OpenClaw,workBuddy上必装的12个深度学习Skill技能
深度学习 Skill 技能说明书
数据来源:SkillsBot AI Skill技能库 · 深度学习分类
整理时间:2026-03-17
页面截图
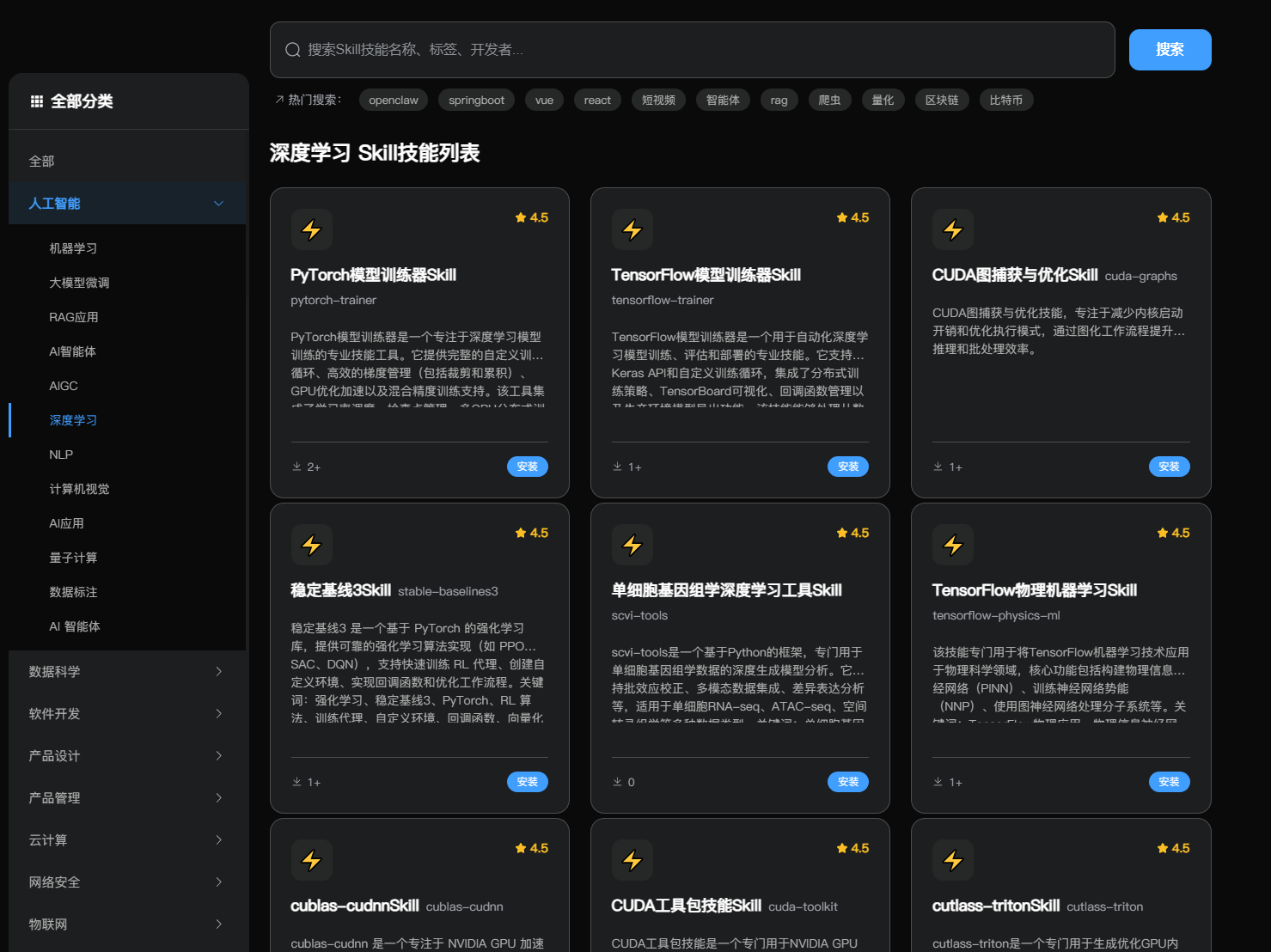
技能速览表
| Skill 名称 | 功能描述 | 痛点解决 | 下载地址 |
|---|---|---|---|
| PyTorch 模型训练器 | 完整自定义训练循环、梯度管理、GPU 优化、混合精度训练,集成学习率调度、检查点与多 GPU 分布式训练 | 手搭训练流程繁琐、梯度爆炸难控制、分布式配置复杂 | skill/464 |
| TensorFlow 模型训练器 | 自动化训练/评估/部署,支持 Keras API、分布式策略、TensorBoard 可视化和 SavedModel/TFLite 导出 | 训练部署链路断裂、跨平台迁移麻烦、可视化配置困难 | skill/469 |
| CUDA 图捕获与优化 | 图化 GPU 工作流程,减少内核启动开销,提升 AI 推理和批处理效率 | 高频推理内核启动开销大、CPU 侧调度延迟高 | skill/2085 |
| 稳定基线 3 | PyTorch 强化学习库,提供 PPO/SAC/DQN 等算法,支持自定义环境、回调函数和向量化并行采样 | RL 算法实现易出 Bug、环境接口不统一、训练效率低 | skill/7705 |
| 单细胞基因组学深度学习工具 | 单细胞基因组数据深度生成模型,支持批效应校正、多模态集成与差异表达分析 | 批效应干扰大、多组学整合难、传统方法精度不足 | skill/7709 |
| TensorFlow 物理机器学习 | 构建 PINN/NNP/GNN,将 TensorFlow 应用于物理科学仿真与分子动力学建模 | 传统数值方法计算成本高、高维问题无法处理 | skill/1733 |
| cublas-cudnn | 集成 cuBLAS 与 cuDNN,提供张量核心配置、GEMM 优化、深度学习层实现及混合精度支持 | 手调 CUDA 库门槛高、算法选型与内存管理复杂 | skill/2083 |
| CUDA 工具包技能 | CUDA 内核开发、nvcc 编译优化、PTX/SASS 汇编分析及 GPU 内存管理 | CUDA 开发曲线陡峭、调试工具链难用、性能瓶颈难定位 | skill/2086 |
| cutlass-triton | 使用 CUTLASS 和 Triton 生成优化 GPU 内核,实现高性能矩阵计算和自定义算子 | 手写高性能 GPU 内核难度极高,缺乏自动化优化工具 | skill/2087 |
| NCCL 多 GPU 通信库集成 | 集成 NCCL,支持全归约/全收集/广播,针对 NVLink/PCIe 拓扑优化多节点集群通信 | 多 GPU 梯度同步配置繁琐、带宽利用率低 | skill/2091 |
| Nsight 性能分析专家 | NVIDIA GPU 性能瓶颈诊断、内核优化、内存带宽分析与线程束效率评估,支持屋顶线模型 | GPU 程序优化无从下手、瓶颈定位依赖经验 | skill/2092 |
| PyTorch Lightning | 组织和自动化 PyTorch 项目,支持多 GPU/TPU 训练、分布式策略、实验跟踪与模块化代码结构 | 训练代码冗余、多卡配置复杂、实验管理混乱 | skill/10680 |
技能详细说明
1. PyTorch 模型训练器 (pytorch-trainer)
