FSCA-YOLO: An Enhanced YOLO-Based Model for Multi-Target Dairy Cow Behavior Recognition
目录
Title
标题:
FSCA-YOLO: An Enhanced YOLO-Based Model for Multi-Target Dairy Cow Behavior Recognition
一种增强型YOLO模型用于多目标奶牛行为识别
作者:
龙挺 1,†, 余荣川 1,†
Simple Summary
精准奶牛养殖中,准确的识别牛的行为对于健康检测和牛群管理至关重要,然而,复杂的畜舍环境和牛之间的高相似性给行为识别系统带来了挑战。提出了一种基于YOLOv11的增强型多行为识别模型。通过集成特征增强模块和注意力机制,该模型提高了复杂场景中的特征识别能力,在检测牛群进食、饮水、站立和躺卧行为方面取得了更高的准确率
Abstract
提出方法:
- 在yolov11 中添加何FEM-SCAM模块和CoordAtt机制,使模型更好地聚焦于牛的有效行为特征,同时抑制无关的背景信息。
- 增加了一个小目标检测头,以增强模型识别相机视角远处发生的牛行为能力
- 使用SIoU损失函数替换了原始损失函数,提高识别准确率并家属模型收敛
结论:
与主流目标检测模型相比,改进模型在精确度、召回率和平均精确度均值,方面,达到了95.7%的精度、92.1%的召回率和94.5%的mAP,分别比基准YOLOv11模 型提高了1.6%、1.8%和2.1%
Conclusion
Introduction
-
第一段:背景介绍:奶牛的日常健康和行为识别是农场管理中的关键任务。
-
第二段:奶牛识别的技术发展:传感技术开发促进了行为识别的进步。可穿戴系统可以准确监控关键牛行为。
-
第三段:计算机视觉技术的优点:更高精准和效率识别牛行为。VGG16‐BiLSTM框架识别五种关 键行为,实现了高准确率。YOLOv4开发了CowXNet用于发情检测。应用背景减除 和帧差分技术,以94.4%的准确率监测犊牛‐环境交互。YOLOv8n(E‐YOLO),在发情行为检测中达到了93.9%的准确率。但是这些方法大多针对特定行为,在复杂农场环境下鲁棒性不足。
-
第四段:行为识别的发展:九种牛行为数据集的提出,yolov8n-BIF-DSC模型扩展感受野并使用注意力增强距离上下文建模,后来进一步发展将行为识别扩展到多目标识别的追踪。
-
第五段:目前的挑战:行为识别能力需要应对复杂的农场环境。奶牛经常在狭窄的饲槽处重叠,身体和头部被其他奶牛或栏杆阻挡 ;密集群体频繁聚集在饮水槽周围,导致严重的目标重叠;躺卧的奶牛部分被卧床结构遮挡,
Related Work
已往的研究有通过牛嘴的纹理进行检测的,但是这些图像不好收集。后面也有通过视网膜、面部和身体检测,这些都需要专业设备和技术成本高
2.1. Automated Cattle Biometrics
