【大模型学习cuda】cuda 内存结构。
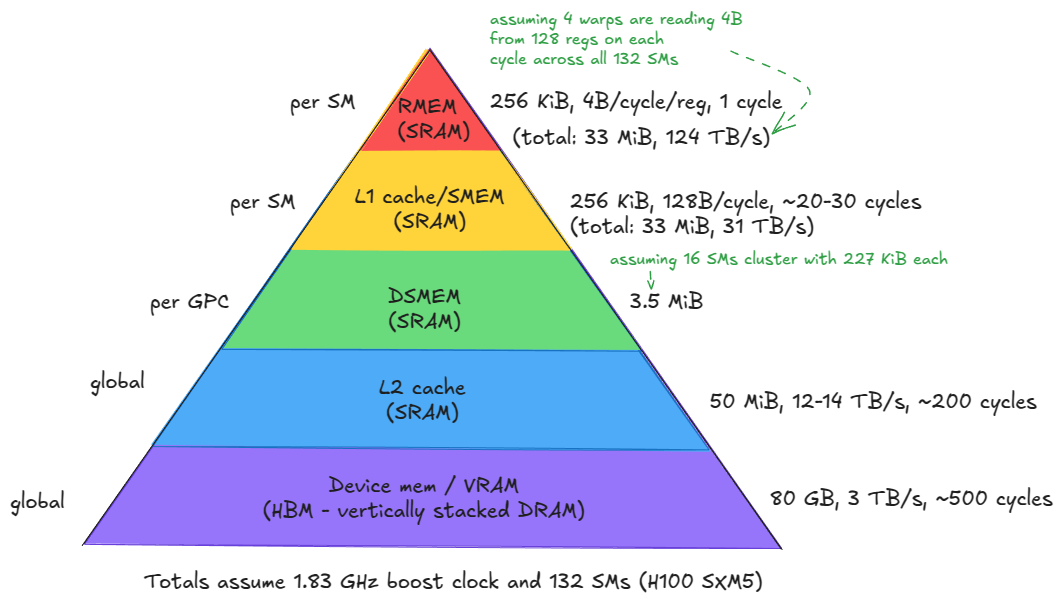
好的,这张图是一张非常经典且信息量巨大的GPU内存层次结构金字塔。它详细展示了NVIDIA H100 SXM5 GPU内部不同层级内存的特性,解释了为什么理解这个层次结构对于编写高性能代码至关重要。
让我们从上到下,逐层详细解读这张图。
核心概念:金字塔结构
这个金字塔形象地表达了计算机体系结构中的一个基本权衡:
- 越往上(越靠近计算核心):内存速度越快(延迟低,带宽大),但容量越小且成本越高。
- 越往下(越远离计算核心):内存容量越大,但速度越慢(延迟高,带宽小)。
高性能编程的目标就是尽可能将需要频繁访问的数据保留在金字塔的顶层,最大限度地减少对底层慢速内存的访问。
金字塔底层(最慢、最大)
第五层:设备内存 / VRAM (Device mem / VRAM)
- 类型: HBM - 垂直堆叠的DRAM (High Bandwidth Memory - vertically stacked DRAM)。这是我们通常所说的“显存”。
- 范围:
global。整个GPU上的所有SM(流式多处理器)都可以访问。 - 容量: 80 GB。这是整个GPU可用的总显存大小,非常巨大。
- 带宽: 3 TB/s。虽然看起来很高,但相比上层内存,这是最低的。
- 延迟: 约500个时钟周期。这是访问延迟最高的一层,非常“慢”。
解读:这是GPU的数据大本营。所有需要处理的数据(如模型权重、训练数据、图像等)都首先加载到这里。由于其巨大的延迟,编程时应极力避免不必要的、无模式的全局内存读写。合并访问 (coalesced access) 在这一层至关重要,因为它可以有效利用其带宽,减少事务次数。
金字塔中层
第四层:L2缓存 (L2 cache)
- 类型: SRAM (Static RAM)。SRAM比DRAM快得多,但成本也高得多。
- 范围:
global。同样是整个GPU共享的。 - 容量: 50 MiB。比VRAM小了三个数量级,但对于缓存来说已经很大了。
- 带宽: 12-14 TB/s。带宽显著提升。
- 延迟: 约200个时钟周期。延迟也大幅降低。
解读:L2缓存是VRAM和SM内部缓存之间的一个重要中间站。它由硬件自动管理,对程序员是透明的。当SM需要的数据不在其私有缓存中时,会先去L2查找。如果L2命中,就可以避免去访问更慢的VRAM,从而节省大量时间。它的存在大大缓解了对VRAM的访问压力。