- 评分:⚡ 4.5 安装量:2+
- 详情页:https://www.skillsbot.cn/skill/464
功能描述
专注于深度学习模型训练的专业技能工具。提供完整的自定义训练循环、高效的梯度管理(裁剪和累积)、GPU 优化加速以及混合精度训练支持,集成学习率调度、检查点管理、多 GPU 分布式训练和早停机制,并能与主流实验跟踪系统无缝对接。
痛点解决
- 手动搭建 PyTorch 训练循环代码冗余、容易出错
- 梯度爆炸/消失问题难以统一管理
- 多 GPU 分布式训练配置门槛高
- AutoML 流水线编排缺乏标准化接口
2. TensorFlow 模型训练器 (tensorflow-trainer)
- 评分:⚡ 4.5 安装量:1+
- 详情页:https://www.skillsbot.cn/skill/469
功能描述
自动化深度学习模型训练、评估和部署的专业技能。支持 Keras API 和自定义训练循环,集成分布式训练策略、TensorBoard 可视化、回调函数管理以及生产环境模型导出功能(SavedModel/TFLite),覆盖数据加载到边缘部署的完整流水线。
痛点解决
- 训练与部署链路断裂,模型无法平滑导出到生产/边缘环境
- TensorBoard 可视化配置复杂
- 分布式训练策略选型困难
- Keras API 与 TF 底层 API 混用导致代码难以维护
3. CUDA 图捕获与优化 (cuda-graphs)
- 评分:⚡ 4.5 安装量:1+
- 详情页:https://www.skillsbot.cn/skill/2085
功能描述
专注于减少 CUDA 内核启动开销和优化执行模式,通过图化工作流程(CUDA Graphs)提升 AI 推理和批处理效率。将重复的 GPU 操作序列预先捕获为执行图,消除运行时调度开销。
痛点解决
- 高频推理场景下 GPU 内核启动开销占比大
- CPU 侧调度 GPU 操作存在不可忽略的延迟
- 批处理任务中大量重复操作缺乏优化机制
4. 稳定基线 3 (stable-baselines3)
- 评分:⚡ 4.5 安装量:1+
- 详情页:https://www.skillsbot.cn/skill/7705
功能描述
基于 PyTorch 的强化学习库,提供 PPO、SAC、DQN 等主流 RL 算法的可靠实现,支持快速训练 RL 智能体、创建自定义环境、实现回调函数和优化工作流程,并支持向量化环境进行并行采样。
痛点解决
- 从零实现 PPO/SAC 等算法易出 Bug,调试困难
- 自定义环境与标准库对接接口不统一
- 超参搜索和实验管理效率低下
- 单环境采样速度慢,训练耗时长
5. 单细胞基因组学深度学习工具 (scvi-tools)
- 评分:⚡ 4.5 安装量:0
- 详情页:https://www.skillsbot.cn/skill/7709
功能描述
基于 Python 的单细胞基因组学深度生成模型框架,应用变分推断对高维基因表达数据建模,支持批效应校正、多模态数据集成(scRNA-seq、ATAC-seq、空间转录组学)和差异表达分析。
痛点解决
- 单细胞测序数据批效应干扰严重,影响分析结论
- 多组学数据整合缺乏统一工具
- 传统统计方法对高维稀疏矩阵处理能力不足
- 差异表达分析中假阳性率高
6. TensorFlow 物理机器学习 (tensorflow-physics-ml)
- 评分:⚡ 4.5 安装量:1+
- 详情页:https://www.skillsbot.cn/skill/1733