通过牛背部特征进行检测的文章很少,所以我们通过这种方式作为生物特征进行研究区分。
2.2. Deep Object Detection
一阶段检测器:SSD和YOLO,它们在一个前馈网络内推断类别概率和边界框偏移
二阶段检测器:Faster R-CNN和Cascade-RCNN,先预处理图像后对这些区域进行分类和调增边界框。
本文使用RetinaNet进行研究,因为他解决了类别不平衡的问题,通过焦点损失替代传统的交叉熵损失进行分类
2.3. Open-Set Recognition
开放集识别:自动重新识别以前从未见过的个体。
随着深度学习和神经网络的性能提升,开放集识别也随之发展。研究使用开放集损失函数公式而不是softmax。
本文的研究方法是学习训练集中每一头牛的潜在表示,形成一种嵌入(embeding),让它能够超越特定的训练群体的视觉特性,概括该品种的视觉特性。
Dataset: OpenCows2020
该数据集包含了室内和室外的鸟瞰图
该数据集分为两部分:
1、牛只检测和定位,设计的第一阶段
2、开放集识别,设计的第二阶段
3.1 Dataset construction
数据集图像中有手动标注的牛群区域,涵盖了牛舍和户外设置。该数据集一共3707张图片,包含了6917个牛的标注。眉头牛我们手动标注了一个边界框,围绕动物的躯干。为了更好的交叉验证,图像被随机打乱并分成10个折叠,按照8:1:1用于训练、验证和测试
3.2. Identification
数据集第二组成部分由检测图像集中识别牛组成。为了确保每种牛至少有9张训练图片,1张验证图片和10张测试图片,所以实例少于20的个体都被丢弃,最后总共46个个体,平均每个类别有103个实例,整体有4736个区域。每个类别内的图片被随机划分,确保所有个体恰好有10个测试实例。剩余图片按照9:1的比例划分训练集和验证集。
可观察到的是获取方法、周围环境和背景、照明条件等方 面的变化。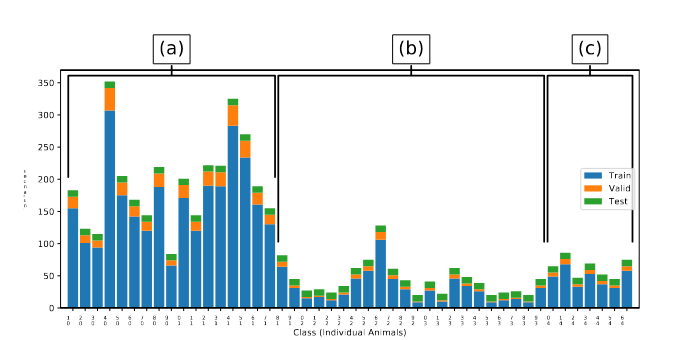
随机将实例拆分,以确保每个类别恰好有10个测试实例,而剩余的实例则以9:1的 比例拆分为训练和验证集。
Cattle Detection
研究的第一阶段是自动稳定地检测和定位相关图像中的弗里斯牛。我们希望训练一个通用的牛检测器,对某些图像的输入,我们接受到一组边界框坐标,及置信分数,作为输出。
在这里插入图片描述
4.1. Detection Loss
RetinaNet由一个主干特征金字塔网络组成,后面跟着两个特定任务的子网络 。一个子网络使用焦点损失对主干的输出进行对象分类,另一个子网络回归边界框位置。为了实现焦点损失,我们首先为方便定义pt如下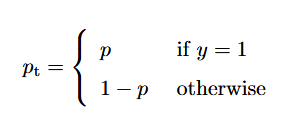
其中 y ∈ {±1} 是真实值,而p是当y=1时的估计概率。对于检测,我们需要将牛与背景分开,这是一个二分类问题,所以焦点损失被定义为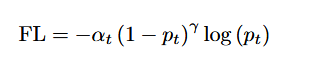
