生成任务Bart
任务分类:
| 任务种类 | 输入变量 | 输出变量 | |
| 任务1 | 回归 | 向量 | 值 |
| 任务2 | 图像分类 | 图片 | 分类结果(标签) |
| 任务3 | 文字序列分类 | 文字序列 | 分类结果(好or坏 |
| 任务4 | 生成任务 | 文字序列 | 文字序列 |
一.主要模型架构
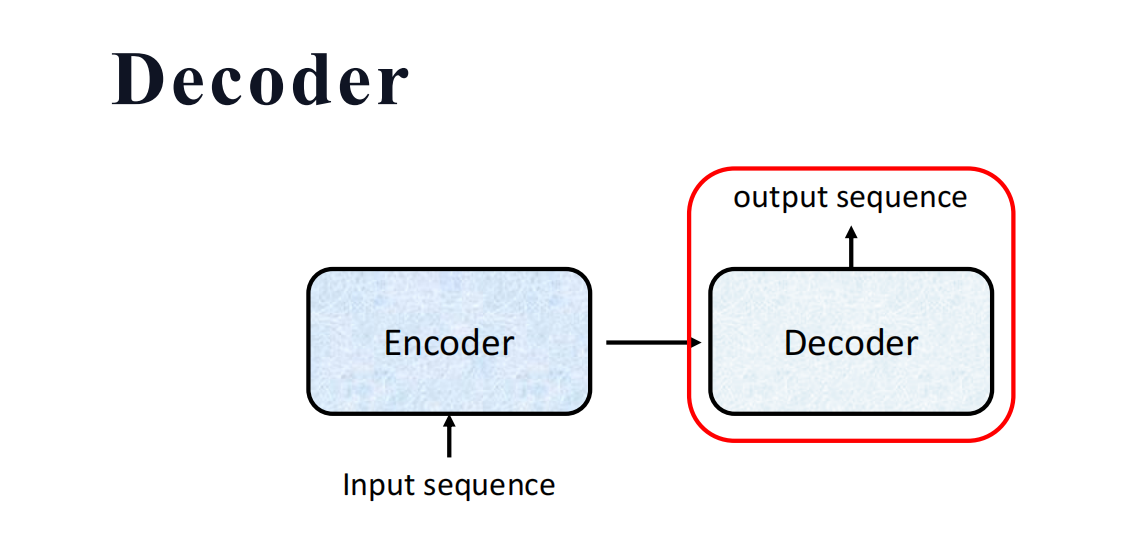
encoder是负责提取特征,然后把这些特征输入到decoder中,通过decoder对此特征来进行输出成文本序列。 而decoder的output的一堆字,所以本质还是一个分类任务(在词典里面词中选出合适的词去输出)
二.自回归(Autoregressive)
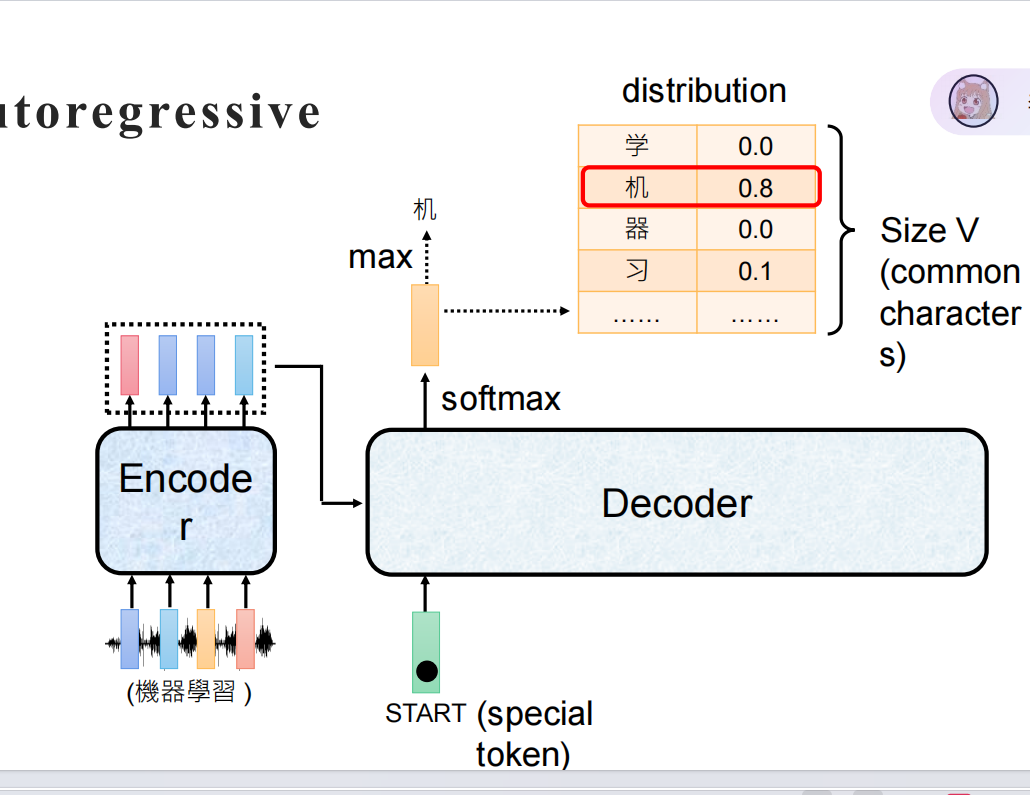
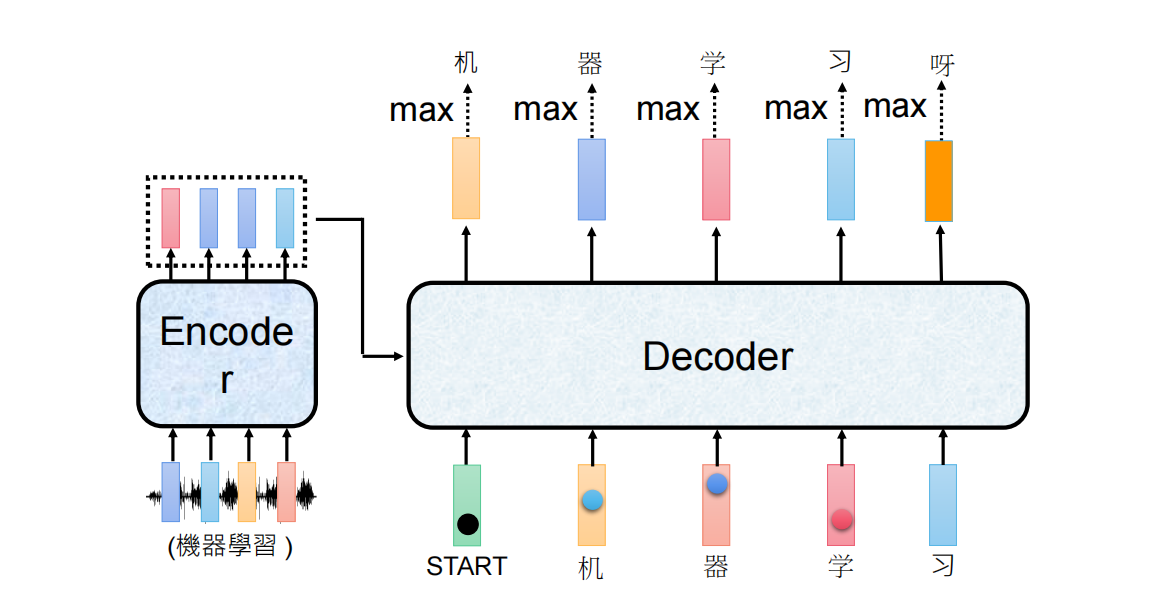
原理:用前面已经生成的内容,预测下一个内容,然后把预测出来的内容加进去,继续预测下一个,循环往复。
此时的问题有两个:
1.一步错,步步错(因为前面的一个出错,就会导致后面的也会跟着出错)
2.只能串行输出,就会导致模型训练太慢
