(论文速读)无分类器扩散制导
论文题目:CLASSIFIER-FREE DIFFUSION GUIDANCE(无分类器扩散制导)
会议:NIPS2021
摘要:分类器引导是最近引入的一种方法,用于在训练后的条件扩散模型中权衡模式覆盖和样本保真度,其精神与其他类型生成模型中的低温采样或截断相同。分类器引导将扩散模型的分数估计与图像分类器的梯度相结合,因此需要训练与扩散模型分离的图像分类器。这也提出了一个问题,即是否可以在没有分类器的情况下进行引导。我们证明,在没有这样的分类器的情况下,纯生成模型确实可以进行引导:在我们所谓的无分类器引导中,我们联合训练一个条件和一个无条件扩散模型,并将得到的条件和无条件分数估计结合起来,以获得样本质量和多样性之间的权衡,类似于使用分类器引导获得的结果。
|
一句话概括 本文提出了无分类器引导(Classifier-Free Guidance)方法:通过联合训练条件扩散模型与无条件扩散模型,采样时对两者的score估计做线性外插,实现了与分类器引导相当的FID/IS权衡效果,且完全不需要额外的分类器。 |
一、背景与痛点
1.1 扩散模型的崛起
扩散模型(Diffusion Models)近年来在图像与音频合成中表现卓越,在FID、IS等指标上已超越BigGAN-deep和VQ-VAE-2等强基线。然而,与GAN、Flow模型相比,扩散模型长期缺乏一种关键能力——截断采样(Truncation Sampling):在样本多样性与单张保真度之间自由权衡。
1.2 截断采样:其他生成模型的魔法按钮
在BigGAN中,调节截断参数可以控制:截断越强,生成图像越精致典型,但多样性降低;截断越弱,多样性丰富但质量参差。Glow的低温采样有类似效果。
然而,直接在扩散模型中模仿这些操作——例如缩放score向量,或减小反向过程的高斯噪声方差——并不奏效,只会产生模糊低质量的样本(Dhariwal & Nichol, 2021)。
1.3 分类器引导(Classifier Guidance)及其三大局限
Dhariwal & Nichol (2021) 提出了分类器引导来弥补上述不足:将扩散模型的score估计与额外图像分类器的梯度混合——
|
分类器引导公式 epsilon_tilde(z,c) = epsilon(z,c) - w * sigma * gradient[log p_classifier(c|z)] 其中 w 为引导强度,p_classifier 是在加噪数据上专门训练的分类器。 |
然而这带来了三个根本性问题:
-
额外训练成本: 必须单独训练分类器,且该分类器必须在加噪数据上训练,无法复用标准预训练分类器,大幅增加管线复杂度。
-
对抗性疑虑: 采样时沿分类器梯度更新,本质上是对分类器施以基于梯度的对抗攻击(adversarial attack)。IS/FID的提升究竟是真实质量提升,还是在欺骗评测分类器?