log(pt)是二元分类的交叉熵,r是平衡易/难样本的调节因子,α可以平衡正例/负例样本的数量。焦点损失函数确保训练过程首先关注正样本和坤年样本
回归子网络预测四个参数((Px1 , Py1), (Px2 , Py2 ))表示锚框A
真实框Y之间的偏移坐标((x1, y1), (x2, y2))。它们的真实偏移((Tx1 , Ty1), (Tx2 , Ty2 ))可以表达为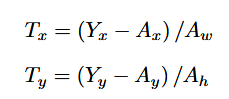
其中 Y 是真实边界框,A 是锚框。边界框的宽度和高度由 w 和 h 给出。回归损 失可以定义为: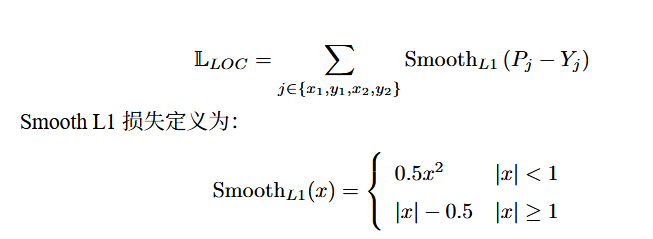
总体而言,检测网络最小化一个组合损失函数,该函数结合了与位置和分类 分别相关的平滑L1损失和焦点损失组件。
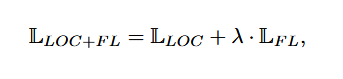
4.2. Experimental Setup
用ResNet-50作为特征金字塔
权重在ImageNet预训练
检测物体的先验概率(π=0.01)
锚点在特征金字塔网络的5层中实现
每层面积从32×32 到512×512
长宽比1:2,1:1和2:1
batch=4
随机梯度下降的初始学习率=1×10的5次方
动量=0.9
权重衰减为1×10的-4次方
为了与其他基线进行适当的比较,以下部分对两个流行且开创性的架构–YOLOv 3 和Faster R-CNN --进行了交叉验证(在相同的数据集和拆分上)。
4.3.Baseline Comparisons and Evaluation
平均精确率作为性能比较指标,每个网络是通过计算每个交叉验证中精确度-召回率曲线下的面积的平均值得出来的。从表中可以看出,所有方法在检测任务上都达到了很好的效果,具体参数选择包括置信度得分为0.175,非最大抑制NMS阈值为0.28,交并比阈值为0.5。虽然置信度和IoU阈值在目标检测中常被使用,但 我们故意选择了一个较低的NMS阈值,这在以下段落中得到了证实。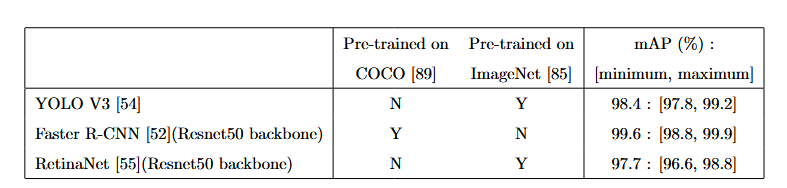
下图描绘了检测失败的案例,a,b由于根据VOC标注指南在物体可见性/遮挡方面进行的图像便捷裁剪导致的。大多数情况下可以通过忽略便捷区域来避免,d中检测器对两头相邻的牛中间部分给出了高的置信度,通过NMS消除两个实际的预测框,在e中,错误检测由紧邻的牛和NMS导致的,牛中间相近他们的真实框重叠越大
Open-Set Individual Identification via Metric Learning
我们希望通过无需手动标记新个体和完全重新训练一个封闭集分类器的方式区分个体。