start (special token,特殊标记) 是深度学习生成任务中用来触发模型开始生成内容的核心特殊符号。是人为定义的、不属于普通词汇 / 像素 / 音符的特殊符号,核心作用是: 告诉模型:“现在可以开始生成目标序列了”; 作为生成过程的第一个输入,让模型有初始的 “启动信号”。同时,里面还会附带encoder所产生的一些特征信息,以供decoder做训练使用。
生成有了,但生成多长就成了问题
模型本身不知道要生成多长,它是靠 特殊标记 + 规则限制 来决定什么时候停止。
比如,有<end>这个token,
当模型训练时,会给每个标签句子的末尾(结束时)打上一个<END>标志,表明此句子已经生成结束。
这样训练后模型的时候就知道什么时候应该终止。
而在模型生成时,模型一旦输出<END>这个Token后,就立即停止生成。
三.Masked Self-attention(掩码自注意力 )
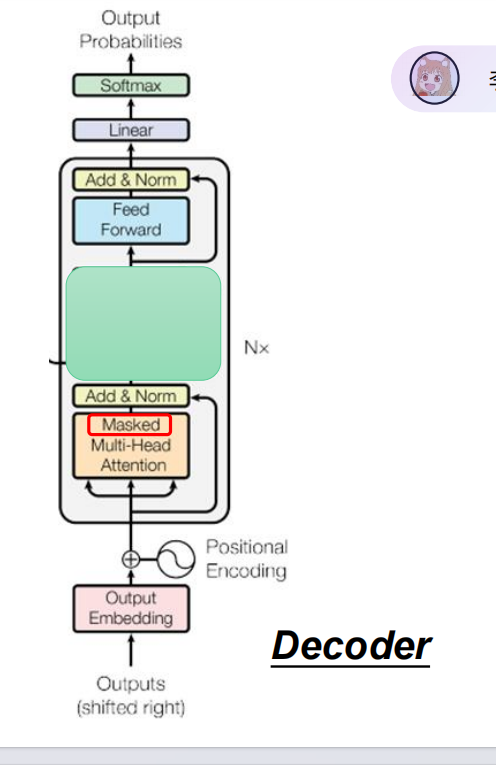
Masked Self-attention(掩码自注意力)是自注意力机制的「带约束版本」,核心是通过掩码(Mask) 屏蔽掉注意力计算中「不该被看到的位置」,让模型只能关注允许的上下文 —— 这也是自回归模型(如 GPT)能实现「单向生成」的核心技术。
为什么需要「掩码」?
普通的 Self-attention(自注意力)会让每个位置的 Token「看到整个序列的所有 Token」,比如计算第 3 个 Token 的注意力时,能关注第 1、2、3、4、5… 个 Token。