-
类GAN的担忧: 这种操作让扩散模型开始像GAN——而GAN本就以高IS/低FID著称。这引发了对方法本质的质疑。
二、核心创新:Classifier-Free Guidance
本文的核心贡献是一个极为简洁而有效的方案——完全不需要分类器,用纯粹的生成模型来实现引导。
2.1 整体思路
|
核心思想 用同一个神经网络同时建模有条件生成和无条件生成,训练时随机丢弃条件信息;采样时将两者的score估计做线性外插,放大条件信号。 |
2.2 训练阶段(Algorithm 1)

|
Algorithm 1: Joint Training with Classifier-Free Guidance |
|
Require: p_uncond — 无条件训练的概率(超参数) repeat |
训练伪代码——关键改动仅一行:以概率 p_uncond 将类别标签 c 替换为空标记
最关键的设计:条件模型和无条件模型共享同一套神经网络参数。无条件生成只需将类别标识符 c 替换为空标记,即 ![]() 。不增加任何额外参数,也无需修改网络结构。
。不增加任何额外参数,也无需修改网络结构。
2.3 采样阶段(Algorithm 2)

|
Require: w — 引导强度; c — 类别条件; λ₁,...,λ_T — log SNR 递增序列 z₁ ~ N(0, I) |
|
核心公式 w = 0 -> 普通条件生成(无引导) w > 0 -> 增强引导:IS升高,多样性降低 w 越大 -> IS 单调递增,FID 先降后升 |
2.4 数学直觉:隐式分类器
这个公式在数学上等价于用隐式分类器![]() 来引导采样。若拥有精确的条件/无条件score,其梯度恰好为:
来引导采样。若拥有精确的条件/无条件score,其梯度恰好为:
![]()
将其代入分类器引导公式,恰好得到上述线性外插式。这说明我们实际上是在用生成模型通过贝叶斯翻转自导出的分类器来引导采样,无需任何外部判别器。
|
重要说明 由于使用无约束神经网络参数化score,score估计不形成保守向量场,因此引导步骤从根本上不是对分类器的对抗攻击——这正是本文消除对抗性疑虑的关键。 |
三、实验结果
论文在 ImageNet 64x64 和 128x128 的类条件生成任务上进行评测,采用 FID(越低越好) 和 IS(越高越好) 作为指标,每个设置生成50,000张样本。
3.1 引导强度 w 的影响(64x64 ImageNet)


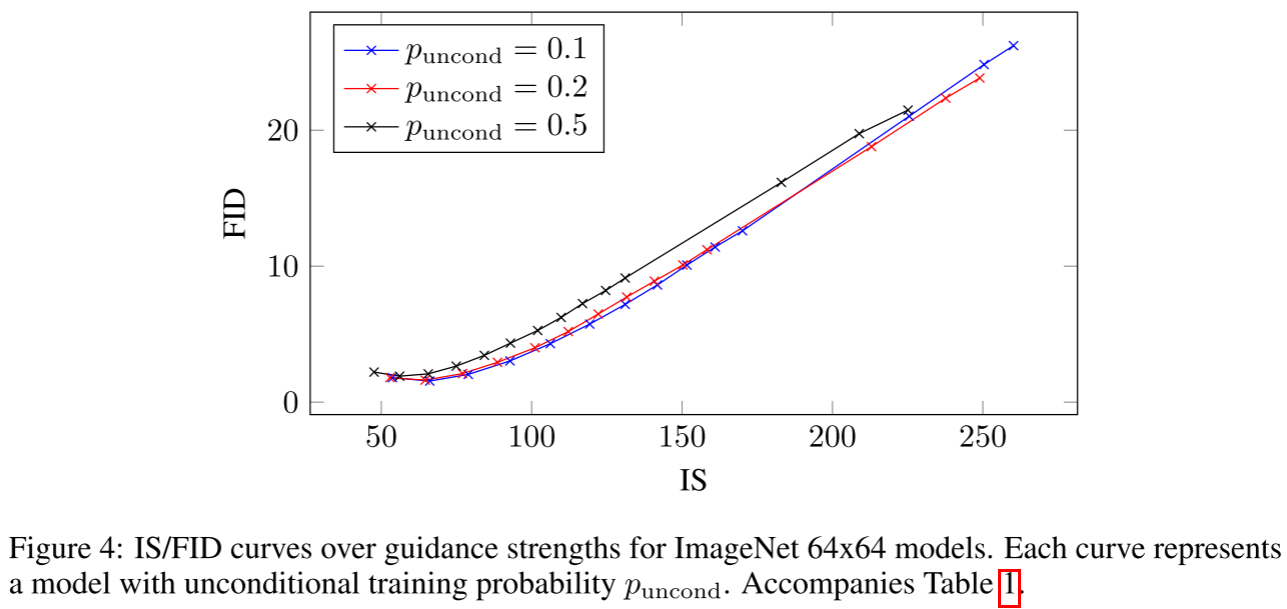
以下为 ImageNet 64x64 实验核心数据(引导强度 w 从0到4,模型 p_uncond=0.1/0.2/0.5):
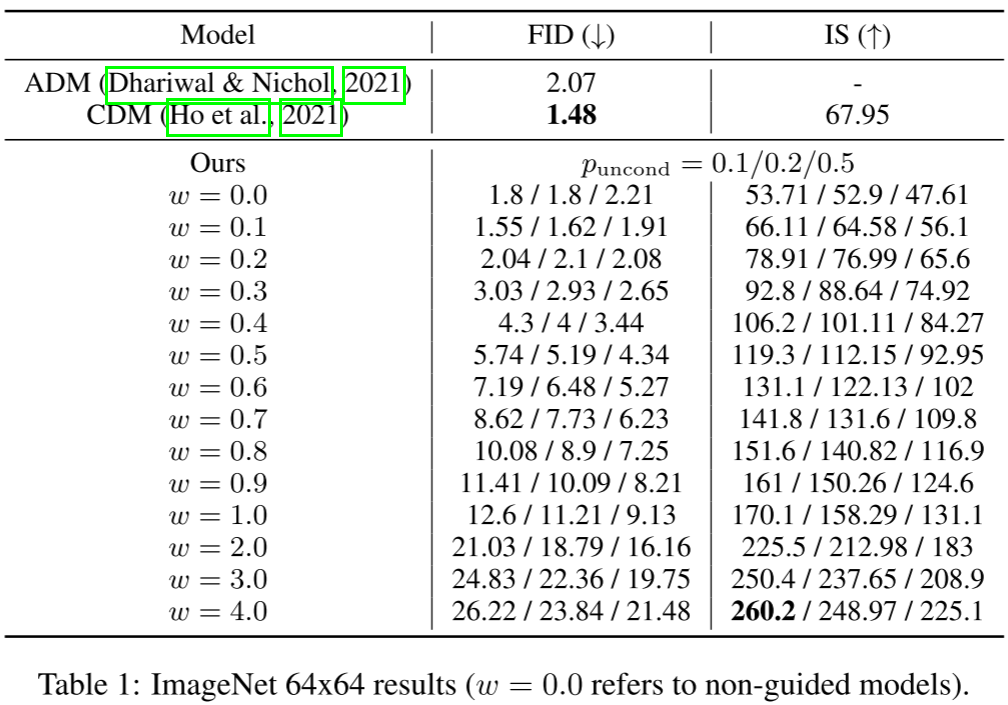
关键观察:
-
最佳FID: p_uncond=0.1时,w=0.1达到FID=1.55,在极少参数增量下与SOTA竞争。
-
最高IS: w=4.0时IS=260.2,远超无引导的53.71。
-
单调权衡: 随w增大,FID单调上升(多样性降低),IS单调上升(保真度增加),曲线清晰。
-
p_uncond的影响: p_uncond=0.5明显差于0.1/0.2,说明只需少量容量用于无条件建模即可。
3.2 与SOTA方法对比(128x128 ImageNet)


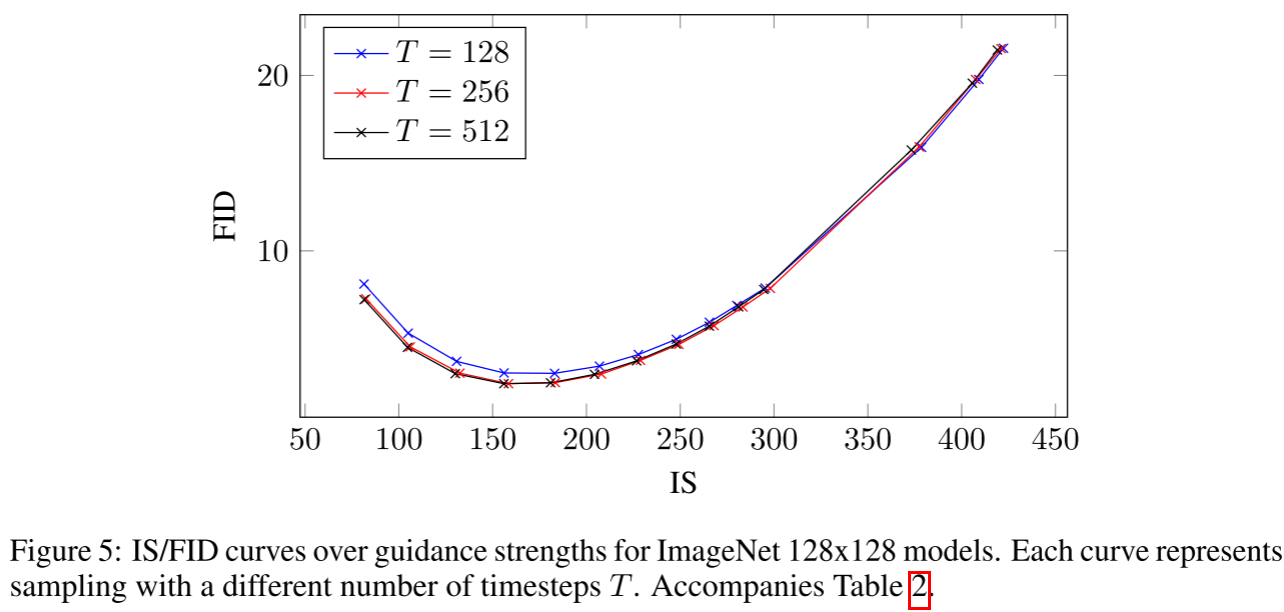
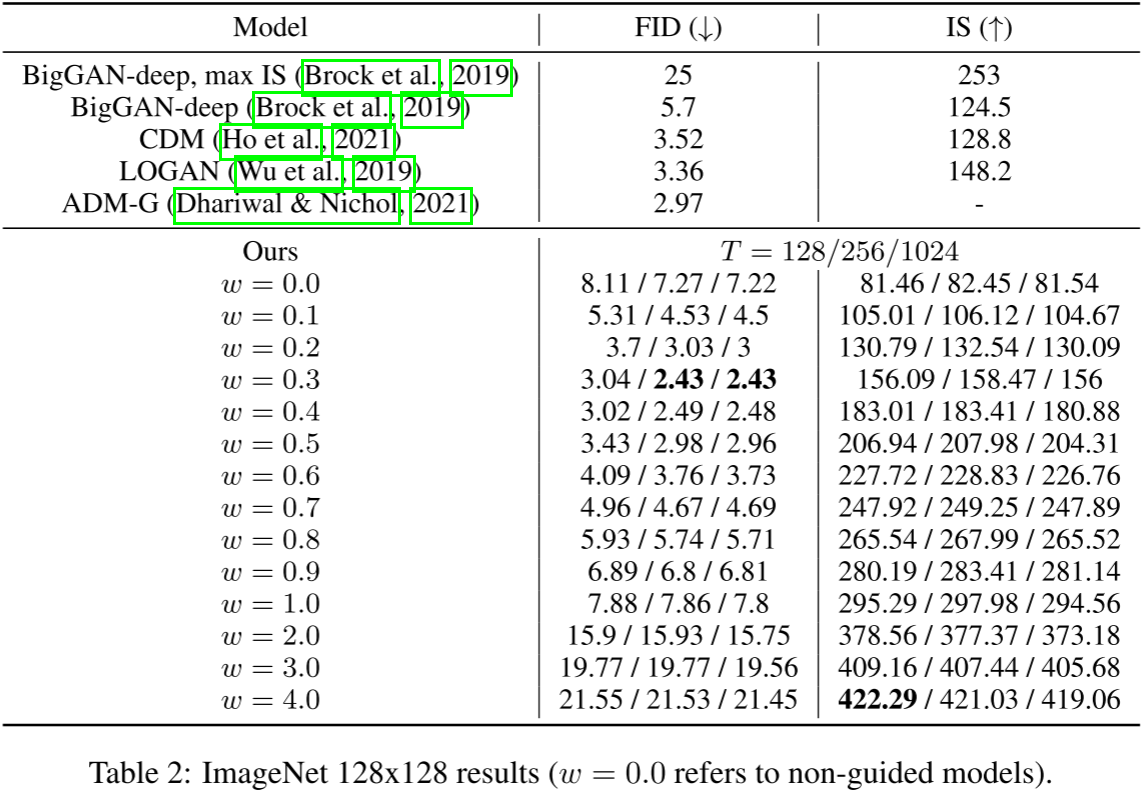
重要结论:
-
w=0.3时FID=2.43,超越ADM-G(2.97),成为128x128 ImageNet新SOTA。
-
w=4.0时IS=421,大幅超越BigGAN-deep最高IS(253),同时FID=21.53也优于BigGAN(25.0)。
-
公平计算量对比: 本文每步需两次前向传播(条件+无条件),与ADM-G相同计算量时(T=128)FID略逊,需注意。
3.3 二维玩具实验的直观验证

论文Figure 2通过三个各向同性高斯分布(代表三个类别)的玩具实验,直观展示了引导的几何效果:随引导强度增加,每个类别的条件概率分布从宽泛的高斯型变为形状复杂、高度集中的分布,概率质量向远离其他类别的方向集中——这正是IS提升、FID上升(多样性降低)的几何直观。
四、讨论与启示
4.1 极简实现
|
实现简洁性 训练改动:仅一行代码 —— 以概率 p_uncond 将 c 替换为空标记 采样改动:仅一行代码 —— 无需修改网络架构,无需额外参数,无需独立训练流程 |
4.2 纯生成模型能力的证明
本文最重要的理论贡献是:证明了纯粹的生成扩散模型在不借助任何判别式分类器的情况下,可以最大化基于分类器的IS/FID评测指标。高质量样本的生成能力内嵌于生成模型本身,而非依赖于外部判别器的对抗引导。
4.3 引导的直觉解释
Classifier-Free Guidance 通过引入负的无条件score项,同时实现了两件事:
-
降低无条件概率: 样本远离平均数据点,避免生成过于平庸的样本;
-
提升条件概率: 样本更靠近该类别的典型区域,生成更具代表性的图像。
这种对无条件score的负向利用在其他生成模型中尚未被系统探索,可能在其他应用场景中也有价值。
4.4 局限与未来工作
-