关键思想是学习一个映射到类别独特的潜在空间,在这个空间中,相同个体图像被聚集在一起。这种特征嵌入编码了输入的潜在表示,而对于图像来说,也相当于从矩阵width×height×channels到大小为IRn的嵌入的显著维度降低,n是嵌入空间的维度。在潜在空间中,距离直接编码输入相似性,因此产生了度量学习。为实际对输入进行分类,在构建成功的嵌入后,可以将轻量级聚类赛放哪应用于潜在空间(如k-nn)
5.1 Open-Set Individual Identification via Metric Learning
成功构建这样一个嵌入空间的关键是选择一个聚类空间的损失函数。度量学习的一个关键例子来源于使用孪生网络架构,其中图像对X1,X2通过一个具有耦合权重的双流网络传递,获得它们的嵌入。权重 θ 在两个相同的网络流 fθ 之间共享:
使用对比损失训练该架构,以根据实例的类别进行聚类: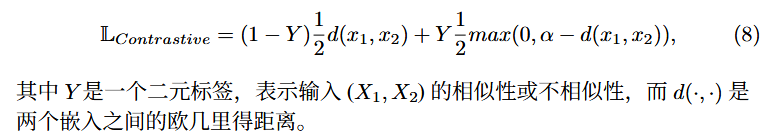
这种表述不能同时鼓励学习视觉的相似性和不相似性。这个缺点可以通过三元组损失公式解决,利用包含三张图像输入(Xa, Xp, Xn)的三元组的嵌入 xa, xp, xn,分别表示一个锚点、来自同一类的正例和来自不同类的负例。目的是在嵌入空间中鼓励锚点 xa 和正例 xp 之间的最小距离,以及锚点 xa 和负样本 xn 之间的最大距离。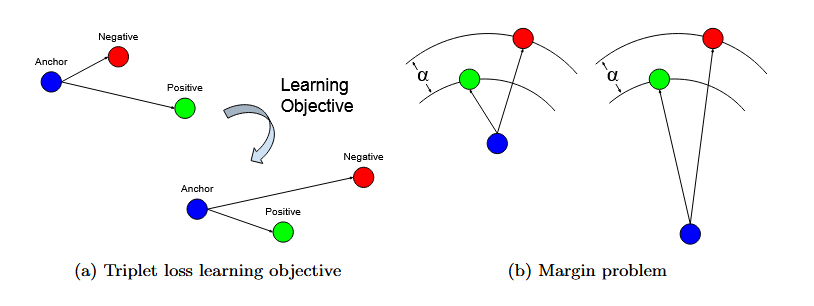
a) 三重损失函数旨在最小化锚点与正实例 (均属于同一类别)之间的距离,同时最大化锚点与负实例(属于不同类别)之间的距离。然而, (b) 说明了在三重损失公式中引入边际 α 参数所带来的问题;它可以在锚点的任何距离处得以满足
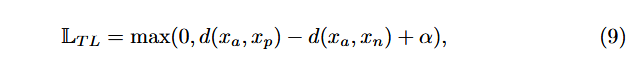
其中 α 表示一个常量边际超参数。常量 α 的包含往往会导致训练问题,因为边 际可以在距离锚点的任何距离下满足;图 11b 展示了这个问题。最近一种称为 倒数三元损失的公式减轻了这个限制 [81],该公式完全去除了边际超参数。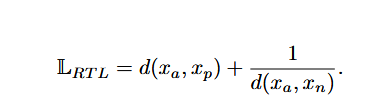
三元组损失 公式中加入SoftMax项来改善开放集识别能力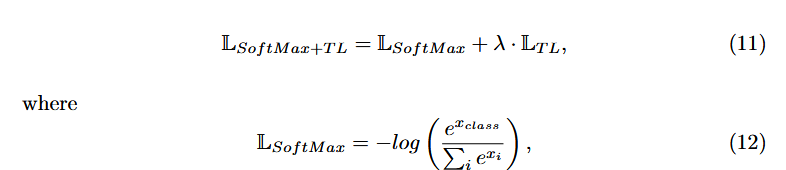
其中 λ 是一个常数权重超参数,LT L 是在方程9中定义的标准三元组损失。对 于我们的实验,我们选择 λ = 0.01作为参数网络搜索的结果
这种公式能够超越标准三重损失方法,因为它结合了两者的优点——完全监督 学习和可分离的嵌入空间。最重要的是,我们建议将由Softmax损失给出的完全 监督损失项与去除指定边界参数必要性的倒数三重损失公式结合。这种组合是 新颖的,表示为:
6. Experiments
比较和对比不同三元损失函数,定量和定性的战术弗里斯兰牛开放集识别任务中的性能差异
6.1. Experimental Setup
嵌入网络:ResNet-50