但在自回归生成任务中(比如逐 Token 写句子),模型只能用「前面的内容」预测「后面的内容」,绝对不能提前看到「还没生成的后面的内容」(相当于 “作弊”)。
掩码自注意力的作用就是:把「未来的位置」“遮住”,让模型只能看到「过去 / 当前」的位置。
本质在于,为了并行处理训练的数据,就采取把label同时输入进模型中训练,这样模型的每个字的输出只会与label有关,且label不会出错,就不会有一步错,步步错的后果。并且,label的输入是不用依赖前面的数据输出的,所以只需要同时使用label输出本字即可。
 掩盖方式:用一个下三角矩阵,把本词后面的label数据给“掩盖”住,不让本次输出的字因看到后面的字而获得“作弊”的信息。
掩盖方式:用一个下三角矩阵,把本词后面的label数据给“掩盖”住,不让本次输出的字因看到后面的字而获得“作弊”的信息。

其中 mask 矩阵中,被遮挡的位置填 -∞,可关注的位置填 0;经过 softmax 后,-∞ 会变成 0,相当于完全忽略这些位置。
注意:这个机制只会在模型训练的时候用,因为具有label的输入(本身就是为了mask数据的标签的),而由于验证的时候,是没有label的,所以不能mask,只能用自回归的方式进行生成。
四、生成任务该如何训练?
