肥胖风险数据预测分析
一、数据集说明
数据集:
通过网盘分享的文件:obesity_level.csv
链接: https://pan.baidu.com/s/1YjcjbXW3UPeWP5x99at6kQ 提取码: vdzc
| 字段 | 含义 | 说明 |
| id | 编号 | 样本唯一标识 |
| Gender | 性别 | Female/Male |
| Age | 年龄 | 数值(含小数) |
| Height | 身高 | 米 (m) |
| Weight | 体重 | 千克 (kg) |
| family_history_with_overweight | 家族肥胖史 |
1/0, 家人是否有超重肥胖 |
| FAVC | 常吃高热量食物 |
1/0, 经常吃高热量零食快餐 |
| FCVC | 蔬菜食用频率 |
1–3, 越高越常吃蔬菜 |
| NCP | 每日正餐数量 |
1-3, 每天吃几顿正餐 |
| CAEC | 两餐间零食习惯 |
Sometimes/ Frequently/ Always/ 0 |
| SMOKE | 吸烟 | 1/0 |
| CH2O | 每日饮水量 |
1–3, 越高喝水越多 |
| SCC | 监控卡路里摄入 |
1/0, 是否关注热量 |
| FAF | 身体活动频率 |
0–3, 越高运动越多 |
| TUE | 电子产品使用时间 |
0–2, 越高久坐时间越长 |
| CALC | 饮酒频率 |
Sometimes/ Frequently/ Always/ 0 |
| MTRANS | 交通方式 |
Public_Transportation/ Automobile/ Walking |
| 0be1dad | 肥胖等级 |
体重不足
正常体重
超重 I 级
超重 II 级
肥胖 I 级
肥胖 II 级
肥胖 III 级 |
二、数据预处理
(一)加载数据
导入所需要的包,如果没有先用pip下载(建议直接下一个anaconda)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.feature_selection import SelectKBest, f_classif
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
plt.rcParams['font.sans-serif'] = ['SimHei', 'WenQuanYi Micro Hei', 'Heiti TC']
plt.rcParams['axes.unicode_minus'] = False加载CSV原文件
# 1. 加载数据
df = pd.read_csv("obesity_level.csv")
print(" 数据加载完成,列名如下:")
print(df.columns.tolist())
print("\n数据前5行预览:")
print(df.head())简单查看数据基本情况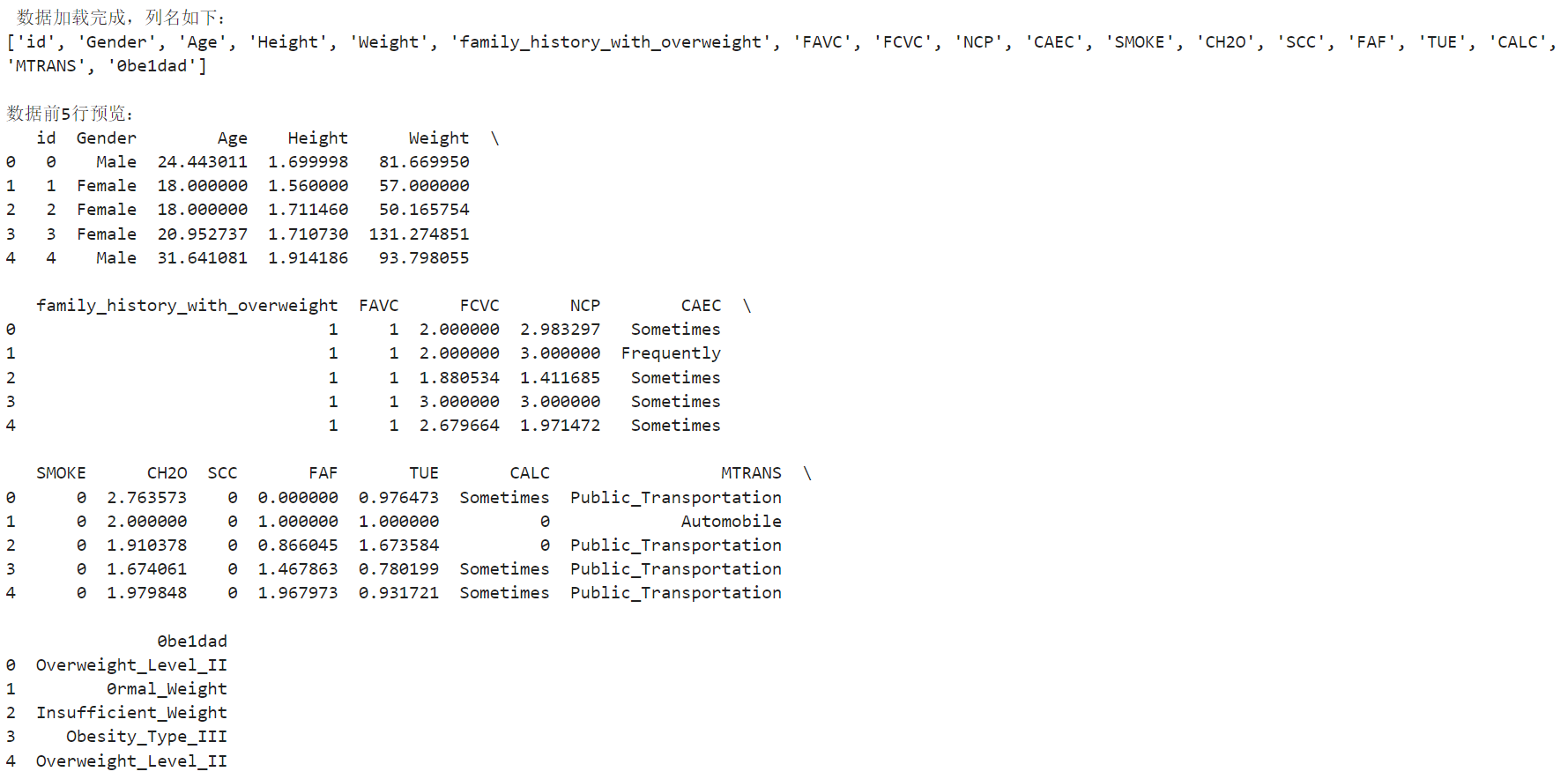
(二)数据预处理
1.缺失值处理
print("\n缺失值统计")
print(df.isnull().sum())