采样速度: 每步需两次前向传播,速度是单模型的一半。可考虑将条件注入推迟到网络后层(作者留作未来工作)。
-
多样性损失: 引导越强,多样性越低。在需要覆盖长尾分布的应用中需谨慎使用高引导强度。
-
多类别近似: 若类别数有限且分布已知,可通过 P(x) = sum_c P(x|c)P(c) 从条件score推导无条件score,但计算量随类别数线性增长。
五、总结
Classifier-Free Diffusion Guidance 是扩散模型领域极具影响力的工作,其价值可从五个维度概括:
|
维度 |
贡献内容 |
|
问题发现 |
指出分类器引导的训练复杂性、对抗性疑虑与类GAN性质三大根本问题 |
|
方法创新 |
提出无分类器引导:联合训练+线性外插,与分类器引导效果相当 |
|
理论洞察 |
揭示引导等价于隐式贝叶斯分类器,阐明纯生成模型可实现截断效果的机制 |
|
实验验证 |
128x128 ImageNet SOTA:w=0.3时FID=2.43超越ADM-G;w=4.0时IS=421超越BigGAN最高IS 253 |
|
工程价值 |
实现极简(各一行改动),已成为Stable Diffusion、DALL-E 2、Imagen等现代生成模型的标配组件 |
|
影响力 Classifier-Free Guidance 已成为现代文生图模型的基础组件,广泛应用于 Stable Diffusion、DALL-E 2、Imagen 等系统中。理解这篇论文,是深入学习扩散模型引导机制的必经之路。 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 13
13 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)