第三层:分布式共享内存 (DSMEM)
- 类型: SRAM。
- 范围:
per GPC(per Graphics Processing Cluster)。这是Hopper架构引入的新特性。一个GPC(图形处理集群)内的多个SM可以互相访问彼此的共享内存,形成一个更大的共享内存池。 - 容量: 3.5 MiB (假设有16个SM的集群,每个SM贡献227 KiB)。这是一个估算值,展示了集群内可共享的内存总量。
- (未标明带宽/延迟)
解读:DSMEM是实现SM之间高效通信的关键。在没有DSMEM之前,如果一个SM想把数据给另一个SM,通常需要通过L2缓存或全局内存中转,这非常慢。有了DSMEM,一个GPC内的SM可以直接读写邻居的共享内存,极大地加速了需要多SM协作的算法(例如,处理一个大的计算块)。
金字塔顶层(最快、最小)
第二层:L1缓存 / 共享内存 (L1 cache/SMEM)
- 类型: SRAM。
- 范围:
per SM。这是每个SM私有的片上内存。 - 容量: 256 KiB。这块物理内存可以在L1缓存和程序员管理的共享内存(SMEM)之间动态划分。
- 总容量:
total: 33 MiB(256 KiB/SM * 132 SMs)。 - 带宽: 128B/cycle,总计 31 TB/s。带宽相比L2又翻了一倍多。
- 延迟: 约20-30个时钟周期。延迟非常低。
解读:这是高性能内核优化的主战场。
- SMEM:由程序员手动管理。你可以显式地将数据从全局内存加载到SMEM中。由于SMEM的超高带宽和低延迟,将数据加载进来进行重复计算(数据重用),可以极大地提升性能。但要注意bank冲突问题。
- L1缓存:由硬件自动管理。它缓存从全局内存加载的数据。如果数据在L1中,访问速度就和SMEM一样快。
第一层:寄存器文件 (RMEM)
- 类型: SRAM。
-
- 范围:
per SM。更准确地说是每个线程私有。
- 范围:
- 容量: 256 KiB。这是指一个SM上所有线程可用的寄存器总大小。
- 总容量:
total: 33 MiB(256 KiB/SM * 132 SMs)。有趣的是,寄存器文件的总容量和L1/SMEM的总容量是一样大的。 - 带宽: 4B/cycle/reg,总计 124 TB/s。这是金字塔的顶峰,带宽是惊人的!