df = df.dropna()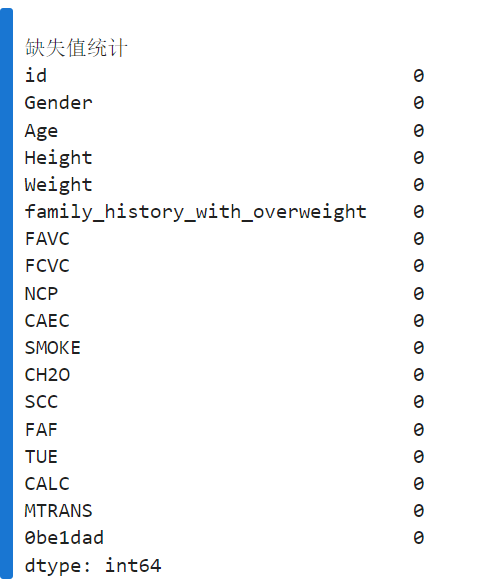
由查询结果可知,数据很规整,没有缺失值,如有缺失值则运行.dropna()语句,删除缺失值。
2.异常值处理
数据中身高(Height字段)设范围为1.2-2.2米,该范围之外视为异常值
数据中体重(Weight字段)设范围为30-200kg,该范围之外视为异常值
df = df[(df["Height"] >= 1.2) & (df["Height"] <= 2.2)]
df = df[(df["Weight"] >= 30) & (df["Weight"] <= 200)]3.二分类变量处理
将 "Gender", "family_history_with_overweight", "FAVC", "SMOKE" 这四列只有两个取值的分类列,转换成 0/1 数值(其中有些字段的值已是)
binary_cols = ["Gender", "family_history_with_overweight", "FAVC", "SMOKE"]
le = LabelEncoder()
for col in binary_cols:
df[col] = le.fit_transform(df[col])
df[binary_cols].head()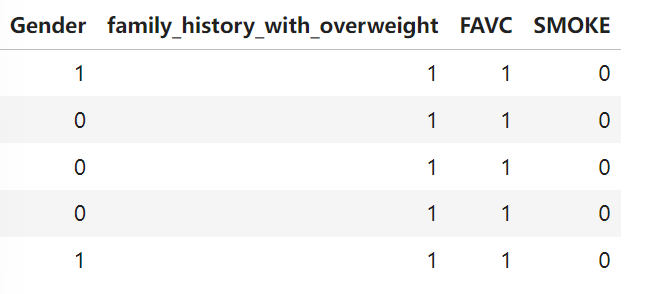
4.多分类变量 OneHot 编码处理
把 无序多分类特征 转成 独热编码(0/1 矩阵),避免模型误以为类别有大小关系。
CAEC:饮食习惯(多类别)SCC:监控卡路里摄入CALC:酒精摄入频率MTRANS:出行方式
multi_cols = ["CAEC", "SCC", "CALC", "MTRANS"]
df = pd.get_dummies(df, columns=multi_cols, drop_first=True)
new_columns = [col for col in df.columns if any(start in col for start in multi_cols)]
print("OneHot 编码后新增的列:")
print(new_columns)
5.目标变量编码处理
把文本 / 字符串类型的目标标签(比如 Insufficient_Weight, Normal_Weight, Obesity 等)转换成 0,1,2,3... 连续整数,这是分类模型(决策树、随机森林、XGBoost、逻辑回归等)强制要求
target_col = "0be1dad"
le_target = LabelEncoder()
df[target_col] = le_target.fit_transform(df[target_col])
print(f"\n 目标列已编码,类别映射关系:")
print(dict(zip(le_target.classes_, le_target.transform(le_target.classes_))))
6.数值型特征标准化
StandardScaler 标准化:把所有不同量级的数值(年龄、身高、体重、分数等)压缩到 均值为 0,标准差为 1 的统一范围。
为什么必须做?