生成任务的主要特点是训练时和验证时动作基本不同:
训练时:会给模型输入X和label,模型是根据X给到encoder去提取特征,然后把此特征给到decoder里面,label(真实值)也是给到decoder里面,这样decoder就可以通过label并行的训练,且不会出现一步错,步步错的情况。
验证时:模型只有X,所以只能把X输入到encoder里面,让encoder输出一个特征START后给到decoder中,而decoder也只能通过这一个向量,通过自回归的方式串行的输出结果。
具体流程
一.预处理数据
要把句子转化为模型能读懂的Token eg 我爱你 -> <start>我 爱 你 <end>
二.模型前向计算
让模型经过Masked Self-attention 的处理,让经过训练后的模型来预测mask后的token
同时,模型还有训练下一个字应该输出什么字的概率训练。(比如:上一个字是“苹”,而下一个字模型大致会预测“果”字)
三.计算交叉熵损失
1. 单个位置的交叉熵
对第 i 个位置:
- 模型输出:概率分布
p_i(向量,长度 = 词表大小) - 真实标签:真实 token
y_i(one-hot 向量)
交叉熵:Hi=−log(pi[yi])
意思:模型对正确答案的置信度越高,loss 越小。
2. 整个句子的平均损失
把所有位置的 loss 加起来,再平均:Loss=T1∑i=1T−log(pi[yi])
- T:序列长度
- 这就是 自回归语言模型的标准训练目标
四.梯度回传,更新参数
- 计算损失对模型所有参数的梯度;
- 用优化器(比如 Adam)沿着梯度下降的方向更新参数,让下一次预测更准;