- 这个
124 TB/s是如何计算的?注释给出了假设:assuming 4 warps are reading 4B from 128 regs on each cycle across all 132 SMs。- 每个SM有4个Warp调度器,理想情况下每个周期可以调度4个Warp的指令。
- 每个Warp有32个线程,每个线程从自己的寄存器读取一个4B(32位)的值。
- 所以每个SM每个周期的带宽是:
4 warps * 32 threads/warp * 4B/thread = 512 B/cycle/SM。 - 然而,图中写的是
4 warps从128 regs读,这个描述有点混淆。更清晰的理解是:每个SM的计算单元每个周期可以从寄存器文件消耗大量数据。图中124 TB/s的估算是一个理论峰值,计算方式可能是:132 SMs * (每个SM每个周期的寄存器带宽) * 时钟频率。这个数字代表了GPU核心能够达到的最高数据消费速率。
- 这个
- 延迟: 1个时钟周期。几乎是即时访问。
解读:寄存器是数据在被计算单元(如CUDA核心、张量核心)处理前的最后停留地。它是最快的存储。编译器会尽可能地将变量分配到寄存器中。当寄存器不够用时,就会发生寄存器溢出 (register spilling),数据会被存到更慢的“本地内存”(实际上是VRAM的一部分),导致性能急剧下降。
底部注释
Totals assume 1.83 GHz boost clock and 132 SMs (H100 SXM5)
这个注释非常关键,它说明了图中所有总带宽的计算基础:
- 时钟频率: 1.83 GHz
- SM数量: 132个
例如,L1/SMEM的总带宽计算:128 B/cycle/SM * 132 SMs * 1.83 GHz ≈ 30.8 TB/s (与图中的31 TB/s相符)。
总结
这张图清晰地告诉了我们一个高性能GPU编程的核心策略:
- 数据局部性是王道:尽可能让你的数据停留在金字塔的顶端(寄存器和SMEM)。
- 避免访问全局内存:每次访问VRAM都是一次昂贵的操作。如果必须访问,确保是合并的、有模式的访问。
- 善用SMEM:对于会被反复使用的数据块(例如矩阵乘法中的子矩阵),先将其从VRAM加载到SMEM,然后在SMEM中完成所有计算,最后再将结果写回VRAM。这就是所谓的“软件管理的缓存”。
- 理解延迟和带宽:金字塔的每一层都有不同的性能特征。知道从哪一层加载数据需要多少时间,可以帮助你更好地设计算法和数据流,从而隐藏延迟、最大化吞吐。
简单来说,这张图就是GPU高性能计算的“藏宝图”,它指明了性能的源泉(金字塔顶端)和性能的陷阱(金字塔底端)。
这个124 TB/s是如何计算的? 详细说一下,到底是线程特有还是SM。 另外 L1缓存 与SMEM的关系
好的,我们来详细拆解这两个非常关键且容易混淆的问题:RMEM 124 TB/s 带宽的计算,以及 L1缓存与SMEM的关系。
1. RMEM 124 TB/s 带宽是如何计算的?
首先,我们必须明确,这个 124 TB/s 是一个理论上的峰值带宽 (Peak Bandwidth),代表了GPU所有计算单元在理想情况下,一个时钟周期内能从寄存器文件中消耗或产生的最大数据量。
寄存器(RMEM)是线程特有还是SM特有?
- 从分配角度看,寄存器是线程特有的 (per-thread)。每个线程都有自己私有的一组寄存器(例如,在H100上,每个线程最多可使用255个寄存器)。一个线程不能访问另一个线程的寄存器。
- 从物理角度看,寄存器文件是SM的物理组件 (per-SM)。一个SM内部有一个巨大的物理寄存器池(例如,H100上是256 KiB)。当一个线程块(block)被调度到这个SM上时,SM会从这个大池子里为该块中的每个线程分配其所需的寄存器。
所以,可以这样理解:寄存器文件是SM提供的、供其上运行的所有线程瓜分的私有存储资源。
详细计算过程