- Age(年龄):范围 10~60
- Height(身高):范围 1.5~2.0
- Weight(体重):范围 40~150如果不标准化,模型会偏向数值大的特征(体重、年龄),忽略小数值特征。
num_cols = ["Age", "Height", "Weight", "FCVC", "NCP", "CH2O", "FAF", "TUE"]
scaler = StandardScaler()
df[num_cols] = scaler.fit_transform(df[num_cols])
print(f"\n 预处理完成,数据形状:{df.shape}")
三、数据特征提取
特征矩阵 X:去掉 id 和目标列,只保留所有输入特征
X:所有用于预测的特征(编码后的分类特征 + 标准化后的数值特征
y:需要被预测的目标标签(肥胖等级)
删除 id:id 是无意义序号,必须删掉,否则会严重干扰模型
删除目标列 0be1dad:不能把答案放进特征里!
X = df.drop(["id", "0be1dad"], axis=1)
y = df["0be1dad"]单变量特征重要性(ANOVA F 值)
f_classif:使用 ANOVA F 检验,衡量每个特征与目标标签的线性相关性强弱- 分数越高 → 特征对分类越重要
SelectKBest(k=10):自动选出得分最高的前 10 个特征X_selected:只保留 10 个最优特征的新特征矩阵scores:所有特征的重要性排序
selector = SelectKBest(score_func=f_classif, k=10)
X_selected = selector.fit_transform(X, y)
scores = pd.Series(selector.scores_, index=X.columns).sort_values(ascending=False)
