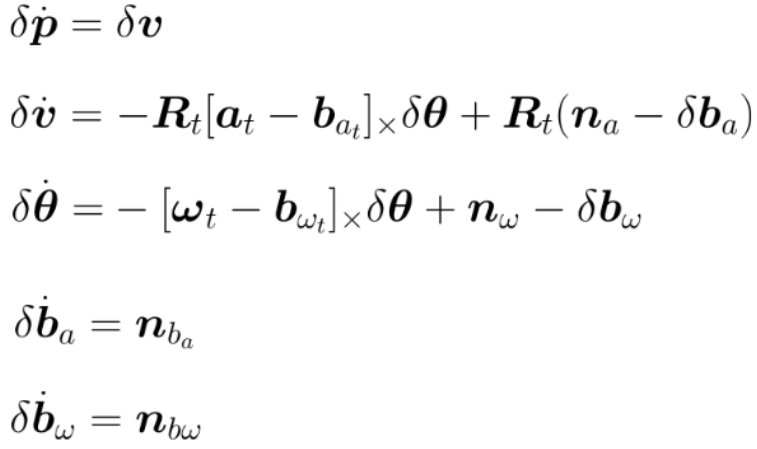
得:
其中:
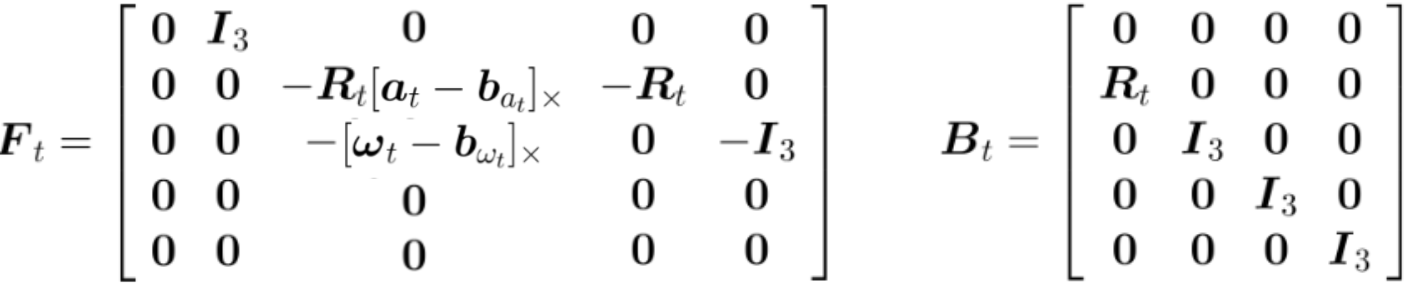
将连续微分方程变成离散化的状态递推公式:

对于齐次部分(系统本身)的矩阵指数进行一阶泰勒展开,得:
![]()
对于非齐次部分(噪音)简化得到:
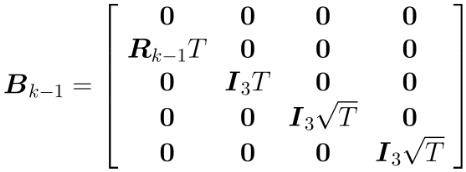
其中,𝑇为滤波周期,即两帧imu数据间的时间差。注:关于的离散化形式,不同资料有差异,但对实际调试影响不大。
3.2.2 观测方程
观测方程:
假设此时以lidar的scan to map得到的位姿T作为观测量,则观测量包含位置、失准角,即:
![]()
观测噪音![]() 。 此时有:
。 此时有:
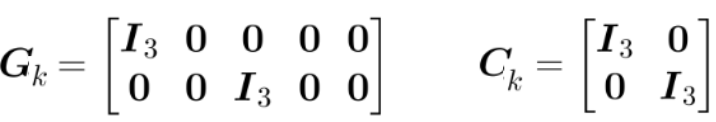
G为观测雅可比矩阵,C为观测噪音雅可比矩阵。
需要注意的是,观测量y的值并不由观测方程计算得到,观测方程主要用于问题建模,进行观测均值和方差的推导。
1)观测量中的计算过程为:
![]()
其中,为imu积分得到的预测值,
为lidar位姿T中的位置。
2)的计算需要先计算旋转误差矩阵:
![]()
再进行对数映射得到失准角(旋转误差向量):