Beam Search算法(束搜索)
算法的目的是根据具体的情况,看模型是用“贪婪算法”还是“全局搜索算法”。
贪婪算法的代价小,但效果可能不好;全局搜索算法代价大,但效果确定是最好的。
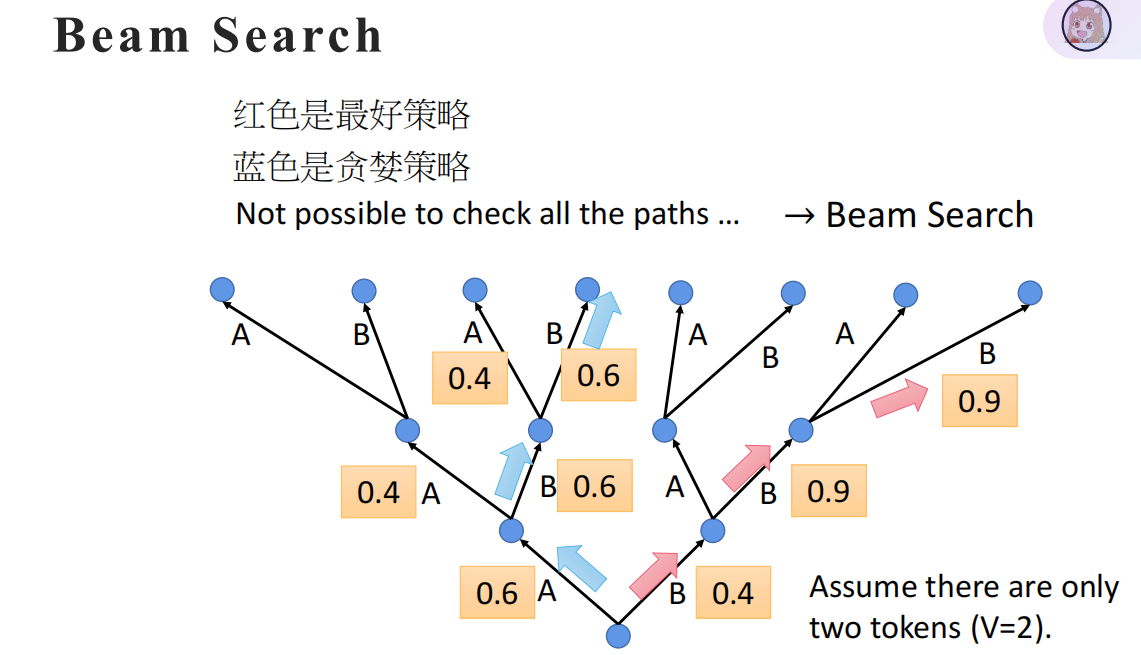
- 束宽 k 的选择:k 越大,生成质量越高,但计算 / 内存成本越高(常用 k=5~10,k=1 等价于贪心搜索,k=V 等价于暴力枚举);
- 重复 Token 处理:可加入 “惩罚机制”,避免生成重复内容(比如 “我我我爱吃火锅”);
- 与自回归 + Mask 的配合:Beam Search 每一步的候选序列,都基于 Masked Self-attention 的输出概率计算,保证只依赖左边已生成内容。
五.Cross-attention
与self-attention不同的地方。
Cross Attention:Q 来自一个地方,K、V 来自另一个地方。
结构永远是:
- Q = Query(来自解码器 / 生成端)
- K = Key,V = Value(来自编码器 / 源端)
这个就是连接encoder和decoder的方式,通过cross-attention帮助decoder在encoder提取的特征中,挑选出注意力大的那个向量输出到decoder中做生成任务。
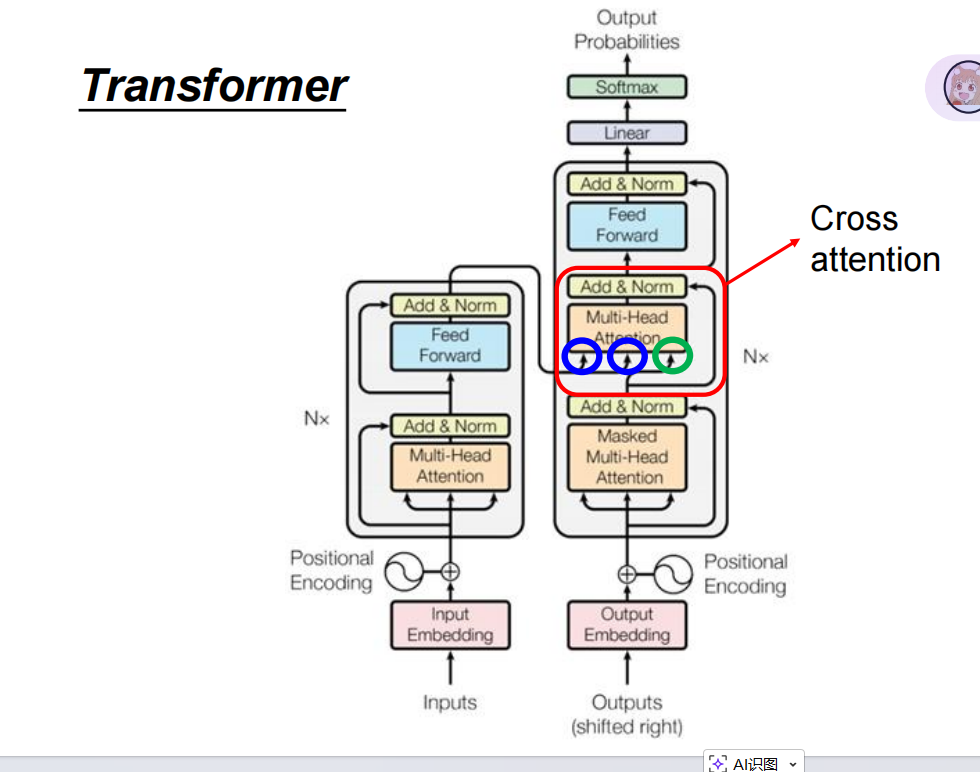
根据模型,总结基本流程:
encoder:
1.先经过embedding分词(词嵌入,分为id,有效字,判断是否是一句),每一个字都是token
2.让每一个token经过self-attention层(句子中字的关系)和Forawed层(全连接,改变维度)