权重:在ImageNet上进行预训练
output:128个输出,定义了嵌入空间的维度
OpenCows2020数据集:是被区域的训练部分进行了100周期微调
batch:16
优化器:梯度下降
初始学习率:1 × 10^-3
动量:0.9
步骤:1、图像输入到主干网络经过特征提取生成n维
2、获得的n维嵌入向量x
3、使用k-nn进行分类,将每个类中的每个非测试实例投影到潜在空间中(无论是训练中有或没有的)
4、随后每个测试实例(已知和未知个体)也被投影到潜在空间
5、每个测试实例从周围的k个最邻近的向量投票获得结果分类。
准确率定义为正确预测数量与测试集样本总数的比值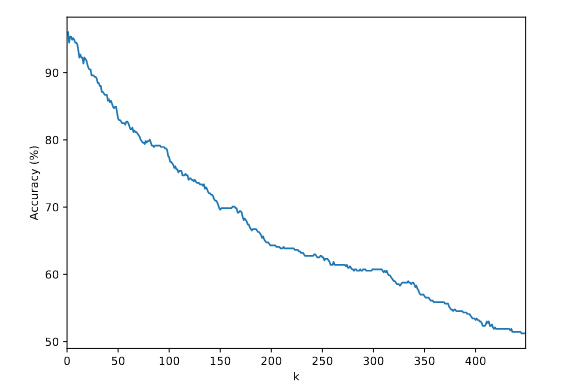
在对验证集的潜在表示进行分类时,所达到的准确度,针对 不同选择的k个最近邻。这项搜索是在50%开放问题的基础上进行的。
为验证模型从已见个体泛化至未见个体的能力,我们通过调整训练中完全扣留的类别比例来构建未知集,其比例取值为 r = {0.1, 0.17, 0.25, 0.33, 0.5, 0.6, 0.7, 0.8, 0.9}。未知类别的选择严格遵循既定比例,从每个图像源(室内或室外,详见第3.2节)中均匀随机抽取,以避免对背景环境或物体分辨率产生偏倚。在每个比例条件下,我们通过随机生成 n=10 次重复实验,以更精确地评估模型在当前已知与未知类别比例下的性能。通过系统调整这一比例,我们探究模型在日益开放的问题场景中的表现。关键的是,这 |r|×n 种划分组合在整个实验过程中保持恒定,以确保结果的一致性,并实现不同训练策略之间的定量比较。
为了挖掘更为合适的三元组,我么采用“批量困难”的挖掘策略
6.2. Results
我们基于嵌入的方法都优于基线方法,还有发现了是被错误没有来自于未知数据集,并且发现网络训练在特定图像来源方面变得更难,错误主要出现在图像比较少的个体中。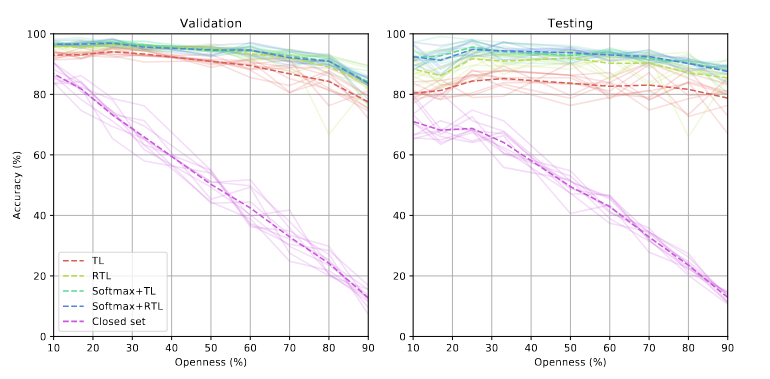
各折叠的平均、最小和最大准确率与问题的开放程度;即在训练过程中完全未考虑的所有身份类别的比例。绘制的是基于所采用的损失函数的不同响应,其中TL和RTL分别表示标准三元组损失和互惠三元组损失,“SoftMax +”表示如[74]所建议 的交叉熵和三元组损失函数的加权混合。还包含一个基准,以突显传统闭集分类器的不适用性。
6.2.1. Qualitative Analysis
可视化嵌入空间。通过t分布随机邻域嵌入技术(t-SNE)生成。嵌入训练集时,可以看到通过三元组损失公式训练的模型成功地将 相似身份‘聚集’在一起,同时将其他身份拉远。这样就足以聚类并重新识别 之前未见过的测试身份(参见图16c)。
下图可视化了在实现的所有损失函数下,针对50%开放问题的一致训练集的嵌入。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)