功能描述
将 TensorFlow 机器学习技术应用于物理科学领域,核心功能包括构建物理信息神经网络(PINN)、训练神经网络势能(NNP)、使用图神经网络(GNN)处理分子系统,实现科学机器学习建模。
痛点解决
- 传统数值方法(有限元/差分)求解 PDE 计算成本极高
- 物理模拟无法处理高维参数空间
- 分子动力学势函数精度与效率难以兼顾
- 纯数据驱动模型无法内嵌物理约束
7. cublas-cudnn (cublas-cudnn)
- 评分:⚡ 4.5 安装量:0
- 详情页:https://www.skillsbot.cn/skill/2083
功能描述
专注于 NVIDIA GPU 加速数学库集成,提供专家级 cuBLAS(线性代数)和 cuDNN(深度神经网络)调用能力。涵盖张量核心操作配置、优化 GEMM 调用生成、深度学习层(卷积/池化/归一化)集成、GPU 内存管理以及 FP16/TF32/INT8 混合精度全面支持。
痛点解决
- 直接调用 cuBLAS/cuDNN C API 门槛极高
- 卷积算法选择需手动基准测试,耗时耗力
- 混合精度操作类型转换容易出错
- GPU 工作空间内存分配缺乏统一管理策略
8. CUDA 工具包技能 (cuda-toolkit)
- 评分:⚡ 4.5 安装量:0
- 详情页:https://www.skillsbot.cn/skill/2086
功能描述
专门用于 NVIDIA GPU 并行计算的开发工具,提供 CUDA 内核开发、nvcc 编译优化、PTX/SASS 汇编分析、内存层次结构管理(共享/全局/寄存器)和错误处理功能,支持多种 GPU 计算能力(sm_XX)。
痛点解决
- CUDA 编程学习曲线陡峭,内核开发调试困难
- nvcc 编译参数繁多、PTX 汇编难以阅读分析
- GPU 内存层次使用不当导致性能差
- 不同 GPU 架构(sm_xx)兼容性问题频发
9. cutlass-triton (cutlass-triton)
- 评分:⚡ 4.5 安装量:0
- 详情页:https://www.skillsbot.cn/skill/2087
功能描述
专门用于生成优化 GPU 内核的技能,通过 CUTLASS 模板库和 Triton DSL 实现高性能矩阵运算和自定义算子,覆盖从算法设计到内核代码生成的完整流程,大幅降低编写高性能 GPU 内核的门槛。
痛点解决
- 手写高性能 GEMM 等矩阵运算内核极为复杂
- CUTLASS 模板元编程抽象层次高,上手困难
- 自定义算子性能无法轻松逼近手工优化水平
- 缺乏 Triton DSL 使用最佳实践指引
10. NCCL 多 GPU 通信库集成 (nccl-communication)
- 评分:⚡ 4.5 安装量:0
- 详情页:https://www.skillsbot.cn/skill/2091
功能描述
集成 NVIDIA 集体通信库(NCCL),提供多 GPU 环境下全归约(AllReduce)、全收集(AllGather)、广播(Broadcast)等集体操作,支持单节点与多节点集群,并针对 NVLink、PCIe 等硬件拓扑进行性能优化,兼容 MPI 与 RCCL。
痛点解决
- 多 GPU 数据并行训练中梯度同步配置繁琐
- NCCL 与 MPI 集成缺乏清晰参考
- NVLink vs PCIe 拓扑下通信策略选择复杂
- 多节点集群网络(RDMA/InfiniBand)配置困难
11. Nsight 性能分析专家 (nsight-profiler)
