一篇文章搞懂消息队列
一.认识消息队列
消息队列(Message Queue),字面意思就是存放消息的队列。最简单的消息队列模型包括3个角色:
- 消息队列:存储和管理消息,也被称为消息代理(Message Broker)
- 生产者:发送消息到消息队列
- 消费者:从消息队列获取消息并处理消息

市面上提供了需要服务实现消息队列,这里我们选择用Redis实现消息队列
Redis提供了三种不同的方式来实现消息队列:
- list结构:基于List结构模拟消息队列
- PubSub:基本的点对点消息模型
- Stream:比较完善的消息队列模型
二.基于List结构模拟消息队列
消息队列(Message Queue),字面意思就是存放消息的队列。而Redis的list数据结构是一个双向链表,很容易模拟出队列效果。
队列是入口和出口不在一边,因此我们可以利用:LPUSH 结合 RPOP、或者 RPUSH 结合 LPOP来实现。
不过要注意的是,当队列中没有消息时RPOP或LPOP操作会返回null,并不像JVM的阻塞队列那样会阻塞并等待消息。
因此这里应该使用BRPOP或者BLPOP来实现阻塞效果。

世界是一个矛盾的集合体,客观事物的内部充斥着矛盾,那么基于List的消息队列有哪些优缺点?
优点:
- 利用Redis存储,不受限于JVM内存上限
- 基于Redis的持久化机制,数据安全性有保证
- 可以满足消息有序性
缺点:
- 无法避免消息丢失
- 只支持单消费者
三.PubSub:基本的点对点消息模型
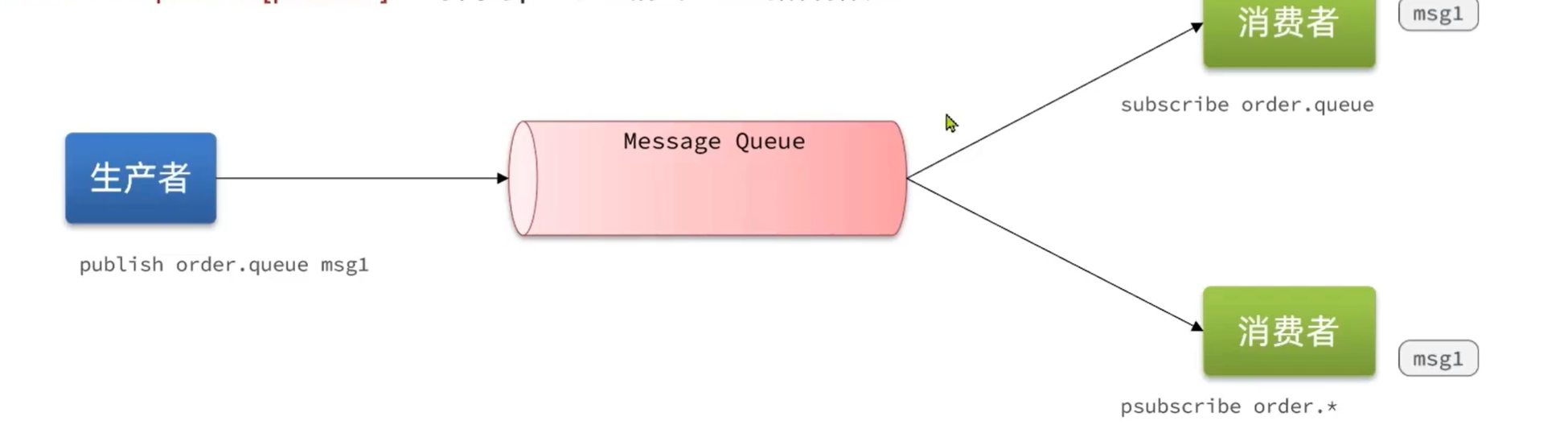
PubSub(发布订阅) 是Redis2.0版本引入的消息传递模型。顾名思义,消费者可以订阅一个或多个channel,生产者向对应channel发送消息后,所有订阅者都能收到相关消息。
- SUBSCRIBE channel [channel] :订阅一个或多个频道
- PUBLISH channel msg :向一个频道发送消息
- PSUBSCRIBE pattern[pattern] :订阅与pattern格式匹配的所有频道
那么基于PubSub的消息队列有哪些优缺点?
优点:
- 采用发布订阅模型,支持多生产、多消费
缺点:
- 不支持数据持久化
- 无法避免消息丢失
- 消息堆积有上限,超出时数据丢失
四.Stream:比较完善的消息队列模型
Stream 是 Redis 5.0 引入的一种新数据类型,可以实现一个功能非常完善的消息队列。
1.发送消息
发送消息的命令:
127.0.0.1:6379> help xadd
XADD key [NOMKSTREAM] [MAXLEN|MINID [=|~] threshold [LIMIT count]] *|ID field value [field value ...]
summary: Appends a new entry to a stream
since: 5.0.0
group: stream注释说明:
[NOMKSTREAM]:如果队列不存在,是否自动创建队列 → 默认是自动创建[MAXLEN|MINID [=|~] threshold [LIMIT count]]:设置消息队列的最大消息数量*|ID:消息的唯一id,*代表由Redis自动生成。格式是 "时间戳-递增数字",例如 "1644804662707-0"field value [field value ...]:发送到队列中的消息,称为Entry。格式就是多个key-value键值对
例如:
## 创建名为 users 的队列,并向其中发送一个消息,内容是:{name=jack,age=21},并且使用Redis自动生成ID
127.0.0.1:6379> XADD users * name jack age 21
"1644805700523-0"2.读取消息
读取消息的方式之一:XREAD
127.0.0.1:6379> help XREAD
XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] ID [ID ...]
summary: Return never seen elements in multiple streams, with IDs greater than the ones reported by the caller for each stream. Can block.
since: 5.0.0
group: stream参数注释说明:
[COUNT count]→ 每次读取消息的最大数量[BLOCK milliseconds]→ 当没有消息时,是否阻塞、阻塞时长STREAMS key [key ...]→ 要从哪个队列读取消息,key就是队列名ID [ID ...]→ 起始id,只返回大于该ID的消息0:代表从第一个消息开始$:代表从最新的消息开始
TREAM类型消息队列的XREAD命令特点:
- 消息可回溯
- 一个消息可以被多个消费者读取
- 可以阻塞读取
- 有消息漏读的风险
五.解决基于Stream的消息队列中的消息漏读风险-------消费者组
1.消费者组简单介绍
消费者组(Consumer Group):将多个消费者划分到一个组中,监听同一个队列。具备下列特点:
01 消息分流
队列中的消息会分流给组内的不同消费者,而不是重复消费,从而加快消息处理的速度
02 消息标示
