计算机毕业设计Django+大模型中华古诗词知识图谱可视化 古诗词智能问答系统 古诗词数据分析 古诗词情感分析模型 自然语言处理NLP 机器学习 深度学习
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
Django + 大模型中华古诗词知识图谱可视化技术说明
一、项目背景与目标
中华古诗词是中华文化的瑰宝,蕴含着丰富的历史、哲学和艺术价值。传统古诗词研究多依赖人工查阅文献,效率低下且难以全面挖掘诗词间的关联。本项目旨在结合Django框架与大模型技术,构建一个中华古诗词知识图谱可视化系统,实现古诗词数据的结构化存储、智能关联分析与直观可视化展示,为古诗词研究、教学与文化传播提供高效工具。
二、技术选型
- 后端框架:Django
- 优势:Django是一个高级Python Web框架,遵循MVT(Model-View-Template)设计模式,具有强大的数据库管理、用户认证、表单处理等功能,能够快速搭建稳定、安全的Web应用。其内置的ORM(对象关系映射)工具方便与数据库交互,适合处理古诗词知识图谱的结构化数据。
- 大模型:选择具有强大自然语言处理能力的大模型,如GPT系列或国内类似的大模型(如文心一言、通义千问等)。利用大模型的语义理解、信息抽取和知识推理能力,从古诗词文本中自动提取关键信息,构建知识图谱的实体和关系。
- 知识图谱存储:Neo4j
- 原因:Neo4j是一种高性能的图数据库,以图结构存储数据,能够高效地表示和查询实体之间的关系。古诗词知识图谱中包含大量的诗词、作者、朝代、意象等实体以及它们之间的复杂关系,Neo4j的图模型非常适合存储和展示这种关系型数据。
- 前端可视化:D3.js或ECharts
- D3.js是一个基于数据驱动的JavaScript库,提供了丰富的可视化组件和强大的交互功能,能够创建高度定制化的知识图谱可视化效果。
- ECharts是一个简单易用的JavaScript可视化库,提供了多种图表类型,包括关系图,适合快速实现知识图谱的可视化展示,且具有良好的兼容性和性能。
三、系统架构设计
(一)整体架构