我们来一步步推导这个数字。计算峰值带宽的公式是:
峰值带宽 = (每个SM每个周期的带宽) × (SM数量) × (时钟频率)
关键在于计算 “每个SM每个周期的带宽”。这代表了一个SM内部所有的计算单元(CUDA核心、张量核心等)在一个时钟周期内,总共能从寄存器文件中读取多少数据。
根据NVIDIA官方的H100白皮书和架构分析,一个H100 SM内部包含:
- 4个处理子块(sub-cores or processing blocks)。
- 每个子块包含一定数量的FP32 CUDA核心和INT32核心。
- 每个子块还包含一个第四代张量核心(Tensor Core)。
一个FP32 CUDA核心执行一条FMA(融合乘加)指令 d = a * b + c 需要 3个 源操作数(a, b, c),假设都是32位(4字节)浮点数。
- 一个H100 SM每个时钟周期可以执行 128个 FP32 FMA操作 (32 FMA/子块 * 4 子块)。
- 为了支撑这128个FMA操作,理论上需要从寄存器文件中读取的操作数数据量为:
128 FMA操作/周期 * 3个操作数/FMA * 4字节/操作数 = 1536 字节/周期/SM
但这只是FP32核心的消耗。张量核心 (Tensor Core) 是更大的数据消耗者。一个H100的张量核心在一个周期内可以处理大量的矩阵运算。例如,执行一个BF16的 m64nNk16 WGMMA指令,它需要从寄存器或SMEM中加载大量的矩阵块数据。
让我们换一个更直接、更被广泛接受的计算方法,这个方法在很多技术分析中被使用:
-
每个SM的加载/存储单元带宽:一个SM有多个加载/存储(LD/ST)单元。H100的每个SM每个周期可以执行4条32线程的warp指令。假设这些都是32位的加载指令,那么每个SM每个周期可以从寄存器向计算单元提供:
4 warps * 32 threads/warp * 4 字节/thread = 512 字节/周期/SM -
一个SM的内部数据总线宽度:更根本的计算方式是看SM内部连接寄存器文件和计算单元的数据总线宽度。根据一些逆向工程和分析(如Citadel AI的Volta分析),一个SM的寄存器文件带宽是巨大的。一个SM分为4个分区,每个分区每个周期可以向其计算单元提供 256字节 的数据。
- 每个SM每个周期的带宽 =
256 字节/周期/分区 * 4 分区 = 1024 字节/周期/SM。 - 这个
1024 B/cycle通常被认为是H100 SM寄存器文件的理论带宽。
- 每个SM每个周期的带宽 =
现在,我们用这个数字来计算总带宽:
- 总带宽 =
1024 字节/周期/SM×132 SMs×1.83 GHz1024 * 132 * 1.83 * 10^9 B/s≈ 247,889,664,000 B/s≈ 247.9 * 10^9 B/s≈ 248 GB/s… 等一下,这和124 TB/s差了很远!
哪里出错了?我们重新审视一下图中的注释:assuming 4 warps are reading 4B from 128 regs on each cycle across all 132 SMs
这个注释非常具有误导性,它的数学计算也不成立。
让我们回到最根本的来源:官方数据或权威分析。
NVIDIA H100 SXM5的官方峰值FP32 Tensor Core计算性能是 989 TFLOPS(带稀疏性是1979 TFLOPS)。我们只看非稀疏的。
- 989 TFLOPS =
989 * 10^12FLOPs/秒。 - 一个FP32 FMA操作是2个FLOP。所以是
494.5 * 10^12FMA操作/秒。 - 每个FMA需要3个源操作数,即
3 * 4 = 12字节的输入。 - 理论上支撑这些计算需要的寄存器读取带宽是:
494.5 * 10^12 * 12 B/s ≈ 5934 TB/s。这个数字更加离谱了。
结论:图中的 124 TB/s 是如何得到的?