print(scores.head(20))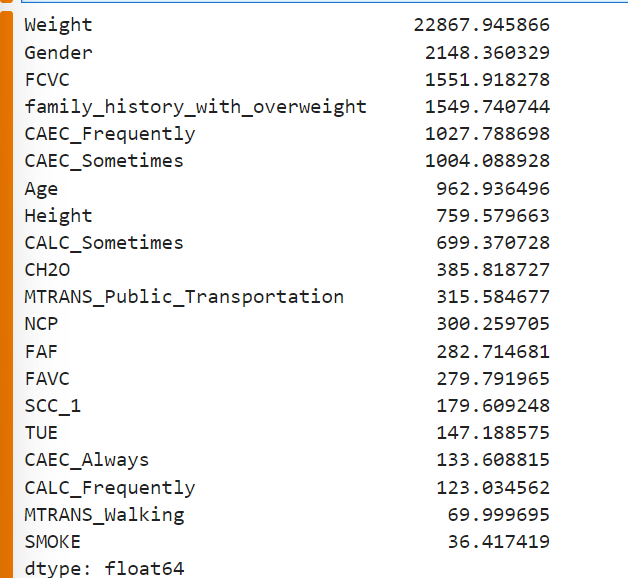
可视化TOP10特征重要性
plt.figure(figsize=(10, 6))
scores.head(10).plot(kind="barh", color="skyblue")
plt.title("Top 10 影响肥胖等级的关键特征(F值越高影响越强)")
plt.xlabel("F值")
plt.gca().invert_yaxis()
plt.show()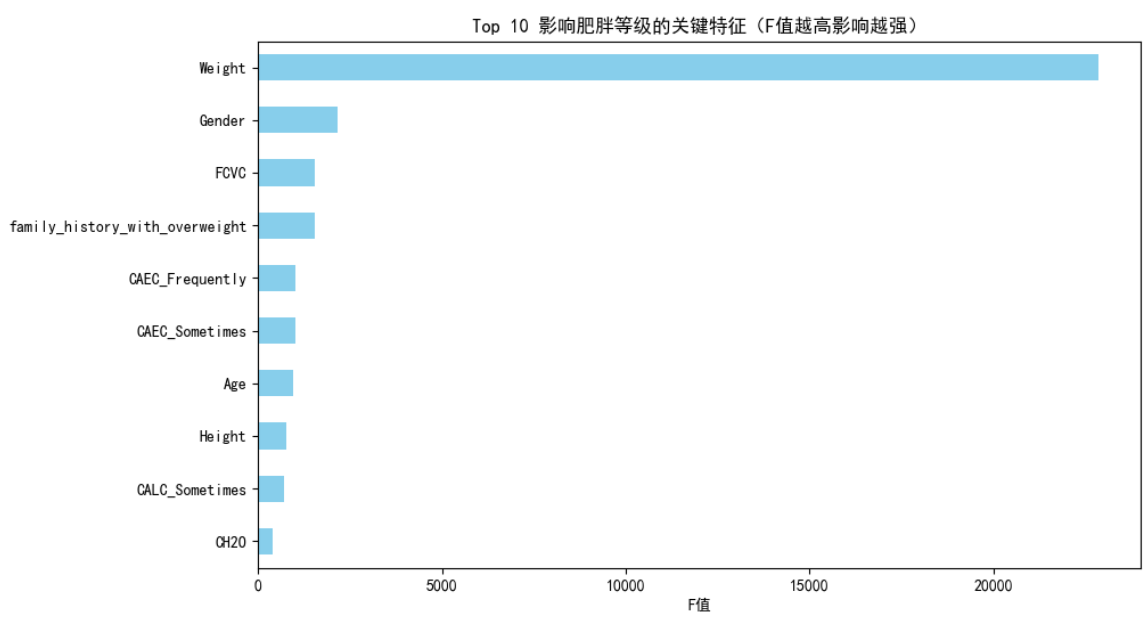
print("\n Top10关键特征:")
print(scores.head(10))
四、模型训练
(一)划分训练集和测试集(8:2,分层抽样保证类别分布一致)
1. 为什么用 X_selected 而不是原来的 X?
X:所有特征(几十列,包含弱相关 / 冗余特征)X_selected:ANOVA 筛选后的 Top10 关键特征- 好处:模型更小、训练更快、减少过拟合、提升泛化能力
2. stratify=y 为什么重要?
- 你的目标列是多分类标签(肥胖等级共 6~7 类)
- 不加这个参数,可能出现:训练集缺某类标签,测试集全是某类标签
- 加了:训练集和测试集的类别分布完全一致,评估结果真实可信
X_train, X_test, y_train, y_test = train_test_split(
X_selected, y, test_size=0.2, random_state=42, stratify=y
)(二)初始化多分类逻辑回归模型
model = LogisticRegression(
multi_class="multinomial",
solver="lbfgs",
max_iter=1000,
random_state=42
)(三)训练模型
model.fit(X_train, y_train)
print("\n 模型训练完成!")