本系统采用三层架构,包括数据层、业务逻辑层和表现层。
- 数据层:负责古诗词数据的存储和管理,包括原始古诗词文本数据、从大模型抽取的知识图谱数据以及用户交互产生的数据。使用Neo4j图数据库存储知识图谱,MySQL数据库存储用户信息、系统配置等结构化数据。
- 业务逻辑层:基于Django框架实现,处理用户请求,调用大模型API进行知识抽取,与数据库进行交互,实现知识图谱的构建、查询和更新等业务逻辑。
- 表现层:使用HTML、CSS和JavaScript技术构建用户界面,通过D3.js或ECharts实现知识图谱的可视化展示,并提供用户交互功能,如搜索、筛选、缩放等。
(二)详细模块设计
- 数据采集与预处理模块
- 从公开的古诗词数据库、古籍文献等来源采集古诗词文本数据。
- 对采集到的数据进行清洗和预处理,包括去除噪声、统一格式、分词等操作,为后续的知识抽取做准备。
- 大模型知识抽取模块
- 调用大模型API,将预处理后的古诗词文本作为输入,利用大模型的语义理解和信息抽取能力,识别出诗词中的实体(如作者、朝代、意象等)和关系(如创作关系、引用关系等)。
- 将抽取到的实体和关系进行整理和标准化,形成知识图谱的节点和边数据。
- 知识图谱构建模块
- 使用Python的Neo4j驱动,将抽取到的节点和边数据导入到Neo4j图数据库中,构建古诗词知识图谱。
- 定义知识图谱的模式(Schema),包括节点的标签和边的类型,确保数据的一致性和规范性。
- Django后端服务模块
- 创建Django项目和应用,配置数据库连接(包括Neo4j和MySQL)。
- 实现知识图谱的查询接口,根据用户请求从Neo4j数据库中检索相关的节点和边数据。
- 处理用户认证、权限管理等安全相关功能,确保系统的安全性。
- 前端可视化模块
- 使用HTML和CSS搭建用户界面的基本框架,设计搜索框、筛选条件、可视化区域等界面元素。
- 使用JavaScript调用Django后端提供的API,获取知识图谱数据。
- 根据获取到的数据,使用D3.js或ECharts绘制知识图谱,并实现交互功能,如节点点击展开、边的高亮显示、图谱的缩放和平移等。
四、关键技术实现