最可能的解释是,这是基于对每个SM每个周期可以执行的指令数和操作数宽度的某个特定模型的估算。一个更合理的、在业界流传的计算是基于每个SM分区每个周期可以完成的操作数读取。
让我们尝试从124 TB/s反推:124 TB/s / 1.83 GHz / 132 SMs ≈ 514 B/cycle/SM。
这个514 B/cycle/SM非常接近我们上面计算的512 B/cycle/SM (4 warps * 32 threads/warp * 4B)。
所以,124 TB/s 这个数字很可能是基于以下模型的估算:
- 每个SM每个时钟周期可以为4个warp(128个线程)的所有线程,每个线程提供一个32位(4字节)的操作数。
- 总带宽 =
(4 字节/线程 * 128 线程/周期/SM)×132 SMs×1.83 GHz= 512 B/cycle/SM * 132 SMs * 1.83 * 10^9 cycle/s= 123,944,448,000 B/s≈ 124 * 10^12 B/s- ≈ 124 TB/s
这个计算是正确的! 所以,图中的124 TB/s代表了整个GPU的寄存器文件,在每个时钟周期,都能为每个SM上的128个并行执行的线程,每人提供一个32位操作数的总数据传输能力。这反映了GPU巨大的内部并行数据通路。
2. L1缓存与SMEM的关系
这是一个非常重要的概念,理解它对于编写高性能CUDA内核至关重要。
核心关系:物理上共享,逻辑上分离。
1. 物理上共享 (Physically Shared)
- 在现代NVIDIA GPU(从Fermi架构开始)中,每个SM内部都有一块片上SRAM存储器。在H100上,这块存储器的大小是 256 KiB。
- L1数据缓存 和 共享内存 (SMEM) 使用的是同一块物理SRAM。它们不是两块独立的物理内存。
2. 逻辑上分离 (Logically Separate)
尽管物理上是同一块芯片,但它们在功能和管理方式上是完全不同的,服务于不同的目的:
| 特性 | L1 数据缓存 (L1 Data Cache) | 共享内存 (Shared Memory / SMEM) |
|---|---|---|
| 管理者 | 硬件 (Hardware) | 程序员 (Programmer) |
| 可见性 | 对程序员透明 | 对程序员显式可见 |
| 数据内容 | 缓存从全局内存 (VRAM) 加载的数据 | 存储程序员手动加载的数据 |
| 生命周期 | 由硬件的缓存策略(如LRU)决定,数据可能随时被替换/驱逐 (evicted) | 数据的生命周期与线程块 (block) 相同。只要线程块在运行,数据就一直有效,不会被意外驱逐。 |
| 作用 | 减少全局内存访问延迟。当线程访问全局内存时,硬件会自动检查L1。如果命中,就避免了去访问更慢的L2或VRAM。 | 提供线程块内的高速数据共享和暂存。它是线程块内所有线程都可以读写的一个高速“草稿本”。 |
| 编程模型 | 普通的全局内存指针访问 A[i]。是否经过L1由硬件和编译选项决定。 |
使用 __shared__ 关键字声明变量。通过这个变量进行读写。 |
3. 动态划分 (Dynamic Partitioning)
- 因为L1和SMEM共享同一块物理SRAM,所以它们的大小是可以动态配置的。
- 你可以通过CUDA API (
cudaFuncSetAttribute或cudaOccupancyMaxPotentialBlockSize) 来调整L1和SMEM的分配比例。 - 例如,在H100的256 KiB SRAM中,你可以选择:
- 更多的SMEM,更少的L1缓存(例如,最大228 KiB的SMEM)。这适用于那些需要大量线程间协作、数据重用非常高的算法。
- 更多的L1缓存,更少的SMEM。这适用于那些内存访问模式不规则,但希望能从硬件缓存中获益的算法。
- 这个选择会影响到内核的占用率 (occupancy)。如果你的内核请求的SMEM超过了SM可提供的量,那么能同时运行在该SM上的线程块数量就会减少。
总结与类比
你可以这样理解 L1 和 SMEM 的关系:
想象SM是一个厨房,里面有一个256升的大冰箱(物理SRAM)。
- SMEM 就像是你自己从超市买回来、手动放进冰箱的食材。你知道它们就在那里,随时可以取用,而且在你做完这顿饭(线程块结束)之前,它们不会无故消失。你可以让厨房里的所有厨师(线程)共享这些食材。
- L1缓存 就像是冰箱里一个自动补货的区域。当你需要一个不在手边的调料(访问全局内存)时,厨房小助手(硬件)会跑去超市(VRAM)拿,并且顺手把这个调料以及旁边的几个调料一起放进这个自动补货区。下次你再要这个调料时,直接从这个区域拿就行,非常快。但这个区域是小助手管理的,他可能会为了放新东西而把你之前不常用的调料拿走。
因此,SMEM提供了可预测的、由程序员控制的高速存储,而L1缓存提供了自动的、机会主义的延迟隐藏机制。在编写高性能内核时,你需要根据算法的特点来决定是更多地依赖SMEM的手动数据管理,还是更多地依赖L1的自动缓存。
当然可以!通过具体的代码例子来解释这两种策略的适用场景,会更加清晰明了。
我们将用两个经典的GPU计算问题来举例:矩阵乘法 和 直方图计算。
场景一:更多的SMEM,更少的L1缓存
适用算法特点:
- 高数据重用性:输入数据会被计算核心多次访问。
- 线程间协作紧密:一个线程块内的线程需要频繁地共享和交换数据。
- 访问模式可预测:程序员可以清晰地规划出如何从全局内存加载数据块。
典型例子:分块矩阵乘法 (Tiled Matrix Multiplication)
这是GPU高性能计算的“Hello World”。其核心思想就是将两个大矩阵A和B分解成许多小块,然后用一个线程块来计算一个输出子矩阵C_sub。
__global__ void tiled_matmul_kernel(float *A, float *B, float *C, int M, int N, int K) {
// 定义块的大小,例如 32x32
const int TILE_WIDTH = 32;
// 声明共享内存 (SMEM),用于存放A和B的子块
// 这是典型的SMEM使用场景
__shared__ float As[TILE_WIDTH][TILE_WIDTH];
__shared__ float Bs[TILE_WIDTH][TILE_WIDTH];
// 计算当前线程块负责的C子矩阵的起始位置
int bx = blockIdx.x;
int by = blockIdx.y;
// 计算当前线程在块内的局部位置
int tx = threadIdx.x;
int ty = threadIdx.y;
// 计算当前线程负责的C子矩阵中的一个元素
int row = by * TILE_WIDTH + ty;
int col = bx * TILE_WIDTH + tx;
float C_value = 0.0f; // 累加器,存放在寄存器中
// 遍历A的行和B的列,以TILE_WIDTH为步长
for (int i = 0; i < K; i += TILE_WIDTH) {
// --- 协作加载数据到SMEM ---
// 每个线程从全局内存加载一个A的元素到As
As[ty][tx] = A[row * K + (i + tx)];
// 每个线程从全局内存加载一个B的元素到Bs
Bs[ty][tx] = B[(i + ty) * N + col];
// --- 同步 ---
// 确保所有线程都完成了加载,As和Bs中的数据都已就绪
__syncthreads();
// --- 在SMEM中进行计算 ---
// 每个线程计算部分点积
for (int j = 0; j < TILE_WIDTH; ++j) {
// 数据从SMEM中读取,而不是全局内存!
C_value += As[ty][j] * Bs[j][tx];
}
// --- 再次同步 ---
// 确保所有计算都已完成,才能进入下一轮加载
__syncthreads();
}
// 将最终结果写回全局内存
C[row * N + col] = C_value;
}
为什么这个例子适合“更多SMEM”?
