Storm Spout 和 Bolt 详解:构建实时计算的核心积木
·
Storm Spout 和 Bolt 详解:构建实时计算的核心积木
|
🌺The Begin🌺点点关注,收藏不迷路🌺
|
前言
在 Apache Storm 中,任何一个实时计算任务,本质上都是由 Spout 和 Bolt 这两种基础组件搭建而成的。它们就像乐高积木中的基础模块——Spout 负责把数据“拉”进系统,Bolt 负责对数据进行加工处理。只有真正理解这两个组件的职责和协作方式,才能搭建出稳定高效的实时计算应用。
本文将用通俗易懂的语言,配合流程图和代码示例,带你彻底搞懂 Spout 和 Bolt 的作用。
一、快速理解:Spout 是“水龙头”,Bolt 是“加工器”
为了方便记忆,我们可以用一个生活中的流水线来类比:
- Spout(水龙头):想象一个水龙头,它连接着外面的水源(比如 Kafka、数据库、日志文件)。它的任务就是不断地把水(数据)引入到我们的处理车间。
- Bolt(螺栓/加工器):水进入车间后,需要经过各种机器的加工。有的机器负责过滤杂质(过滤),有的负责分装(转换),有的负责贴标签(聚合)。这些“加工机器”就是 Bolt。
二、Spout:数据流的源头
2.1 Spout 的核心职责
Spout 是 Storm 拓扑中唯一能与外部数据源直接交互的组件,它的职责非常明确:
- 连接数据源:建立与消息队列(如 Kafka)、数据库或文件系统的连接。
- 读取数据:持续不断地从数据源拉取数据。
- 发射数据:将读取到的数据封装成 Tuple(元组),发送给拓扑中的 Bolt 进行处理。
- 可靠性回调(可选):当一条数据在整个拓扑中处理成功(
ack)或失败(fail)时,Spout 可以收到通知,从而执行相应的逻辑(如提交偏移量或重发数据)。
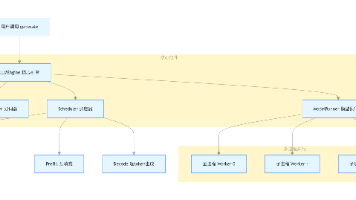
2.2 Spout 的工作流程
2.3 一个简单的 Spout 示例
下面是一个从模拟数据源随机读取句子的 Spout 实现:
/**
* 随机句子生成器 Spout
* 作用:模拟数据源,不断向外发射随机句子
*/
public class RandomSentenceSpout extends BaseRichSpout {
// 用于发射 Tuple 的收集器,必须持有
private SpoutOutputCollector collector;
private Random random;
// 模拟的句子数据池
private String[] sentences = new String[]{
"the cow jumped over the moon",
"an apple a day keeps the doctor away",
"four score and seven years ago",
"snow white and the seven dwarfs"
};
/**
* 1. 初始化方法,Spout 启动时调用一次
*/
@Override
public void open(Map conf, TopologyContext context,
SpoutOutputCollector collector) {
this.collector = collector;
this.random = new Random();
}
/**
* 2. 核心方法!Storm 会循环调用这个方法,要求 Spout 发射数据
* 注意:这个方法不能阻塞,如果没有数据,可以短暂 sleep
*/
@Override
public void nextTuple() {
// 模拟从外部读取数据
String sentence = sentences[random.nextInt(sentences.length)];
// 发射数据,Values 是 Tuple 的值列表
// 第二个参数是消息ID,用于可靠性追踪,如果不关心可靠性可以传 null
collector.emit(new Values(sentence), System.currentTimeMillis());
// 控制发射速度,避免 CPU 空转
Utils.sleep(100);
}
/**
* 3. 定义输出字段的名称
* 下游 Bolt 可以通过 "sentence" 这个名字获取这个字段的值
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("sentence"));
}
/**
* 4. 消息处理成功回调(只有提供了消息ID才会触发)
*/
@Override
public void ack(Object msgId) {
System.out.println("消息处理成功: " + msgId);
}
/**
* 5. 消息处理失败回调
*/
@Override
public void fail(Object msgId) {
System.out.println("消息处理失败: " + msgId);
// 可以在这里实现重发逻辑
}
}
三、Bolt:数据的加工单元
3.1 Bolt 的核心职责
Bolt 是 Storm 拓扑中的“劳模”,所有的计算逻辑都在这里完成。它可以做任何事情:
- 过滤:丢弃不需要的数据。
- 转换:修改数据格式或内容。
- 聚合:对数据进行计数、求和等操作。
- 连接:合并多个数据流。
- 存储:将结果写入数据库或外部系统。
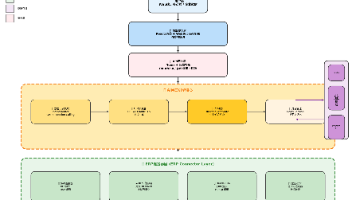
3.2 Bolt 的工作流程
3.3 一个简单的 Bolt 示例
下面是一个分词 Bolt,它接收句子,拆分成单词后发射给下游:
/**
* 分词 Bolt
* 作用:接收句子,拆分成单词后逐个发射
*/
public class SplitSentenceBolt extends BaseRichBolt {
private OutputCollector collector;
/**
* 1. 初始化方法,Bolt 启动时调用
*/
@Override
public void prepare(Map conf, TopologyContext context,
OutputCollector collector) {
this.collector = collector;
}
/**
* 2. 核心方法!每当有一个 Tuple 到达时,此方法被调用
*/
@Override
public void execute(Tuple tuple) {
try {
// 获取上游发送过来的句子
String sentence = tuple.getStringByField("sentence");
// 分词
String[] words = sentence.split(" ");
// 发射每个单词
for (String word : words) {
// 锚定:传入输入的 tuple,建立血缘关系
collector.emit(tuple, new Values(word));
}
// 确认处理成功
collector.ack(tuple);
} catch (Exception e) {
// 处理失败,要求重发
collector.fail(tuple);
}
}
/**
* 3. 定义输出字段
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
四、Spout 和 Bolt 的协同工作
理解了单个组件后,我们来看它们如何协作完成一个完整的词频统计任务。