(一)大模型知识抽取
以下是一个使用Python调用大模型API进行知识抽取的示例代码(以调用OpenAI的GPT模型为例):
python
1import openai
2
3# 设置OpenAI API密钥
4openai.api_key = "YOUR_API_KEY"
5
6def extract_knowledge(poem_text):
7 prompt = f"请从以下古诗词文本中提取实体和关系:\n{poem_text}\n实体包括作者、朝代、意象等,关系包括创作关系、引用关系等。以JSON格式返回结果,例如:{{\"entities\": [{\"name\": \"李白\", \"type\": \"author\"}], \"relations\": [{\"source\": \"李白\", \"target\": \"《静夜思》\", \"type\": \"create\"}]}}"
8 response = openai.Completion.create(
9 engine="text-davinci-003",
10 prompt=prompt,
11 max_tokens=500
12 )
13 result = response.choices[0].text.strip()
14 # 这里可以添加对返回结果的进一步处理和解析
15 return result
16(二)Neo4j知识图谱构建
使用Python的Neo4j驱动将抽取到的知识导入到Neo4j数据库中:
python
1from neo4j import GraphDatabase
2
3class Neo4jDatabase:
4 def __init__(self, uri, user, password):
5 self._driver = GraphDatabase.driver(uri, auth=(user, password))
6
7 def close(self):
8 self._driver.close()
9
10 def create_node(self, label, properties):