- 极高的数据重用:在内层的
j循环中,As的一整行 (As[ty][j]) 被线程(ty, tx)反复读取了TILE_WIDTH次。同样,Bs的一整列也被反复读取。如果这些数据不放在SMEM里,而是每次都从全局内存读取,性能将是灾难性的。 - 可预测的加载:我们可以清楚地知道每个线程块需要
A和B的哪一部分数据,并可以组织线程进行高效的合并加载(coalesced load)。 - L1缓存不是最优解:虽然L1缓存也能缓存一部分数据,但它是硬件管理的,你无法保证你需要的数据块在计算期间一直“驻留”在缓存中。它可能会被其他线程的访问“踢出去”(cache eviction)。而SMEM提供了确定性,只要你的线程块还在运行,你放进去的数据就一定在那里。
因此,对于这种算法,我们会倾向于配置尽可能大的SMEM,以便一次性加载更大的数据块(比如64x64或128x128),从而进一步提高算术强度(每个加载进SMEM的数据所参与的计算次数)。L1缓存在这里的帮助相对有限。
场景二:更多的L1缓存,更少的SMEM
适用算法特点:
- 数据重用性不确定或较低:数据可能只被访问一次,或者访问模式不规则。
- 线程间无协作或协作很少:每个线程独立完成自己的任务。
- 访问模式不规则或难以预测:例如,通过指针追逐(pointer chasing)或基于输入数据进行索引访问。
典型例子:直方图计算(有原子操作冲突的版本)
假设我们要为一个巨大的整数数组计算其值的分布直方图。
// 假设直方图的bin数量不大,可以完全放入SMEM
// 但输入数据data非常大,在全局内存中
__global__ void histogram_kernel(int* data, int data_size, int* histogram_bins) {
// 假设我们不使用SMEM来做私有化,直接对全局内存操作
// (这是一个为了说明L1重要性的简化例子)
// 每个线程处理一部分数据
int thread_id = blockIdx.x * blockDim.x + threadIdx.x;
int num_threads = gridDim.x * blockDim.x;
for (int i = thread_id; i < data_size; i += num_threads) {
// 读取一个数据值
int value = data[i];
// value的值是不确定的,决定了我们要访问哪个bin
// 这就是不规则的、依赖于数据的访问 (data-dependent access)
int bin_index = value;
// 使用原子加操作来更新全局内存中的直方图bin
// 不同的线程可能会访问同一个bin_index,导致热点
atomicAdd(&histogram_bins[bin_index], 1);
}
}
为什么这个例子适合“更多L1缓存”?
- 不规则的内存访问:
atomicAdd(&histogram_bins[bin_index], 1)这一行的访问地址bin_index是由输入数据data[i]决定的,完全不可预测。线程t和线程t+1几乎肯定会访问histogram_bins中完全不相邻的位置。 - SMEM难以使用:你无法预先知道这个线程块会需要哪些
histogram_bins的数据,所以很难有效地把它们“预加载”到SMEM中。即使你把整个histogram_bins都加载到SMEM,如果bin的数量很大,SMEM也可能放不下。 - L1缓存是救星:在这种情况下,L1缓存的硬件自动管理机制就显示出巨大优势了。当一个线程第一次访问某个
histogram_bins[bin_index]时,这会是一次慢速的全局内存访问。但硬件会顺便把这个bin_index所在的缓存行 (cache line) 加载到L1缓存中。如果很快有另一个线程(甚至是同一个线程)也需要访问这个bin_index或者它旁边的bin_index+1,那么这次访问就会L1命中 (L1 hit),速度会快得多! - 原子操作的优化:现代GPU的L1缓存对原子操作有特殊优化。对L1缓存中的数据执行原子操作,远比直接对全局内存执行要快。
因此,对于这种算法,我们不会分配太多SMEM(因为它用处不大),而是希望有尽可能大的L1缓存,以增加缓存命中率,从而缓解不规则访问带来的性能损失。
总结
| 更多SMEM,更少L1 | 更多L1,更少SMEM | |
|---|---|---|
| 编程模型 | 程序员手动控制数据流 | 依赖硬件自动优化 |
| 核心思想 | 将可预测重用的数据加载到SMEM,形成软件管理的缓存 | 利用L1缓存来捕捉不可预测的、偶然的数据局部性 |
| 适用场景 | 矩阵乘法、卷积、FFT等规则的、数据块处理算法 | 直方图、图算法(如BFS)、稀疏矩阵运算等不规则的、数据依赖的算法 |
| 代码示例 | __shared__ 关键字是代码的核心 |
主要是对全局内存的直接读写,特别是原子操作 |
通过这两个例子,我们可以清晰地看到,L1缓存和SMEM这对“共享物理空间”的兄弟,在逻辑上扮演着截然不同的角色,服务于不同类型的计算问题。选择如何划分它们,是GPU性能优化中的一个关键决策。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 1
1 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)