3.重复1,2多次。最后提出特征,传到decoder里面。
decoder:
1.与encoder相同,同时在句首加一个<start>,表示句子开始的token。
2.Mask self-attention(保证只能看前面) <让模型预测mask的值>。
3.Cross-Attention 看上下文字与字之间的关系。
4.Forward 全连接,预测下一个token
5.循环2.3.4.直到遇到<end>才停止。
实战
BART 核心特点
1. 模型结构
-
Encoder + Decoder 完整 Transformer 结构
- Encoder:双向注意力(类似 BERT)
- Decoder:单向自回归注意力(类似 GPT)→ 所以它是 兼具理解与生成的 “全能型” 模型
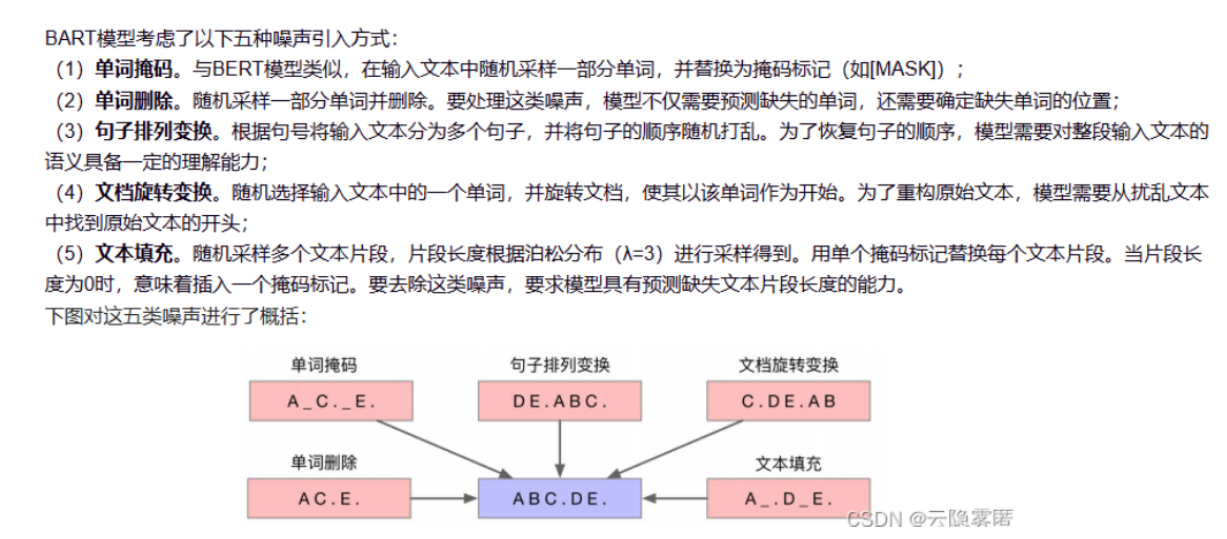
2. 预训练任务:去噪自编码器(Denoising Autoencoder)
给输入加各种噪声,让模型还原干净句子:
- Token 掩码
- Token 删除
- 句子重排
- 文本填充
- 旋转句子
本质是Bart的性能是适合“摘要”任务,性能优于transformer和GPT模型。
BART 是我们项目的 “最优解”
综合来看,我们选择 BART 的核心原因是:
- 有大规模预训练权重,能快速适配医疗场景,降低训练成本;
- 编码器 - 解码器架构,完美匹配 “CT 编码→诊断结论” 的条件生成任务;
- 生成可控性更强,更适合医疗这种对准确性要求极高的场景
项目介绍

CT医疗数据是关于病人的私人信息,所以只能用脱敏数据来表示(相当于是一个数组,用数组下标来代替字)