11 with self._driver.session() as session:
12 query = f"CREATE (n:{label} $props) RETURN n"
13 result = session.run(query, props=properties)
14 return result.single()[0]
15
16 def create_relation(self, source_label, source_name, target_label, target_name, relation_type):
17 with self._driver.session() as session:
18 query = f"""
19 MATCH (s:{source_label} {{name: $source_name}}), (t:{target_label} {{name: $target_name}})
20 CREATE (s)-[r:{relation_type}]->(t)
21 RETURN r
22 """
23 result = session.run(query, source_name=source_name, target_name=target_name)
24 return result.single()[0]
25
26# 示例使用
27db = Neo4jDatabase("bolt://localhost:7687", "neo4j", "password")
28# 创建作者节点
29author_node = db.create_node("Author", {"name": "李白", "dynasty": "唐朝"})
30# 创建诗词节点
31poem_node = db.create_node("Poem", {"name": "《静夜思》", "content": "床前明月光,疑是地上霜。举头望明月,低头思故乡。"})
32# 创建创作关系
33relation = db.create_relation("Author", "李白", "Poem", "《静夜思》", "CREATE")
34db.close()
35(三)Django后端查询接口实现
在Django的views.py中实现知识图谱的查询接口:
python
1from django.http import JsonResponse
2from neo4j import GraphDatabase
3
4def search_knowledge_graph(request):
5 query = request.GET.get('query', '')
6 # 连接Neo4j数据库
7 driver = GraphDatabase.driver("bolt://localhost:7687", auth=("neo4j", "password"))
8 with driver.session() as session:
9 # 这里根据查询条件构建Cypher查询语句
10 cypher_query = f"MATCH (n) WHERE n.name CONTAINS '{query}' RETURN n LIMIT 10"
11 result = session.run(cypher_query)
12 nodes = []
13 for record in result:
14 node = record["n"].values()
15 nodes.append(node)
16 driver.close()
17 return JsonResponse({"nodes": nodes})
18(四)前端可视化实现(以ECharts为例)
html
1<!DOCTYPE html>
2<html lang="zh-CN">
3
4<head>
5 <meta charset="UTF-8">
6 <title>中华古诗词知识图谱可视化</title>
7 <script src="https://cdn.jsdelivr.net/npm/echarts@5.4.3/dist/echarts.min.js"></script>
8</head>
9
10<body>