五、模型评估
(一)预测准确性
y_pred = model.predict(X_test)
acc = accuracy_score(y_test, y_pred)
print(f"\n 模型准确率:{acc:.4f}")
(二)查看详情
print("\n 分类报告")
print(classification_report(y_test, y_pred, target_names=le_target.classes_))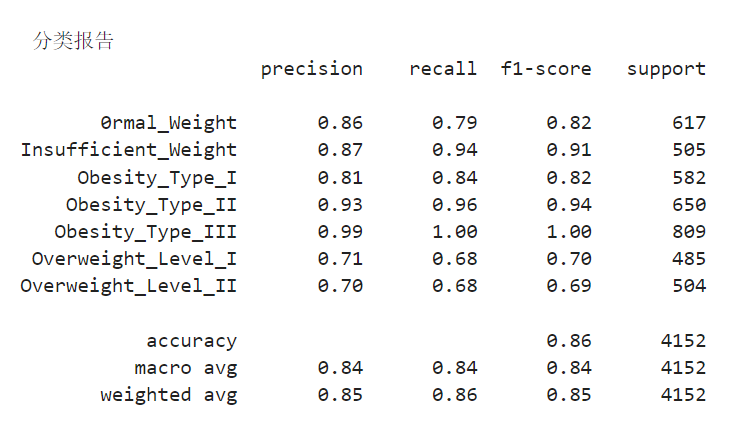
六、混淆矩阵可视化总结
cm = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(10, 8))
sns.heatmap(cm, annot=True, fmt="d", cmap="Blues",
xticklabels=le_target.classes_, yticklabels=le_target.classes_)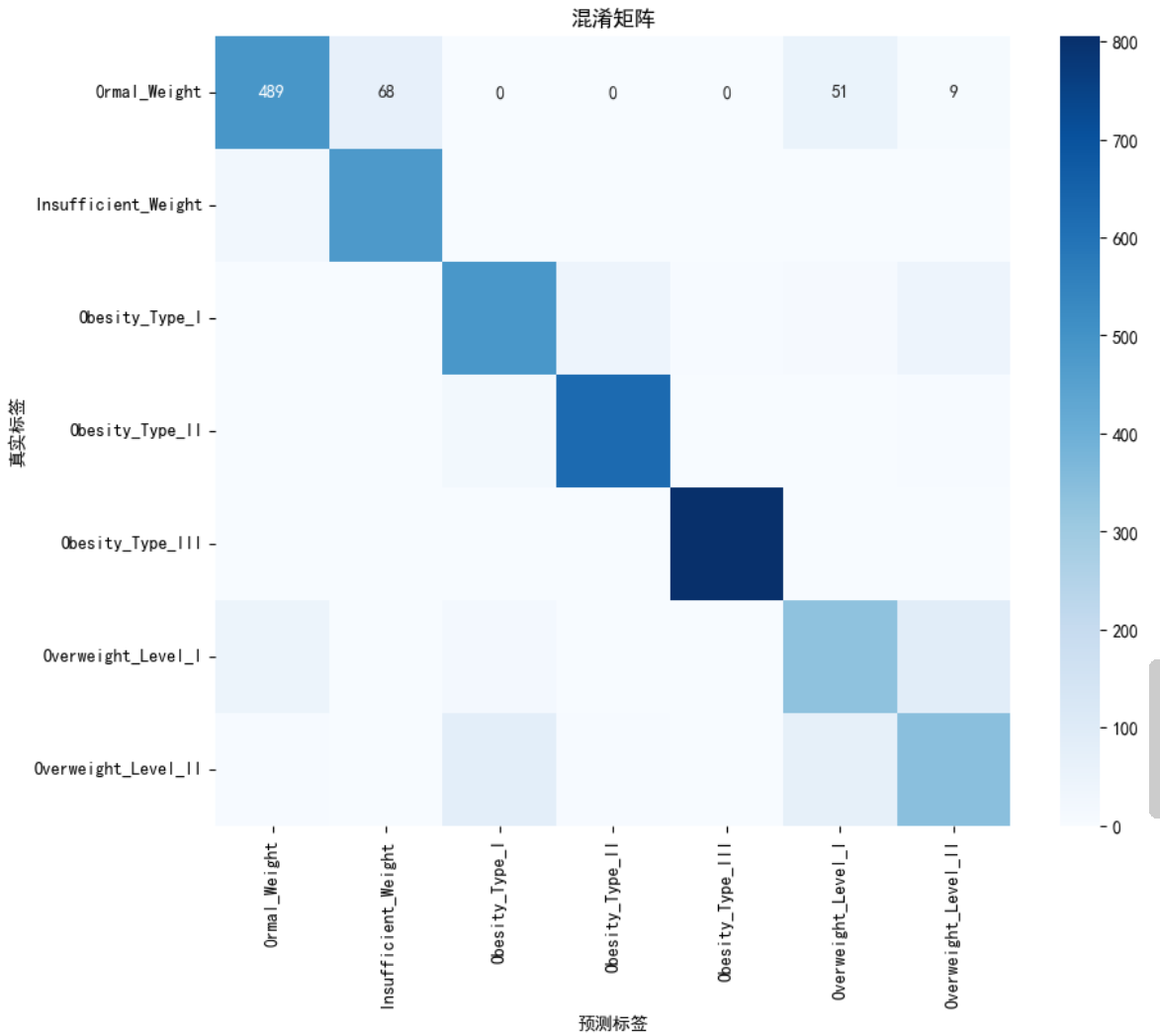


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)