4.1 词频统计拓扑图
4.2 完整拓扑代码
public class WordCountTopology {
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
// 1. 设置 Spout:1个任务,随机产生句子
builder.setSpout("spout", new RandomSentenceSpout(), 1);
// 2. 设置第一个 Bolt:分词器,4个任务,随机接收句子
builder.setBolt("split", new SplitSentenceBolt(), 4)
.shuffleGrouping("spout"); // 随机分发
// 3. 设置第二个 Bolt:计数器,6个任务,按单词分组
// Fields Grouping 确保相同单词进入同一个 Bolt 任务
builder.setBolt("count", new WordCountBolt(), 6)
.fieldsGrouping("split", new Fields("word"));
// 4. 设置第三个 Bolt:打印结果,1个任务
builder.setBolt("print", new PrintBolt(), 1)
.shuffleGrouping("count");
// 5. 配置并提交
Config conf = new Config();
conf.setDebug(false);
conf.setNumWorkers(3); // 使用3个Worker进程
// 本地模式运行(方便测试)
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("word-count", conf, builder.createTopology());
// 运行60秒后停止
Thread.sleep(60000);
cluster.shutdown();
}
/**
* 计数 Bolt(简单版,不考虑窗口)
*/
static class WordCountBolt extends BaseRichBolt {
private OutputCollector collector;
private Map<String, Integer> counts = new HashMap<>();
@Override
public void prepare(Map conf, TopologyContext context,
OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String word = tuple.getStringByField("word");
Integer count = counts.getOrDefault(word, 0) + 1;
counts.put(word, count);
// 发射结果
collector.emit(tuple, new Values(word, count));
collector.ack(tuple);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
}
}
/**
* 打印 Bolt
*/
static class PrintBolt extends BaseRichBolt {
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context,
OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String word = tuple.getStringByField("word");
Integer count = tuple.getIntegerByField("count");
// 打印到控制台
System.out.println("【结果】 " + word + " : " + count);
collector.ack(tuple);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// 不需要输出
}
}
}
五、最佳实践与常见陷阱
5.1 Spout 开发要点
| 要点 | 说明 |
|---|---|
| 不要阻塞 | nextTuple() 方法不能长时间阻塞,没有数据时请 sleep(1) |
| 可靠追踪 | 如果业务要求数据不丢,发射时一定要传入消息ID,并实现 ack 和 fail |
| 流量控制 | 通过 conf.setMaxSpoutPending() 限制 Spout 最大未处理消息数,避免压垮下游 |
5.2 Bolt 开发要点
| 要点 | 说明 |
|---|---|
| 务必调用 ack/fail | 每个接收到的 Tuple 最终都必须调用 ack 或 fail,否则会导致内存泄漏 |
| 锚定发射 | 在 Bolt 中发射新 Tuple 时,尽量传入输入的 Tuple(锚定),以保证消息血缘链完整 |
| 注意状态大小 | 在 Bolt 中维护状态(如计数器)时,要考虑状态会无限增长,必要时加窗口或定期清理 |
5.3 常见错误示例
// ❌ 错误1:忘记调用 ack
public void execute(Tuple tuple) {
process(tuple); // 处理完就完了,没有 ack
// 后果:消息永远不会被确认,Spout 会认为消息还在处理中,最终超时失败
}
// ❌ 错误2:未锚定发射
public void execute(Tuple tuple) {
collector.emit(new Values(word)); // 没有传入 tuple
collector.ack(tuple);
// 后果:发射的新 Tuple 与输入的 Tuple 没有血缘关系,如果下游处理失败,上游不会重发
}
// ❌ 错误3:无限增长的状态
Map<String, Integer> state = new HashMap<>();
public void execute(Tuple tuple) {
state.put(key, state.getOrDefault(key, 0) + 1); // 永远不清理
// 后果:内存溢出
}
总结
Spout 和 Bolt 作为 Storm 最基础的构建块,通过清晰的职责划分和灵活的协作机制,共同构建了强大的实时数据处理能力:
| 组件 | 核心职责 | 关键方法 | 设计要点 |
|---|---|---|---|
| Spout | 从外部系统读取数据,发射 Tuple | open, nextTuple, ack, fail |
非阻塞读取、可靠性追踪、流量控制 |
| Bolt | 接收 Tuple,执行处理逻辑 | prepare, execute, cleanup |
及时 ack/fail、锚定发射、状态管理 |
理解这两个组件,就等于拿到了构建 Storm 应用的钥匙。无论多么复杂的实时计算任务,最终都可以分解为一个个 Spout 和 Bolt 的组合。
思考题:如果希望实现一个“每5分钟统计一次热门商品”的功能,你觉得应该在 Bolt 中如何设计?欢迎在评论区分享你的思路!

|
🌺The End🌺点点关注,收藏不迷路🌺
|

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 2
2 0
0- 0



 已为社区贡献44条内容
已为社区贡献44条内容

所有评论(0)