11 <div id="knowledgeGraph" style="width: 800px; height: 600px;"></div>
12 <script>
13 // 模拟从后端获取的数据
14 const data = {
15 nodes: [
16 { name: '李白', category: 'author' },
17 { name: '《静夜思》', category: 'poem' },
18 { name: '唐朝', category: 'dynasty' }
19 ],
20 links: [
21 { source: '李白', target: '《静夜思》', type: 'create' },
22 { source: '李白', target: '唐朝', type: 'live_in' }
23 ]
24 };
25
26 // 初始化ECharts实例
27 const chart = echarts.init(document.getElementById('knowledgeGraph'));
28
29 // 配置项
30 const option = {
31 title: {
32 text: '中华古诗词知识图谱'
33 },
34 tooltip: {},
35 legend: {
36 data: ['author', 'poem', 'dynasty']
37 },
38 series: [{
39 type: 'graph',
40 layout: 'force',
41 data: data.nodes.map(function (node) {
42 return {
43 name: node.name,
44 category: node.category,
45 symbolSize: 30
46 };
47 }),
48 links: data.links.map(function (link) {
49 return {
50 source: link.source,
51 target: link.target,
52 label: {
53 show: true,
54 formatter: link.type
55 }
56 };
57 }),
58 categories: [{
59 name: 'author'
60 }, {
61 name: 'poem'
62 }, {
63 name: 'dynasty'
64 }],
65 roam: true,
66 label: {
67 show: true
68 },
69 force: {
70 repulsion: 100
71 }
72 }]
73 };
74
75 // 使用配置项显示图表
76 chart.setOption(option);
77 </script>
78</body>
79
80</html>
81五、系统测试与优化
(一)功能测试
对系统的各个功能模块进行测试,包括数据采集与预处理、大模型知识抽取、知识图谱构建、查询接口和前端可视化等。确保系统能够正确地采集、抽取、存储和展示古诗词知识图谱数据。
(二)性能测试
使用压力测试工具对系统进行性能测试,模拟多用户并发访问的情况,检查系统的响应时间、吞吐量等性能指标。针对性能瓶颈进行优化,如优化数据库查询语句、使用缓存技术等。
(三)安全测试
对系统进行安全测试,检查是否存在常见的安全漏洞,如SQL注入、跨站脚本攻击(XSS)等。采取相应的安全措施,如输入验证、参数化查询、使用安全框架等,保障系统的安全性。
六、总结与展望
本项目通过结合Django框架与大模型技术,成功构建了一个中华古诗词知识图谱可视化系统。该系统实现了古诗词数据的自动化采集、知识抽取、知识图谱构建和可视化展示,为古诗词研究提供了有力的工具。未来可以进一步优化大模型的知识抽取效果,扩展知识图谱的实体和关系类型,增加更多的交互功能和分析算法,提升系统的实用性和智能化水平。同时,可以考虑将系统推广应用到其他文化领域,如历史、哲学等,促进中华文化的传承和传播。
运行截图
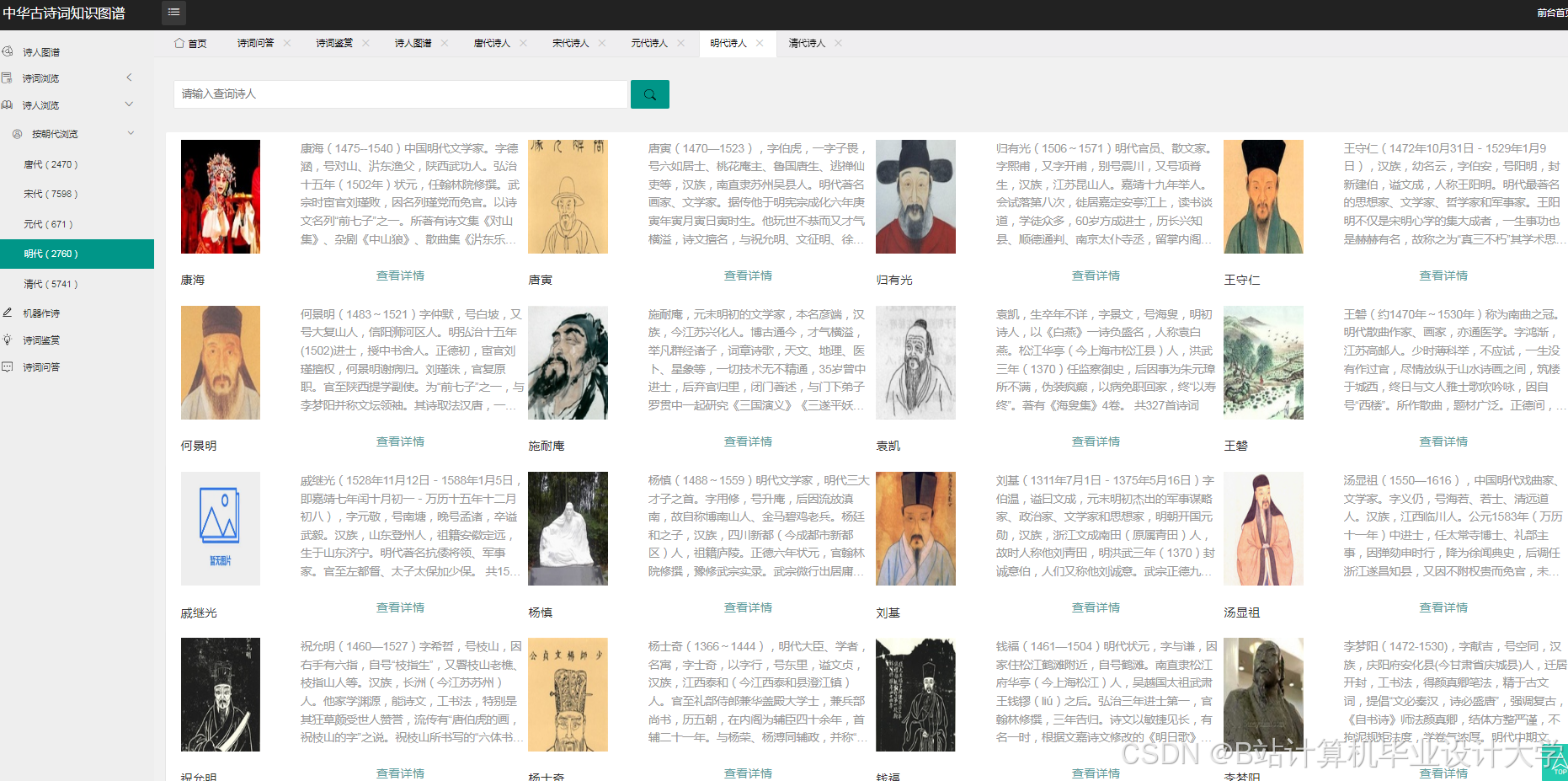
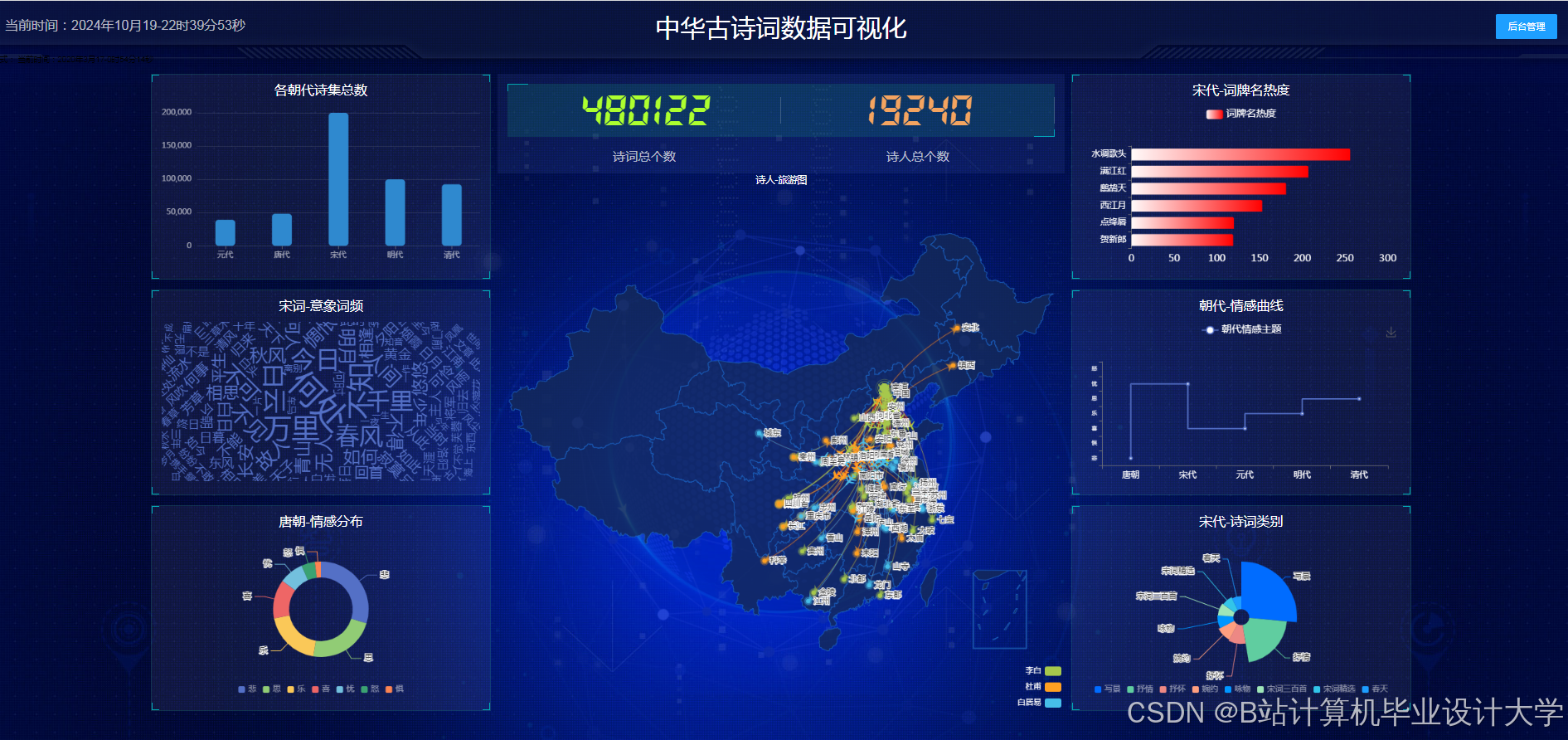
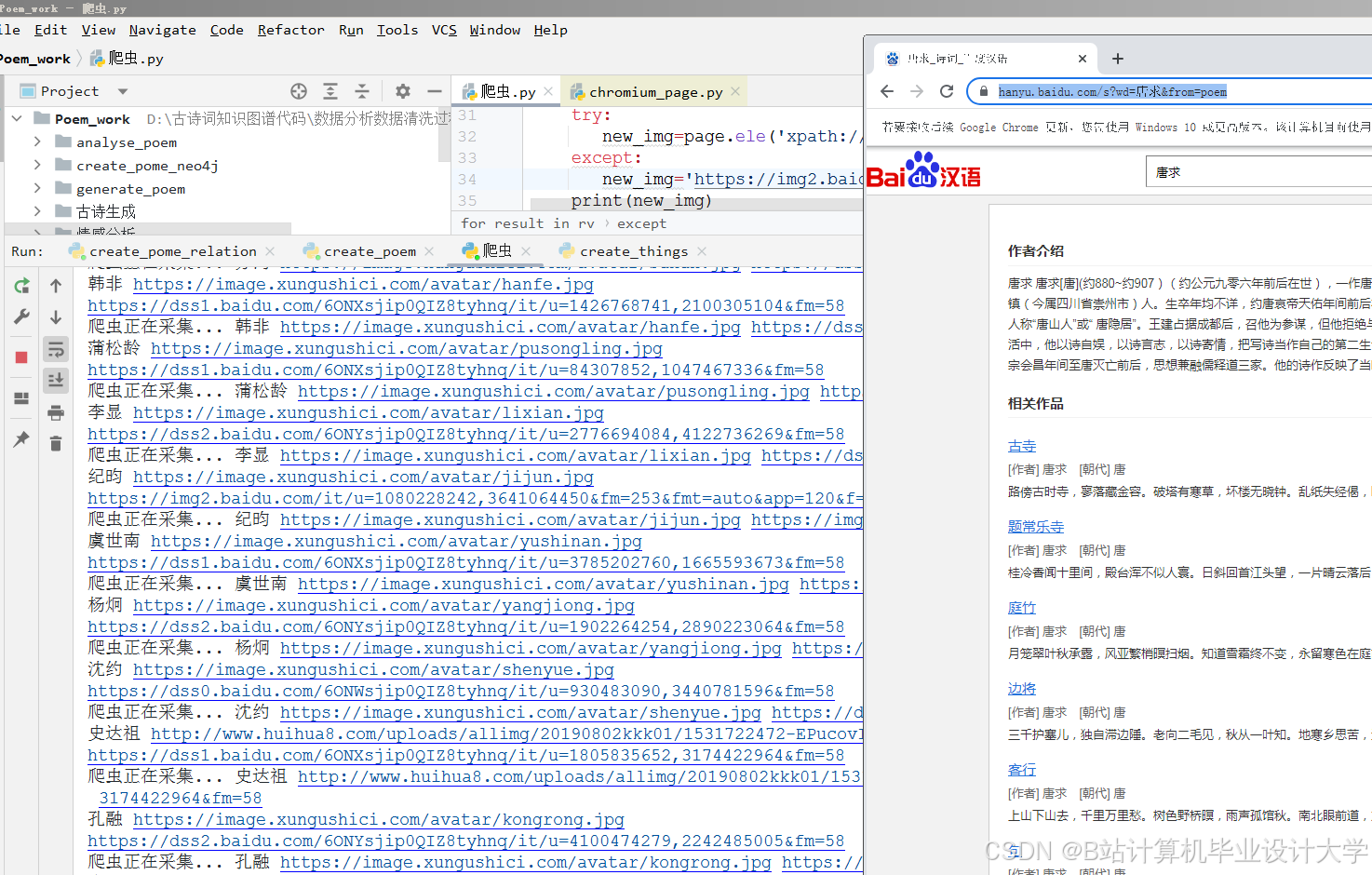