- 评分:⚡ 4.5 安装量:0
- 详情页:https://www.skillsbot.cn/skill/2092
功能描述
专门用于 NVIDIA GPU 应用程序性能分析和优化的专业工具。提供 GPU 性能瓶颈诊断、内核优化、内存带宽分析、线程束效率评估等核心功能,支持屋顶线模型(Roofline)分析,帮助开发者深度优化 CUDA 程序性能。
痛点解决
- GPU 程序性能优化无从下手,缺乏系统化方法
- 性能瓶颈定位完全依赖经验,效率极低
- 内存带宽利用率、占用率等关键指标难以量化
- 屋顶线模型分析需要复杂的手动计算
12. PyTorch Lightning (pytorch-lightning)
- 评分:⚡ 4.5 安装量:0
- 详情页:https://www.skillsbot.cn/skill/10680
功能描述
用于组织和自动化 PyTorch 深度学习项目的框架,支持多 GPU/TPU 训练、分布式策略(DDP/FSDP)、数据管道管理、实验跟踪(W&B/MLflow)和模块化代码结构,将 PyTorch 研究代码工程化。
痛点解决
- PyTorch 训练代码重复冗余(训练循环到处复制粘贴)
- 多卡/多节点训练配置复杂,容易出错
- 实验管理混乱,难以复现结果
- 研究代码与生产代码结构差异大,迁移困难
技术方向分类
🏋️ 模型训练框架
| Skill | 链接 |
|---|---|
| PyTorch 模型训练器 | https://www.skillsbot.cn/skill/464 |
| TensorFlow 模型训练器 | https://www.skillsbot.cn/skill/469 |
| PyTorch Lightning | https://www.skillsbot.cn/skill/10680 |
🎮 GPU 底层加速
| Skill | 链接 |
|---|---|
| CUDA 图捕获与优化 | https://www.skillsbot.cn/skill/2085 |
| cublas-cudnn | https://www.skillsbot.cn/skill/2083 |
| CUDA 工具包技能 | https://www.skillsbot.cn/skill/2086 |
| cutlass-triton | https://www.skillsbot.cn/skill/2087 |
| NCCL 多 GPU 通信库集成 | https://www.skillsbot.cn/skill/2091 |
| Nsight 性能分析专家 | https://www.skillsbot.cn/skill/2092 |
🤖 强化学习
| Skill | 链接 |
|---|---|
| 稳定基线 3 | https://www.skillsbot.cn/skill/7705 |
🔬 科学计算与生物信息学
| Skill | 链接 |
|---|---|
| 单细胞基因组学深度学习工具 | https://www.skillsbot.cn/skill/7709 |
| TensorFlow 物理机器学习 | https://www.skillsbot.cn/skill/1733 |

数据截取自 SkillsBot 技能库

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 12
12 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)