或者可以取巧,由于预测值与观测值之间的关系为:
![]()
所以:
![]()
将以上各变量,带入kalman滤波的五个方程,即可构建完整的滤波器更新流程。
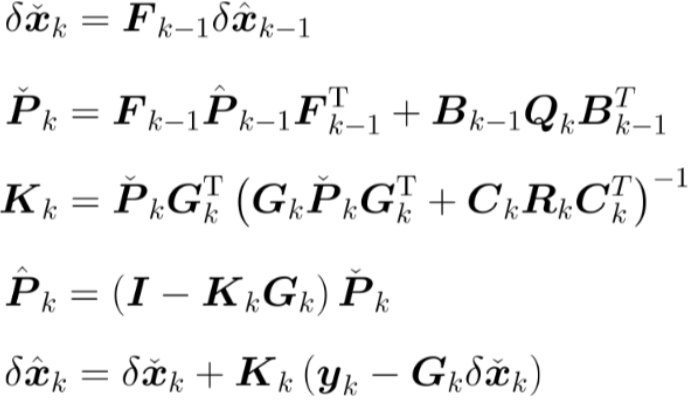
3.3 ESKF的使用
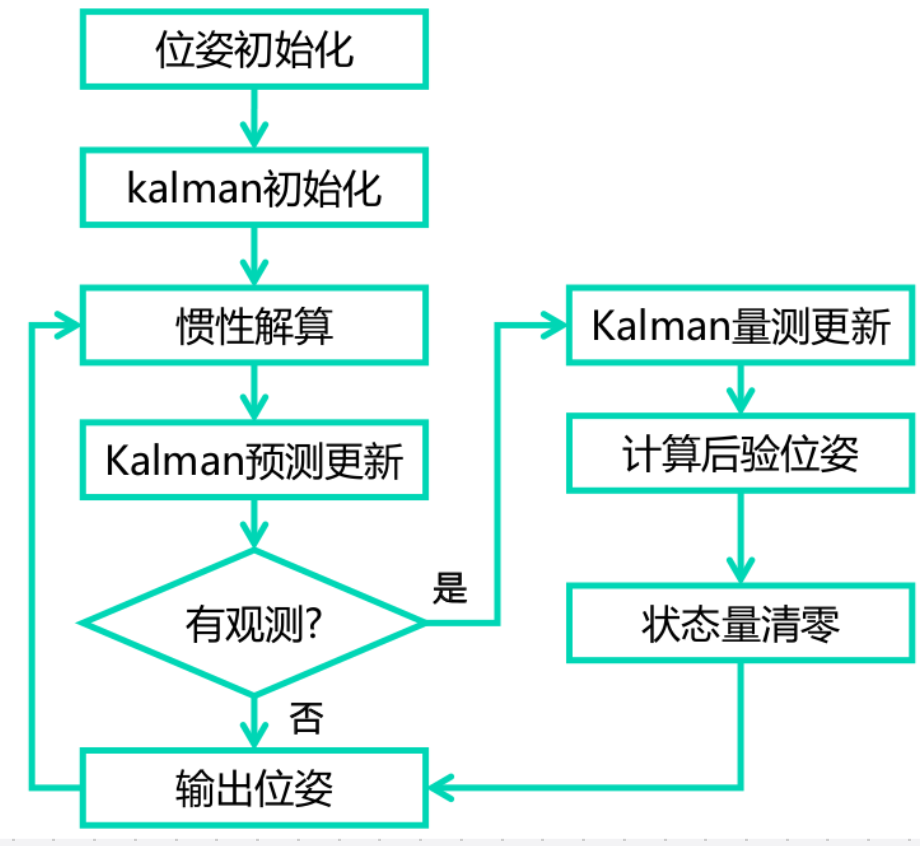
(1)位姿初始化
在点云地图中实现初始定位,并给以下变量赋值:

(2)Kalman 初始化
![]()
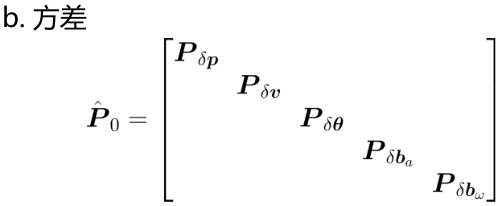
初始方差理论上可设置为各变量噪声的平方,实际中一般故意设置大一些,这样可加快收敛速度。
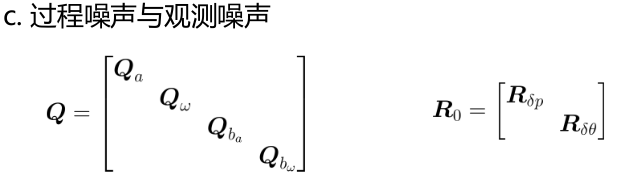
过程噪声与观测噪声一般在 kalman 迭代过程中保持不变。
(3)惯性解算
1)姿态解算:
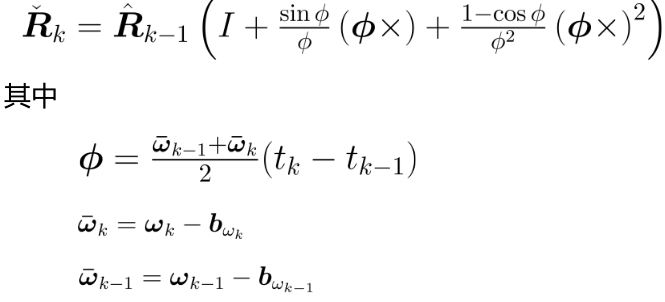
该位姿属于先验预测位姿。
2)速度解算:
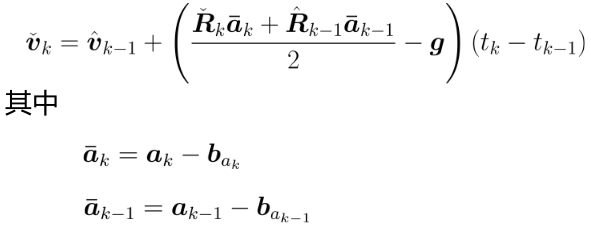
3)位置解算:
![]()
(4)Kalman 预测更新
执行kalman五个步骤中的前两步,即:
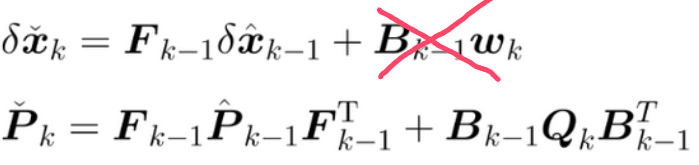
(由于我们假设过程噪声为零均值白噪声,对其求期望后噪声项为零。因此,在推算先验状态时噪声项自然消退,而非被忽略;噪声的真实影响将在随后的协方差预测方程中予以体现。)
这里需要实时根据公式计算![]() 和
和![]() 。
。
(5)无观测时后验更新
无观测时,不需要执行kalman剩下的三个步骤,后验等于先验,即:
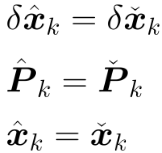
(6)有观测时的量测更新
执行kalman滤波后面的三个步骤,得到后验状态量:
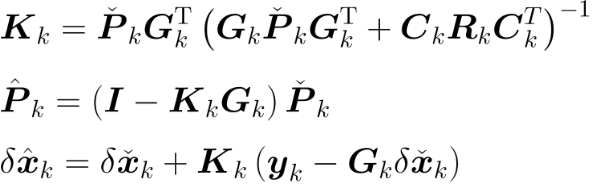
(7)有观测时计算后验位姿
真值 = 名义状态 - 误差状态
根据后验状态量,更新后验位姿:
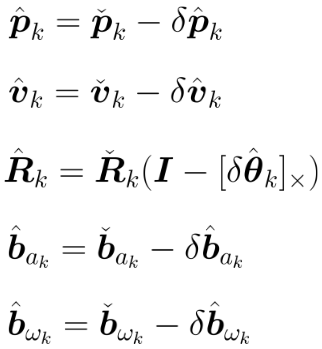
(将误差从名义状态中剔除)
(8)有观测时状态量清零
状态量已经用来补偿,因此需要清零:
![]()
后验方差保持不变。(状态的不确定性保持不变)
(9)输出位姿
把后验位姿输出给其他模块使用。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)