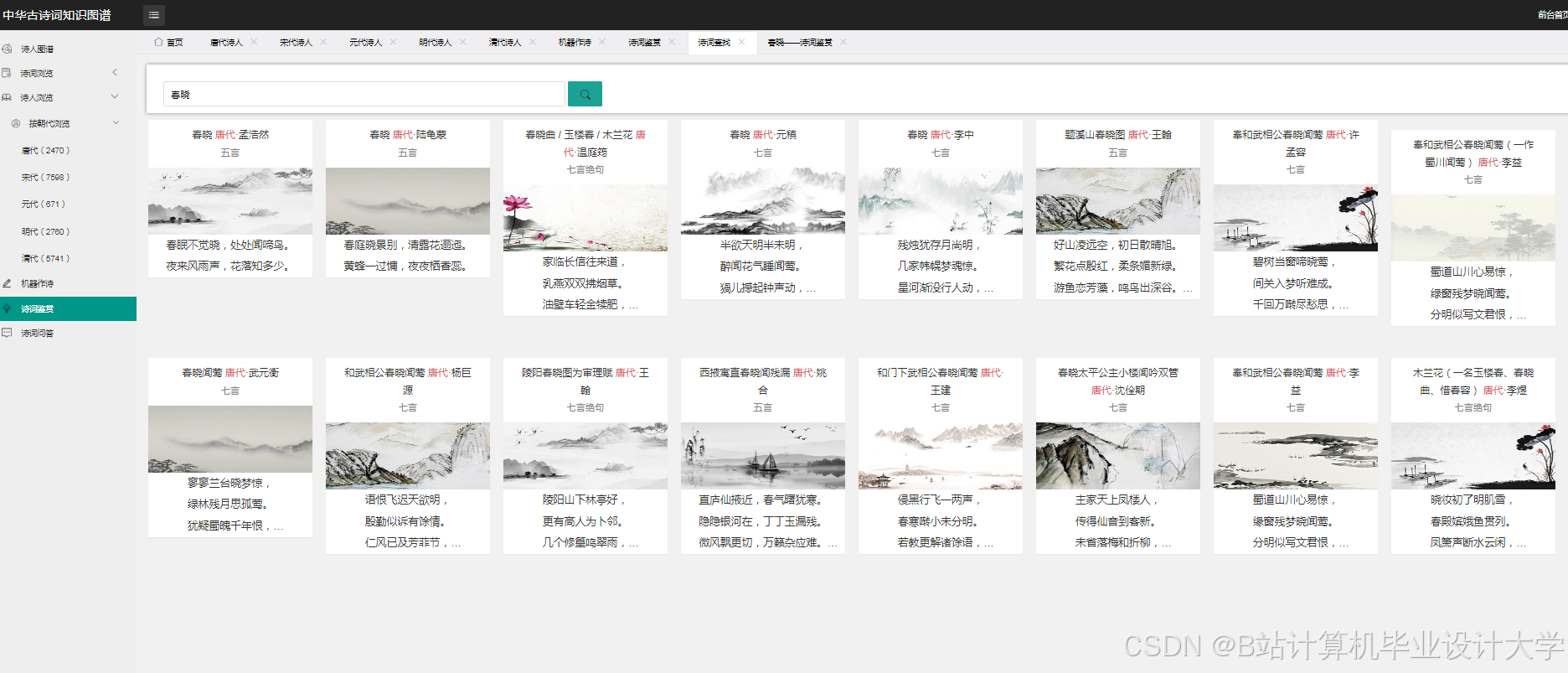
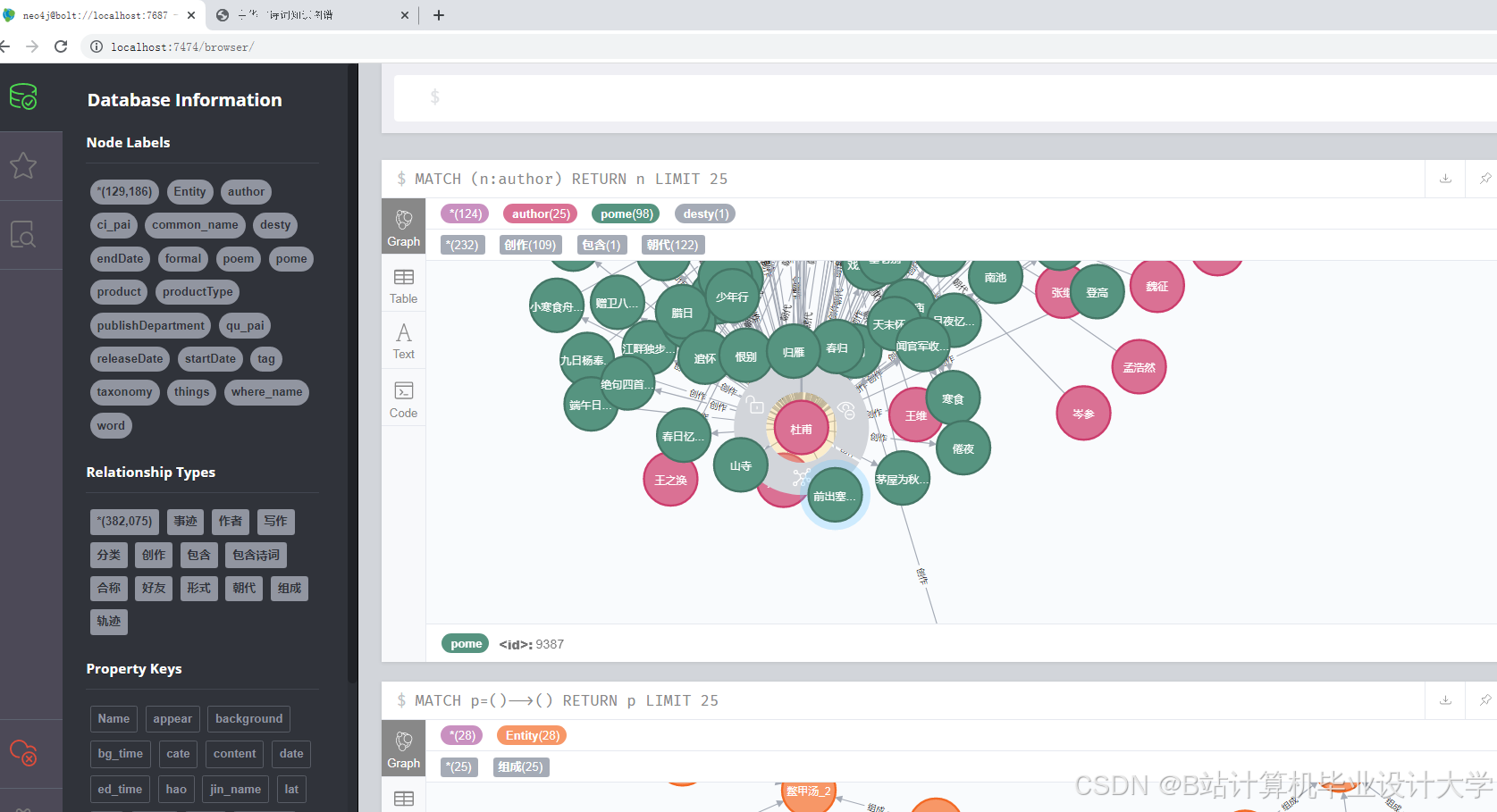
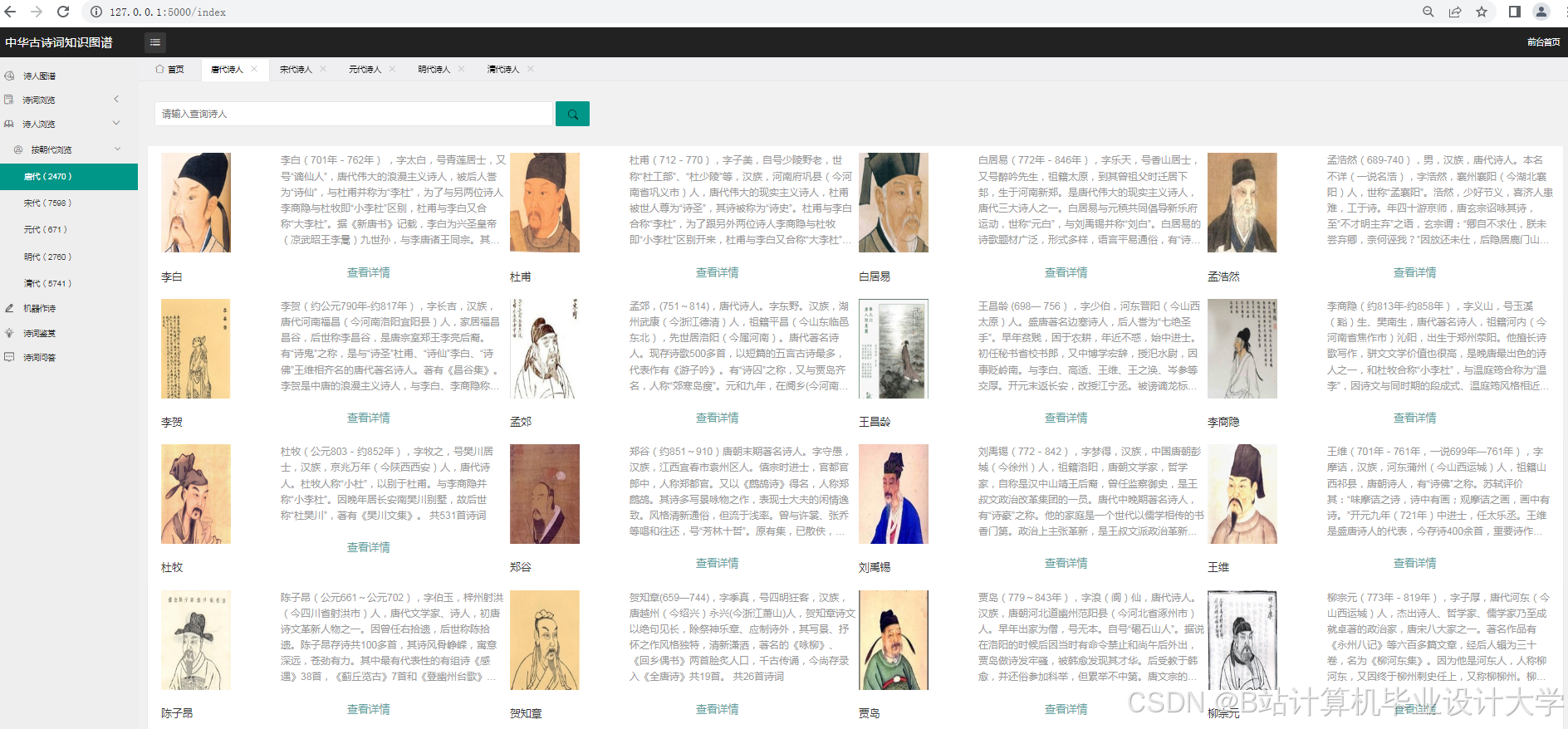
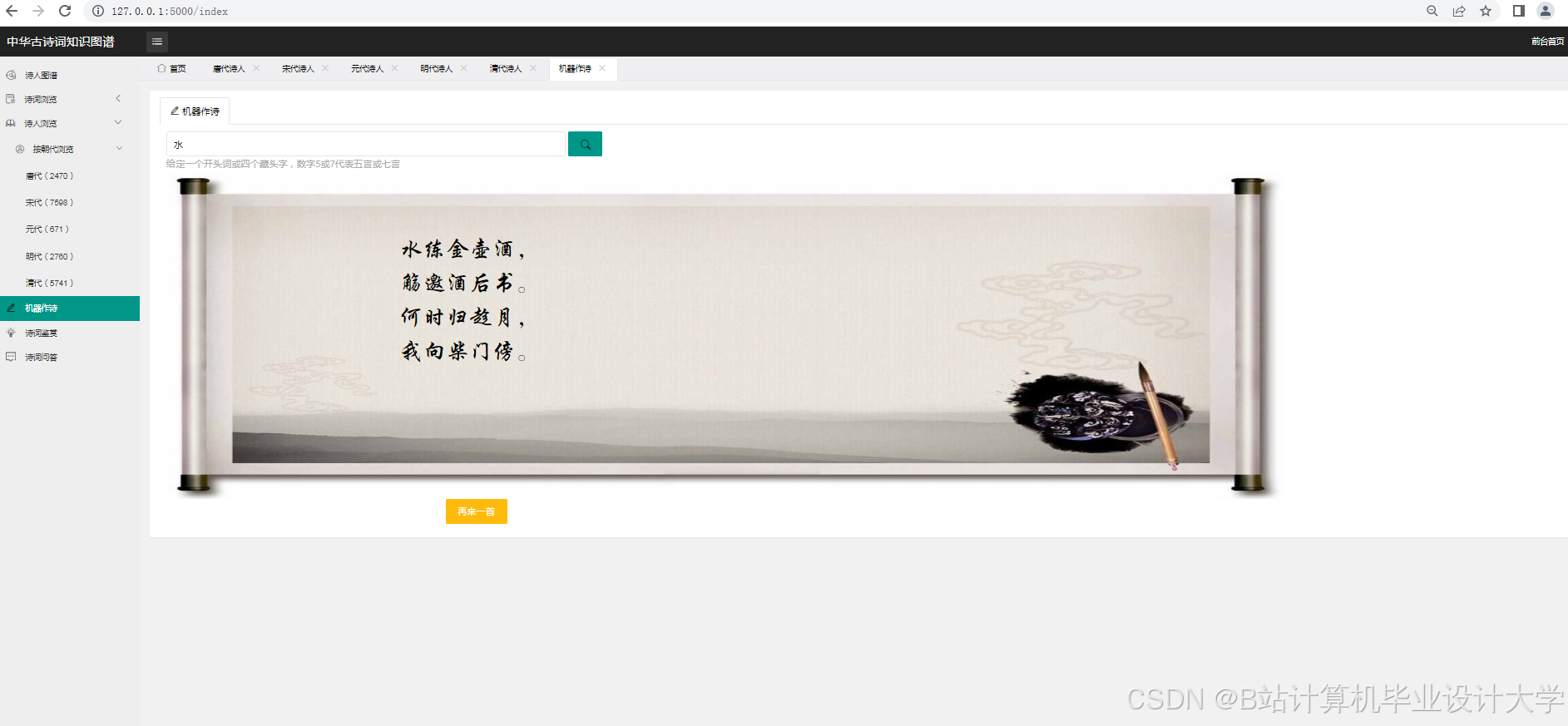
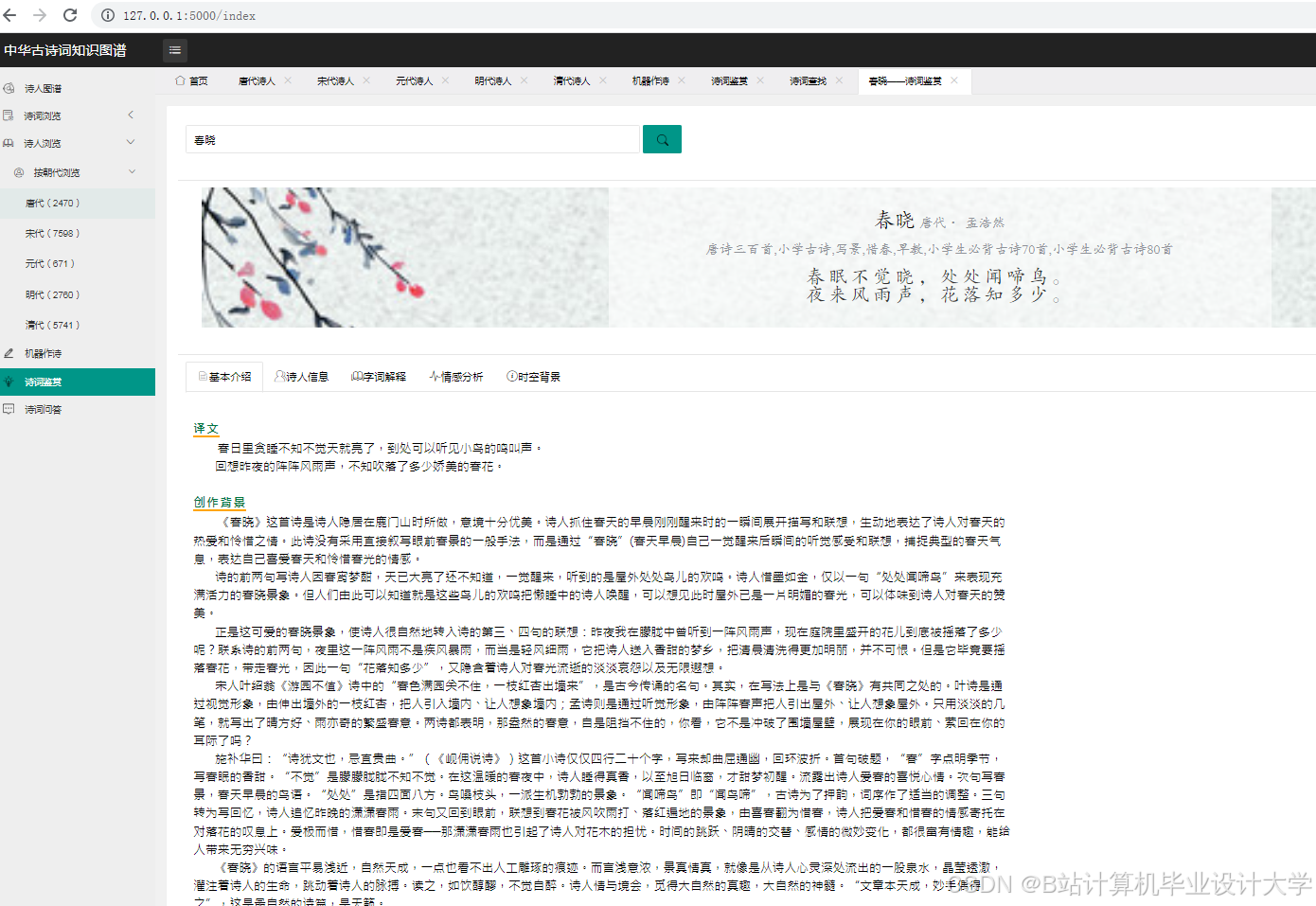
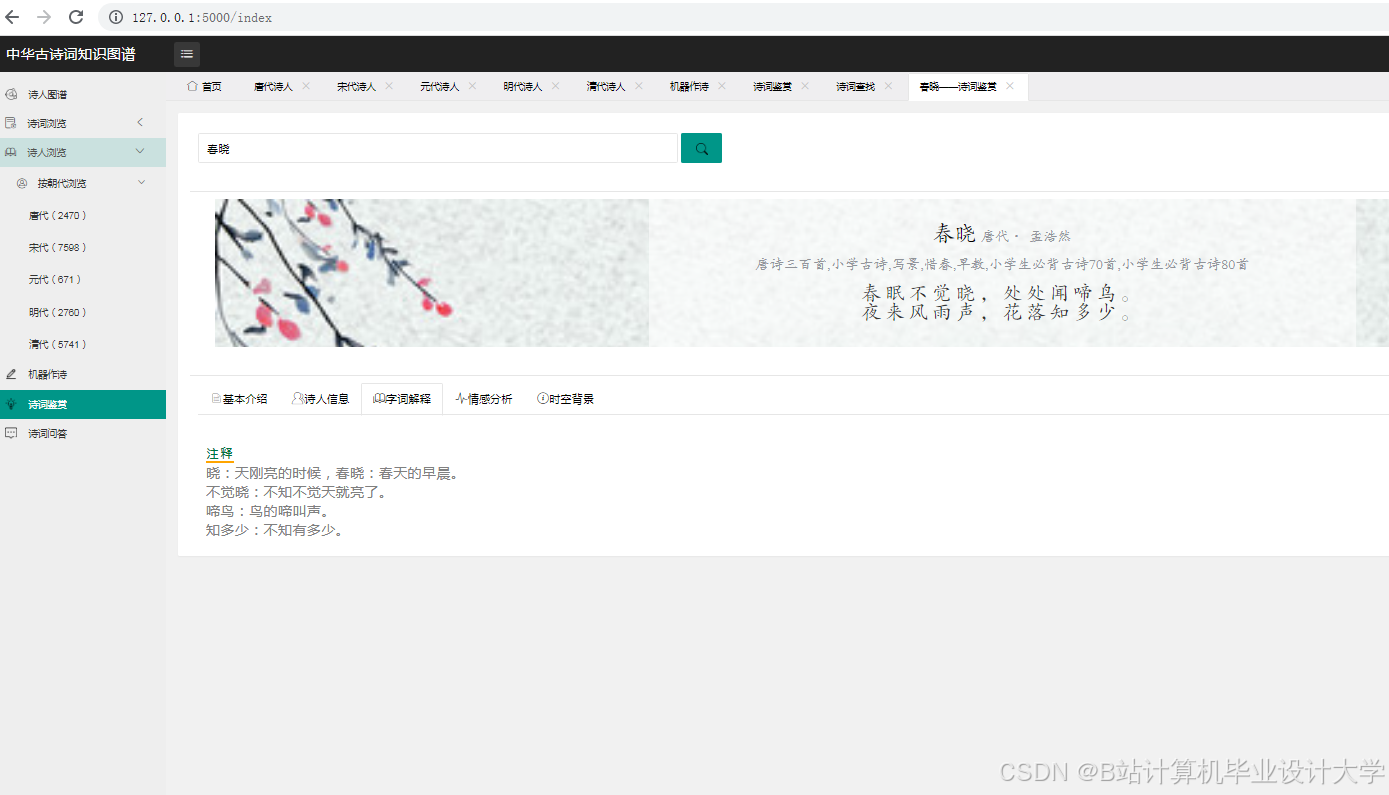
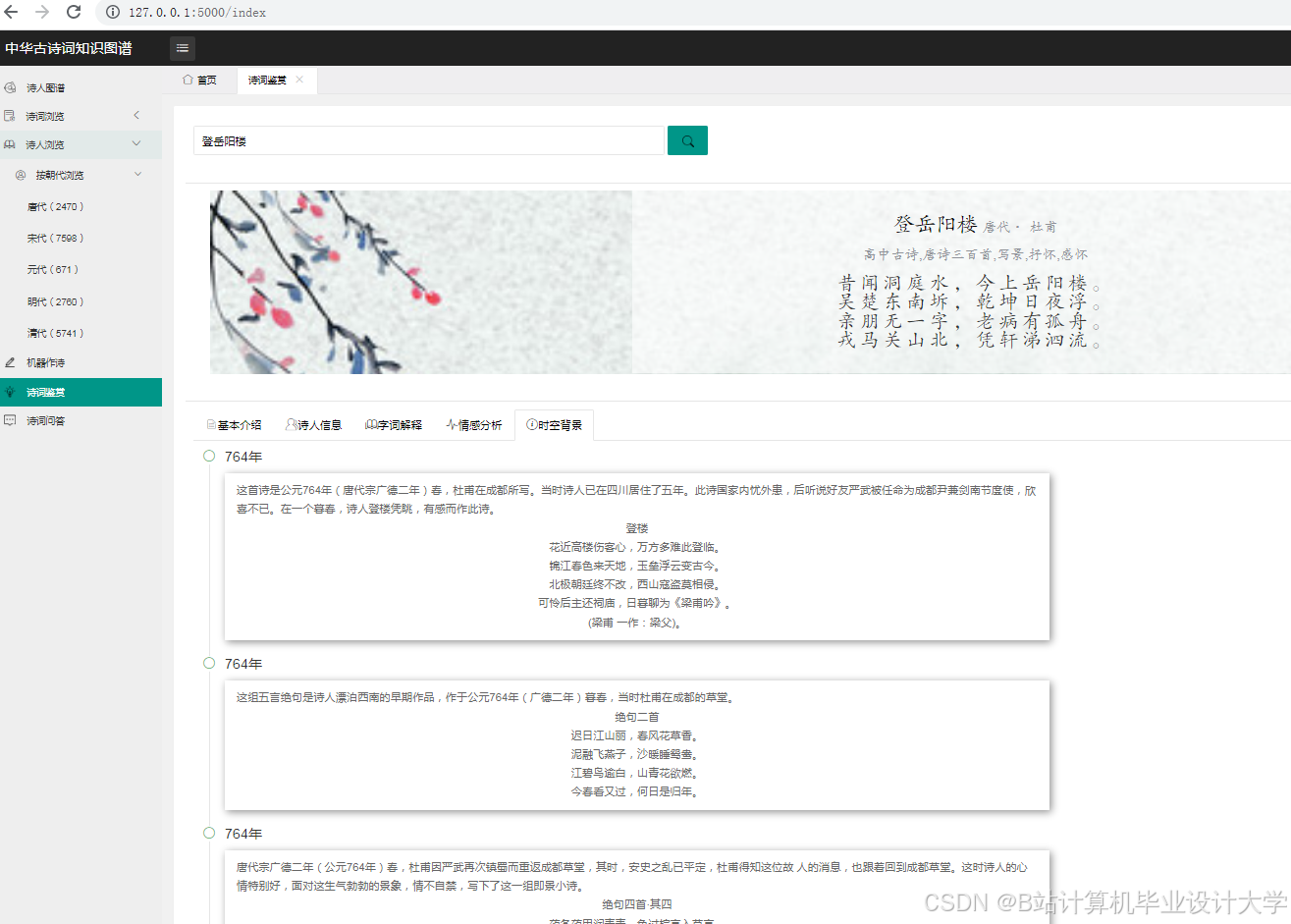
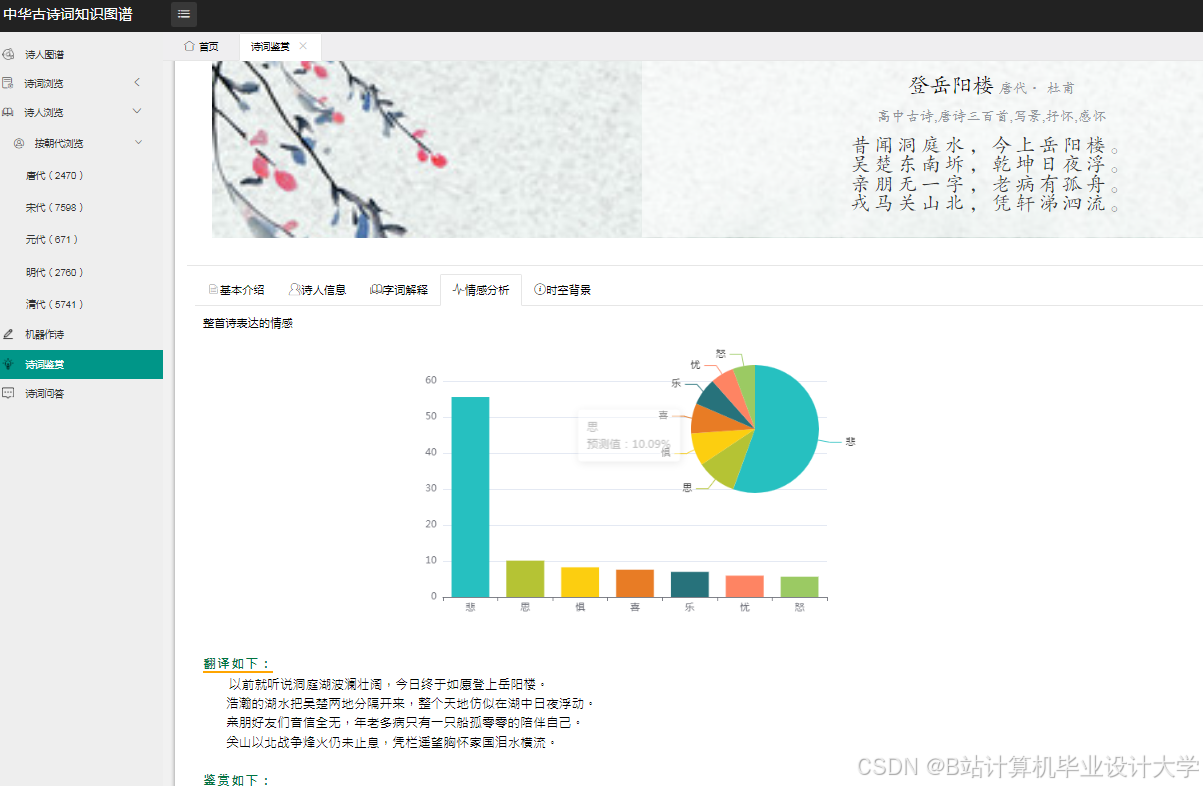
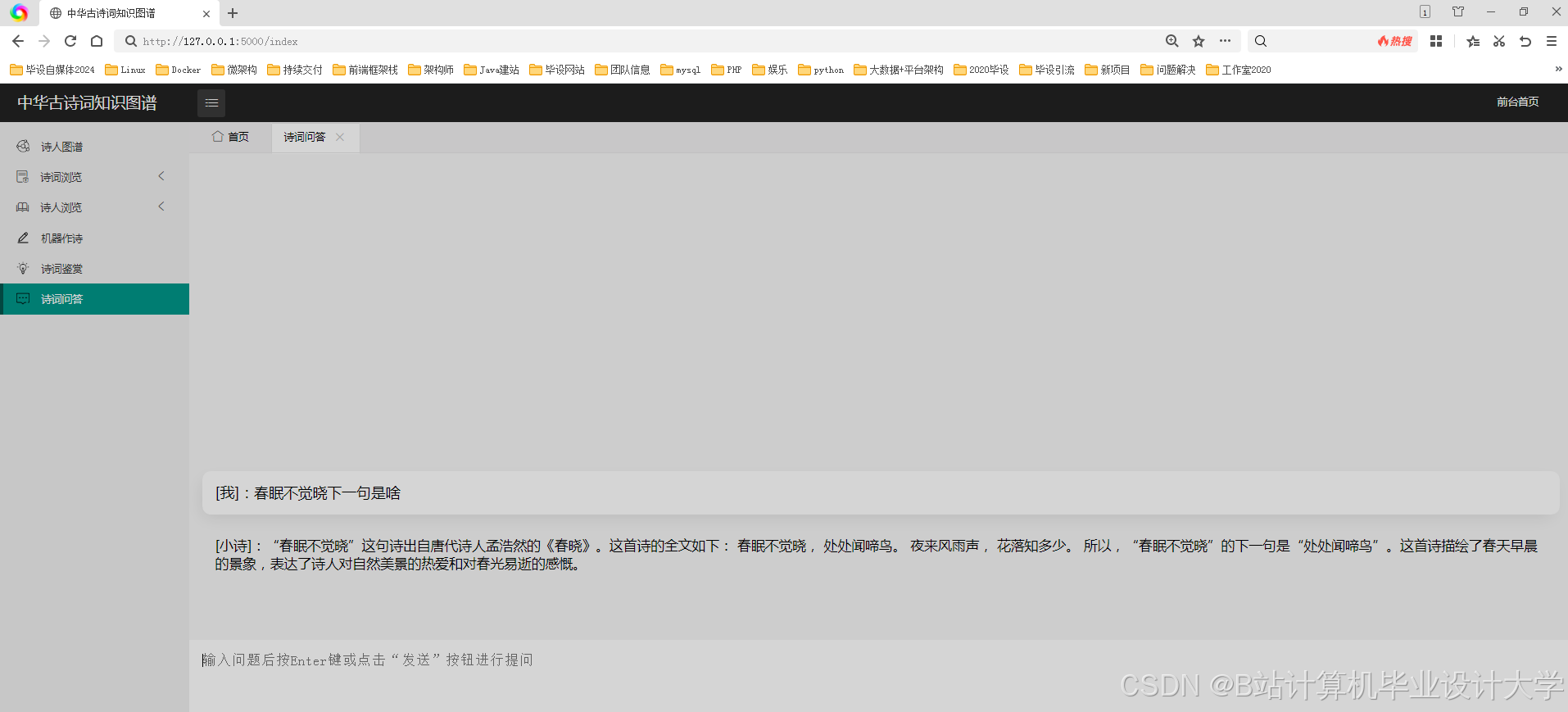
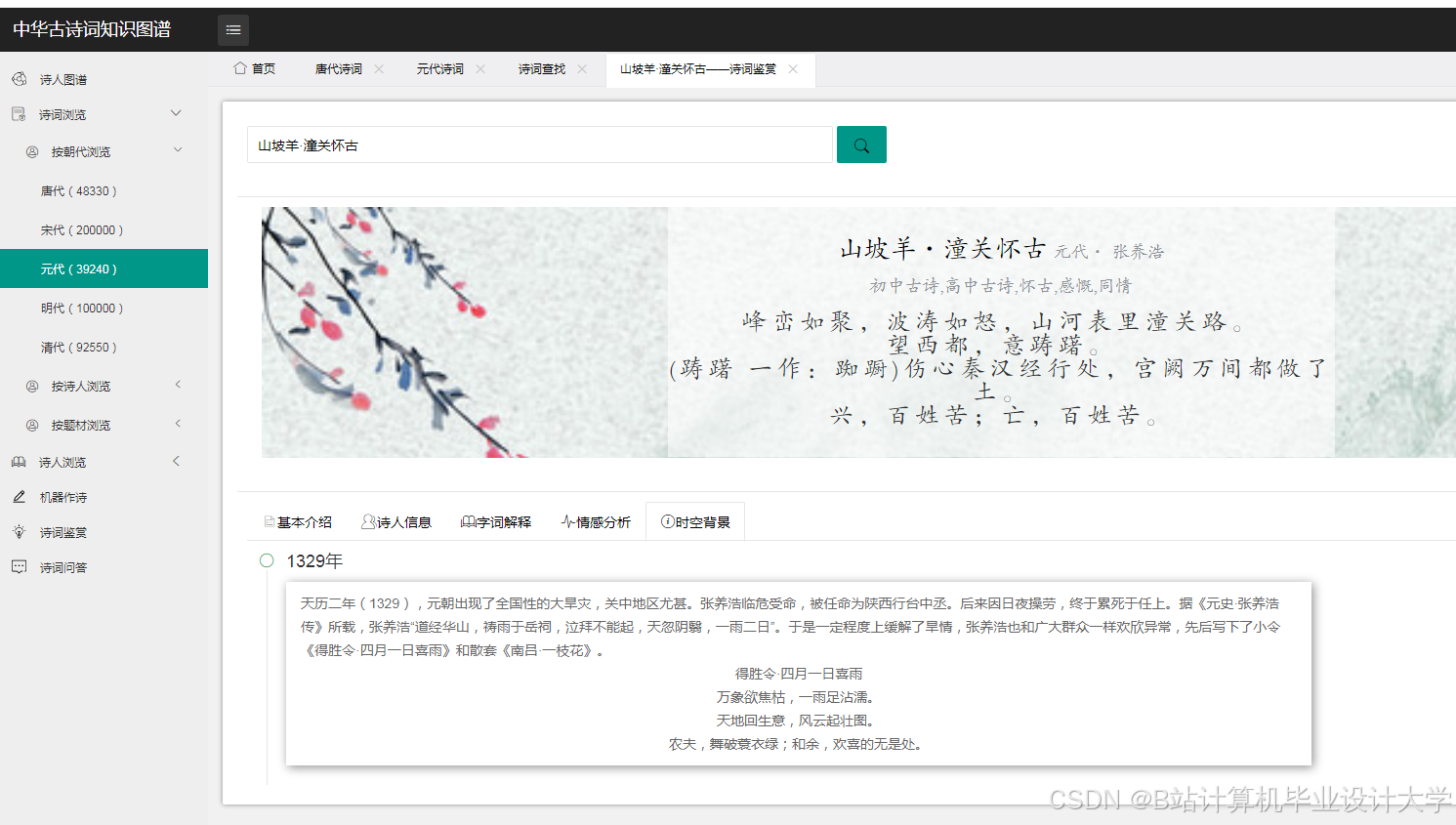
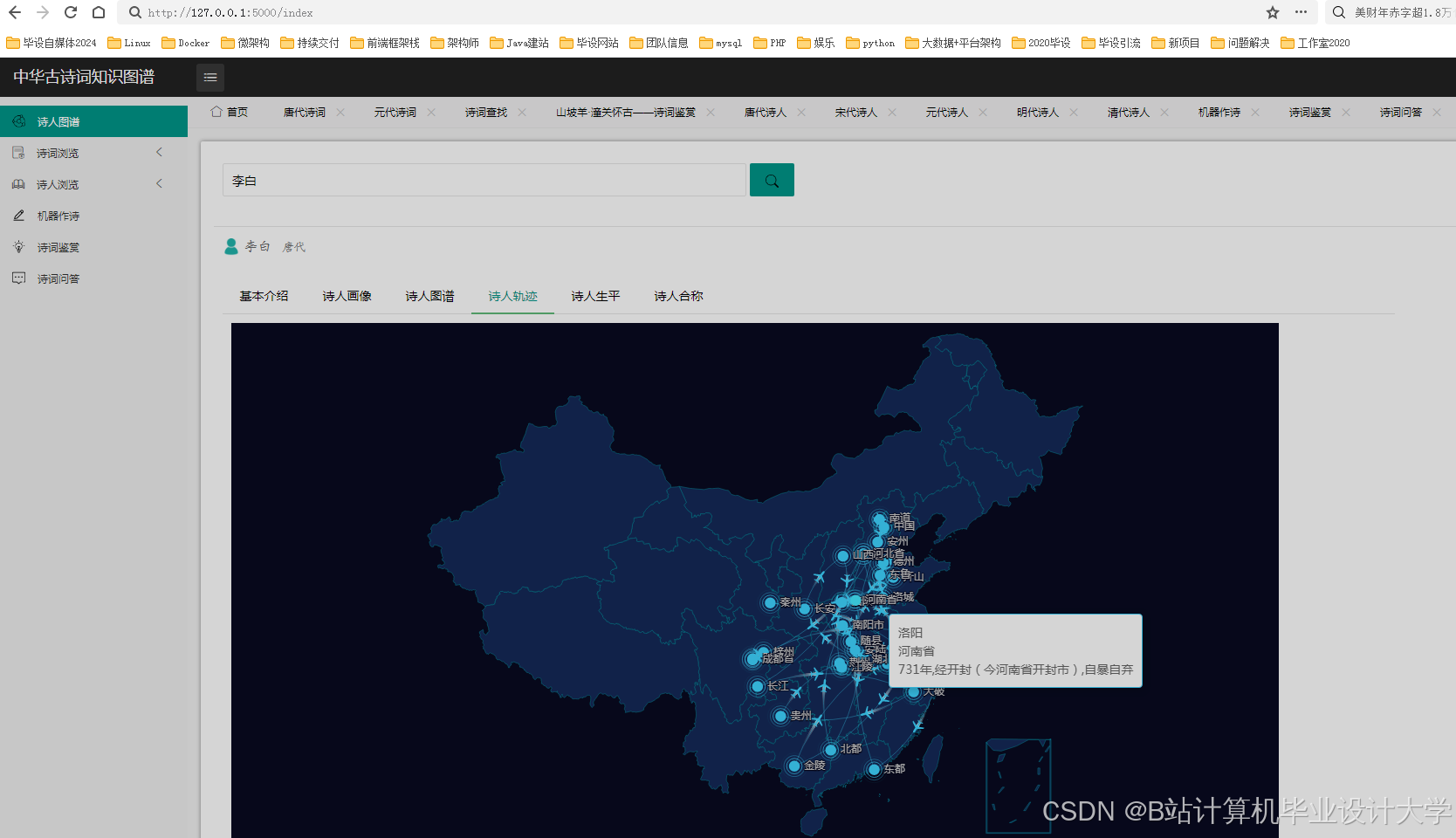
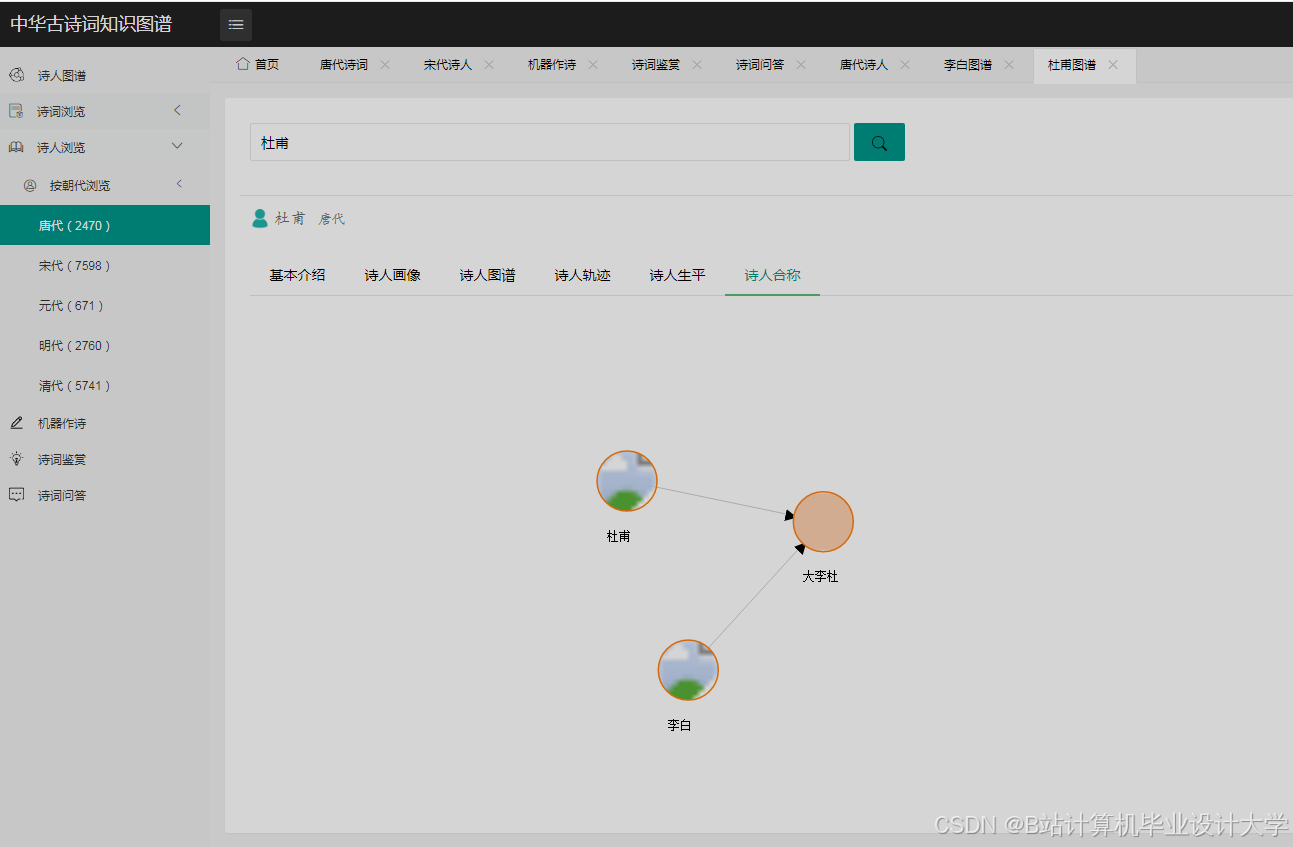
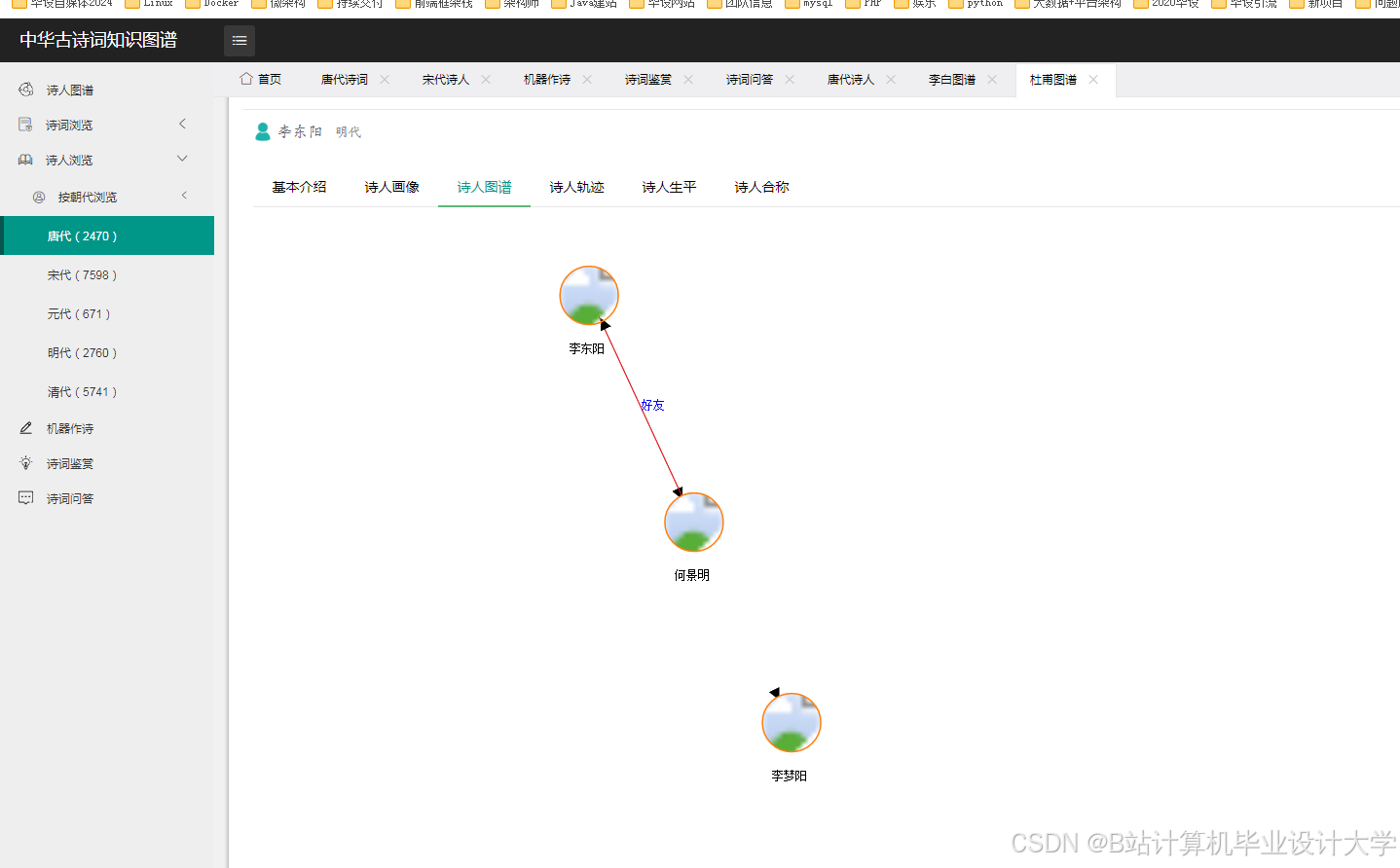
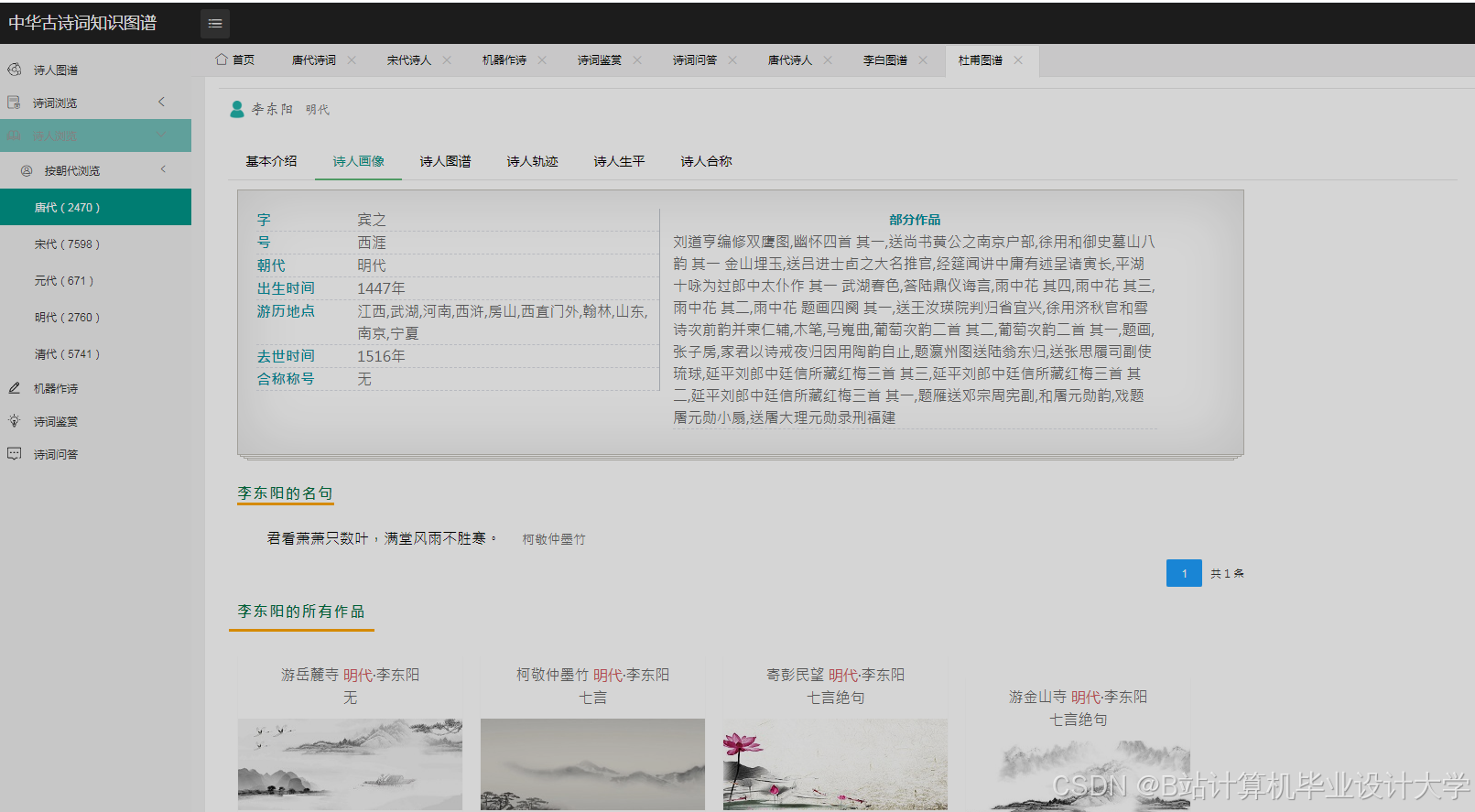
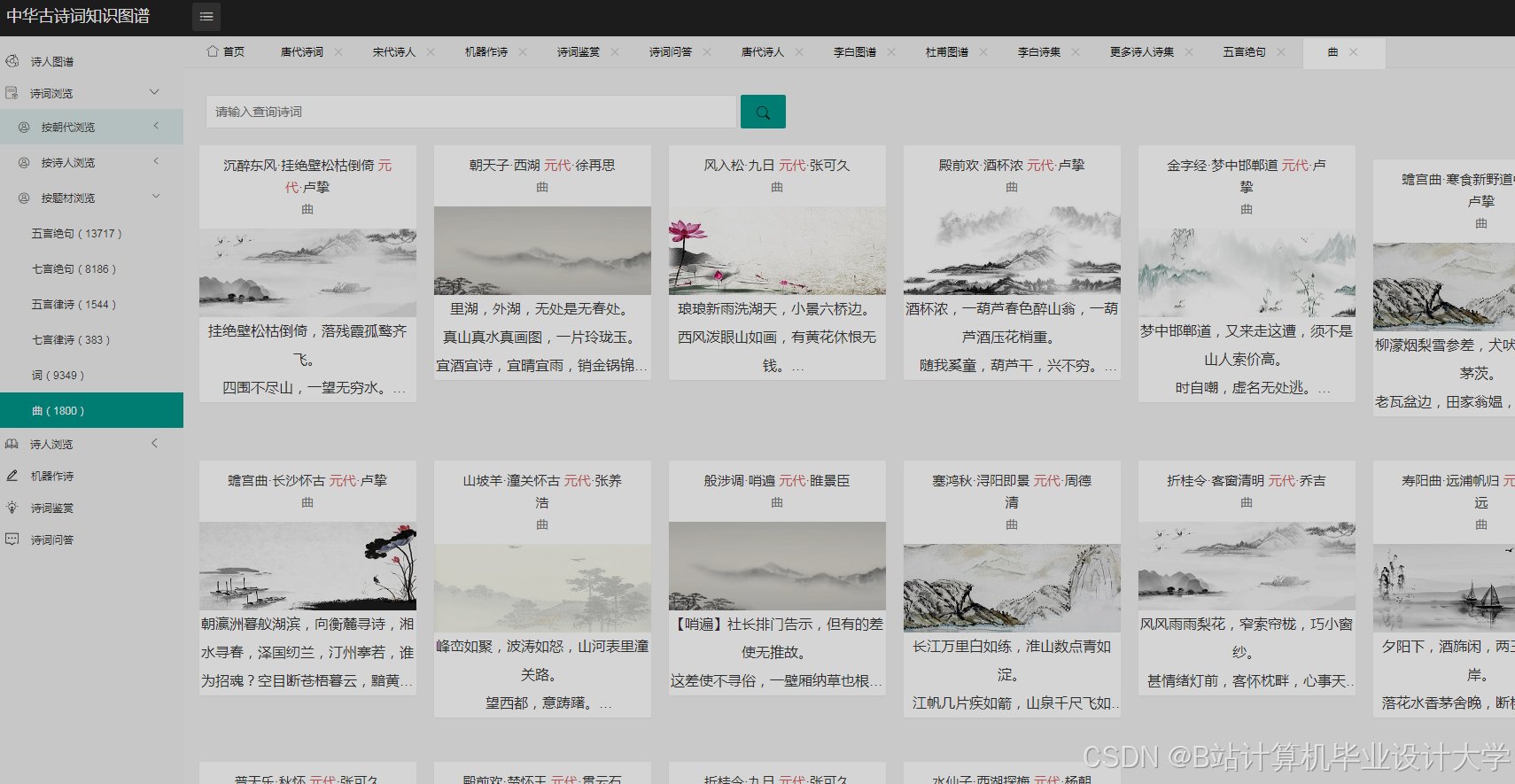
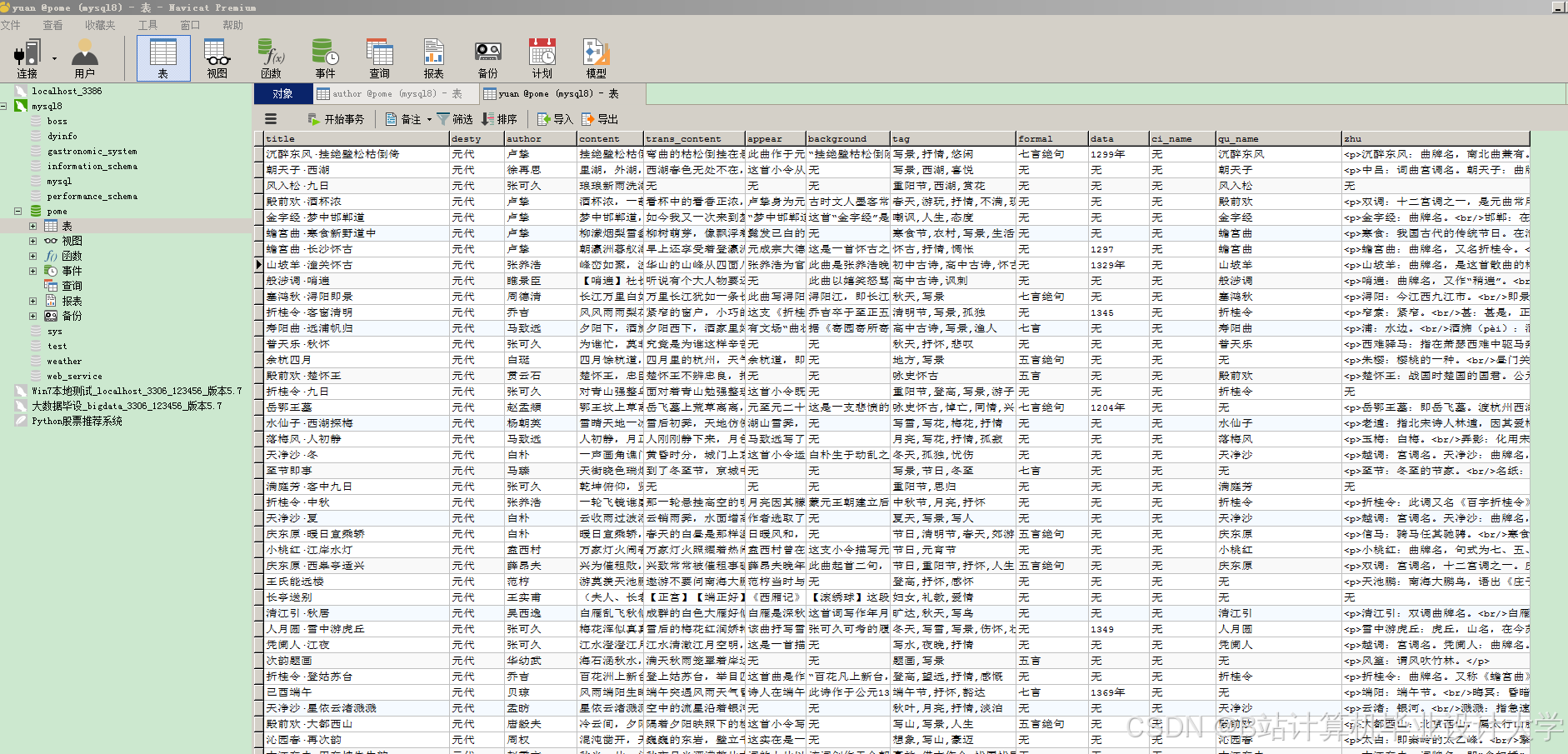
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是CSDN毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是CSDN特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查↓↓↓↓↓↓获取联系方式↓↓↓↓↓↓↓↓

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献277条内容
已为社区贡献277条内容

所有评论(0)