输入:脱敏后的数字编码序列 ,表示CT所展现的事实
输出:医生针对CT给出的现象,给出一定的治疗方法
搭配文件配置
数据预处理
将数据划分为训练集,验证集和测试集

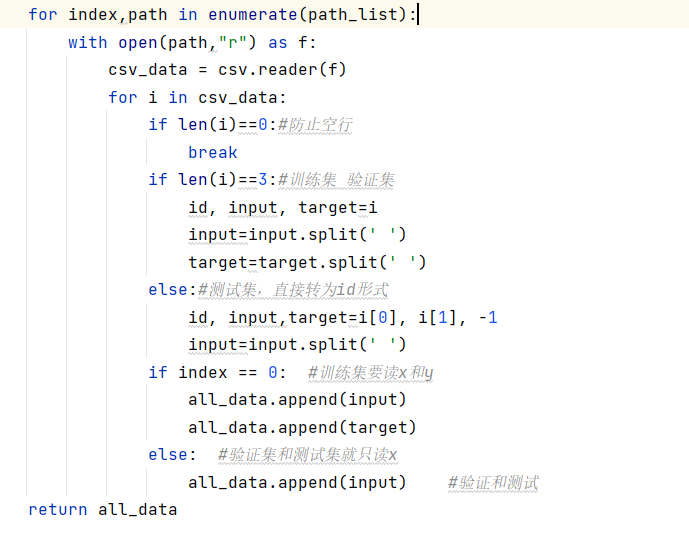
读CVS文件,一般用Pamdas函数来实现。通过手动划分的方式,把训练集划分为训练集和验证集。
由于某一些词不在原先的词表里面,所以要通过某些方法修改词表:
1.Tokenizer(最常用)
- 使用目标领域 / 目标语言数据重新训练
- BPE(GPT、GPT2、BART)
- WordPiece(BERT)
- Unigram(T5、mBART)
- 重新确定:哪些是完整 token,哪些要拆分。
2. 扩充词表(增量添加)
保留原有词表,只加新 token:
- 生僻字
- 专业术语
- 特殊符号优点:不用大改模型,快、稳定。
3. 裁剪词表(删减低频词)
删掉出现次数极少、几乎不用的 token:
- 减少内存
- 加速线性层 /softmax 计算常用于移动端、轻量模型。
4. 跨语言词表统一 / 映射
多语言模型(mBART、mT5)中:
- 统一不同语言的 token 空间
- 或做词表映射,提升迁移能力
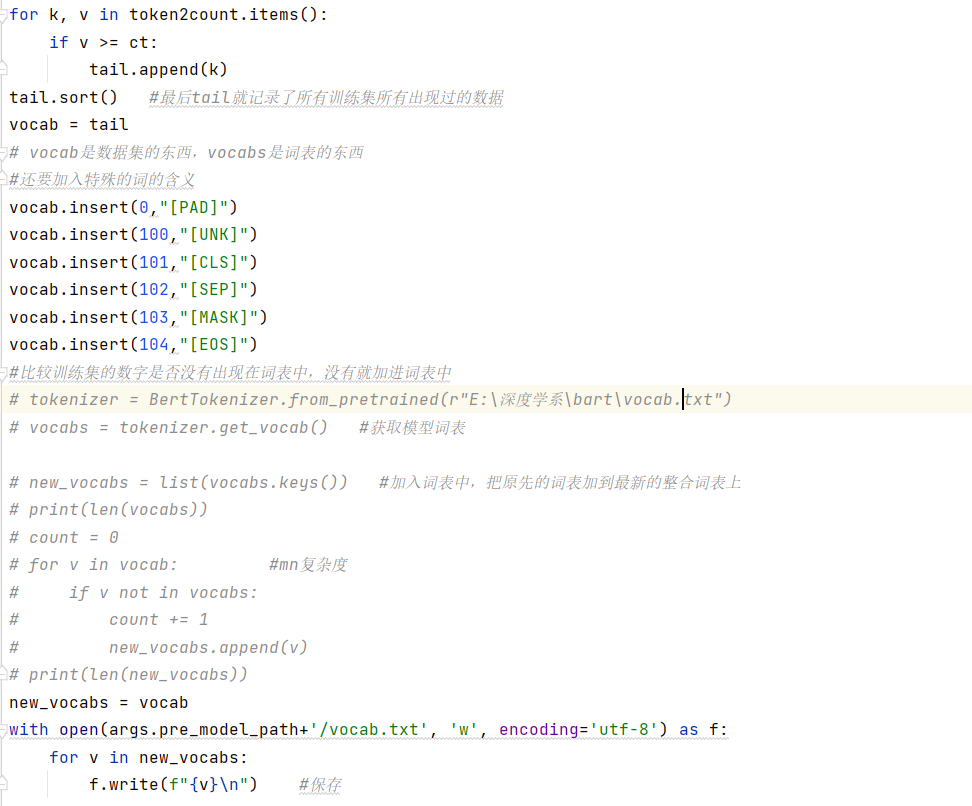
数据加载函数

整合CSV数据,为MLM预训练做预料的准备。
基础预训练数据集

为 “条件生成预训练” 提供格式化数据(输入 + 输出序列)
MLM 预训练数据集 MLM_Data
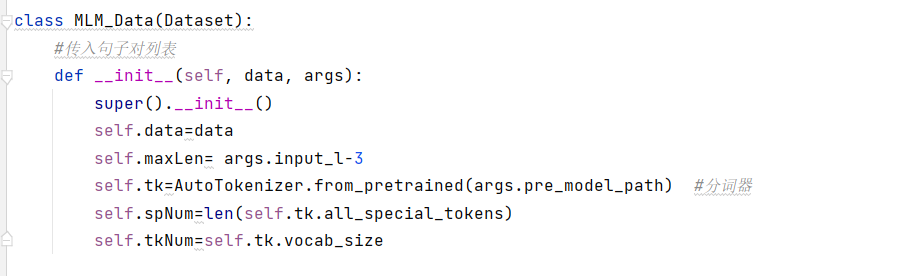