消费者组会维护一个标示,记录最后一个被处理的消息,哪怕消费者宕机重启,还会从标示之后读取消息。确保每一个消息都会被消费
03 消息确认
消费者获取消息后,消息处于 pending 状态,并存入一个 pending-list。当处理完成后需要通过 XACK 来确认消息,标记消息为已处理,才会从 pending-list 移除。
2.创建消费者组:
XGROUP CREATE key groupName ID [MKSTREAM]- key:队列名称
- groupName:消费者组名称
- ID:起始ID标示,
$代表队列中最后一个消息,0则代表队列中第一个消息 - MKSTREAM:队列不存在时自动创建队列
3.其它常见命令:
# 删除指定的消费者组
XGROUP DESTROY key groupName
# 给指定的消费者组添加消费者
XGROUP CREATECONSUMER key groupname consumername
# 删除消费者组中的指定消费者
XGROUP DELCONSUMER key groupname consumername4.从消费者组读取消息:
从消费者组读取消息:
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] ID [ID ...]- group:消费组名称
- consumer:消费者名称,如果消费者不存在,会自动创建一个消费者
- count:本次查询的最大数量
- BLOCK milliseconds:当没有消息时最长等待时间
- NOACK:无需手动 ACK,获取到消息后自动确认
- STREAMS key:指定队列名称
- ID:获取消息的起始 ID:
- ">":从下一个未消费的消息开始
- 其它:根据指定 id 从 pending-list 中获取已消费但未确认的消息,例如
0,是从 pending-list 中的第一个消息开始
5.消费者监听消息的基本思路
消费者监听消息的基本思路:
1 while(true){
2 // 尝试监听队列,使用阻塞模式,最长等待 2000 毫秒
3 Object msg = redis.call("XREADGROUP GROUP g1 c1 COUNT 1 BLOCK 2000 STREAMS s1 >");
4 if(msg == null){ // null说明没有消息,继续下一次
5 continue;
6 }
7 try {
8 // 处理消息,完成后一定要ACK
9 handleMessage(msg);
10 } catch(Exception e){
11 while(true){
12 Object msg = redis.call("XREADGROUP GROUP g1 c1 COUNT 1 STREAMS s1 0");
13 if(msg == null){ // null说明没有异常消息,所有消息都已确认,结束循环
14 break;
15 }
16 try {
17 // 说明有异常消息,再次处理
18 handleMessage(msg);
19 } catch(Exception e){
20 // 再次出现异常,记录日志,继续循环
21 continue;
22 }
23 }
24 }
25 }代码逻辑简要说明:
- 主循环通过
XREADGROUP ... >从流中读取新消息(未消费过的)。 - 如果处理失败(catch Exception),进入内层循环,用
XREADGROUP ... 0从当前消费者的 PEL(Pending List) 中重新拉取“已投递但未确认”的消息进行重试。 - 内层循环会持续尝试处理 PEL 中的消息,直到全部成功或为空为止。
- 注意:此代码示例未显式调用 XACK,实际生产中应在
handleMessage成功后手动 ACK,否则消息会永久滞留在 PEL 中。
6.STREAM类型消息队列的XREADGROUP命令特点:
- 消息可回溯
- 可以多消费者争抢消息,加快消费速度
- 可以阻塞读取
- 没有消息漏读的风险
- 有消息确认机制,保证消息至少被消费一次
六.消息队列三种实现方法的区别
| 特性 | List | PubSub | Stream |
|---|---|---|---|
| 消息持久化 | 支持 | 不支持 | 支持 |
| 阻塞读取 | 支持 | 支持 | 支持 |
| 消息堆积处理 | 受限于内存空间,可以利用多消费者加快处理 | 受限于消费者缓冲区 | 受限于队列长度,可以利用消费者组提高消费速度,减少堆积 |
| 消息确认机制 | 不支持 | 不支持 | 支持 |
| 消息回溯 | 不支持 | 不支持 | 支持 |
- List:适合简单队列场景,支持持久化和阻塞读,但无 ACK、无法回溯,依赖手动控制消费逻辑。
- PubSub:实时广播模式,无持久化、无确认、无回溯,适用于对可靠性要求不高的即时通知。
- Stream:功能最强大,支持持久化、ACK、回溯、消费者组负载均衡,是构建可靠消息系统的推荐选择。
- 需要高可靠 + 可重试 + 历史回放 → 选 Stream
- 简单 FIFO 队列 + 自行管理状态 → 选 List
- 实时推送/事件广播 → 选 PubSub

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 27
27 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)