实现 MLM(掩码语言模型)预训练的数据集,是模型学习医疗文本语义的核心
模型训练

MLM的训练开始‘;
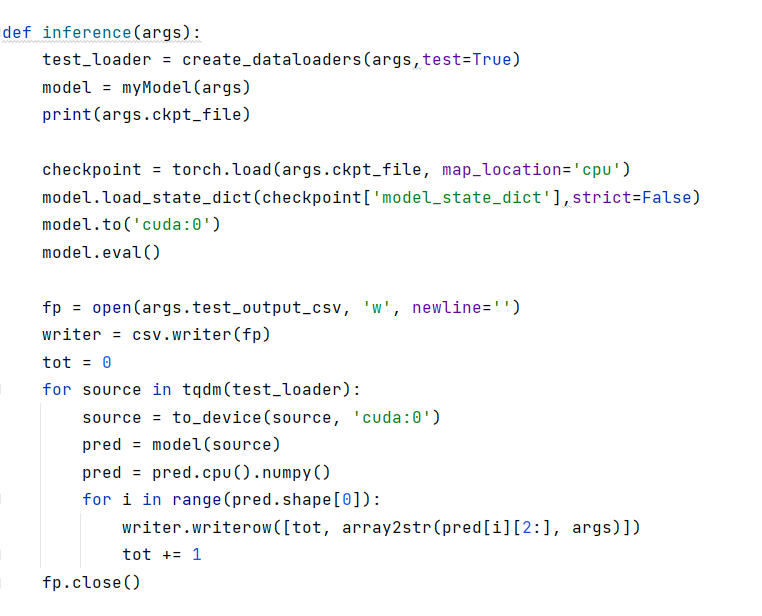
把模型放到GPU上
模型评估

通过(CE)交叉熵损失做模型评价。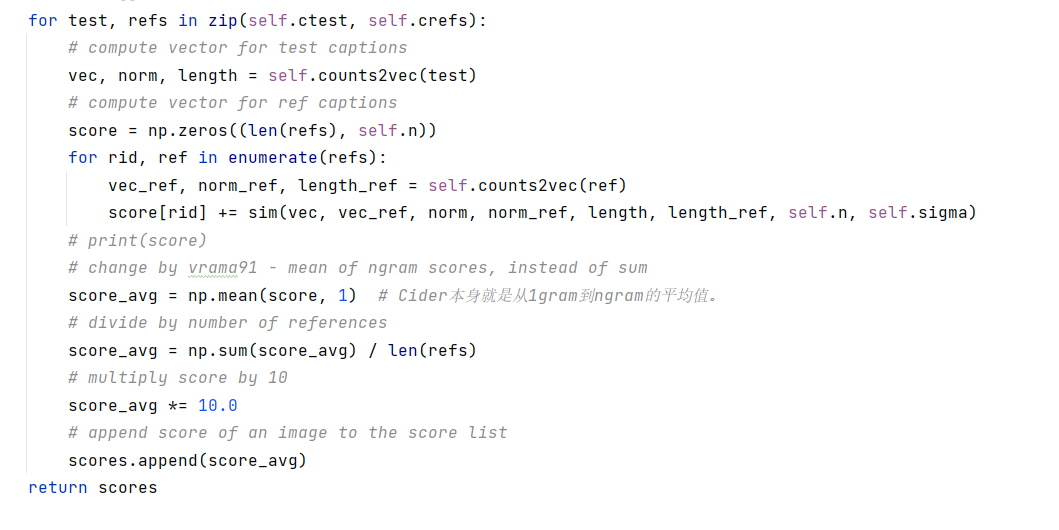
通过Cider-D(文本生成质量评价指标)对生成文本进行评估。
CIDEr-D与gram的联系与区别:
| 对比维度 | 1-gram | n-gram(n≥2) | CIDEr-D |
|---|---|---|---|
| 本质定位 | 文本切分单元(n=1) | 文本切分单元(n≥2) | 完整的文本生成评价指标 |
| 上下文依赖 | 无,仅单个词 | 有,依赖前 n-1 个词 | 综合 1-gram 到 4-gram(常用)的匹配 |
| 权重机制 | 无,仅计数 | 无,仅计数 | 引入TF-IDF 加权,区分 n-gram 重要性 |
| 惩罚机制 | 无 | 无 | 含高斯长度惩罚(惩罚句长差异)、n-gram 计数截断(惩罚重复高频词) |
| 计算目标 | 词频统计、概率计算 | 词序列概率、局部匹配 | 生成描述与参考描述的整体相似度评分 |
| 应用场景 | 基础词频分析、简单匹配 | 语言模型、文本匹配 | 图像 / 视频描述生成的自动评价 |
n-gram:文本序列的基本切分单元,将句子按连续 n 个词 / 字切分,用于统计词序与共现概率

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)